The following technologies where used in building the API:
- ExpressJs: ExpressJs is a web framework for Nodejs. It is used to create server-side logic in Javascript.
- Ioredis: Ioredis is a robust, full-support redis client. Redis Redis is an in-memory data store, primarily used for caching purpose due to its volatile nature.
- swagger-ui-express: This module will allow us to serve auto-generated swagger-ui generated API docs from express link here: https://www.npmjs.com/package/swagger-ui-express
- Octokit: This a GitHub REST API client for JavaScript. https://www.npmjs.com/package/@octokit/rest
Let's look at the architecture diagram first:
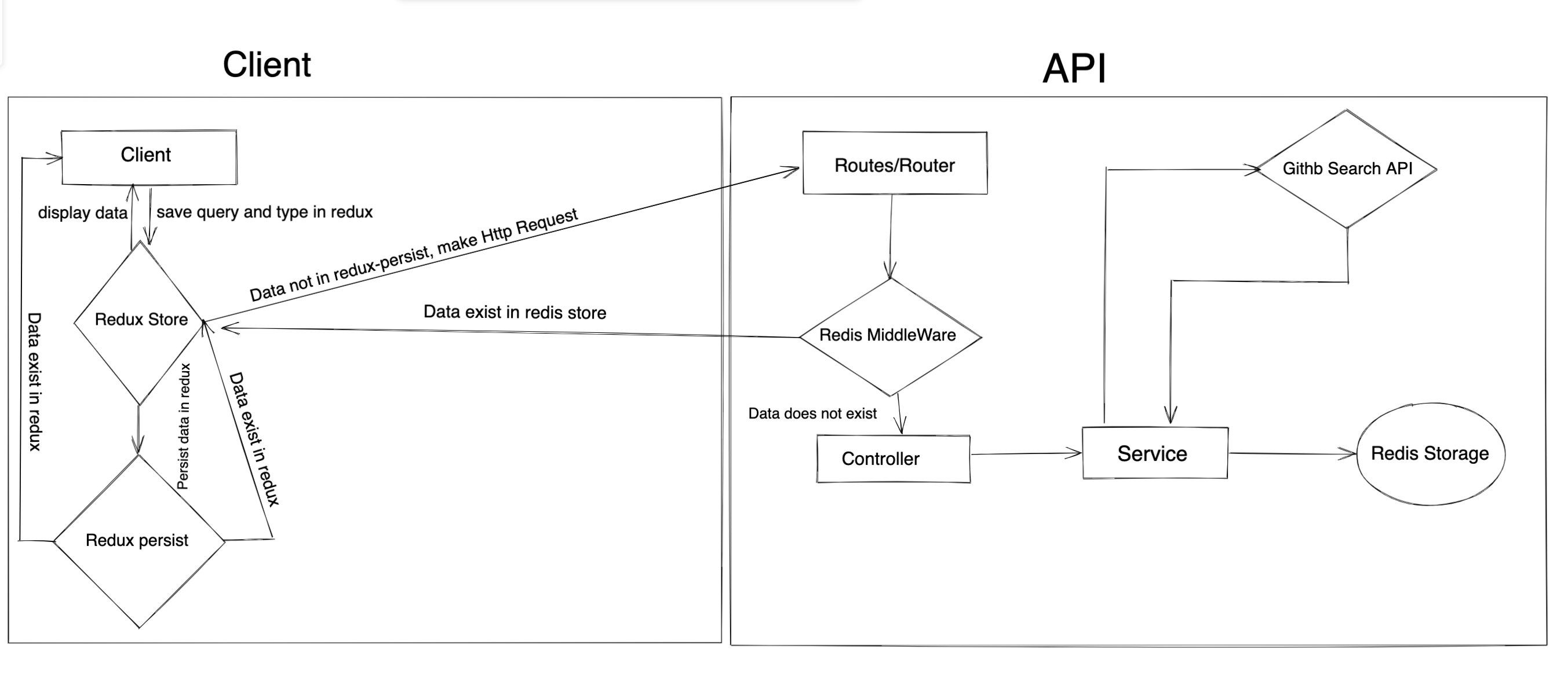
From the flow diagram above, client request for a data by posting the search query as a body. The request body is validated before it's sent to the controller which in turn calls the service to handle the business logic of getting the requested data from the external api (Github api). Once the data is returned successfully, it's cached in redis memory for two hours. Hence, when the client request for the same data, we check the redis memory for the data, if it exist we return the cached data to the client instead of making the api call.
-
Getting useful user data: Github response for users doesn't return the required user data such as the user location or number of followers. Hence to get this data, the response returns an array of objects which has a key url. This url contains the full user details. In this case, when the response returns from the API, I had to map through the returned data the get the url value and make another api call to get user. This time it returns the main user data which i concate into the initial data using a spread operator.
-
Clear cached data: Although the data cached in redis will expire within 2hours, i needed a way to clear the cached data from redis. Their are may way to go about this, which includes using the keys command in searching for all the matching keys, but the solution is not optimal for when the number of keys are large or for large applications. To solve this problem, redis has a command
scanwhich incrementally iterate through the keys in the storage. Using thescaStreammethod which accepts two optionsmatchwhich defines the pattern to search andcountwhich limits the number of keys to return in a single scan. At this point i have the Keys that match the search word, then i had to loop through the keys, and using the redis pipeline feature which can help us send multiple commands at once to redis and get back all the replies, we apply the.delcommand to delete the cached data.
- react-redux
- react-router
- react-router-dom
- redux-persist
- @reduxjs/toolkit
- Clone or Download the app from here
- Navigate to the server directory with the command
cd server - Install dependencies run
yarn - Run the server
yarn dev - Once server is running, you can view swagger definition on port: http://localhost:5005/api-docs/#/github-search/GithubSearch
- Api Test with the command
yarn test - Test Api-flow with the command
yarn api-flow;
- Navigate to the client directory with the command
cd client - Install all dependencies, run
yarn - Run the client app with
yarn start - App will run on port http://localhost:3000/
Cheers Happy coding...