Daniel Keen || Marcus Gardiner || Carlos Trapet || Stephen Tilley
To use SentiMind, visit: sentimind.co.uk
SentiMind analyses and visualises the live sentiment (frequency and polarity) of the latest 100 tweets using SentiBot, a bot trained using a machine learning algorithm (Bernoulli Naive Bayes Algorithm)
You can find out what the world thinks about a topic of your choice on sentimind.co.uk. Visualise the world's sentiment on everything from Donald Trump to kittens and rainbows!
Our motivations for the project were to explore both Machine Learning and ReactJS. To do so, we aimed to harness a live stream of twitter data and analyse, visualise and extract meaning from the result.
View our final project presentation deck at: SentiMind Presentation
- Python/Flask
- ReactJS
- Jest/Enzyme
- Nose/Pytest
- Docker
- AWS EC2
- Tweepy -- to make calls to the Twitter API
- NLTK -- a toolkit used for Natural Language Processing
- To train our bot, we used the Stanford Sentiment140 tweet data library
- Citation: Go, A., Bhayani, R. and Huang, L., 2009. Twitter sentiment classification using distant supervision. CS224N Project Report, Stanford, 1(2009), p.12.
Please note: to use the twitter API which is integral to this program, you will need to add a 'credentials.py' file to the folder backend/mypkg. This file can be of the following format, subbing in your twitter account credentials:
consumer_key = YOUR_KEY consumer_secret = YOUR_SECRET access_token = YOUR_TOKEN access_token_secret = YOUR_TOKEN_SECRET
- Install Docker (and docker-compose) from https://docs.docker.com/install/
- git clone this repository and change into the folder with 'cd' in the terminal
- Run 'docker-compose build' in the terminal
- When the build is complete, run 'docker-compose up' in the terminal
- Visit localhost:3000 in your browser
In order to run the server, you will need to download python and then run: pip3 install pipenv
In the terminal:
- clone the repository
- From the root folder of the directory
pipenv install requeststo download the python dependencies pipenv shellcd frontendnpm installto download the react/npm dependencies
To run the backend server:
cd backendpython3 server.py
To run the frontend server:
cd frontendnpm start
With both servers running - you can visit 'localhost:3000' in your browser to use the app
For Testing our ReactJS front-end we used Jest with enzyme. To run the tests:
cd frontendnpm run test
If you get the error 'Error watching file for changes: EMFILE', run the following commands to fix your install of watchman:
brew uninstall watchman
brew link automake
brew install --HEAD watchman
For Testing our Python back-end we used Pytest.
To run python tests:
- Ensure you have run 'pipenv install requests' from the root folder and 'npm install' from the front end folder to download dependencies
- 'pipenv shell' to set up the python environment
- cd to backend folder and use 'pytest' to run tests
In 7 days we learned and used entirely new technologies to build our app (ReactJS and Python/Flask), train a machine (Python's statistical libraries) and deploy to sentimind.co.uk (AWS and Docker).
Almost every tech we used for this project was something completely new to us. We have been able to use the knowledge we have gained during our time at Makers to produce well written quality code with the aim of following best practices. See the process section below for details
One of our major successes was our communication and ability to work as a team. We had daily stand ups and retros where we discussed how we had followed XP values and also a morale check for everyone in the group. We all felt comfortable being open about how we felt. Following these practices led to us having a fairly stress free time and also showed us the importance of soft skills in development.
We arrived out our MVP very early on and began to iterate on this, allowing our product to grow organically. At the end of the first week we felt we could have happily had a feature freeze and still had something awesome to show off. This allowed us to go down other avenues we didn't think we would have had time for, like learning how to deploy using AWS/Docker.
Learning from each challenge, we ended up with 2 high-quality and highly efficient micro-services that spoke to each other through JSON data and ran in optimised containers to dynamically visualise live sentiment data. Above all we feel we have been able to produce an awesome product that we are proud of.
We decided to challenge ourselves and use AWS/Docker to deploy rather than something simpler like Heroku. This had a major learning curve and we ended up spending multiple days learning about the intricacies of reverse proxy servers, containers versus virtual machines and how cloud servers work in practice.
