-
Notifications
You must be signed in to change notification settings - Fork 0
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
Showing
2 changed files
with
309 additions
and
0 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,309 @@ | ||
| --- | ||
| layout: post | ||
| title: Innodb Buffer Pool | ||
| --- | ||
|
|
||
| <img src="/public/images/2024-03-05/dota2.jpeg" alt="图片名称" align=center /> | ||
|
|
||
| <br> | ||
|
|
||
| ### 简介 | ||
|
|
||
| Buffer Pool 在Innodb 实例当中通常使用了绝大多数的内存,为实例的读写page 流程进行加速,是Innodb 内核中非常重要的一个组件。其本质是用内存换磁盘io 的过程,第一次读page 的时候将磁盘page数据拷贝到内存page当中,相同page 的反复修改,只需修改内存page ,而不是再次执行读盘操作后修改。当然,Buffer Pool 需要定期的Flush page 将内存的page 数据刷回到磁盘当中,保证数据的持久化。理论上,内存越大缓存的数据越多,实例的io 操作也就越少。无穷大的内存,就不需要io。实际上,无穷大的内存是不可能的。所以,innodb 的工程实现上需要平衡用有限的内存资源,缓存尽量多的常用page,最大限度的减少io。 | ||
|
|
||
|
|
||
| <br> | ||
| ### 基本数据结构 | ||
|
|
||
|
|
||
| **buf_pool_t** 是Buffer Pool 的具体数据结构,其主要成员如下: | ||
|
|
||
| **LRU_list** 和**page_hash**是实现LRU 算法所使用的数据结构。page_hash 是一个哈希表,存放了所有使用的page ,在page 查找的时候可以迅速的找到page。LRU_list 是一个链表,维护LRU 的逻辑。 | ||
|
|
||
| **flush_list** 是脏页链表,对于page 修改之后会挂到flush_list 上。 | ||
|
|
||
| **free_list** 是空置页链表,对于新读到buffer pool 中的page 会从这个链表中获取。 | ||
|
|
||
| **chunks** 是一堆连续内存块,初始化buffer pool 的时候,会申请若干个连续内存块,从这些内存中分割出若干Buf_block_t结构体。挂到free_list 上面。 | ||
|
|
||
| ```c++ | ||
| struct buf_pool_t { | ||
| UT_LIST_BASE_NODE_T(buf_page_t) LRU; | ||
| hash_table_t *page_hash; | ||
| UT_LIST_BASE_NODE_T(buf_page_t) flush_list; | ||
| UT_LIST_BASE_NODE_T(buf_page_t) free; | ||
| buf_chunk_t *chunks; | ||
| ... | ||
| } | ||
| ``` | ||
| **buf_block_t** 是Buffer Pool 中对于Page 控制的最小单元。主要成员如下: | ||
| **buf_page_t** 存放了Page的主要控制信息,但是不包括页本身的内容。 | ||
| **byte *frame** 是Page本身的内容。 | ||
| ```c++ | ||
| /* page control block */ | ||
| struct buf_block_t { | ||
| buf_page_t page;/*page infomation*/ | ||
| byte *frame; /* 存放数据的指针 */ | ||
| } | ||
| class buf_page_t { | ||
| page_id_t id; | ||
| ib_uint32_t buf_fix_count;// 代表是否有流程正在持有这个page。读上来的时候初始化成0。buf_page_get_gen 会inc 这个值,mtr commit 的时候会dec 这个值。为0 代表读上来之后没有流程正在使用这个page。 | ||
| buf_io_fix io_fix; //代表这个page 是否在被进行io 动作(读或写)。这个page 准备读或者准备刷的时候,这个值会置成BUF_IO_READ或者BUF_IO_WRITE 状态。io 操作结束的时候会设置成BUF_IO_NONE。BUF_IO_NONE 代表这个page 没有进行任何io 操作。 | ||
