
- 🔥 Meet xDiT
- 📢 Updates
- 🎯 Supported DiTs
- 📈 Performance
- 🚀 QuickStart
- 🖼️ ComfyUI with xDiT
- ✨ xDiT's Arsenal
- 📚 Develop Guide
- 🚧 History and Looking for Contributions
- 📝 Cite Us
Diffusion Transformers (DiTs) are driving advancements in high-quality image and video generation. With the escalating input context length in DiTs, the computational demand of the Attention mechanism grows quadratically! Consequently, multi-GPU and multi-machine deployments are essential to meet the real-time requirements in online services.
To meet real-time demand for DiTs applications, parallel inference is a must. xDiT is an inference engine designed for the parallel deployment of DiTs on a large scale. xDiT provides a suite of efficient parallel approaches for Diffusion Models, as well as computation accelerations.
The overview of xDiT is shown as follows.
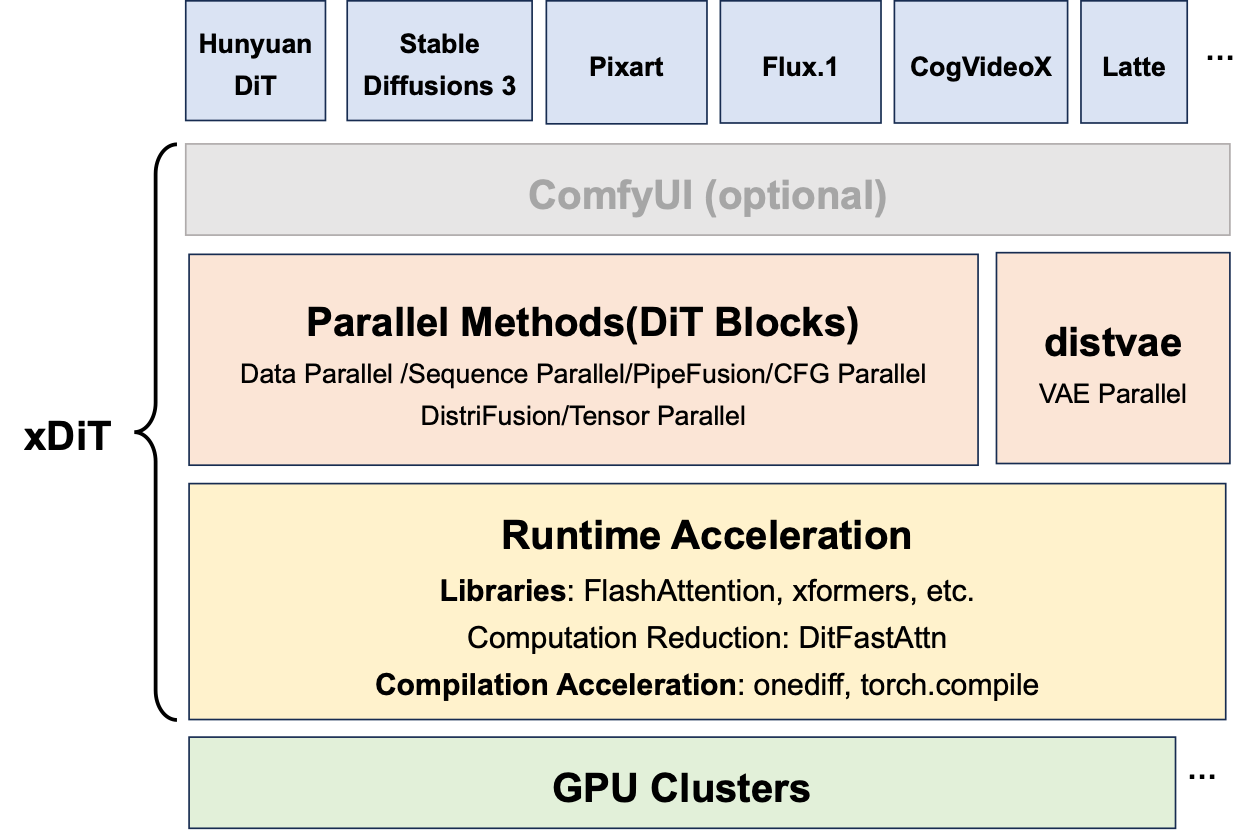
-
Sequence Parallelism, USP is a unified sequence parallel approach proposed by us combining DeepSpeed-Ulysses, Ring-Attention.
