This project is no longer actively developed or maintained. The project exists here for historical reference. If you are interested in the future of the project and taking over stewardship, please contact [email protected].
The etcd operator manages etcd clusters deployed to Kubernetes and automates tasks related to operating an etcd cluster.
There are more spec examples on setting up clusters with different configurations
Read Best Practices for more information on how to better use etcd operator.
Read RBAC docs for how to setup RBAC rules for etcd operator if RBAC is in place.
Read Developer Guide for setting up a development environment if you want to contribute.
See the Resources and Labels doc for an overview of the resources created by the etcd-operator.
- Kubernetes 1.8+
- etcd 3.2.13+
See instructions on how to install/uninstall etcd operator .
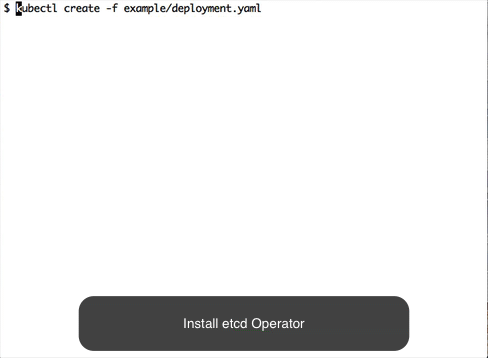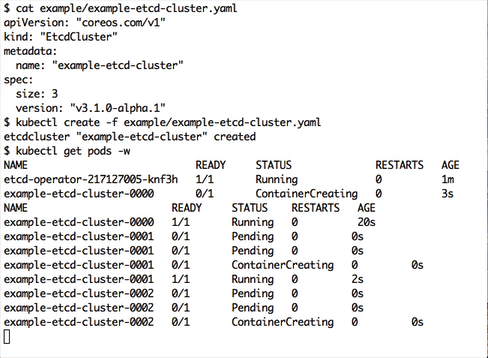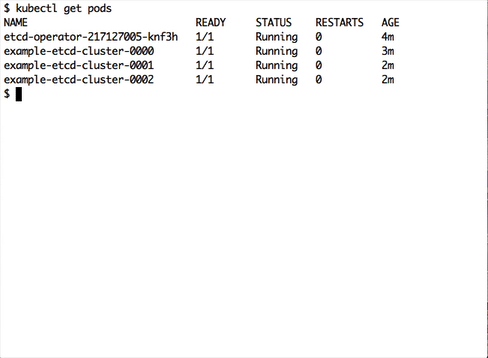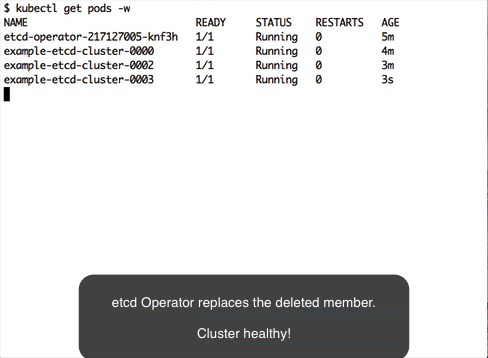
$ kubectl create -f example/example-etcd-cluster.yamlA 3 member etcd cluster will be created.
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
example-etcd-cluster-gxkmr9ql7z 1/1 Running 0 1m
example-etcd-cluster-m6g62x6mwc 1/1 Running 0 1m
example-etcd-cluster-rqk62l46kw 1/1 Running 0 1mSee client service for how to access etcd clusters created by the operator.
If you are working with minikube locally, create a nodePort service and test that etcd is responding:
$ kubectl create -f example/example-etcd-cluster-nodeport-service.json
$ export ETCDCTL_API=3
$ export ETCDCTL_ENDPOINTS=$(minikube service example-etcd-cluster-client-service --url)
$ etcdctl put foo barDestroy the etcd cluster:
$ kubectl delete -f example/example-etcd-cluster.yamlCreate an etcd cluster:
$ kubectl apply -f example/example-etcd-cluster.yaml
In example/example-etcd-cluster.yaml the initial cluster size is 3.
Modify the file and change size from 3 to 5.
