
The Go programming language's simplicity, execution speed, and concurrency support make it a great choice for building data pipeline systems that can perform custom ETL (Extract, Transform, Load) tasks. Ratchet is a library that is written 100% in Go, and let's you easily build custom data pipelines by writing your own Go code.
Ratchet provides a set of built-in, useful data processors, while also providing an interface to implement your own. Conceptually, data processors are organized into stages, and those stages are run within a pipeline. It looks something like:
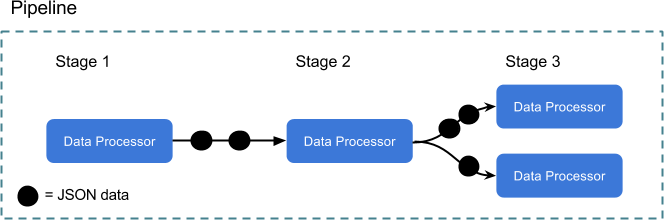
Each data processor is receiving, processing, and then sending data to the next stage in the pipeline. All data processors are running in their own goroutine, so all processing is happening concurrently. Go channels are connecting each stage of processing, so the syntax for sending data will be intuitive for anyone familiar with Go. All data being sent and received is JSON, which provides for a nice balance of flexibility and consistency.
-
Check out the full Godoc reference:
-
Get Ratchet: go get github.com/rhansen2/ratchet
Ratchet comes with vendored dependencies so it can work out of the box if you use go1.6 (or go1.5 with the GO15VENDOREXPERIMENT environment variable set to 1).
However, if you prefer to vendor your own dependencies then you should move the dependencies out of ratchet's vendor/ folder and into your own. Read the vendor/vendor.json file to get a list of its dependencies and their versions. Ratchet works with the vendor-spec, so it will also work with the govendor dependency manager. After you have copied the dependencies into your project's vendor.json, you can download them into your project's vendor folder--along with ratchet--by running:
govendor sync govendor add github.com/rhansen2/ratchet govendor add github.com/rhansen2/ratchet/data govendor add github.com/rhansen2/ratchet/logger govendor add github.com/rhansen2/ratchet/processors govendor add github.com/rhansen2/ratchet/util

While not necessary, it may be helpful to understand some of the pipeline concepts used within Ratchet's internals: https://blog.golang.org/pipelines
Ratchet could be used anytime you need to perform some type of custom ETL. At DailyBurn we use Ratchet mainly to handle extracting data from our application databases, transforming it into reporting-oriented formats, and then loading it into our dedicated reporting databases.
Another good use-case is when you have data stored in disparate locations that can't be easily tied together. For example, if you have some CSV data stored on S3, some related data in a SQL database, and want to combine them into a final CSV or SQL output.
In general, Ratchet tends to solve the type of data-related tasks that you end up writing a bunch of custom and difficult to maintain scripts to accomplish.