-
PipeFusion, a sequence-level pipeline parallelism, similar to TeraPipe but takes advantage of the input temporal redundancy characteristics of diffusion models.
-
Data Parallel: Processes multiple prompts or generates multiple images from a single prompt in parallel across images.
-
CFG Parallel, also known as Split Batch: Activates when using classifier-free guidance (CFG) with a constant parallelism of 2.
The four parallel methods in xDiT can be configured in a hybrid manner, optimizing communication patterns to best suit the underlying network hardware.
As shown in the following picture, xDiT offers a set of APIs to adapt DiT models in huggingface/diffusers to hybrid parallel implementation through simple wrappers. If the model you require is not available in the model zoo, developing it by yourself is not so difficult; please refer to our Dev Guide.
We also have implemented the following parallel strategies for reference:
- Tensor Parallelism
- DistriFusion
Optimization is orthogonal to parallel and focuses on accelerating performance on a single GPU.
First, xDiT employs a series of kernel acceleration methods. In addition to utilizing well-known Attention optimization libraries, we leverage compilation acceleration technologies such as torch.compile and onediff.
Furthermore, xDiT incorporates optimization techniques from DiTFastAttn, which exploits computational redundancies between different steps of the Diffusion Model to accelerate inference on a single GPU.
- 🎉December 7, 2024: xDiT is the official parallel inference engine for HunyuanVideo, reducing the 5-sec video generation latency from 31 minutes to 5 minutes on 8xH100!
- 🎉November 28, 2024: xDiT achieves 1.6 sec end-to-end latency for 28-step Flux.1-Dev inference on 4xH100!
- 🎉November 20, 2024: xDiT supports CogVideoX-1.5 and achieved 6.12x speedup compare to the implementation in diffusers!
- 🎉November 11, 2024: xDiT has been applied to mochi-1 and achieved 3.54x speedup compare to the official open source implementation!
- 🎉October 10, 2024: xDiT applied DiTFastAttn to accelerate single GPU inference for Pixart Models!
- 🎉September 26, 2024: xDiT has been officially used by THUDM/CogVideo! The inference scripts are placed in parallel_inference/ at their repository.
- 🎉September 23, 2024: Support CogVideoX. The inference scripts are examples/cogvideox_example.py.
- 🎉August 26, 2024: We apply torch.compile and onediff nexfort backend to accelerate GPU kernels speed.
- 🎉August 15, 2024: Support Hunyuan-DiT hybrid parallel version. The inference scripts are examples/hunyuandit_example.py.
- 🎉August 9, 2024: Support Latte sequence parallel version. The inference scripts are examples/latte_example.py.
- 🎉August 8, 2024: Support Flux sequence parallel version. The inference scripts are examples/flux_example.py.
- 🎉August 2, 2024: Support Stable Diffusion 3 hybrid parallel version. The inference scripts are examples/sd3_example.py.
- 🎉July 18, 2024: Support PixArt-Sigma and PixArt-Alpha. The inference scripts are examples/pixartsigma_example.py, examples/pixartalpha_example.py.
- 🎉July 17, 2024: Rename the project to xDiT. The project has evolved from a collection of parallel methods into a unified inference framework and supported the hybrid parallel for DiTs.
- 🎉May 24, 2024: PipeFusion is public released. It supports PixArt-alpha scripts/pixart_example.py, DiT scripts/ditxl_example.py and SDXL scripts/sdxl_example.py. This version is currently in the
legacybranch.
| Model Name | CFG | SP | PipeFusion |
|---|---|---|---|
| 🎬 HunyuanVideo | NA | ✔️ | ❎ |
| 🎬 CogVideoX1.5 | ✔️ | ✔️ | ❎ |
| 🎬 Mochi-1 | ✔️ | ✔️ | ❎ |
| 🎬 CogVideoX | ✔️ | ✔️ | ❎ |
| 🎬 Latte | ❎ | ✔️ | ❎ |
| 🔵 HunyuanDiT-v1.2-Diffusers | ✔️ | ✔️ | ✔️ |
| 🟠 Flux | NA | ✔️ | ✔️ |
| 🔴 PixArt-Sigma | ✔️ | ✔️ | ✔️ |
| 🟢 PixArt-alpha | ✔️ | ✔️ | ✔️ |
| 🟠 Stable Diffusion 3 | ✔️ | ✔️ | ✔️ |
Supported by legacy version only, including DistriFusion and Tensor Parallel as the standalone parallel strategies:
ComfyUI, is the most popular web-based Diffusion Model interface optimized for workflow. It provides users with a UI platform for image generation, supporting plugins like LoRA, ControlNet, and IPAdaptor. Yet, its design for native single-GPU usage leaves it struggling with the demands of today’s large DiTs, resulting in unacceptably high latency for users like Flux.1.