We had some problems training our bot with large datasets. We initially had a dataset of 1.6 million tweets we wanted to use but discovered that even a smaller dataset of 100,000 tweets was taking tens of hours to train with and quite often killing the process before it had completed. If we were to carry on with this project we would like to look into producing either a more efficient algorithm to train our bot with or a way to build on our bots training using partial datasets.
Using the free tiers of services (Twitter API, AWS) has caused some minor roadblocks for us. For example being limited in the number of tweets we can grab means we only have a small sample size to make our predictions on, and our website will slow down quite noticeably at times due to using AWS free tier services.
Learning Python has caused a few minor headaches. Although very similar to Ruby which we are familiar with, Python has its own set of idiosyncrasies we have had to navigate through. For example the way files are imported caused us some confusion early on in the project. The way we split our Frontend and Backend was different to the usual Model View Controller model we have been using throughout the Makers Academy course. Learning a new architecture had its own challengers and led to several difficult but essential code-base restructures.
Trying to decide on a balance between adding features and quality is a natural tension in all projects. We stuck strongly to prioritising code quality in our core app, and this yielded many benefits later on in extending the code. As the final deadline approached, the tension between code quality and features became more tense: code quality definitely slipped as would be expected: the key then was to refactor the code base. One time run code such as bot training was also an area of debate in terms of test coverage, with lower coverage and a reliance on testing the bots themselves when they had finished their training.
As a team, we learned a lot across both technical and team skills. In terms of technical skills, we learned about APIs, applied a brand new and cutting edge tech stack (ReactJS and Python) and even deployed a production level build with Docker and AWS. The learnings we made as a team were even more important: nothing beats a best practice coding process, strong team culture and a keen focus on planning.
- Benefits of aiming for a best practice coding process
- SOLID (particularly Single Responsibility and Open, Closed principles) result in clean, extendable code. This allowed team members to work on separate elements and with minimal knowledge exchange on the codebase for they could rapidly contribute.
- For example, after a REACT knowledge exchange, a team member was able to easily add components to our react app and understood how this would fit with the rest of the page, even though they had never used react before
- Working on each step with a best practice mindset leads to less problems and less stress later down the line. If the code you make is of quality in the early stages, later developments are easy and don’t require touching previous methods or breaking other functionality
- Using an agile process of agreeing a clear, realistic MVP led to a product that organically evolved based on what we were finding out as we developed it. At each stage, we would reflect on what was working and ask other team members what they thought of what we had built and what ideas they had, which led to a better end product.
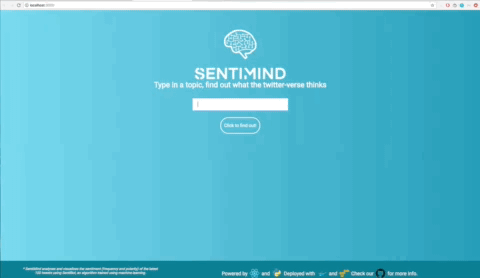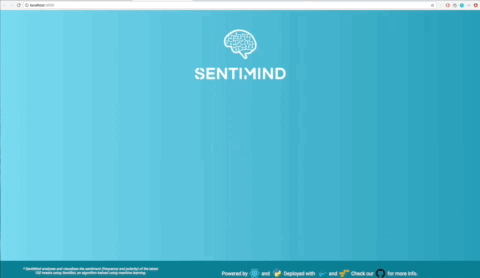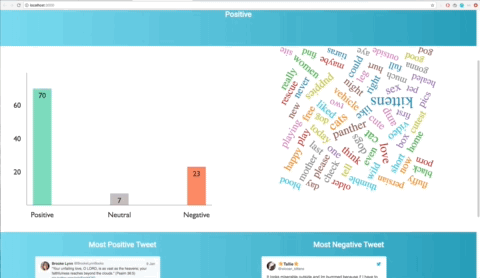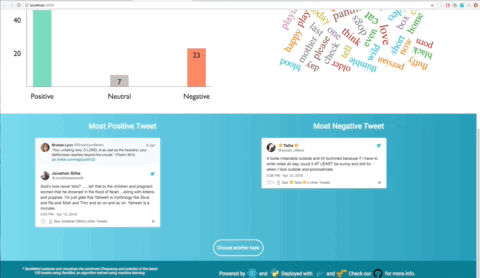
- For example, we were trying to truly capture the number of tweets we were processing and representing what words they had, and went from a pie chart that was more difficult to interpret to polarising ‘most positive/negative’ tweets and a world capturing the full range of tweets
- SOLID (particularly Single Responsibility and Open, Closed principles) result in clean, extendable code. This allowed team members to work on separate elements and with minimal knowledge exchange on the codebase for they could rapidly contribute.
