A pytorch implementation of transformers.
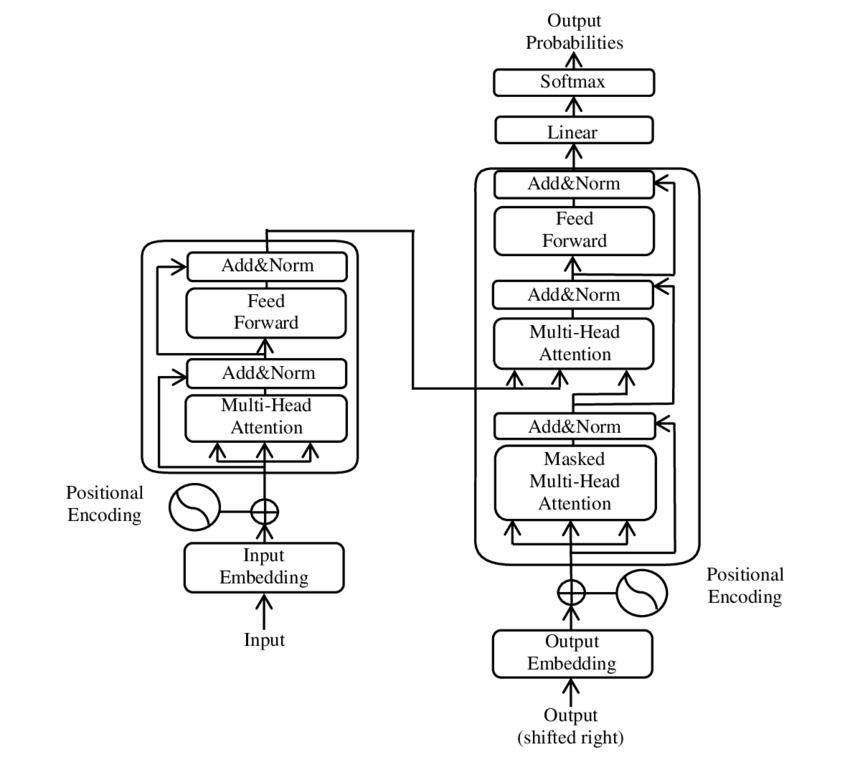
This repository contains the implementation of the transformer model as described in the paper "Attention is All You Need" (2017). The implementation is based on the original paper and it's written in PyTorch with learning purposes only, since PyTorch already provides optimized implementations of the transformer model that you can import as:
from torch.nn.functional import scaled_dot_product_attention
from torch.nn import MultiheadAttention
from torch.nn import TransformerEncoderLayer
from torch.nn import TransformerDecoderLayer
from torch.nn import TransformerThe paper introduces the following concepts:
Let
With
The attention is all you need paper, proposes a positional encoding function
With the "frequencies" defined by
And a constant
The positional encoding matrix
The positional encoding matrix
class PositionalEncoding(Module):
def __init__(self, sequence_lenght_limit: int, model_dimension: int, scaling_factor: int = 10000, device=None, dtype=None):
super().__init__()
self.embeddings = Parameter(data=torch.zeros(sequence_lenght_limit, model_dimension, device=device, dtype=dtype), requires_grad=False)
for dimension in range(model_dimension):
self.embeddings[:,dimension] = dimension // 2 + 1
self.embeddings[:,dimension] = exp(-2*self.embeddings[:,dimension] * math.log(scaling_factor) / model_dimension)
for sequence in range(sequence_lenght_limit):
if dimension % 2 == 0:
self.embeddings[sequence,dimension] = sin(sequence * self.embeddings[sequence,dimension])
else:
self.embeddings[sequence,dimension] = cos(sequence * self.embeddings[sequence,dimension])
def forward(self, input: Tensor) -> Tensor:
input = input + self.embeddings[:,:input.size(1)]
return input
Given three tensors
def attention(query: Tensor, key: Tensor, value: Tensor, mask: Optional[Tensor] = None) -> Tensor:
scale = 1 / math.sqrt(key.size(-1))
score = query @ key.transpose(-2, -1) * scale
if mask is not None:
score = score.masked_fill(mask == 0, float('-inf'))
return softmax(score, dim=-1) @ valueIn the transformers model, the attention mechanism is applied in parallel to multiple projections of the queries, keys and values. Each projection is called an "attention head". To define these projections, three weight matrices
Let:
$W^Q \in \mathbb{R}^{d \times d_q}$ $W^K \in \mathbb{R}^{d \times d_k}$ $W^V \in \mathbb{R}^{d \times d_v}$
With
$X W^Q \in \mathbb{R}^{l \times d_k} $ $X W^K \in \mathbb{R}^{l \times d_k} $ $X W^VX \in \mathbb{R}^{l \times d_v} $
Are the projections of the tensor
With
Although in the definition of the multi-head attention mechanism layer, different views are generated for the input tensors
Given a projection
Where the first matrix is the first head, the second matrix is the second head and so on. The final result is a tensor of dimension
The concatenation of the outputs of each head is done in the dimension
Finally, the output is multiplied by the matrix
Note that
So the multi-head attention mechanism will be:
Where each matrix inside the tensors corresponds to an attention head. The result of the attention function is a tensor of dimension
The concatenation of the outputs of each head is done in the dimension
Finally, the output is multiplied by the matrix
def split(sequence: Tensor, number_of_heads: int) -> Tensor:
batch_size, sequence_length, model_dimension = sequence.size()
sequence = sequence.view(batch_size, sequence_length, number_of_heads, model_dimension // number_of_heads)
sequence = sequence.transpose(1, 2)
return sequence
def concat(sequence: Tensor) -> Tensor:
batch_size, number_of_heads, sequence_lenght, heads_dimension = sequence.size()
sequence = sequence.transpose(1, 2).contiguous()
sequence = sequence.view(batch_size, sequence_lenght, heads_dimension* number_of_heads)
return sequence
class MultiheadAttention(Module):
def __init__(self, model_dimension: int, key_dimension: int, value_dimension: int, number_of_heads):
super().__init__()
self.number_of_heads = number_of_heads
self.query_projector_weight = Parameter(torch.empty(model_dimension, model_dimension))
self.key_projector_weight = Parameter(torch.empty(model_dimension, key_dimension))
self.value_projector_weight = Parameter(torch.empty(model_dimension, value_dimension))
self.output_projector_weight = Parameter(torch.empty(model_dimension, model_dimension))
init.xavier_normal_(self.query_projector_weight)
init.xavier_normal_(self.key_projector_weight)
init.xavier_normal_(self.value_projector_weight)
init.xavier_normal_(self.output_projector_weight)
def forward(self, query: Tensor, key: Tensor, value: Tensor, mask: Optional[Tensor] = None) -> Tensor:
query, key, value = query @ self.query_projector_weight.T, key @ self.key_projector_weight.T, value @ self.value_projector_weight.T
query, key, value = split(query, self.number_of_heads), split(key, self.number_of_heads), split(value, self.number_of_heads)
heads = attention(query, key, value, mask)
heads = concat(heads)
return heads @ self.output_projector_weight.TThere are also implementations of the layer normalization and feed forward layers, the encoder and decoder, the transformer and some other details here: notebook
The models are in the folder model and I wrote some tests for the model in the folder tests.
The implementation is not optimized and is not intended to be used in production, but to understand the transformer model and how it works. The code is written in a way that is easy to understand and follow the steps of the model. Soon I will be adding some experiments, more tests and some other implementations of the transformer model.
If you have any questions, feel free to contact me at [email protected]