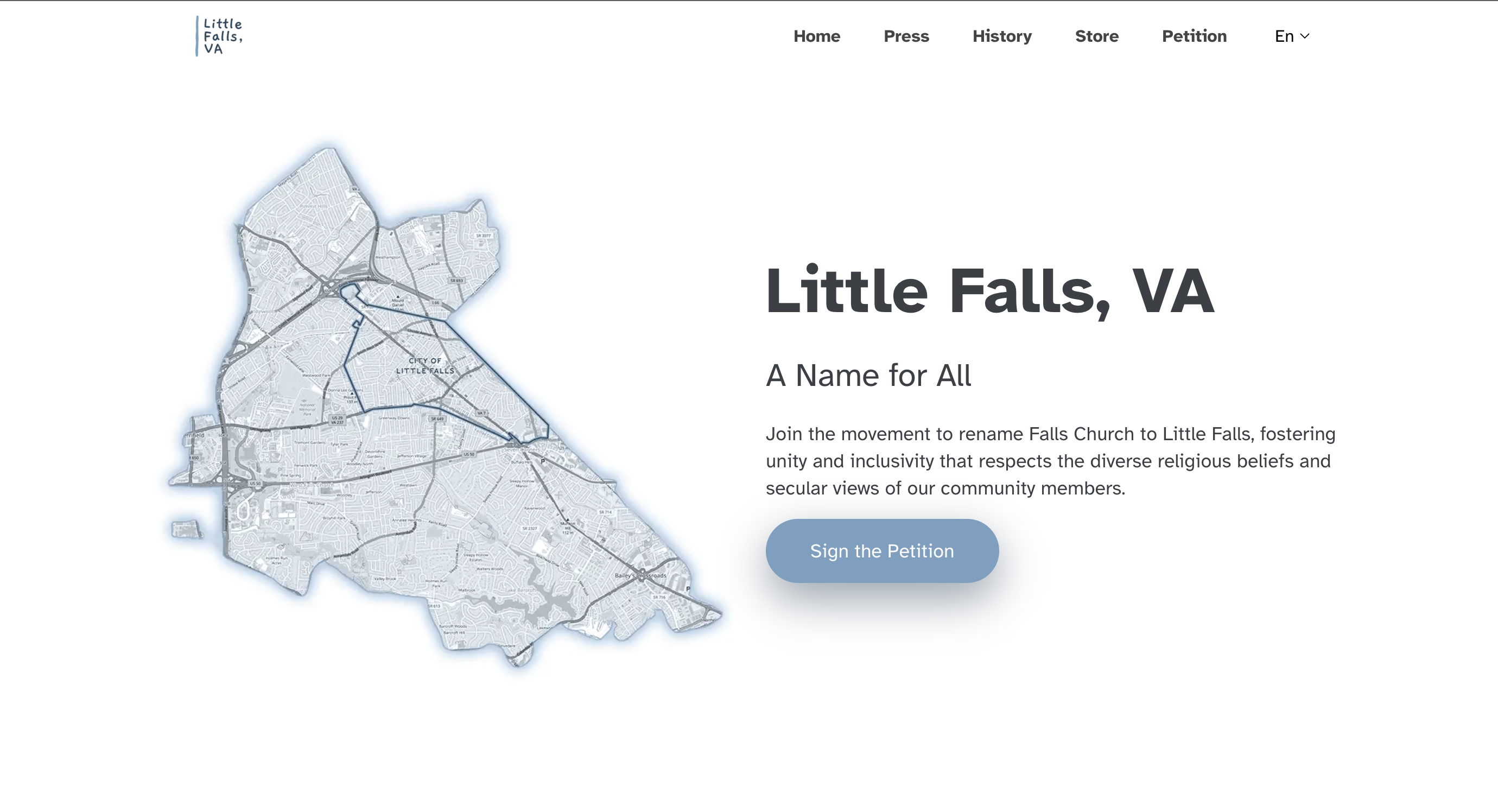
The Little Falls, VA website advocates for the renaming of Falls Church, Virginia to Little Falls. It's built on Hugo framework using the Vex Hugo theme.



- Clone this repository
- Install dependencies with
npm install - Run the development server with
npm run dev - View the site at http://localhost:1313
To build the site for production:
npm run buildThe built site will be in the public directory.
This site is deployed on Netlify. Any push to the main branch will trigger a new build and deployment.