Using our commercial project TACO-DiT, a SaaS build on xDiT, we’ve successfully implemented a multi-GPU parallel processing workflow within ComfyUI, effectively addressing Flux.1’s performance challenges. Below is the example of using TACO-DiT to accelerate a Flux workflow with LoRA:
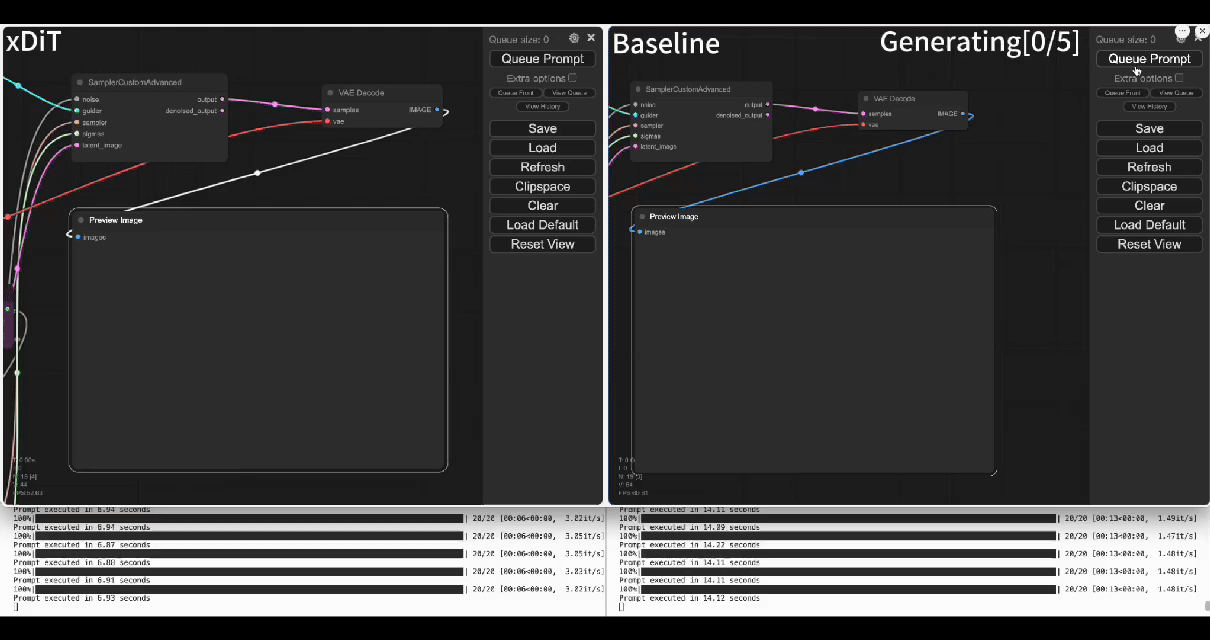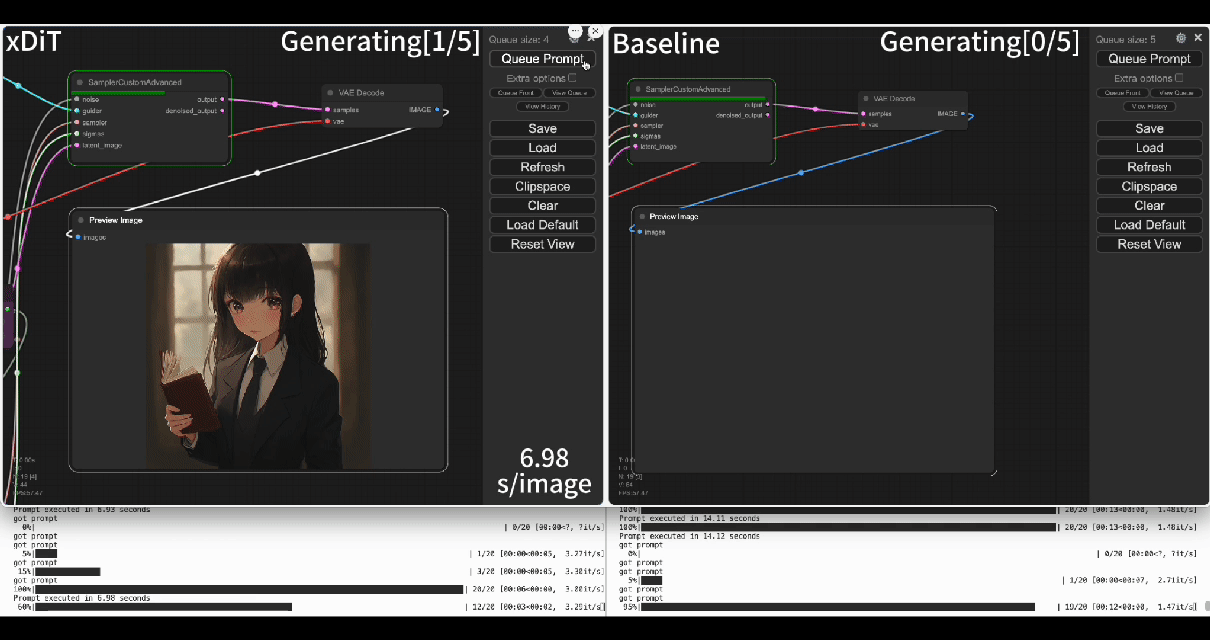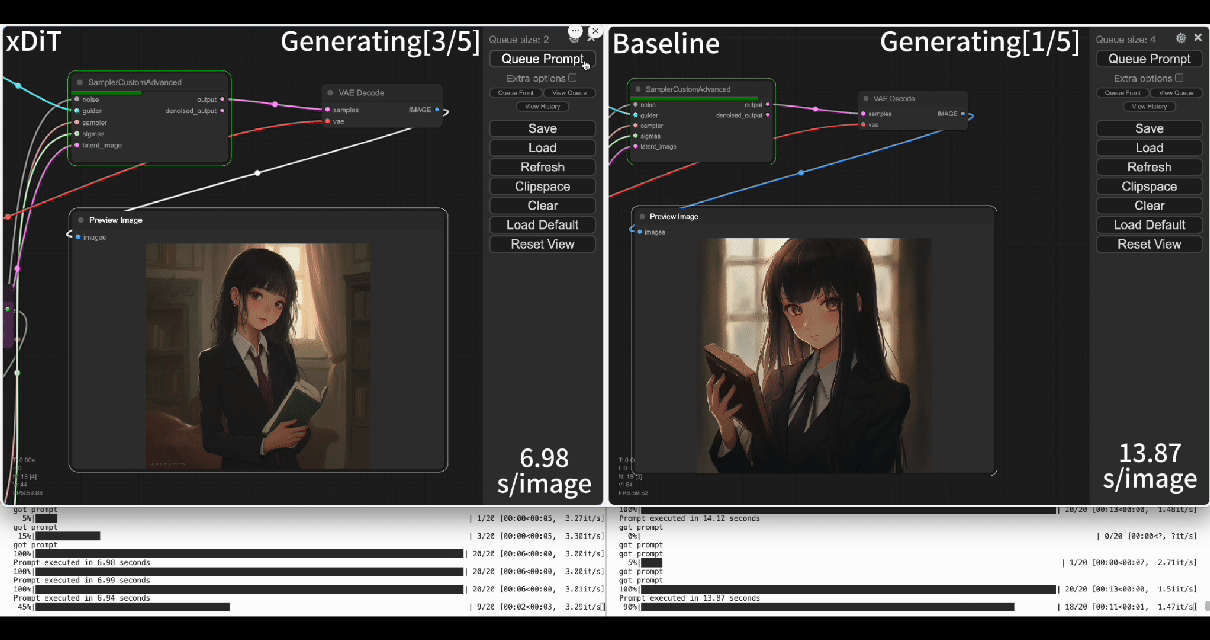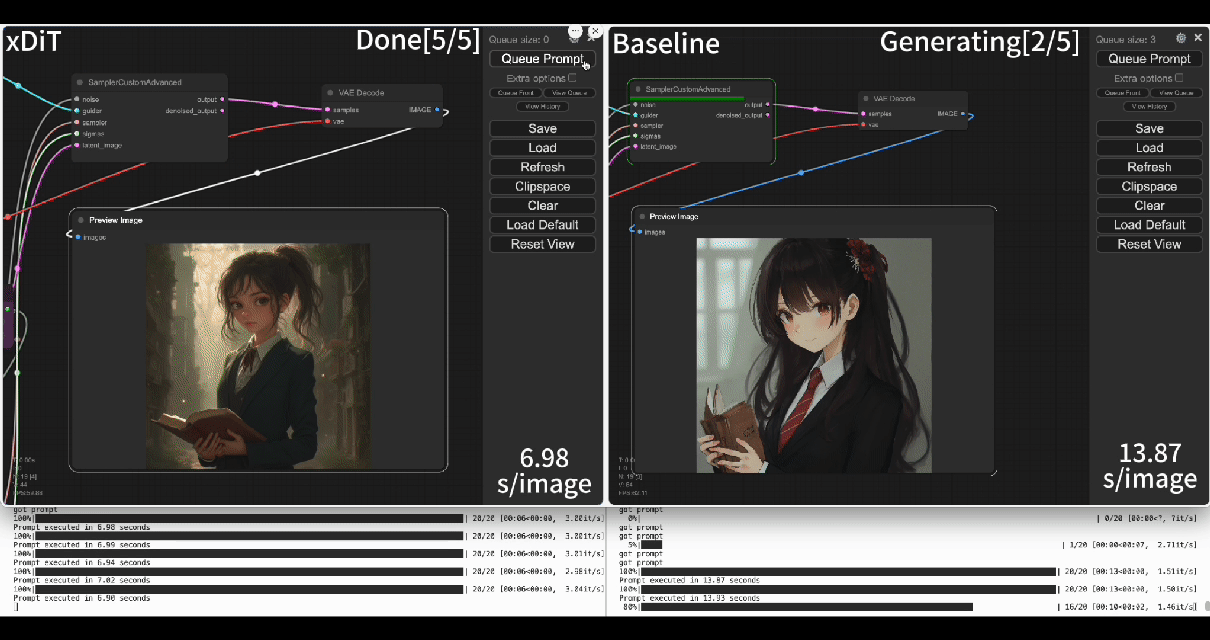
By using TACO-DiT, you could significantly reduce your ComfyUI workflow inference latency, and boosting the throughput with Multi-GPUs. Now it is compatible with multiple Plug-ins, including Controlnet and loras.
More features and details can be found in our Intro Video:
- [YouTube] TACO-DiT: Accelerating Your ComfyUI Generation Experience
- [Bilibili] TACO-DiT: 加速你的ComfyUI生成体验
The blog article is also available: Supercharge Your AIGC Experience: Leverage xDiT for Multiple GPU Parallel in ComfyUI Flux.1 Workflow.