| // 这里的buf_fix_count 和 io_fix 这两个状态主要的作用是减少锁判断次数。 | ||
| lsn_t newest_modification; | ||
| lsn_t oldest_modification; // 代表这个page被读上来之后最老的一次修改。读上来的时候初始化成0,mtr commit 时候,如果是第一次修改这个page就候赋值。为0 代表读上来之后没有人修改。 | ||
| ... | ||
| } | ||
| ``` | ||
|
|
||
|
|
||
|
|
||
| <br> | ||
|
|
||
|
|
||
| ### LRU实现 | ||
|
|
||
|  | ||
|
|
||
|
|
||
|
|
||
| LRU(Least Recently Used)算法记录了内部page 的访问顺序,最新访问的page 会头插到list 的最前面。以保证经常访问的page 会保持在list 当中。不常访问的page 位于list 的尾部,随着更多的page 插入。经常访问的page会逐步向list 头部移动,不常访问的page 会逐步向list 尾部移动,逐步被淘汰出list。 | ||
|
|
||
| 在Innodb 实现当中使用**buf_page_init_for_read** 把page插入到LRU list 。使用**buf_LRU_free_page** 从LRU list 中去除page。 | ||
|
|
||
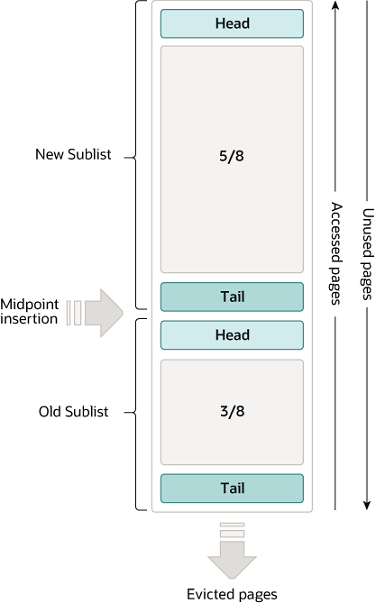
| BufferPool 的LRU list 被分为两个部分,内核当中叫young list 和 old list(官方文档上叫new sublist,old sublist,如图)。young list 占整个LRU list 长度的5/8,old list 占整个LRU list 长度的3/8。LRU list内部维护了一个指向old list 的head的指针**LRU_old**。如果从buffer pool 中读出的page是新从磁盘读入的,先头插到old list 里面。如果读出的page已经在LRU list 里面,会根据条件把这个page 向young list head 移动(**buf_page_make_young_if_needed**)。同时每次page 插入到LRU list 或者从LRU list 删除的时候,LRU_old 指针会通过**buf_LRU_old_adjust_len** 函数判断是否做相应的移动,确保其指向的位置大概在LRU总长度的后 **LRU_old_ratio (3/8)**的位置左右。为了避免频繁的移动,这里有**BUF_LRU_OLD_TOLERANCE(20)**的可容忍误差范围,**LRU_old** 在误差范围内是不移动的。 | ||
|
|
||
| 之所以把LRU list 分为两个部分是考虑如下场景,如果只有一个list,按照朴素的LRU 算法,突然有大量的读page 请求(全表扫描)把整个LRU list 全部都污染了,这些page 是最新访问的page ,但是之后很可能再也不会访问。之后的请求中,原本应该命中buffer pool 的page 被驱逐出去了,这样失去了LRU 把频繁访问的page 放到list 的本意。如果把LRU 分为两个list,大量读page 请求,会首先进入old list,不会污染young list,等到这些page 符合一定条件,再把old list 放入到young list 当中。 | ||
|
|
||
| 控制进入young list 的逻辑是**buf_page_make_young_if_needed**: | ||
|
|
||
| page 进入young list 内核当中称作make young。 | ||
| 1, 访问的page在old list里面。并且上次访问的时间已经过了大于**buf_LRU_old_threshold_ms(1000ms)** (针对的场景是一个全表扫描把buffer pool全都污染了。) | ||
| 2, 访问的page 在young list 里面。并且这个page 进入young 的时候到现在,距离LRU young head至少超过yong list 的1/4了。这时候认为这个这次问的page 有被逐出的风险,所以需要young 一下。LRU 的目的还是维护一堆频繁访问的page,只要没有evicted 风险都可以尽量不make_young.(处理的场景是特别热的page 不停的读,可能会导致不停的make_young,锁开销会影响LRU性能, 理论上的LRU每一次读page都应该make_young 这里只是为了性能考虑的工程优化。) | ||
|
|
||
|
|
||
|
|
||
|
|
||
| <br> | ||
|
|
||
