Vehicle recognition using Single Shot Detector (SSD) in Autonomous Vehicles (AV's) was created as a final project for CSC 7991: Introduction to Deep Learning. The purpose of this project was to conduct experiments using a SSD to detect vehicles in nighttime, snowy, and drone videos. The goal is to demonstrate the SSD's ability to detect vehicles at varying distances in harsh conditions. The SSD for this project was implemented from its creators Wei Liu et al., which paper, model, and model setup is listed below.




By Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, Alexander C. Berg.
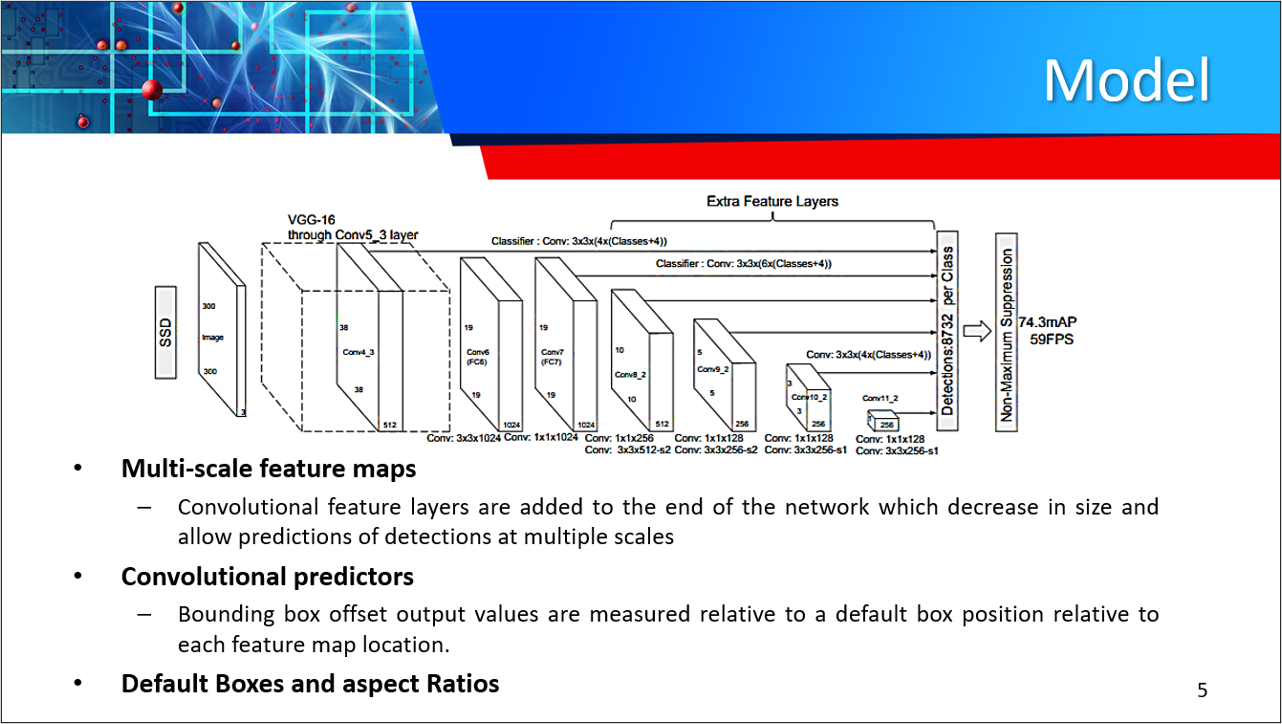
SSD is an unified framework for object detection with a single network. Authors Liu et al, have made the code available to train/evaluate a network for object detection task. For more details, please refer to our arXiv paper and slide link below. Our team decided on SSD because it is more fine grained compared to YOLO which is more suited for large object detection in a video or image. SSD is a feedforward convolutional network that uses a fixed number of bounding boxes and scores to attempt to detect VoC object classes within those bounding boxes. The VOC dataset consists of 11,530 training images. Finally a non-maximum suppression step to produce the final detections and remove overlapping bounding boxes. SSD is simple relative to methods that require object proposals because it completely eliminates proposal generation and subsequent pixel or feature resampling stages and encapsulates all computation in a single network.
