DADA2 16S Chemerin Tutorial
This tutorial outlines how to process 16S rRNA sequencing data with the DADA2 pipeline. This tutorial is based on the DADA2 Big Data Tutorial and our previous 16S tutorial. We have written R scripts to allow the DADA2 pipeline to be run from the command-line.
Author: Gavin Douglas
First created: Sept 2017
- Basic unix skills (This is a good introductory tutorial: http://korflab.ucdavis.edu/bootcamp.html).
- If you are not using the prepared virtual box image you will need:
Amplicon sequencing is a common method of identifying which taxa are present in a sample based on amplified marker genes. This approach contrasts with shotgun metagenomics where all the DNA in a sample is sequenced. The most common marker gene used for prokaryotes is the 16S ribosomal RNA gene. It features regions that are conserved among these organisms, as well as variable regions that allow distinction among organisms. These characteristics make this gene useful for analyzing microbial communities at reduced cost compared to shotgun metagenomics approaches. Only a subset of variable regions are generally sequenced for amplicon studies and you will see them referred to using syntax like "V3-V4" (i.e. variable regions 3 to 4) in scientific papers. For this tutorial we will process V6-V8 amplified sequences.
This tutorial dataset was originally used in a project to determine whether knocking out the protein chemerin affects gut microbial composition. Originally 116 mouse samples acquired from two different facilities were used for this project (only a subset of samples were used in this tutorial dataset, for simplicity). Metadata associated with each sample is indicated in the mapping file (map.txt). In this mapping file the genotypes of interest can be seen: wildtype (WT), chemerin knockout (chemerin_KO) and chemerin receptor knockout (CMKLR1_KO). Also of importance are the two source facilities: "BZ" and "CJS". It is generally a good idea to include as much metadata as possible, since this data can easily be explored later on.
If you are running this tutorial as part of EMBL-EBI's Metagenomics workshop then the tutorial files should already be on your computer. You can copy the zipped folder to the Desktop, unzip it, and enter the folder to get started.
cd ~/Desktop
cp ~/Documents/16S_chemerin_tutorial.zip ~/Desktop
unzip 16S_chemerin_tutorial.zip
cd 16S_chemerin_tutorial
Otherwise you can download the tutorial files by replacing the cp command above with the below wget command.
wget http://kronos.pharmacology.dal.ca/public_files/tutorial_datasets/16S_chemerin_tutorial.zip
Before going any further we will need to specify the anaconda environment to work in. Using different anaconda environments is convenient on systems where there could be different versions of programs used for different projects. In this case we will be using the qiime1 environment, which is already set-up.
source ~/anaconda2/bin/activate qiime1
Note when you want to deactivate this environment you can type:
source /anaconda2/bin/deactivate
DADA2 infers the error rates from the reads themselves and will have trouble if primer sequences are included, so we first need to remove them. We will do so by running cutadapt on each pair of FASTQs with GNU parallel.
Before running all FASTQs in parallel however, it may be helpful to look at a single cutadapt command, which you do not need to run. This command will first determine if the matching primer sequences are found at the beginning of each read in a pair (with up to 10% of bases differing) and if so this pair will be trimmed and written to output.
Note: the \ characters in the below commands are just used to break up commands over multiple lines for clarity. These are not necessary to use for your own commands.
cutadapt \
--pair-filter any \
--no-indels \
--discard-untrimmed \
-g ACGCGHNRAACCTTACC \
-G ACGGGCRGTGWGTRCAA \
-o primer_trimmed_fastqs/109CHE6WT_S369_L001_R1_001.fastq.gz \
-p primer_trimmed_fastqs/109CHE6WT_S369_L001_R2_001.fastq.gz \
fastq/109CHE6WT_S369_L001_R1_001.fastq fastq/109CHE6WT_S369_L001_R2_001.fastq
This command is being run on paired FASTQs: 109CHE6WT_S369_L001_R1_001.fastq and 109CHE6WT_S369_L001_R2_001.fastq. The options mean:
-
--pair-filter any: if either read fails the filtering criterion, both will be discarded. -
--no-indels: no INDELs are permitted in primer sequences. -
--discard-untrimmed: discard reads that do not contain the matching sequence. -
-gand-G: the forward and reverse primer sequences to be matched respectively (note they contain IUPAC characters).
parallel is a handy way to get around writing out this command for each pair of reads. It can be slightly confusing at first, but it is extremely useful once you master it! You can see a brief tutorial on GNU parallel here.
