Deploy
在Kubernetes-ansible目录里
运行ansible-playbook 01-setup.yml
该步骤会设置基础设置+安装时间同步并重启生效,有些系统自带dnsmasq,这里出现Could not find rhe request service dnsmasq忽略。喜欢测试最新内核的人可以带上 -e 'kernel=true'会升级到最新的内核。
如果出现某台机器yum出错可以单独ansible-playbook 01-setup.yml -e run=xxx.xxx.xxx.xxx
执行完后再连上去在剧本目录运行ansible all -m shell -a date看看连通性和时间是否一致,时间不一致则检查chrony服务
运行ansible-playbook 02-docker.yml
根据group_vars/all.yml里docker.version从aliyun使用yum模块安装docker-ce,如果出现错误可以再来一次,单独为某个节点安装可以运行ansible-playbook 02-docker.yml -e 'run=172.16.1.10',这个也可以为非k8s以外的机器安装docker。如果机器的docker服务在运行会不安装docker,仅仅配置配置+重启,想强制升级带上'-e force=true'
1.14-1.15,<1.16.3的版本使用19.03.3以下docker且cg驱动为systemd因为runc报错耗cpu和内存,该bug在19.03.3+修复,如果是低版本的docker,可以升级docker后再升级下containerd.io版本
$ rpm -qa | grep containerd.io
containerd.io-1.2.10-3.2.el7.x86_64
- 这步不是剧本,手动运行
bash 03-get-binaries.sh all: 通过docker下载k8s和etcd的二进制文件还有cni插件,觉得不信任可以自己其他方式下载。 - cni压缩包放剧本目录,二进制文件放/usr/local/bin/
- 如果是运行剧本机器不是第一个master节点,可以利用上面02的
-e 'run=localhost'安装完docker后运行此步下载 - 想下载同大版本内的小版本号则更改脚本里的版本号
运行ansible-playbook 04-tls.yml
生成证书和管理组件的kubeconfig,kubeconfig生成依赖kubectl命令,此步确保已经下载有kubectl.
运行ansible-playbook 05-etcd.yml
部署etcd,etcd可以非master上跑,按照格式设置好ansible的hosts文件即可. 另外要注意3.3开始配置文件里的auto-compaction-retention值类型从int更改为string了。
生成alias别名脚本存放在目录/etc/profile.d/etcd.sh,命令为etcd_v2和etcd_v3方便操作etcd,etcd成员机器上的脚本目录有etcd_cron.sh备份脚本生成。可以复制相关证书在etcd以外的机器上去备份,用法-c保留几个备份,-d指定备份目录