When writing research articles, use the following citation shortcode format:
{{< cite url="URL" title="Full Title of Source" >}}
Single citation:
Falls Church became a microcosm of Southern defiance {{< cite url="https://example.com/article#:~:text=relevant,text,here" title="Article Title - Publication Name" >}}.Multiple citations in sequence:
This fact is supported by multiple sources {{< cite url="https://example1.com" title="First Source" >}} {{< cite url="https://example2.com" title="Second Source" >}}.- Always include both the
urlandtitleparameters - For URLs with text fragments (#:~:text=), include the full URL to reference specific quotes
- Place citations immediately after the relevant text, before any punctuation
- For multiple citations supporting the same statement, place them together without spacing
- Citations will render as clickable chips showing the domain name in uppercase
- Hovering over a citation will reveal the full title
- Citations in the Sources section should follow the same format
- Be specific with text fragments in URLs to point to exact quotes
- Use descriptive titles that include both the article name and publication
- Place citations logically to clearly indicate which statements they support
- When citing multiple sources, order them by relevance or chronologically
- Include a Sources section at the end of each article listing all citations
This repository contains tools to help with historical research about Falls Church, Virginia.
These scripts help extract text from PDF documents and add metadata front matter.
extract_pdf_text.py: Basic extraction with limited OCR (first 30 pages)extract_full_pdf.py: Advanced extraction with batch processing for large PDFs
# Process a specific PDF with OCR for all pages:
python3 extract_full_pdf.py --pdf "YourPDFFile.pdf" --ocr
# Process a specific page range (for large PDFs):
python3 extract_full_pdf.py --pdf "YourPDFFile.pdf" --ocr --start-page 0 --max-pages 60
# Process the next batch:
python3 extract_full_pdf.py --pdf "YourPDFFile.pdf" --ocr --start-page 60 --max-pages 60- Python 3.9+
- Tesseract OCR (
brew install tesseract) - Poppler (
brew install poppler) - Python packages: pytesseract, pdf2image, pdfminer.six
# Install required system dependencies
brew install tesseract poppler
# Install required Python packages
python3 -m pip install pytesseract pdf2image pdfminer.sixThis script processes IIIF manifest URLs from digital libraries (such as the Mary Riley Styles Public Library) and creates markdown files with metadata and image information.
- Extracts comprehensive metadata from IIIF manifests
- Creates markdown files with structured front matter
- Includes links to original images and manifests
- Uses descriptive titles for filenames
- Provides placeholders for adding historical significance notes
# Process a single IIIF manifest URL
python3 process_iiif_manifest.py "https://iiif.quartexcollections.com/mrspl/iiif/e3970652-8b7e-40e9-a9c9-d6dde46c2b42/manifest"
# Process multiple IIIF manifest URLs
python3 process_iiif_manifest.py "URL1" "URL2" "URL3"
# Process a list of URLs from a file
python3 process_iiif_manifest.py $(cat manifest_urls.txt)The script creates markdown files in the .research/images/ directory with:
- Front matter containing all available metadata
- A description section
- A complete metadata section listing all fields
- Direct links to the full-resolution image
- Links to the original IIIF manifest
- A section for adding historical significance notes
The script extracts and includes these fields in the front matter when available:
title: The title of the imagedate: The date of the imagesubject: The subject(s) of the imagecreator: The creator/photographerlocation: The place where the image was takenformat: The format of the original (e.g., Photographs)source: The collection sourceidentifier: The unique identifierdescription: A description of the imagecolor: Color information (b/w or color)dimensions: The dimensions of the originaldigitized: Always set to Truemanifest_url: The URL of the IIIF manifestimage_url: The URL to the full-resolution image
- Python 3.6+
- Python packages: requests
# Install required Python packages
python3 -m pip install requestsI need help extracting text from historical PDF documents. I have the following PDFs:
[List your PDFs here]
I've previously used scripts called extract_pdf_text.py and extract_full_pdf.py to extract text from PDFs and add front matter.
The scripts work by:
1. Attempting standard PDF text extraction first
2. Using OCR (Tesseract) if standard extraction fails
3. Processing large documents in batches (10 pages at a time)
4. Adding metadata front matter to the output markdown files
I'd like to extract all pages from [specific PDF] and add the following front matter:
- title: "[Title]"
- creator: "[Creator]"
- date: "[Date]"
- format: "[Format]"
- subject: "[Subject]"
- identifier: "[Identifier]"
- source: "[Source URL]"
Can you help me:
1. Update the script if needed
2. Run the extraction process
3. Combine the output into a single markdown file with proper front matter
I need to create markdown files with metadata from these IIIF manifest URLs:
[List your IIIF manifest URLs here]
I've previously used a script called process_iiif_manifest.py that:
1. Extracts metadata from IIIF manifests
2. Creates markdown files with detailed front matter
3. Includes links to the original images and manifests
4. Creates descriptive filenames based on the title
Can you help me:
1. Process these manifest URLs
2. Organize the resulting markdown files in my .research/images/ directory
3. Check for any errors or missing metadata