Goal= Correctly guessing the classification of texts and audios
It is a text classification task implementation transformers (by HuggingFace) with BERT. It contains several parts:
--Data pre-processing
--BERT tokenization and input formating
--Train with BERT
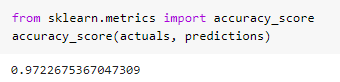
--Evaluation
--Save and load saved model

Text classification tasks are most easily encountered in the area of natural language processing and can be used in various ways.
However, the given data needs to be preprocessed and the model's data pipeline must be created according to the preprocessing.
The purpose of this Repository is to allow text classification to be easily performed with Transformers (BERT)-like models if text classification data has been preprocessed into a specific structure.
Implemented based on Huggingfcae transformers for quick and convenient implementation.

3061 rows