- A team culture that cares for other team members, realises the importance of morale and values the soft skills of XP values is a vital foundation on which to build a product
- Not only does a strong team culture make the experience fun, it is also essential to the quality of the final product
- Morale and team dynamics were as if not more important than what we were doing, including in formal settings such as stand ups, retros and in our team ground rules. This culture is what gives people the space and courage to create a quality product.
- One of the reflections of why our teamwork went so smoothly is that we lived a culture a ‘no egos, honest discussions and the best ideas win’. For example, in discussing our data visualisations different team members had different ideas of what would work. We properly pitched our ideas, and team members felt empowered to raise concerns and counter-arguments that resulted in a better outcome.
- Prioritisation and appropriate planning (with an agile rather than waterfall approach) saves you time in the long run
- By setting up a comprehensive plan, but one that only covered what it needed to at each mvp iteration, we saved a lot of time as a team and could take courageous steps into new topics such as DevOps and machine learning.
- We agreed on a plan that balanced personal goals and a good overall strategy for the project: We set out a plan to use a pre-trained bot first, and focussed on finishing the product, before then doing our own bot trained through machine learning.
- This strong planning meant we could go after a tech stack and product that would initially seem very intimidating. Machine learning is a huge and complex topic, so is DevOps. We aimed high in choosing these topics, but what enabled us to succeed was planning, re-planning and execution.
- DevOps was a topic area we had not learned at all about during the course. We wanted to learn how to use 2 cutting edge and rapidly growing technologies for deployment: Docker and Amazon Web Services
- Our app was also a different structure to what we had learned previously: it was split into 2 micro-services, a front-end in ReactJS and a back-end in Python, which communicated with each other using an API between the micro services and JSON data.
- Docker was a fantastic technology to learn, its advantages over virtual machines and dynamic building of tailored images for our two micro services was excellent to use. Once set up and understood, editing images was rapid due to the layering system it employs for constructing and editing images, and pushing it onto the remote AWS server was fantastic using the remote docker registry. Knowing the images would work efficiently in a range of environments was a fantastic thing to learn in both development and deployment in future.
- AWS equally has become very popular. Initially it was daunting due to the huge range of services they provide and high-barrier to entry of dev ops. However, its been fantastic to realise what is truly being cloud servers and how they can work hand in hand with docker.
- Learning how to issue a production level build taught us the importance considerations of DevOps, how to execute some core elements of it and importantly how apps would scale using containers across powerful cloud servers.
- We also had some individual learnings about how our web-apps really work.
- For example:
- We had to understand how our containers were their own environments with their own set of ports that we had to expose, and how the AWS server again had ports in its own rights that needed to be accessed publicly.
- We also got stuck having 2 deployed micro services with only 1 public port on AWS. This led to some research into reverse proxy servers as one solution, which worked locally but not on the aws cloud in the way we deployed it, as well as ultimately opening up multiple ports on our AWS server (one for each micro service) by allowing access to an additional port in our firewall.
- We also learned to better understand POST requests, and how each request is tailored to a specific IP address, so multiple post requests to the same back end micro service website will be handled independently and not affect each other.