Currently, if you need the parallel version of ComfyUI, please fill in this application form or contact [email protected].
We set diffusers as an optional installation requirement. First, if you only use the USP interface, you don't need to install diffusers. Second, different models have different requirements for diffusers - for example, the latest models may need to be installed from the diffusers main branch.
pip install xfuser
# Or optionally, with diffusers
pip install "xfuser[diffusers]"
pip install -e .
# Or optionally, with diffusers
pip install -e ".[diffusers]"
Note that we use two self-maintained packages:
The flash_attn used for yunchang should be >= 2.6.0
We provide a docker image for developers to develop with xDiT. The docker image is thufeifeibear/xdit-dev.
We provide examples demonstrating how to run models with xDiT in the ./examples/ directory. You can easily modify the model type, model directory, and parallel options in the examples/run.sh within the script to run some already supported DiT models.
bash examples/run.shHybriding multiple parallelism techniques togather is essential for efficiently scaling. It's important that the product of all parallel degrees matches the number of devices. Note use_cfg_parallel means cfg_parallel=2. For instance, you can combine CFG, PipeFusion, and sequence parallelism with the command below to generate an image of a cute dog through hybrid parallelism. Here ulysses_degree * pipefusion_parallel_degree * cfg_degree(use_cfg_parallel) == number of devices == 8.
torchrun --nproc_per_node=8 \
examples/pixartalpha_example.py \
--model models/PixArt-XL-2-1024-MS \
--pipefusion_parallel_degree 2 \
--ulysses_degree 2 \
--num_inference_steps 20 \
--warmup_steps 0 \
--prompt "A cute dog" \
--use_cfg_parallelwarmup_steps, also required in DistriFusion, typically set to a small number compared with num_inference_steps.
The warmup step impacts the efficiency of PipeFusion as it cannot be executed in parallel, thus degrading to a serial execution.