查看集群状态
. /etc/profile.d/etcd.sh
etcd-ha #下面输出
+--------------------------+------------------+---------+---------+-----------+-----------+------------+
| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | RAFT TERM | RAFT INDEX |
+--------------------------+------------------+---------+---------+-----------+-----------+------------+
| https://172.16.1.3:2379 | 81b2beed0aa11c91 | 3.3.15 | 803 kB | true | 5 | 132579 |
| https://172.16.1.4:2379 | 7b298ca15aa8c6e | 3.3.15 | 807 kB | false | 5 | 132579 |
| https://172.16.1.5:2379 | c78674ed122263b6 | 3.3.15 | 815 kB | false | 5 | 132579 |
+--------------------------+------------------+---------+---------+-----------+-----------+------------+
运行ansible-playbook 06-HA.yml
keepalived+haproxy, haproxy七层去check apiserver, 四层代理+VIP来高可用 https://zhangguanzhang.github.io/2019/03/11/k8s-ha/
运行ansible-playbook 07-master.yml
- master管理组件,这步会出现带有
...ignoring报错请忽略,执行完运行下kubectl get cs有输出就不用管。 - 另外v1.14.x与v1.15.x有个已知bug不影响使用,见 https://zhangguanzhang.github.io/2019/10/21/k8s-v1.14-v1.15-fix-issue/
- v1.16目前到在get cs显示
unkown是官方废弃的, 不影响使用,废弃后在大家呼吁下又在1.17版本回来了。非1.16版本cs是有status的
$ kubectl get cs
NAME STATUS MESSAGE ERROR
controller-manager Healthy ok
scheduler Healthy ok
etcd-2 Healthy {"health": "true"}
etcd-1 Healthy {"health": "true"}
etcd-0 Healthy {"health": "true"}
运行ansible-playbook 08-bootstrap.yml
生成bootstrap文件给kubelet注册用