The below command will run cutadapt on all FASTQs. The --link option is extremely important in this case as it specifies that there are two input files to each parallel command.
Running parallel with the --dry-run option is a good way to double-check that the commands are being specified correctly (they will be printed to screen, but not run).
mkdir primer_trimmed_fastqs
parallel --link --jobs 9 \
'cutadapt \
--pair-filter any \
--no-indels \
--discard-untrimmed \
-g ACGCGHNRAACCTTACC \
-G ACGGGCRGTGWGTRCAA \
-o primer_trimmed_fastqs/{1/}.gz \
-p primer_trimmed_fastqs/{2/}.gz \
{1} {2} \
> primer_trimmed_fastqs/{1/}_cutadapt_log.txt' \
::: fastq/*_R1_*.fastq ::: fastq/*_R2_*.fastq
Each sample's logfile created above can be parsed to put the counts of passing reads into a single table (cutadapt_log.txt by default).
parse_cutadapt_logs.py \
-i primer_trimmed_fastqs/*log.txt
We will now be filtering out low quality reads from the dataset. To get an idea of what cut-offs should be used you should always take a look at the quality distribution across your reads. The commands below will generate a quality report per sample which you can open in a web browser.
mkdir primer_trimmed_fastqc_out
fastqc -t 9 primer_trimmed_fastqs/*fastq.gz -o primer_trimmed_fastqc_out/
You should see a plot like this for the distribution of quality scores per base-pair in forward reads:

And like this for the reverse reads:

Notice that the reverse reads' quality scores dip off much sooner than the forward reads, which is typical for Illumina sequencing.
dada2_filter.R \
-f primer_trimmed_fastqs --truncLen 270,210 --maxN 0 \
--maxEE 3,7 --truncQ 2 --threads 9 --f_match _R1_.*fastq.gz \
--r_match _R2_.*fastq.gz
-
-f primer_trimmed_fastqs: Input folder. -
--truncLen 270,210: Truncate forward and reverse reads to 270 and 210 bp respectively. -
--maxN 0: Allow no N characters in reads (DADA2 will fail if it encounters Ns). -
--maxEE 3,7: Max of 3 and 7 expected # of errors allowed in forward and reverse reads respectively. -
--truncQ 2: Truncate reads at first instance of quality score <= 2. -
--threads 9: Run command over 9 cores in parallel. -
--f_matchand--r_match: Strings to match forward and reverse FASTQs respectively.
The output read count table (dada2_filter_read_counts.txt by default) is helpful to look at to help determine if cut-offs were too lenient or stringent.
The output filtered reads are written to filtered_fastqs/ by default.
Now that we have our filtered reads in hand, we are ready to actually infer the error models from the reads and identify "variants" (as opposed to "OTUs"). Paired-end reads will also be merged at this step.
dada2_inference.R \
-f filtered_fastqs/ --seed 4124 -t 9 --verbose --plot_errors
Options:
-
-f filtered_fastqs/: input reads. -
--seed 4124: random seed which should be set for reproducibility. -
--plot_errors: output plots of the inferred error rates (for sanity check).
The output R object containing the inferred variants and read counts per sample is written to seqtab.rds by default. This is a binary object that can be read into R by downstream steps or by yourself with the readRDS() function in R.
Once again it is helpful to look at the read counts in the logfile (dada2_inferred_read_counts.txt by default). It is typical to see some drop in reads at the merging step, but if this is too restrictive then you may need to change the upstream filtering cut-offs.
The final DADA2 steps are to remove chimeric variants and assign taxonomy to the variants.
dada2_chimera_taxa.R -i seqtab.rds \
-r ~/Documents/dada2_rdp_ref/rdp_train_set_16.fa.gz \
--skip_species -t 9
-
-i seqtab.rds: input sequence count table in RDS format. -
-r ~/Documents/dada2_rdp_ref/rdp_train_set_16.fa.gz: path to reference sequences for taxonomy assignment. -
--skip_species: flag to indicate that only taxonomy assignment until the genus level will be outputted (when this option is not set an additional output file is created). -
-t 9: run command over 9 cores in parallel.
