this project is designed using three drivers
- ' m1 ' the Api
- ' m2 ' the BackServer
- PostgreDB hosted on cloud database as a service ElephantSql
You can find the live demo of the Project here .
first the api should receive a get request with the name of the category as an input and some other options
then the api will make some calculations and send a post request to the BackServer including the name and the options required for that server to operate properly,
the second server then will make requests back to the yellow pages website crawling all the pages of specific category through multiple or one thread as specified from the Api post request,
after processing the responses came, if the Api requested storing data this server would send the request and after it will continue background calculations to store the results into the PostgreDB
-
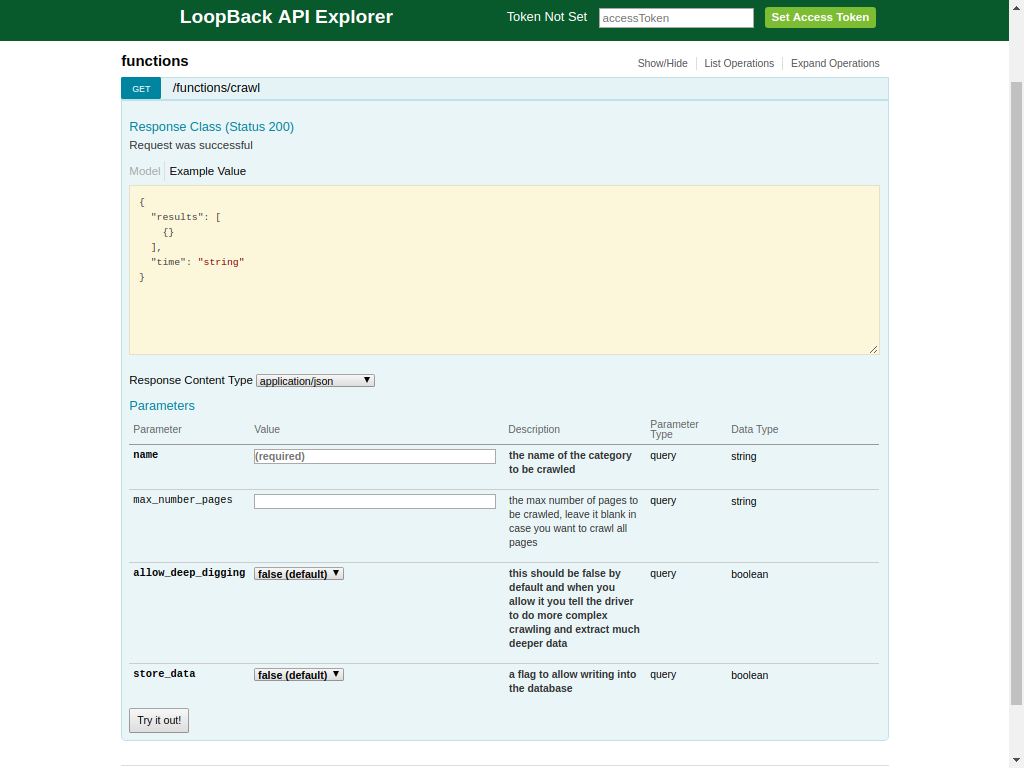
this model is responsible for the crawling and different options that should be sent to the second machine
- name: the name of the category to be crawled.
- max_number_pages: the max number of pages to be crawled, leave it blank in case you want to crawl all pages
- allow_deep_digging: this should be false by default and when you allow it you tell the driver to do more complex crawling and extract much deeper data.
- store_data: a flag to allow writing into the database.
This call could takes much time relatively to the nubmer of pages that certain category has and the deep_digging option specified in the Api call, for example a search for fast food category with the deep_digging option set to true take from 40s to 59s, so please be patient :smiley
-
this model is responsible for dealing with the database from the user perspective
-
ElephantSql@ElephantSql.com: ElephantSQL automates every part of setup and running of PostgreSQL clusters. Available on all major cloud and application platforms all over the world. ElephantSQL is offered by a small but stable, committed and hardworking team from Sweden. With 20,000+ running databases and several years of DBA PostgreSQL experience, we can help you with all questions you might have concerning your DB. Customers like Mr. Cooper, Blendle, and Cambridge Assessment just to mention a few, are feeling safe with us managing their DBs.
-
LoopBack@LoopBack.com: LoopBack is a highly-extensible, open-source Node.js framework that enables you to:
- Create dynamic end-to-end REST APIs with little or no coding.
- Access data from Oracle, MySQL, PostgreSQL, MS SQL Server, MongoDB, SOAP and other REST APIs.
- Incorporate model relationships and access controls for complex APIs.
- Use built-in push, geolocation, and file services for mobile apps.
- Easily create client apps using Android, iOS, and JavaScript SDKs.
- Run your application on-premises or in the cloud.
-
Express.js@Express.js.com:The Express philosophy is to provide small, robust tooling for HTTP servers, making it a great solution for single page applications, web sites, hybrids, or public HTTP APIs. Express does not force you to use any specific ORM or template engine. With support for over 14 template engines via Consolidate.js, you can quickly craft your perfect framework.
-
cheerio@cheerio.com: Cheerio parses markup and provides an API for traversing/manipulating the resulting data structure. It does not interpret the result as a web browser does. Specifically, it does not produce a visual rendering, apply CSS, load external resources, or execute JavaScript. If your use case requires any of this functionality, you should consider projects like PhantomJS or JSDom.
-
axios@axios.com: Promise based HTTP client for the browser and node.js.
-
node-postgres@node-postgres.com: Non-blocking PostgreSQL client for node.js. Pure JavaScript and optional native libpq bindings.
-
worker-farm@worker-farm.com: Distribute processing tasks to child processes with an über-simple API and baked-in durability & custom concurrency options. Available in npm as worker-farm.
-
body-parser@body-parser.com: Parse incoming request bodies in a middleware before your handlers, available under the req.body property.
-
Heroku@Heroku.com: Heroku is a platform as a service (PaaS) that enables developers to build, run, and operate applications entirely in the cloud.
- yellow pages@yellow pages.com