运行ansible-playbook 09-node.yml
kubelet,执行完后看看kubectl get node有没有(notReady为正常),没有就debug,如何debug见 https://github.com/zhangguanzhang/Kubernetes-ansible/wiki/systemctl-running-debug
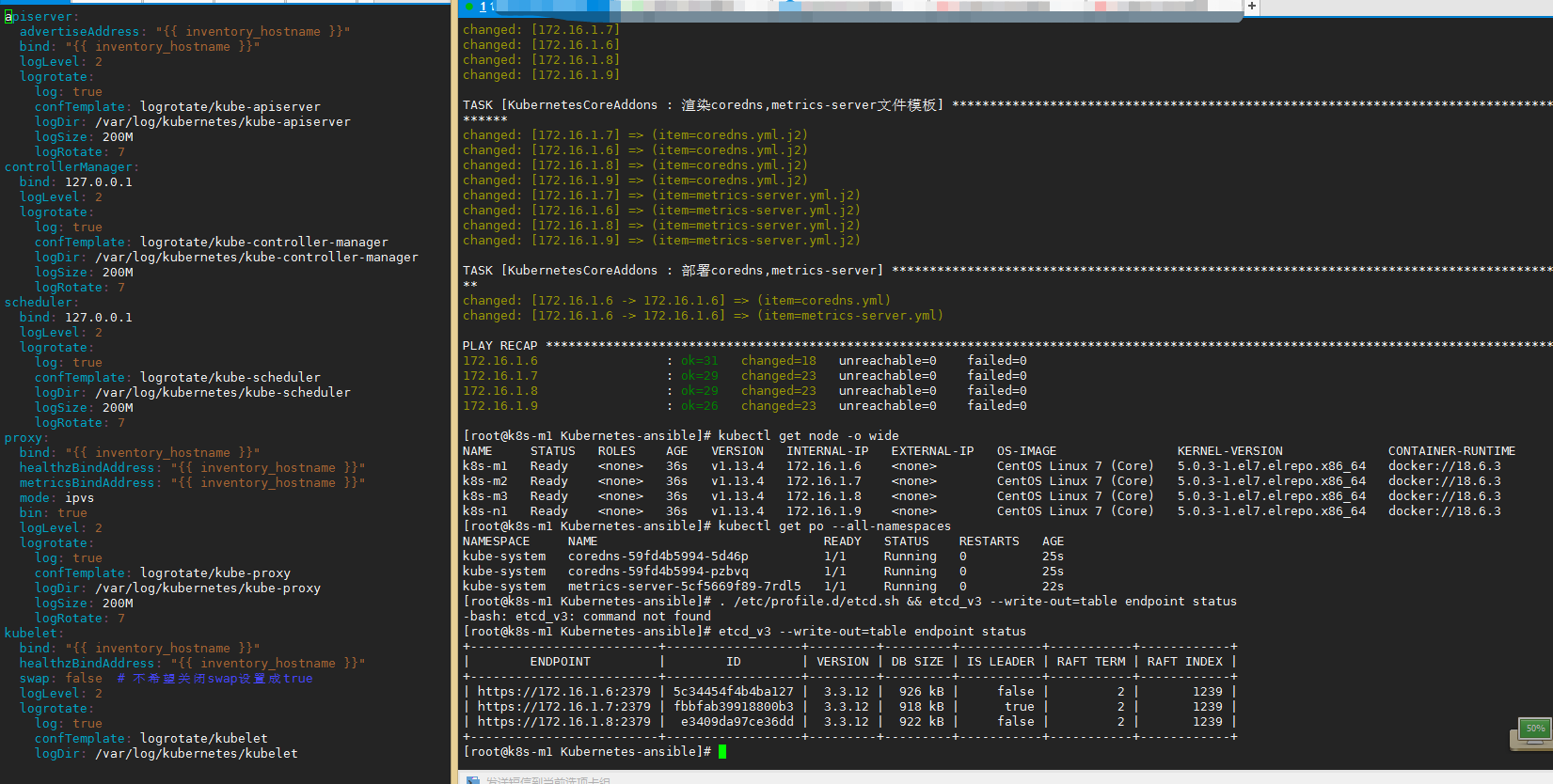
运行ansible-playbook 10-addon.yml
此步部署kube-proxy,flannel,coredns,metrics-server。如果flannel二进制跑请确保运行前已经下载了flannel的二进制文件,03步骤那已经下载过了,如果单独下载使用bash 03-get-binaries.sh flanneld,如果flannel使用daemonset的话提前拉取镜像使用命令拉取ansible Allnode -m shell -a 'curl -s https://zhangguanzhang.github.io/bash/pull.sh | bash -s -- quay.io/coreos/flannel:v0.11.0-amd64', flanneld错误的话请把debug的错误信息提交到issue里
确保coredns的pod running了后,测试下
time curl -I 10.96.0.10:9153/metrics如果是real 1m3秒的话请查看文章 https://zhangguanzhang.github.io/2020/05/23/k8s-vxlan-63-timeout/ 或者使用v1.18.6, v1.16.13, v1.17.9以上的kube-proxy试下
- 运行完01和02以及
03-get-binaries.sh后执行ansible-playbook deploy.yml
不想master跑一般pod可以按照输出的命令打污点
kubectl taint nodes ${master_node_name} node-role.kubernetes.io/master="":NoSchedule
master的ROLES字段默认是none,它显示的值是来源于一个label
kubectl label node ${master_node_name} node-role.kubernetes.io/master=""
kubectl label node ${node_name} node-role.kubernetes.io/node=""
kubelet初次会在flannel或者calico没起来前报错Container runtime network not ready,忽略即可
- 在当前的ansible目录改hosts,添加[newNode]分组写上成员和信息,role是复用的,所以不要在此时修改一些标志位参数,例如flanneld.type和bin
- 执行
ansible-playbook setup.yml -e 'run=newNode', 然后等待重启完可以ping通后执行ansible-playbook addNode.yml - 然后查看是否添加上