- For example:
- We learned the fundamentals of machine learning, in theory but most importantly in practice, including how to apply it using powerful python libraries
- Core epiphanies on machine learning:
- Machine learning is essentially learning a target function (f) that best maps input variables (X) to an output variable (Y): Y = f(X)
- We can use different models to model a relationship between inputs and outputs, and different machine learning algorithms to make guesses to get to the best weighting’s that make the model more accurate, but supervised learning still comes down to feeding in inputs, with weights, and trying to get an output guess
- Machine learning is not really ‘learning’ at all - it is ‘machine mixing the number stew of inputs into our target function, using trial and error’
- e.g. if the model is linear: y= mx + c, we are guessing the best value to feed in as ‘m’ to be the line of best fit.
- In practice, the models are many multiples more complex, but the approach is still the same
- The key to machine learning algorithms, is that they don’t care what your problem or data is, they just care about the best way to model the relationship. They don’t know or care what a ‘word’ or a ‘face’ is, ultimately - we need to turn them into numbers for the computer to read and recognise them and learn the relationships. This means a general machine learning algorithm is really general, and can be flexibly applied to any topic, regardless of what the data is representing in reality.
- For example, in training our model, the ‘positive’ label was actually just the integer ‘2’. The machine doesn’t actually care what ‘positive’ is.
- To use machine learning in practice, there are fantastic libraries in python that do some of the hardest maths for you, enabling you to focus on the core elements of feeding your model
- Some core learnings for our specific model and natural language processing:
- Natural language processing is hard. Considerations include: Sarcasm, words that accentuate the next one (e.g. ‘really' great), words that flip meaning (e.g. ‘not' great), stop and connecting words are not useful for detecting sentiment (e.g. ‘and’)
- In practice, we turned the words in our tweet database into a giant unique library of ‘features’. Whereas a machine learning model that predicts house prices would only consider a few factors such as neighbourhood, bedrooms, square feet etc, we had thousands of features in the form of individual words.
- Key to the logic of our machine learning model using these words as features was the probability of a word being part of a positive or negative tweet. For example, if the term "insulting" appears 10.6 more times as often in negative tweets as it does in positive tweets, this is a very telling feature for classifying future tweets as negative. A neutral word would be shared between positive and negative more easily.
- For every tweet, the entire custom dictionary we created would be checked. If that word was found in our fast dictionary, it would be marked as appearing in that tweet. By considering each words relative probability score (positive versus negative), an overall sentiment for the tweet would be estimated probabilistically. e.g. if positive is ‘1’ and negative is ‘0’, and a tweet ‘This is amazingly awesome’ resulted in a 0.95 confidence it was positive, it would evaluate to an overall positive sentiment with a high positive polarity.
- Machine learning is essentially learning a target function (f) that best maps input variables (X) to an output variable (Y): Y = f(X)
Give me six hours to chop down a tree and I will spend the first four sharpening the axe.
-Abraham Lincoln
At the start of the week, a good while was spent planning our approach to the task at hand. Part of this was deciding on exactly what the task was.
We knew we would approach this task in an agile way, building an MVP and iterating on it, and discussing regularly which new features were important to us. But in order to prioritise and understand the core benefits of what we were building, we discussed our individual goals and found we all aligned on the following:
-
Learning - We wanted a project that would allow us to explore new techs - particularly machine learning. The number one goal of this 2 week project was to learn.
-
A product - We wanted something useable, something that would really add value to a user, and be a meaningful or enjoyable experience.
With these in mind, we decided that the best idea was to create a product first - using a pre-trained bot - and then replace this with our own bot once we had the finished product.
This decision set the tone for the project. It allowed us space to relax, be creative, and really focus on building a great product first, and worrying about the potentially un-scalable hurdles (training our own bot) later.
We felt that giving the day a bit of structure was important, but would also allow us to regularly check in with each other and understand exactly where each pair was in their development task.
The structure was as follows:
-
9:30am: Stand up. We begin with a morale check for each member of the team, to ensure we know and understand everyones energy and motivation levels for the day. It's also chance to discuss what needs to be done for the day and pair up accordingly.
-
2:00pm: Check in. Check where the other pair is at in their task allocation, and see if there is need for a knowledge share, or a switch up/ re-prioritisation of tasks.
-
5:00pm: Retro. A discussion on what went well, what didn't go so well, how everyone is feeling about the project, the team and their general situation. We tended to have a chat about XP values here, and pick one per retro that we think we particularly did well in that day and why.
