Read the full blog post here: https://saadiqm.com/2019/03/06/computer-vision-streets.html
Code adapted from: https://github.com/tensorflow/models/blob/master/samples/outreach/blogs/segmentation_blogpost/image_segmentation.ipynb
For this exercise, I’m working with 100 Google Street View images divided into 80 images for training and 20 images for test. Using so few images will not produce a performant model, but this exercise was mainly to familiarize myself with the general CNN training workflow as well as Tensorflow’s data pipeline.
This post is divided into the following sections:
- Image Labelling (Ground Truth)
- Creating Image Label Masks
- Input data/image pipeline & creating TFRecords
- Building the Model
- Training the Model
- Prediction
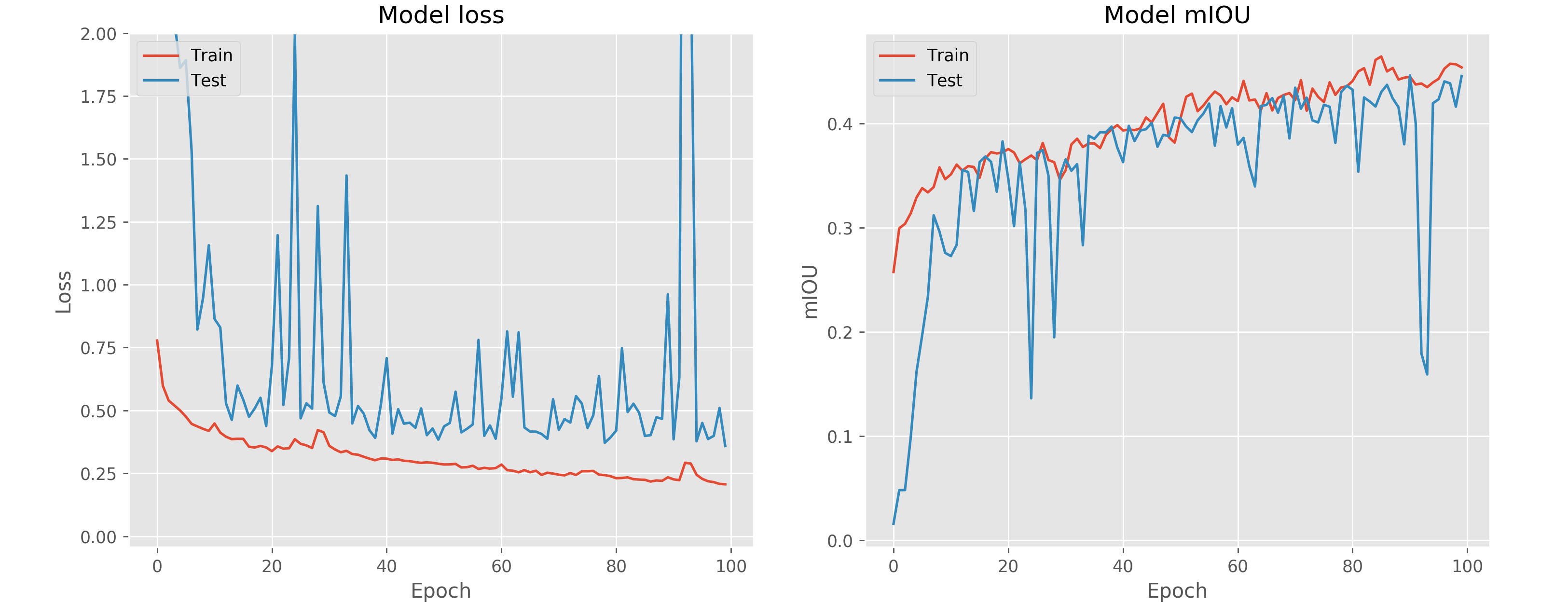
The final loss/mIOU charts seem somewhat reasonable for a toy example given that we only have 80 training samples and 20 test samples. Of course we are not expecting to see high performance results with such a small dataset despite some data augmentation.