The above command created a sequence count table written to seqtab_final.rds by default. The logfile dada2_nonchimera_counts.txt is again helpful to look at to see how many reads and variants were discarded at the chimera checking step.
The above commands each generated a logfile. We have written an Rscript that will take in logfiles in this format and combine them into one as shown by the below command.
merge_logfiles.R \
-i cutadapt_log.txt,dada2_filter_read_counts.txt,dada2_inferred_read_counts.txt,dada2_nonchimera_counts.txt \
-n cutadapt,filter,infer,chimera -o combined_log.txt
At this point there are a number of different analysis workflows you could use. The DADA2 authors recommend phyloseq, which you can read about in their tutorial. Here, we will present a more straight-forward workflow using QIIME.
To begin we first need to convert the sequence count table into a BIOM and FASTA file respectively. The --taxa_in option also specified taxonomic identifiers which will be outputted per DADA2 variant into a textfile.
convert_dada2_out.R -i \
seqtab_final.rds -b seqtab.biom -f seqtab.fasta --taxa_in tax_final.rds
The taxonomy labels can be added as metadata to the BIOM file using the below command.
biom add-metadata -i seqtab.biom -o seqtab_tax.biom --observation-metadata-fp taxa_metadata.txt \
--observation-header OTUID,taxonomy --sc-separated taxonomy
Now that we have our BIOM file we can see a summary report with the below command. This is especially useful for choosing a reasonable rarefaction cut-off in the next step.
biom summarize-table -i seqtab.biom -o seqtab_summary.txt
Based on the above report most samples have > 200 reads so we will rarify to this depth. Note that this is extremely low depth and in most cases you should not be using a cut-off this low on your own data.
single_rarefaction.py -i seqtab_tax.biom -o seqtab_tax_rarified.biom -d 200
The below commands will determine if there are community-level differences between sample groupings based on weighted UniFrac distances.
Firstly, we need to align all of the DADA2 variants together. The below command uses PyNAST, which uses the Greengenes reference alignment as a template for aligning.
align_seqs.py -i seqtab.fasta -o pynast_aligned_seqs
Importantly, whenever you use PyNAST you need to filter the alignment for non-informative columns (i.e. columns that are all gaps) since the Greengenes alignment is based on full 16S sequences and typically study variants are of only smaller regions.
filter_alignment.py -o pynast_aligned_seqs -i pynast_aligned_seqs/seqtab_aligned.fasta
Finally we can use the below command to build a phylogenetic tree using fasttree.
make_phylogeny.py -i pynast_aligned_seqs/seqtab_aligned_pfiltered.fasta -o dada2_seqs.tre
Based on this phylogenetic tree UniFrac distances can be calculated between samples and a PCoA plot can be used to visualize these distances in multi-dimensional space.