| ### Buffer Pool 初始化 | ||
|
|
||
| BufferPool 在内核中为了分担锁带来的开销,将整个buffer pool分为**srv_buf_pool_instances** 个buf_pool_t 实体,每个buf_pool_t 有自己独立的list mutex。buf_pool_t 的初始化主要通过buf_chunk_t 结构初始化buf_block_t。若干个buf_chunk_t 的初始化,构成了buf_pool_t 的初始化。 | ||
|
|
||
| buf_chunk_t 初始化流程申请了一整块内存,之后在这个内存当中初始化了若干个buf_block_t 结构体,包括了buf_block_t使用内存和frame指针使用的真实内存。一个buf_chunk_t 默认大小128MB(这个是只包含8192个16k page 的大小),但实际申请内存包括了buf_page_t这个控制结构体的内存大小。具体一个chunk 的实际占用内存大小根据不同版本的buf_block_t 结构体大小而定。8.0.13 buf_block_t 结构体占用392bytes,测试看128MB 的chunk 实际申请了131MB左右的内存,多余的内存申请是8192个Buf_block_t( 392bytes) 导致。 | ||
|
|
||
| 具体的 buf_chunk_t内存分布是: | ||
|
|
||
| 3MB buf_block_t 控制信息+128MB page 内容,每一个buf_block_t 当中的frame字段指向后面分配的128MB 物理page 位置。 | ||
|
|
||
|  | ||
|
|
||
|
|
||
| <br> | ||
|
|
||
| Innodb中对于page 的修改通常会使用mini-transaction(mtr)完成,首先通过**buf_page_get_gen** 获得一个page ,加上page 的锁,记录到mtr_t 当中。随后可以对page 进行相应的修改。mtr commit 的时候调用**add_dirty_page_to_flush_list** 把mtr_t 包含的脏页全挂到flush list 上面。后台的线程会陆续把这些脏页刷回到磁盘上。 | ||
|
|
||
| <br> | ||
|
|
||
|
|
||
| ### Buffer Pool 获取Page | ||
|
|
||
|
|
||
|
|
||
| **buf_page_get_gen** 主要流程如下: | ||
|
|
||
| 1,**buf_page_hash_lock_get** 从**page_hash** 中尝试获取page。如果page 没有在LRU 当中,就调用**buf_read_page** 从盘上读上来一个page。读盘的过程当中会调用 **buf_LRU_get_free_block** 获取一个空的**buf_block_t** 的结构,初始之后放入LRU old list 当中。 | ||
|
|
||
| 2,维护LRU list 相关操作。(**buf_page_make_young_if_needed**) | ||
|
|
||
| 3,**buf_read_ahead_random/buf_read_ahead_linear** 两种预读操作。 | ||
|
|
||
| 4,**buf_block_fix** 标记page 已经被使用,并且加page 锁,记录到mtr_t 当中。 | ||
|
|
||
| ```c++ | ||
| buf_block_t* buf_page_get_gen() { | ||
| block = (buf_block_t *)buf_page_hash_get_low(buf_pool, page_id); | ||
| if (block == nullptr) { | ||
| buf_read_page(page_id, page_size); | ||
| buf_read_ahead_random(page_id, page_size, ibuf_inside(mtr)); | ||
| } | ||
| buf_block_fix(fix_block); | ||
| ... | ||
| buf_page_make_young_if_needed(&fix_block->page); | ||
| buf_read_ahead_linear(page_id, page_size, ibuf_inside(mtr)); | ||
| ... | ||
| rw_lock_s_lock_inline/rw_lock_sx_lock_inline/rw_lock_x_lock_inline; | ||
| mtr_memo_push(mtr, fix_block, fix_type); | ||
| } | ||
| ``` | ||
|
|
||
|
|
||
|
|
||
| <br> | ||
|
|
||
|
|
||