$ kubectl get node -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
k8s-m1 Ready <none> 28m v1.13.11 172.16.1.3 <none> CentOS Linux 7 (Core) 5.0.3-1.el7.elrepo.x86_64 docker://18.6.3
k8s-m2 Ready <none> 28m v1.13.11 172.16.1.4 <none> CentOS Linux 7 (Core) 5.0.3-1.el7.elrepo.x86_64 docker://18.6.3
k8s-m3 Ready <none> 28m v1.13.11 172.16.1.5 <none> CentOS Linux 7 (Core) 5.0.3-1.el7.elrepo.x86_64 docker://18.6.3
k8s-n1 Ready <none> 28m v1.13.11 172.16.1.6 <none> CentOS Linux 7 (Core) 5.0.3-1.el7.elrepo.x86_64 docker://18.6.3
k8s-n2 Ready <none> 6s v1.13.11 172.16.1.7 <none> CentOS Linux 7 (Core) 5.0.3-1.el7.elrepo.x86_64 docker://18.6.3
把etcdctl和证书复制了单独一台机器上就可以外部操作和备份集群了,etcd备份利用命令: etcd_v3 snapshot save test.db
恢复备份执行ansible-playbook restoreETCD.yml -e 'db=/root/Kubernetes-ansible/test.db',db指定db文件在剧本机器的路径,etcd_v3 --write-out=table endpoint status查看状态
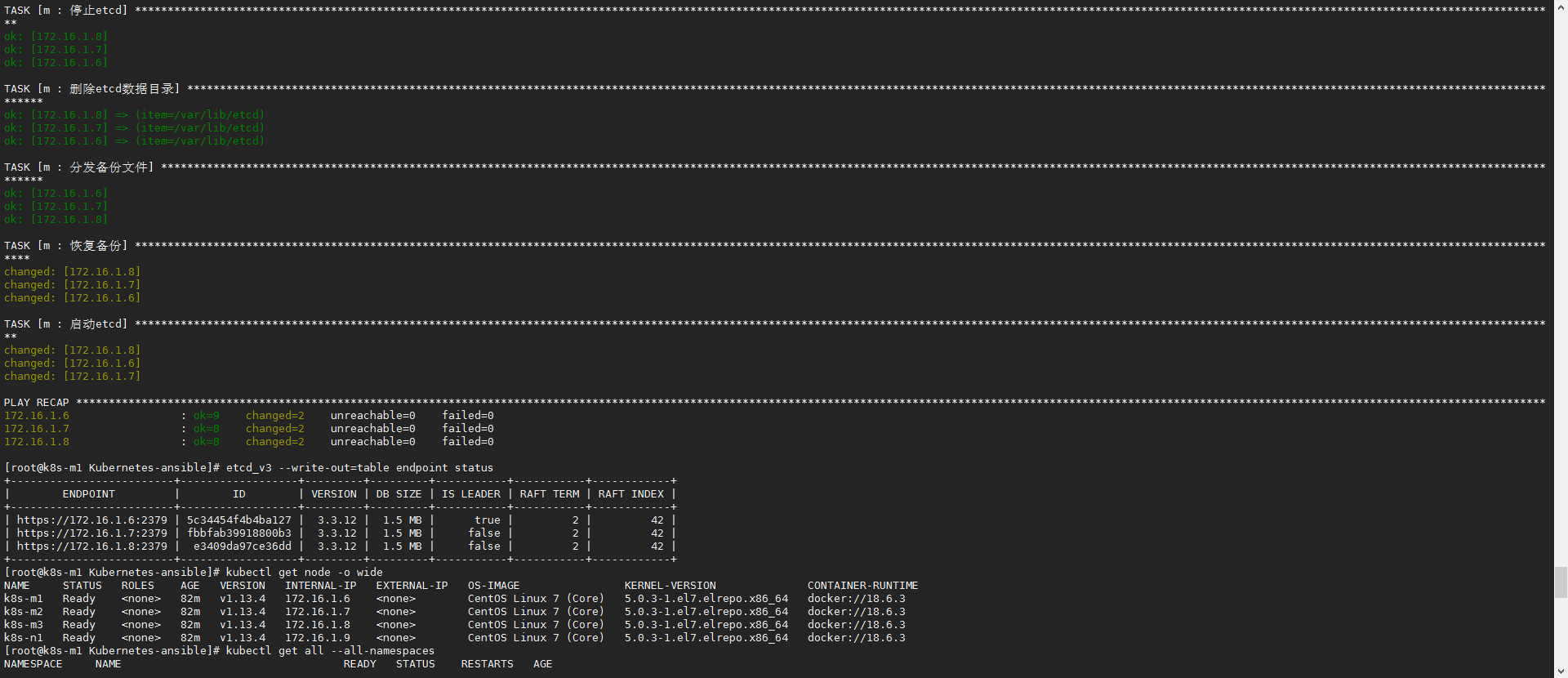
- 如果单台机器恢复记得把文件
restoreETCD.yml的hosts改成机器的ip - 如果maser是etcd,文件
roles/restoreETCD/tasks/main.yml的groups['etcd']改成groups['master']
ca文件还在就能增加,增加的时候可能会有空窗期,理论上我写成滚动了,但是会丢一些apiserver的session,没事不要尝试扩master
Master下面子组取消newMaster的注释,newMaster组取消注释填上信息,然后执行ansible-playbook preRedo.yml设置新机器的系统设置,然后执行ansible-playbook redo.yml
步骤是检查ca文件存在否,设置新机器系统设置重启,然后安装docker和剧本复用生成证书发送证书,滚动重启进程
后面的一些Extraaddon后续更新(当然也别等我更新,集群到node那了所谓的coredns和flannel后就可以用可以去找官方的addon部署)