We observed that a warmup of 0 had no effect on the PixArt model.
Users can tune this value according to their specific tasks.
You can also launch an HTTP service to generate images with xDiT.
Launching a Text-to-Image Http Service
We provide different difficulty levels for adding new models, please refer to the following tutorial.
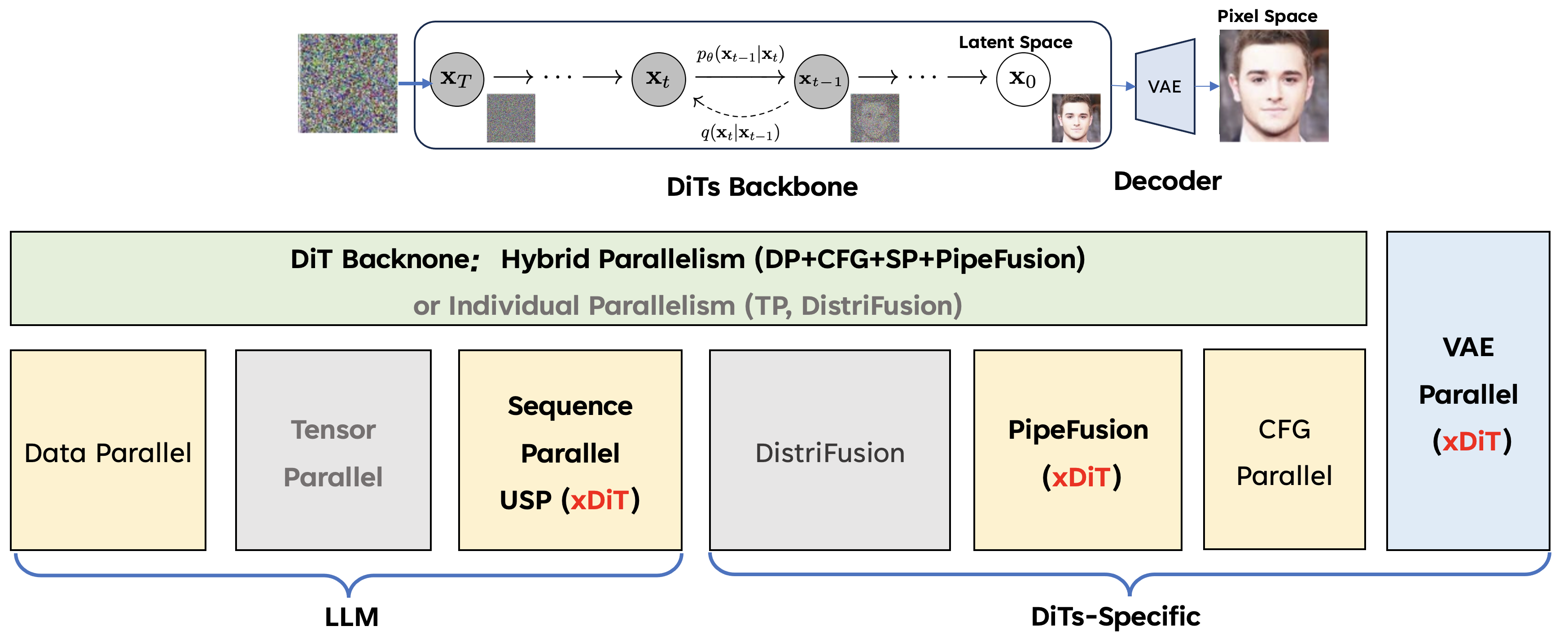
A high-level design of xDiT framework is provided below, which may help you understand the xDiT framework.
The implement and design of xdit framework
The remarkable performance of xDiT is attributed to two key facets. Firstly, it leverages parallelization techniques, pioneering innovations such as USP, PipeFusion, and hybrid parallelism, to scale DiTs inference to unprecedented scales.
Secondly, we employ compilation technologies to enhance execution on GPUs, integrating established solutions like torch.compile and onediff to optimize xDiT's performance.
As illustrated in the accompanying images, xDiTs offer a comprehensive set of parallelization techniques. For the DiT backbone, the foundational methods—Data, USP, PipeFusion, and CFG parallel—operate in a hybrid fashion. Additionally, the distinct methods, Tensor and DistriFusion parallel, function independently. For the VAE module, xDiT offers a parallel implementation, DistVAE, designed to prevent out-of-memory (OOM) issues. The (xDiT) highlights the methods first proposed by use.