beta_diversity_through_plots.py -m map.txt -t dada2_seqs.tre -i seqtab_tax_rarified.biom \
-o plots/bdiv_otu
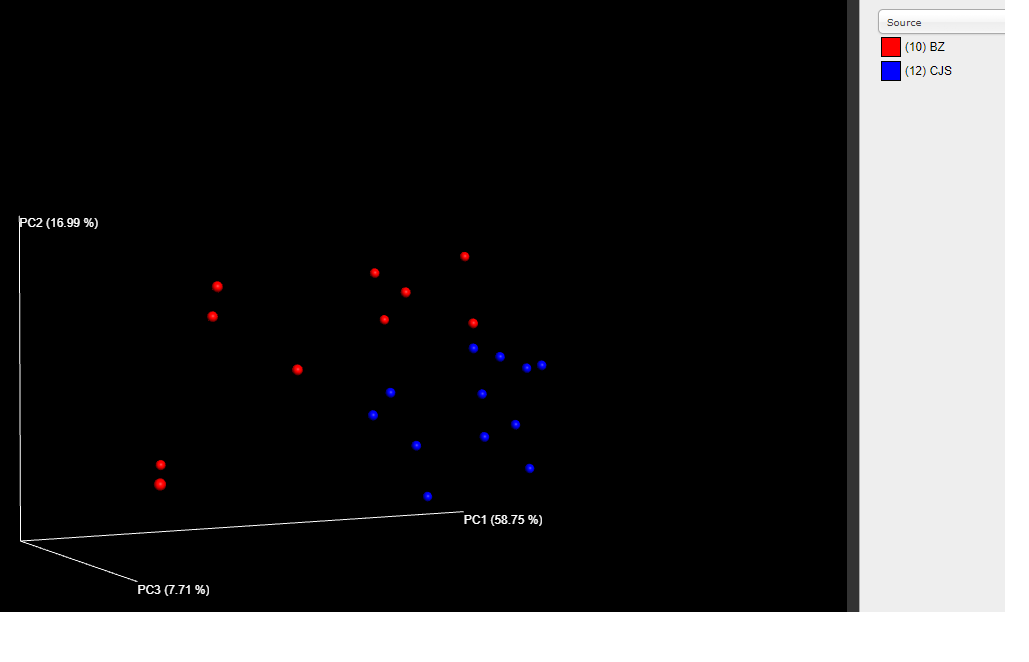
The output plots of interest are in plots/bdiv_otu/weighted_unifrac_emperor_pcoa_plot/index.html, which you can open in your browser. You can change by which metadata the samples are coloured. They should look similar to the below images for the genotype and source metadata, respectively.

Click to see how you could subset the samples to test the genotypes within each source facility separately (may want to skip these steps if short on time).
Since we know that source facility is such an important factor, we could analyze samples from each facility separately. This will lower our statistical power to detect a signal, but otherwise we cannot easily test for a difference between genotypes.
To compare the genotypes within the two source facilities separately we fortunately do not need to re-run the OTU-picking. Instead, we can just take different subsets of samples from the final OTU table. First though we need to make two new mapping files with the samples we want to subset:
head -n 1 map.txt >> map_BZ.txt; awk '{ if ( $3 == "BZ" ) { print $0 } }' map.txt >>map_BZ.txt
head -n 1 map.txt >> map_CJS.txt; awk '{ if ( $3 == "CJS" ) { print $0 } }' map.txt >>map_CJS.txt
These commands are split into 2 parts (separated by ";"). The first part writes the header line to each new mapping file. The second part is an awk command that prints any line where the 3rd column equals the id of the source facility. Note that awk splits by any whitespace by default, which is why the source facility IDs are in the 3rd column according to awk, even though we know this isn't true when the file is tab-delimited.
The BIOM "subset-table" command requires a text file with 1 sample name per line, which we can generate by these quick commands:
tail -n +2 map_BZ.txt | awk '{print $1}' | grep -v "111CHE6KO\|113CHE6WT" > samples_BZ.txt
tail -n +2 map_CJS.txt | awk '{print $1}' > samples_CJS.txt
These commands mean that the first line (the header) should be ignored and then the first column should be printed to a new file. The first line also excludes two BZ samples which were dropped. We can now take the two subsets of samples from the BIOM file:
biom subset-table -i seqtab_tax_rarified.biom -a sample -s samples_BZ.txt -o seqtab_tax_rarified_BZ.biom
biom subset-table -i seqtab_tax_rarified.biom -a sample -s samples_CJS.txt -o seqtab_tax_rarified_CJS.biom
We can now re-create the beta diversity plots for each subset:
beta_diversity_through_plots.py -m map_BZ.txt -t dada2_seqs.tre -i seqtab_tax_rarified_BZ.biom -o plots/bdiv_otu_BZ
beta_diversity_through_plots.py -m map_CJS.txt -t dada2_seqs.tre -i seqtab_tax_rarified_CJS.biom -o plots/bdiv_otu_CJS
We can now take a look at whether the genotypes separate in the re-generated weighted beta diversity PCoAs for each source facility separately.