| ### Buffer Pool 预读 | ||
|
|
||
| 预读是通过当前用户请求的一些规律,使用异步读的方式,提前把需要的page 读到buffer pool 当中。主要分为两种用户使用场景下的预读,分别为**buf_read_ahead_random** 和**buf_read_ahead_linear**。 | ||
|
|
||
|
|
||
|
|
||
| **buf_read_ahead_random** 随机预读,成功读盘读到page 之后,触发随机预读。具体流程: | ||
|
|
||
| 先确定预读范围 **BUF_READ_AHEAD_AREA()**,这里指的是在什么范围内进行预读,这里默认是一个extent(1M, 64个16k page), 理论上也可以是其他的范围。 | ||
| 之后,计算这个已经读到的page_id 所在的extent 有多少是在young list里面,并且还是比较热的数据(young list 前1/4 的位置),如果这个extent中有**BUF_READ_AHEAD_RANDOM_THRESHOLD (13)**以上是热数据,就说明接下来有可能这个extent 有可能有更多的page 被读上来,所以执行预读调用**buf_read_page_low **把这个extent 中剩余的page 都预读上来。 | ||
|
|
||
|
|
||
|
|
||
| **buf_read_ahead_linear** 线性预读,这个page 第一次被读到,触发随机预读。具体流程: | ||
|
|
||
| 先确认预读范围**BUF_READ_AHEAD_AREA()**,默认是一个extent (1M, 64个16k page) | ||
| 具体流程,需要符合以下条件: | ||
|
|
||
| 1,检查这个extent 里面的一定数量(**srv_read_ahead_threshold** )page的的访问时间是不是递增的或者是递减的。 | ||
| 2,这个page是一个extent 的边缘的page id。即extent 的最小的那个page,或者最大的那个page。 | ||
| 3,通过**fil_page_get_prev** 和**fil_page_get_next **拿到的这个page 在btree 上的上一个和下一个page。这个page 的前一个page 和后一个page 的page id 也是连续的。 | ||
|
|
||
| 如果满足上面条件就调用调用buf_read_page_low把这个extent 里面的page 都预读上来。线性预读针对的还是全表扫描等类似的使用场景。 | ||
|
|
||
|
|
||
|
|
||
| ### buf_LRU_get_free_block | ||
|
|
||
| 这是buffer pool获得free block 的统一调用函数入口。其逻辑注释已经讲的比较清楚。 | ||
|
|
||
| scan LRU 看能不能取下来直接放到free list 的时候,判断page 是和否能从LRU list 上面摘掉的条件是**buf_flush_ready_for_replace**: | ||
|
|
||
| 需要以下三个条件同时满足,之后可以从LRU list 摘掉放到free list 里面。 | ||
|
|
||
| 1,bpage->oldest_modification == 0 代表读上来之后没有人修改。 | ||
|
|
||
| 2,bpage->buf_fix_count == 0 代表读上来之后没有流程正在使用这个page。 | ||
|
|
||
| 3,buf_page_get_io_fix(bpage) == BUF_IO_NONE 代表这个page 没有正在进行任何io 操作。 | ||
|
|
||
| ```c++ | ||
| /** iteration 0: | ||
| * get a block from free list, success:done | ||
| * if buf_pool->try_LRU_scan is set | ||
| * scan LRU up to srv_LRU_scan_depth to find a clean block | ||
| * the above will put the block on free list | ||
| * success:retry the free list | ||
| * flush one dirty page from tail of LRU to disk | ||
| * the above will put the block on free list | ||
| * success: retry the free list | ||
| * iteration 1: | ||
| * same as iteration 0 except: | ||
| * scan whole LRU list | ||
