{kind=link}
{kind=link}
{kind=link}
Ein Beispiel für schemalose Daten wäre bei unserem Kunden die Auslagen mit Sensoren zu versehen. Dort wird aufgenommen wie lange ein Kunde welches Handy in die Hand nimmt. Dies generiert einen Datenstrom der sehr schemalos ist.
Der Kunde meiner Firma ist eine große Telco Firma, hier könnte man die Kundendaten als schematisch ansehen. Name/Adresse etc. sind bei jedem Kunden gleich und können somit mithilfe einer Relationalen Datenbank gespeichert werden.
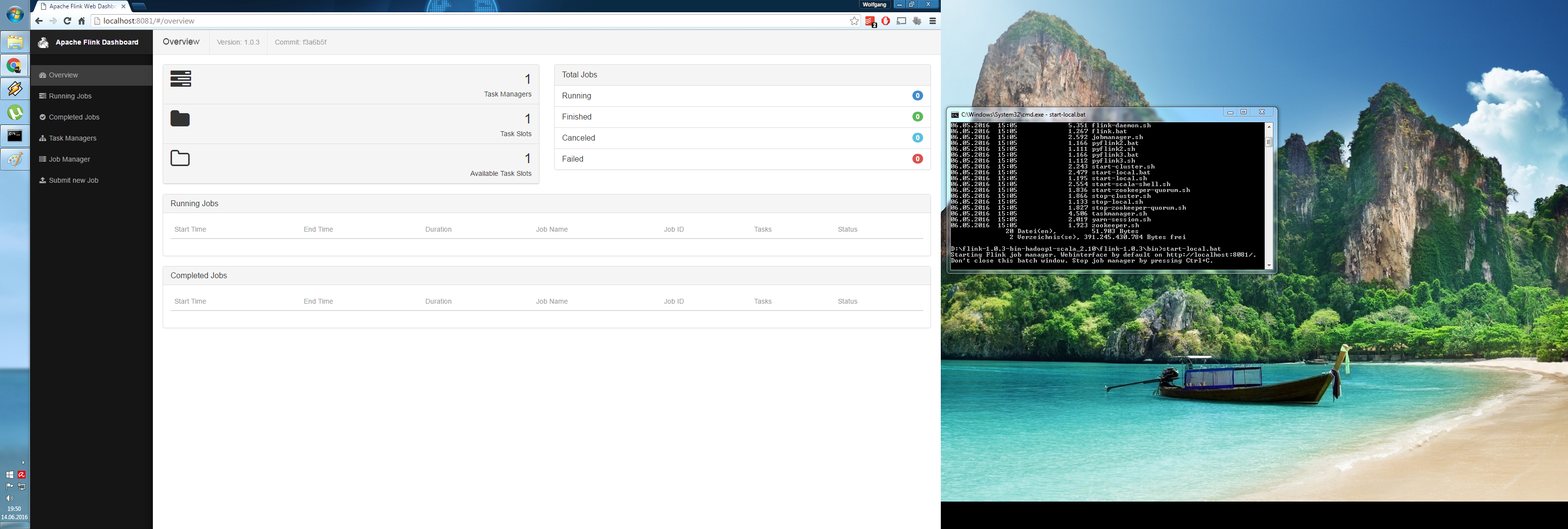
Ich habe mich für Apache Flink entschieden, da es leicht zu installieren war(siehe Screenshot) und ich Java-Entwickler bin, womit eine Entwicklung in Java einfach ist. -> https://raw.githubusercontent.com/wolfgangfuker/bld_ss2016/master/flink.png Toolchain: Eclipse Maven Hadoop
{kind=link}
Flinkintro.java can be found under https://github.com/wolfgangfuker/bld_ss2016/blob/master/src/main/java/at/wolfgangfuker/Flinkintro.java Screenshot from running code -> https://github.com/wolfgangfuker/bld_ss2016/blob/master/flink_code.png
{kind=link}
Matlab SPSS
Ich würde SPSS wählen, es ist zwar bereits in die Jahre gekommen, aber ich habe bereits Erfahrung in Statistik damit gemacht und kann somit schneller zum Arbeiten beginnen.
Ich entscheide mich für Python, da ich damit auch in der Arbeit schon in Kontakt gekommen bin. Screenshot from running code -> https://github.com/wolfgangfuker/bld_ss2016/blob/master/python.png Toolchain: Notepad++ für die Scripts
{kind=link}
- classification: Hierbei werden Daten in Zusammenhänge, Ideen etc. kategorisiert. Bsp.: Bei Amazon: Alle Sportartikel mit dem Wort "Fußball".
- regression: Wird verwendet zur Vorhersagen und Prognose von Daten. z.B.: Was kauft ein Kunde als nächstes auf Amazon.
- clusting: Wird verwendet um Cluster unter Daten zu finden. Darunter versteht man ähnliche Daten die man einer Gruppe zuordnen kann. z.B.: Hier könnte man den Amazon Warenkorb hernehmen, wo sobald man einen Artikel in den Warenkorb legt, ähnliche / zusammenhängende Artikel angeboten werden.
- dimensional: Darunter versteht man die Reduktion eines Datensatzes um ungenauen/unpassende Werte. z.B.: Bei mehreren Wetterstationen wird das Mittel genommen. Einer dieser Stationen liefert einen Fehlerwert der ein extremer Ausreißer ist, dieser wird wegreduziert.