$ cat example/example-etcd-cluster.yaml
apiVersion: "etcd.database.coreos.com/v1beta2"
kind: "EtcdCluster"
metadata:
name: "example-etcd-cluster"
spec:
size: 5
version: "3.2.13"
Apply the size change to the cluster CR:
$ kubectl apply -f example/example-etcd-cluster.yaml
The etcd cluster will scale to 5 members (5 pods):
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
example-etcd-cluster-cl2gpqsmsw 1/1 Running 0 5m
example-etcd-cluster-cx2t6v8w78 1/1 Running 0 5m
example-etcd-cluster-gxkmr9ql7z 1/1 Running 0 7m
example-etcd-cluster-m6g62x6mwc 1/1 Running 0 7m
example-etcd-cluster-rqk62l46kw 1/1 Running 0 7m
Similarly we can decrease the size of the cluster from 5 back to 3 by changing the size field again and reapplying the change.
$ cat example/example-etcd-cluster.yaml
apiVersion: "etcd.database.coreos.com/v1beta2"
kind: "EtcdCluster"
metadata:
name: "example-etcd-cluster"
spec:
size: 3
version: "3.2.13"
$ kubectl apply -f example/example-etcd-cluster.yaml
We should see that etcd cluster will eventually reduce to 3 pods:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
example-etcd-cluster-cl2gpqsmsw 1/1 Running 0 6m
example-etcd-cluster-gxkmr9ql7z 1/1 Running 0 8m
example-etcd-cluster-rqk62l46kw 1/1 Running 0 9mp
If the minority of etcd members crash, the etcd operator will automatically recover the failure. Let's walk through this in the following steps.
Create an etcd cluster:
$ kubectl create -f example/example-etcd-cluster.yaml
Wait until all three members are up. Simulate a member failure by deleting a pod:
$ kubectl delete pod example-etcd-cluster-cl2gpqsmsw --nowThe etcd operator will recover the failure by creating a new pod example-etcd-cluster-n4h66wtjrg:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
example-etcd-cluster-gxkmr9ql7z 1/1 Running 0 10m
example-etcd-cluster-n4h66wtjrg 1/1 Running 0 26s
example-etcd-cluster-rqk62l46kw 1/1 Running 0 10mDestroy etcd cluster:
$ kubectl delete -f example/example-etcd-cluster.yamlLet's walk through operator recovery in the following steps.
Create an etcd cluster:
$ kubectl create -f example/example-etcd-cluster.yaml
Wait until all three members are up. Then stop the etcd operator and delete one of the etcd pods:
$ kubectl delete -f example/deployment.yaml
deployment "etcd-operator" deleted
$ kubectl delete pod example-etcd-cluster-8gttjl679c --now
pod "example-etcd-cluster-8gttjl679c" deletedNext restart the etcd operator. It should recover itself and the etcd clusters it manages.
$ kubectl create -f example/deployment.yaml
deployment "etcd-operator" created
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
example-etcd-cluster-m8gk76l4ns 1/1 Running 0 3m
example-etcd-cluster-q6mff85hml 1/1 Running 0 3m
example-etcd-cluster-xnfvm7lg66 1/1 Running 0 11sCreate and have the following yaml file ready:
$ cat upgrade-example.yaml
apiVersion: "etcd.database.coreos.com/v1beta2"
kind: "EtcdCluster"
metadata:
name: "example-etcd-cluster"
spec:
size: 3
version: "3.1.10"
repository: "quay.io/coreos/etcd"
Create an etcd cluster with the version specified (3.1.10) in the yaml file:
$ kubectl apply -f upgrade-example.yaml
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
example-etcd-cluster-795649v9kq 1/1 Running 1 3m
example-etcd-cluster-jtp447ggnq 1/1 Running 1 4m
example-etcd-cluster-psw7sf2hhr 1/1 Running 1 4m
The container image version should be 3.1.10:
$ kubectl get pod example-etcd-cluster-795649v9kq -o yaml | grep "image:" | uniq
image: quay.io/coreos/etcd:v3.1.10
Now modify the file upgrade-example and change the version from 3.1.10 to 3.2.13:
$ cat upgrade-example
apiVersion: "etcd.database.coreos.com/v1beta2"
kind: "EtcdCluster"
metadata:
name: "example-etcd-cluster"
spec:
size: 3
version: "3.2.13"
Apply the version change to the cluster CR:
$ kubectl apply -f upgrade-example
Wait ~30 seconds. The container image version should be updated to v3.2.13:
$ kubectl get pod example-etcd-cluster-795649v9kq -o yaml | grep "image:" | uniq
image: gcr.io/etcd-development/etcd:v3.2.13
Check the other two pods and you should see the same result.
Note: The provided etcd backup/restore operators are example implementations.
Follow the etcd backup operator walkthrough to backup an etcd cluster.
Follow the etcd restore operator walkthrough to restore an etcd cluster on Kubernetes from backup.