| * scan LRU list even if buf_pool->try_LRU_scan is not set | ||
| * iteration > 1: | ||
| * same as iteration 1 but sleep 10ms */ | ||
| buf_block_t *buf_LRU_get_free_block(buf_pool_t *buf_pool) { | ||
| buf_LRU_get_free_only(buf_pool); | ||
| buf_LRU_scan_and_free_block(buf_pool, scan_all); | ||
| buf_flush_single_page_from_LRU(buf_pool); // 单刷一个page,在buf_page_io_complete 里面摘LRU 放到free list | ||
| } | ||
|
|
||
| ibool buf_flush_ready_for_replace(buf_page_t *bpage) { | ||
| return (bpage->oldest_modification == 0 && | ||
| bpage->buf_fix_count == 0 && | ||
| buf_page_get_io_fix(bpage) == BUF_IO_NONE); | ||
| } | ||
| ``` | ||
| <br> | ||
| ### Buffer Pool 刷脏 | ||
| Buffer Pool 的刷脏 流程通常有三个场景。分别是 Batch Flush,single page flush, synchronous flush。 | ||
| Batch flush 的场景: | ||
| 最主要的Page刷盘的场景,通常page 都是通过这种方式刷回到磁盘上面。Batch flush 由后台线程Flush page coordinator线程完成, | ||
| 这个线程控制 **srv_n_page_cleaners** 个page cleaner线程周期性的把 flush_list 和 LRU_list 上面的page 调用 **buf_flush_do_batch** 函数刷回到盘上。每一次的刷脏力度由 **page_cleaner_flush_pages_recommendation** 函数控制。 | ||
| Single page flush场景: | ||
| 用户sql 执行过程当中,如果通过**buf_page_get_gen** 无法拿到free block ,**buf_LRU_get_free_block**的流程里面需要单刷1个page,调用**buf_flush_single_page_from_LRU**, 这里使用的是同步io,等io 完成之后,在**buf_page_io_complete** 里面从LRU 摘掉放到free list。 | ||
| synchronous flush 场景: | ||
| 在打checkpoint时候触发,如果当前redo 写入位置离上一次打checkpoint 的位置超过log.max_modified_age_sync, 这时候会触发 sync flush。sync flush 的流程还是触发Flush page coordinator 流程,刷脏到固定的lsn,后续还是交给page cleaner 去具体刷脏。 | ||
| 一些影响刷脏力度的参数如下: | ||
| ```c++ | ||
| innodb_io_capacity /* 系统io 次数能力 */ | ||
| innodb_io_capacity_max /* 系统io 次数的上限,innodb_io_capacity 修改不能超过这个上限。。*/ | ||
| innodb_max_dirty_pages_pct /*bp 里面允许的最大脏页百分比,超过就激烈刷脏 */ | ||
| innodb_max_dirty_pages_pct_lwm /* bp 脏页超过这个值就开始刷脏 */ | ||
| ``` | ||
|
|
||
|
|
||
|
|
||
| 每次刷脏的力度是影响Buffer Pool整体性能的关键。所以在刷脏流程中需要关注 **page_cleaner_flush_pages_recommendation**。page cleaner 会根据该函数的返回刷脏page 个数,进行实际上的page flush。 | ||
|
|
||
|
|
||
| <br> | ||
|
|
||
| ### page_cleaner_flush_pages_recommendation | ||
|
|
||
| 计算出应该刷的page 数由两个维度决定,一个是脏页个数本身,一个是由于lsn 受限需要flush 的page 个数。 | ||
|
|
||
