



Preprocessing Library for Natural Language Processing
- Python >= 3.6
- Mecab morphological analyzer for Korean
sh scripts/install_mecab.sh # Only for Mac OS users, run the code below before run install_mecab.sh script. # export MACOSX_DEPLOYMENT_TARGET=10.10 # CFLAGS='-stdlib=libc++' pip install konlpy - C++ Build tools for fastText
- g++ >= 4.7.2 or clang >= 3.3
- For Windows, Visual Studio C++ is recommended.
prenlp can be installed using pip as follows:
pip install prenlp
Popular datasets for NLP tasks are provided in prenlp. All datasets is stored in /.data directory.
- Sentiment Analysis: IMDb, NSMC
- Language Modeling: WikiText-2, WikiText-103, WikiText-ko, NamuWiki-ko
| Dataset | Language | Articles | Sentences | Tokens | Vocab | Size |
|---|---|---|---|---|---|---|
| WikiText-2 | English | 720 | - | 2,551,843 | 33,278 | 13.3MB |
| WikiText-103 | English | 28,595 | - | 103,690,236 | 267,735 | 517.4MB |
| WikiText-ko | Korean | 477,946 | 2,333,930 | 131,184,780 | 662,949 | 667MB |
| NamuWiki-ko | Korean | 661,032 | 16,288,639 | 715,535,778 | 1,130,008 | 3.3GB |
| WikiText-ko+NamuWiki-ko | Korean | 1,138,978 | 18,622,569 | 846,720,558 | 1,360,538 | 3.95GB |
General use cases are as follows:
>>> wikitext2 = prenlp.data.WikiText2()
>>> len(wikitext2)
3
>>> train, valid, test = prenlp.data.WikiText2()
>>> train[0]
'= Valkyria Chronicles III ='>>> imdb_train, imdb_test = prenlp.data.IMDB()
>>> imdb_train[0]
["Minor Spoilers<br /><br />Alison Parker (Cristina Raines) is a successful top model, living with the lawyer Michael Lerman (Chris Sarandon) in his apartment. She tried to commit ...", 'pos']Frequently used normalization functions for text pre-processing are provided in prenlp.
url, HTML tag, emoticon, email, phone number, etc.
General use cases are as follows:
>>> from prenlp.data import Normalizer
>>> normalizer = Normalizer(url_repl='[URL]', tag_repl='[TAG]', emoji_repl='[EMOJI]', email_repl='[EMAIL]', tel_repl='[TEL]', image_repl='[IMG]')
>>> normalizer.normalize('Visit this link for more details: https://github.com/')
'Visit this link for more details: [URL]'
>>> normalizer.normalize('Use HTML with the desired attributes: <img src="cat.jpg" height="100" />')
'Use HTML with the desired attributes: [TAG]'
>>> normalizer.normalize('Hello 🤩, I love you 💓 !')
'Hello [EMOJI], I love you [EMOJI] !'
>>> normalizer.normalize('Contact me at [email protected]')
'Contact me at [EMAIL]'
>>> normalizer.normalize('Call +82 10-1234-5678')
'Call [TEL]'
>>> normalizer.normalize('Download our logo image, logo123.png, with transparent background.')
'Download our logo image, [IMG], with transparent background.'Frequently used (subword) tokenizers for text pre-processing are provided in prenlp.
SentencePiece, NLTKMosesTokenizer, Mecab
>>> from prenlp.tokenizer import SentencePiece
>>> SentencePiece.train(input='corpus.txt', model_prefix='sentencepiece', vocab_size=10000)
>>> tokenizer = SentencePiece.load('sentencepiece.model')
>>> tokenizer('Time is the most valuable thing a man can spend.')
['▁Time', '▁is', '▁the', '▁most', '▁valuable', '▁thing', '▁a', '▁man', '▁can', '▁spend', '.']
>>> tokenizer.tokenize('Time is the most valuable thing a man can spend.')
['▁Time', '▁is', '▁the', '▁most', '▁valuable', '▁thing', '▁a', '▁man', '▁can', '▁spend', '.']
>>> tokenizer.detokenize(['▁Time', '▁is', '▁the', '▁most', '▁valuable', '▁thing', '▁a', '▁man', '▁can', '▁spend', '.'])
Time is the most valuable thing a man can spend.>>> from prenlp.tokenizer import NLTKMosesTokenizer
>>> tokenizer = NLTKMosesTokenizer()
>>> tokenizer('Time is the most valuable thing a man can spend.')
['Time', 'is', 'the', 'most', 'valuable', 'thing', 'a', 'man', 'can', 'spend', '.']Below figure shows the classification accuracy from various tokenizer.
- Code: NLTKMosesTokenizer, SentencePiece
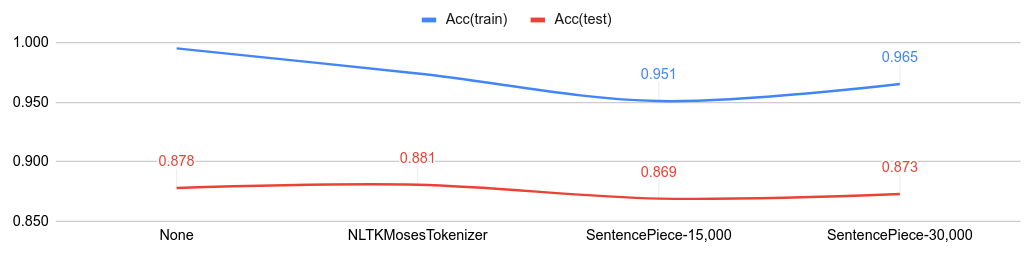
Below figure shows the classification accuracy from various tokenizer.
- Code: Mecab, SentencePiece
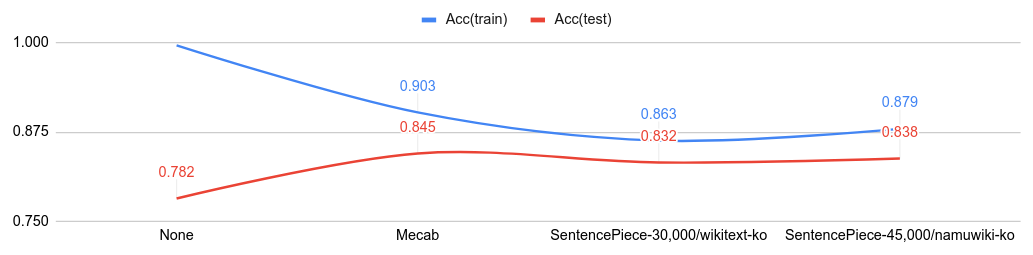
- Hoyeon Lee @lyeoni
- email : [email protected]
- facebook : https://www.facebook.com/lyeoni.f