The communication and memory costs associated with the aforementioned intra-image parallelism, except for the CFG and DP (they are inter-image parallel), in DiTs are detailed in the table below. (* denotes that communication can be overlapped with computation.)
As we can see, PipeFusion and Sequence Parallel achieve lowest communication cost on different scales and hardware configurations, making them suitable foundational components for a hybrid approach.
𝒑: Number of pixels;
𝒉𝒔: Model hidden size;
𝑳: Number of model layers;
𝑷: Total model parameters;
𝑵: Number of parallel devices;
𝑴: Number of patch splits;
𝑸𝑶: Query and Output parameter count;
𝑲𝑽: KV Activation parameter count;
𝑨 = 𝑸 = 𝑶 = 𝑲 = 𝑽: Equal parameters for Attention, Query, Output, Key, and Value;
| attn-KV | communication cost | param memory | activations memory | extra buff memory | |
|---|---|---|---|---|---|
| Tensor Parallel | fresh | ||||
| DistriFusion* | stale | ||||
| Ring Sequence Parallel* | fresh | ||||
| Ulysses Sequence Parallel | fresh | ||||
| PipeFusion* | stale- |
PipeFusion: Displaced Patch Pipeline Parallelism for Diffusion Models
USP: A Unified Sequence Parallelism Approach for Long Context Generative AI
We utilize two compilation acceleration techniques, torch.compile and onediff, to enhance runtime speed on GPUs. These compilation accelerations are used in conjunction with parallelization methods.
We employ the nexfort backend of onediff. Please install it before use:
pip install onediff
pip install -U nexfort
For usage instructions, refer to the example/run.sh. Simply append --use_torch_compile or --use_onediff to your command. Note that these options are mutually exclusive, and their performance varies across different scenarios.
xDiT also provides DiTFastAttn for single GPU acceleration. It can reduce computation cost of attention layer by leveraging redundancies between different steps of the Diffusion Model.
DiTFastAttn: Attention Compression for Diffusion Transformer Models
We conducted a major upgrade of this project in August 2024, introducing a new set of APIs that are now the preferred choice for all users.
The legacy APIs are applied in early stage of xDiT to explore and compare different parallelization methods. They are located in the legacy branch, are now considered outdated and do not support hybrid parallelism. Despite this limitation, they offer a broader range of individual parallelization methods, including PipeFusion, Sequence Parallel, DistriFusion, and Tensor Parallel.
For users working with Pixart models, you can still run the examples in the scripts/ directory under the legacy branch. However, for all other models, we strongly recommend adopting the formal APIs to ensure optimal performance and compatibility.
We also warmly welcome developers to join us in enhancing the project. If you have ideas for new features or models, please share them in our issues. Your contributions are invaluable in driving the project forward and ensuring it meets the needs of the community.
xDiT: an Inference Engine for Diffusion Transformers (DiTs) with Massive Parallelism
@article{fang2024xdit,
title={xDiT: an Inference Engine for Diffusion Transformers (DiTs) with Massive Parallelism},
author={Fang, Jiarui and Pan, Jinzhe and Sun, Xibo and Li, Aoyu and Wang, Jiannan},
journal={arXiv preprint arXiv:2411.01738},
year={2024}
}
PipeFusion: Patch-level Pipeline Parallelism for Diffusion Transformers Inference
@article{fang2024pipefusion,
title={PipeFusion: Patch-level Pipeline Parallelism for Diffusion Transformers Inference},
author={Jiarui Fang and Jinzhe Pan and Jiannan Wang and Aoyu Li and Xibo Sun},
journal={arXiv preprint arXiv:2405.14430},
year={2024}
}
USP: A Unified Sequence Parallelism Approach for Long Context Generative AI
@article{fang2024unified,
title={A Unified Sequence Parallelism Approach for Long Context Generative AI},
author={Fang, Jiarui and Zhao, Shangchun},
journal={arXiv preprint arXiv:2405.07719},
year={2024}
}
Unveiling Redundancy in Diffusion Transformers (DiTs): A Systematic Study
@article{sun2024unveiling,
title={Unveiling Redundancy in Diffusion Transformers (DiTs): A Systematic Study},
author={Sun, Xibo and Fang, Jiarui and Li, Aoyu and Pan, Jinzhe},
journal={arXiv preprint arXiv:2411.13588},
year={2024}
}