This basic structure meant that each member of the team knew exactly where each other person was both mentally and in project task / development terms. This focus on mental wellbeing and 'soft skills' was a huge reason why we were a successful, cohesive team.
The morale check as part of each check-in was a quick go-around where each person said a number out of 10 relating to their overall wellbeing, and a quick note on how they feel. We found this incredibly useful as a tool to quickly see what everyones levels were, and could adjust how we pair with them if needs be.
We wanted to make our MVP in 2 days, and continue these mini-sprints for the full 8 days of the project. In order to get the application up and running as soon as possible, we split the tasks into frontend and back end, assigning a pair to each part of the stack.
We often stayed in these pairs for the full 2 days, to ensure maximum productivity during the mini sprint, as often it took the majority of a day to become comfortable with the new tasks and technologies, so it made sense to keep the pairs together working on the same task.
At the start of the project we made sure we would hold each other accountable when it came to sticking to best practices, in order to build the best possible product we could in the 10 days, and to learn as much as we could.
For us, this meant sticking to TDD throughout the project, and ensuring that our code was built using the SOLID object oriented design principles we had been taught and honing throughout Makers Academy. At each stage we aimed to finesse and build upon the best coding process we could muster. This became particularly visible in debugging, where very difficult issues were navigated calmly and resolved in a practical, efficient manner: trying each potential avenue in a prioritised order and aiming to deepen learning to unlock new solutions
The fact that we followed Agile methodologies since the get-go and decided on MVP v1, v2 and v3 at the very start of the project made sure that our app is easily extendable and scalable. Adding features like the ones explained below is therefore easily achievable without having to extensively modify the existing codebase, a key goal of ours at the start of the project.
-
Refactoring: clean-up the backend code to optimise the way the different methods (polarity checker, top tweets, top words, etc.) are looping through the tweets.
-
"History of sentiment": Sentiment search linked to time. User can search for the positivity perception now vs. an earlier period of time.
-
Search by users: hero or troll? General sentiment on Twitter-users where the SentiMind user gives a summary of that user's last 100 tweets, and whether they are positive or negative in their tweeting behaviour.
-
Responsive web design: considering the time put into UI, UX and deploying our product, we would like to improve SentiMind's user interface, as well as the overall user experience, eg. by including flexible grids and images so that the app can easily be used on tablets and mobiles.
-
Search history: add database & login functionality so that users can have a list of previously searched keywords and scores.
-
Cover edge cases of user inputs and return results, for example if a search query has no tweets. We could also have a 'kid-friendly' version which filters out swearwords.
One of the most impactful learnings we had this week was finding out that using Machine Learning to train a bot can take a day or a year; accuracy can always be improved.
Due to time constraints and the fact that we wanted to have a usable product by the end of the week, the dataset that we trained the bot with was limited to 20,000 tweets. Some examples on how to improve bot-accuracy:
-
Use NLTK to add a list of adverbs and adjectives that modify the proceeding noun phrases' polarity
-
Add context-based analysis
-
Add smiley/emoji -based analysis
-
Add arrays of easily identifiable positive/negative noun phrases that weigh the polarity of the sentence
-
Add sarcasm detection via emoji and sarcastic noun-phrase identification
- You need to think about the context of the problem you really trying to solve, and investigate and interrogate your data to come up with hypotheses that will influence how you train the machine
- We can apply better data munging and cleansing techniques to feed out model better data to train with. This data process can be far more important than the algorithm, and can be particularly hard for certain topics e.g. natural language processing
- We can apply different machine learning algorithms to different data and different contexts, as well as combine algorithms, to try and get the most accurate model. Different machine learning algorithms can be better or worse for different datasets or relationships
- Beyond core machine learning algorithms, deep learning is also a fantastic new tech area, using neural nets to model vastly complex relationships. Again, this is particularly useful in certain situations, for example facial recognition and natural language processing
- There are ways we can get to better machine learning trial and error ‘guesses’ faster. This can be a very complex element of machine learning.
- More data is better, better data is the best. Data is king over the quality of algorithm for training a powerful machine