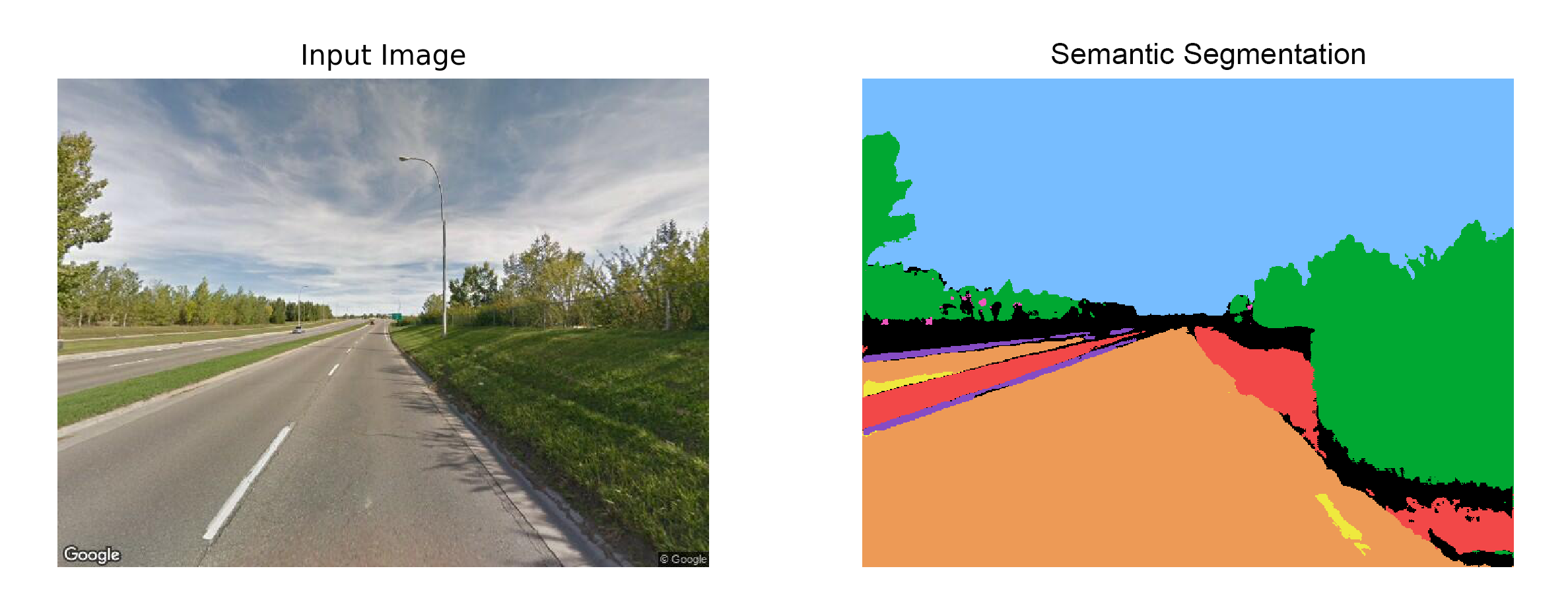
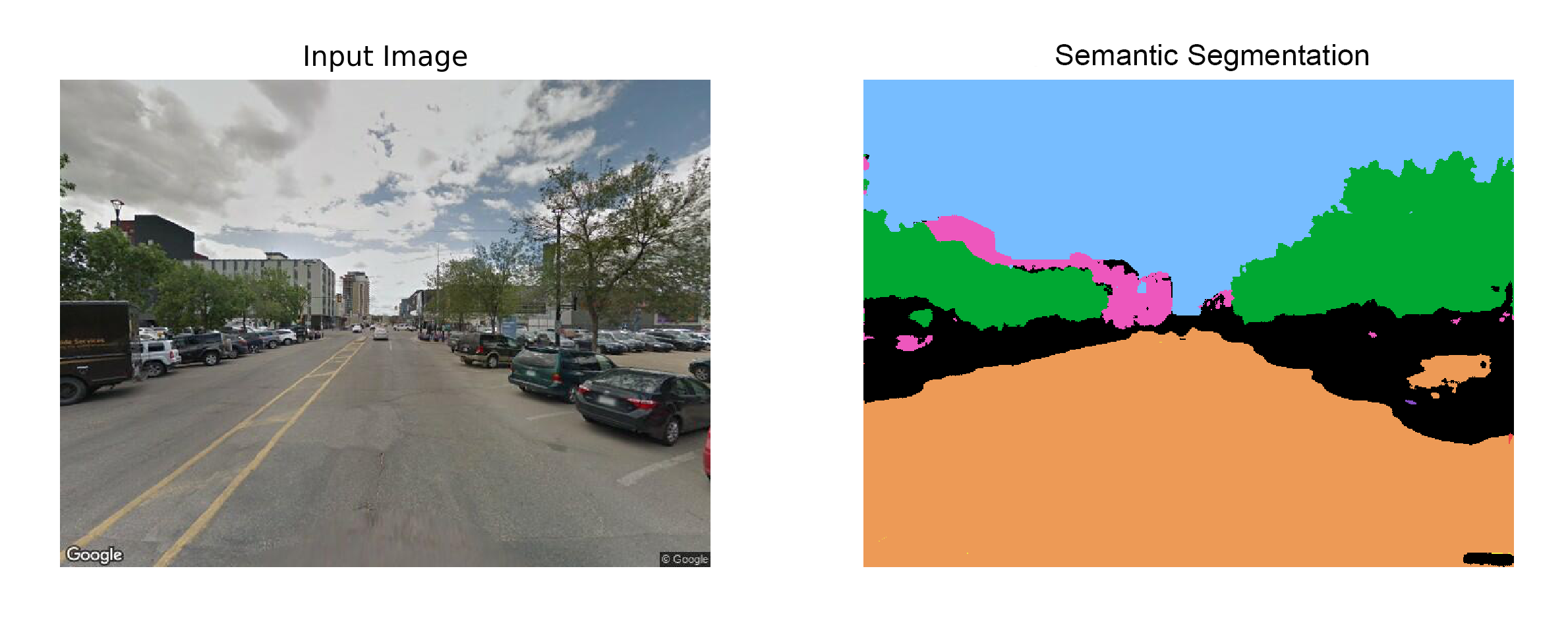
Finally, lets predict the output masks given some sample images. The output looks acceptable for images with few classes but fails when predicting many classes and complex representations.