For the BZ source facility:

And for the CJS source facility:

Just by looking at these PCoA plots it is clear that if there is any difference it is subtle. To statistically evaluate whether the weighted UniFrac beta diversities differ among genotypes within each source facility, you can run an analysis of similarity (ANOSIM) test. These commands will run the ANOSIM test and change the output filename:
compare_categories.py --method anosim -i plots/bdiv_otu_BZ/weighted_unifrac_dm.txt -m map_BZ.txt -c genotype -o beta_div_tests
mv beta_div_tests/anosim_results.txt beta_div_tests/anosim_results_BZ.txt
compare_categories.py --method anosim -i plots/bdiv_otu_CJS/weighted_unifrac_dm.txt -m map_CJS.txt -c genotype -o beta_div_tests
mv beta_div_tests/anosim_results.txt beta_div_tests/anosim_results_CJS.txt
There is a clear qualitative difference between the microbiota of mice from the two source facilities based on the above plots. It is also possible that there might also be differences between the rarefaction curves of samples from different source facilities. Rarefaction plots show estimates of alpha diversity at different read depths. They can help you determine if you have sufficiently sequenced your samples (based on whether they plateau) and whether the alpha diversity differs between your sample groupings.
alpha_rarefaction.py -i seqtab_tax_rarified.biom -o plots/alpha_rarefaction_plot -t dada2_seqs.tre -m map.txt \
--min_rare_depth 25 --max_rare_depth 200 --num_steps 8
--min_rare_depth and --max_rare_depth specify the min and max depths to rarify too (i.e. to subsample each of your samples to and then re-calculate the alpha diversity metric). --num_steps specifies the number of steps to take between these two values. Usually you would specify a much higher max_rare_depth, since again 200 is a very low depth to rarify to for actual data.
Note that setting the num_steps higher will give you better resolution, but will take longer. As for the beta diversity plots, you can open the resulting HTML file to view the plots: plots/alpha_rarefaction_plot/alpha_rarefaction_plots/rarefaction_plots.html.
Choose "observed_otus" as the metric and "Source" as the category. You should see this plot:

Often we are interested in figuring out which particular taxa (or other feature such as functions) differs in relative abundance between groups. There are many ways this can be done, but one common method is to use the easy-to-use program STAMP. We will run STAMP on the full variant table to figure out which genera differ between the two source facilities as an example.
Before running STAMP we need to convert our BIOM table into a format that STAMP can read:
biom_to_stamp.py -m taxonomy seqtab_tax_rarified.biom > seqtab_tax_rarified.spf
If you take a look at this file with less you'll see that it's just a simple tab-delimited table.
Now we're ready to open up STAMP, which you can either do by typing STAMP on the command-line or by clicking the side-bar icon indicated below.
To load data into STAMP click "File" and then "Load data..." as indicated below.

Load seqtab_tax_rarified.spf as the Profile file and map.txt as the Group metadata file.
Change the Group field to "Source" and the profile level to "Level_6" (which corresponds to the genus level). Change the heading from "Multiple groups" to "Two groups". The statistical test to "Welch's t-test" and the multiple test correction to "Benjamini-Hochberg FDR" (as shown below).

Change the plot type to "Boxplot".
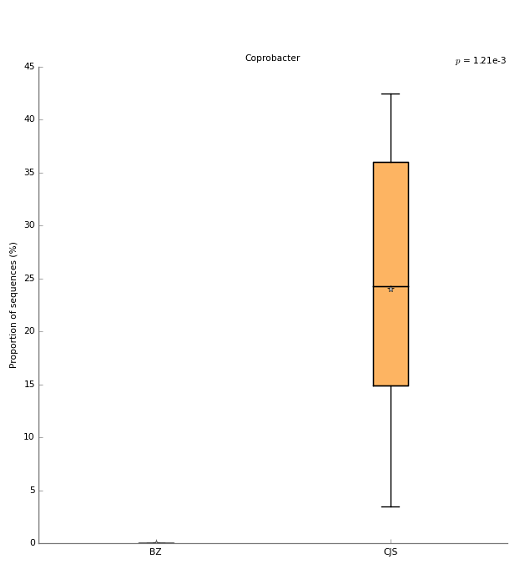
Only one genus differs between the two source facilities: Coprobacter. The boxplots of relative abundance between source facilities is shown below.