| 这里引入了 lsn 对应的flush page 这个参数。一方面由于redo 空间有限,如果page 刷的比较少,会导致redo 空间紧张,checkpoint 不推进的问题。另一方面,是因为在修改page 很少但是修改非常频繁的场景下,只按照脏页百分比计算出的刷脏个数可能非常少,有可能导致要刷脏的page 一直刷不下去,导致checkpoint 一直打不下去。 | ||
|
|
||
| 计算公式如下: | ||
|
|
||
| ```c++ | ||
| #define PCT_IO(p) ((ulong)(srv_io_capacity * ((double)(p) / 100.0))) | ||
| n_pages = (PCT_IO(pct_total) + avg_page_rate + pages_for_lsn) / 3; | ||
| ``` | ||
| **pct_total **代表的是基于当前实例状态下,需要flush 的page 个数。**avg_page_rate**和**pages_for_lsn** 是基于实例的历史平均数据,计算出的应该flush 下去的page 个数。 | ||
| 1, **pct_total** 根据当前实例的状态,计算出当前脏页的百分比跟lsn 脏的百分比, 取两者的最大值。 | ||
| ```c++ | ||
| pct_total = ut_max(pct_for_dirty, pct_for_lsn); | ||
| ``` | ||
|
|
||
| 脏页的百分比(pct_for_dirty)由**af_get_pct_for_dirty**计算, 代表bufferpool 当中脏页比例。如果超过bp 上限的修改量**srv_max_buf_pool_modified_pct**,返回100%,并且使用上限**srv_io_capacity**,参与最终n_pages 计算。 | ||
|
|
||
| 脏的lsn 的百分比(pct_for_lsn)由**af_get_pct_for_lsn**计算。这里计算的是还没有刷下去的lsn 的距离,占总共redo 可用空间的比例。之后用这个比例,带入了一个公式得出最终百分比,公式如下: | ||
|
|
||
| ```c++ | ||
| lsn_age_factor = (age * 100) / limit_for_age; | ||
| return (static_cast<ulint>(((srv_max_io_capacity / srv_io_capacity) *(lsn_age_factor * sqrt((double)lsn_age_factor))) /7.5)); | ||
| ``` | ||
| 通过观察**pct_for_lsn = f(lsn_age_factor) **通过简单的计算,可知他的斜率是大于1的。也就是说这里未刷脏lsn 增长一点,返回的需要刷脏的page 就会成倍的增长。说明这里还是想用更激进的刷脏策略,限制未刷脏lsn 的大小。 | ||
| 2,**avg_page_rate** 计算几次batch flush 刷下去page 的平均个数。 | ||
| 3,**pages_for_lsn** 先计算几次batch flush 推进的lsn 的平均长度, 再计算如果这次flush也推进这么多lsn,对应的page 是多少。如果预估这次flush 可能推进的lsn 是A。从flush list 里面捞出oldest_modification 小于这个lsn A 的page 个数,就是估算的pages_for_lsn。 | ||
| 最终的n_pages 计算出来之后需要受**srv_max_io_capacity** 限制,最终的io 不会超过**srv_max_io_capacity** 大小。 | ||
| <br> | ||
| ### Reference | ||
| [https://github.com/mysql/mysql-server/tree/mysql-8.0.13](https://github.com/mysql/mysql-server/tree/mysql-8.0.13) | ||
| [http://mysql.taobao.org/monthly/2023/04/02/](http://mysql.taobao.org/monthly/2023/04/02/) | ||
| [http://catkang.github.io/2023/08/08/mysql-buffer-pool.html](http://catkang.github.io/2023/08/08/mysql-buffer-pool.html) | ||
| [https://dev.mysql.com/doc/refman/8.0/en/innodb-buffer-pool.html](https://dev.mysql.com/doc/refman/8.0/en/innodb-buffer-pool.html) |
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.