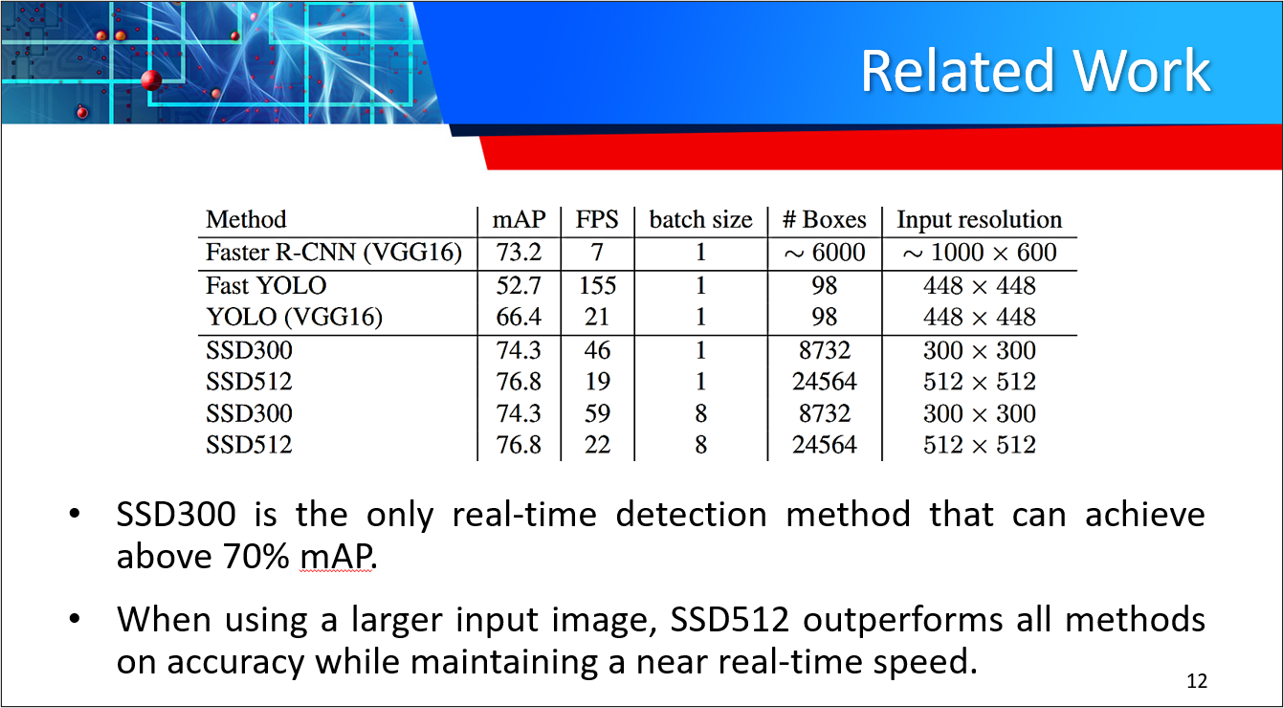
| System | VOC2007 test mAP | FPS (Titan X) | Number of Boxes | Input resolution |
|---|---|---|---|---|
| Faster R-CNN (VGG16) | 73.2 | 7 | ~6000 | ~1000 x 600 |
| YOLO (customized) | 63.4 | 45 | 98 | 448 x 448 |
| SSD300* (VGG16) | 77.2 | 46 | 8732 | 300 x 300 |
| SSD512* (VGG16) | 79.8 | 19 | 24564 | 512 x 512 |

Note: SSD300* and SSD512* are the latest models. Current code should reproduce these results.
SSD: Single Shot MultiBox Detector, Liu et al. arVix
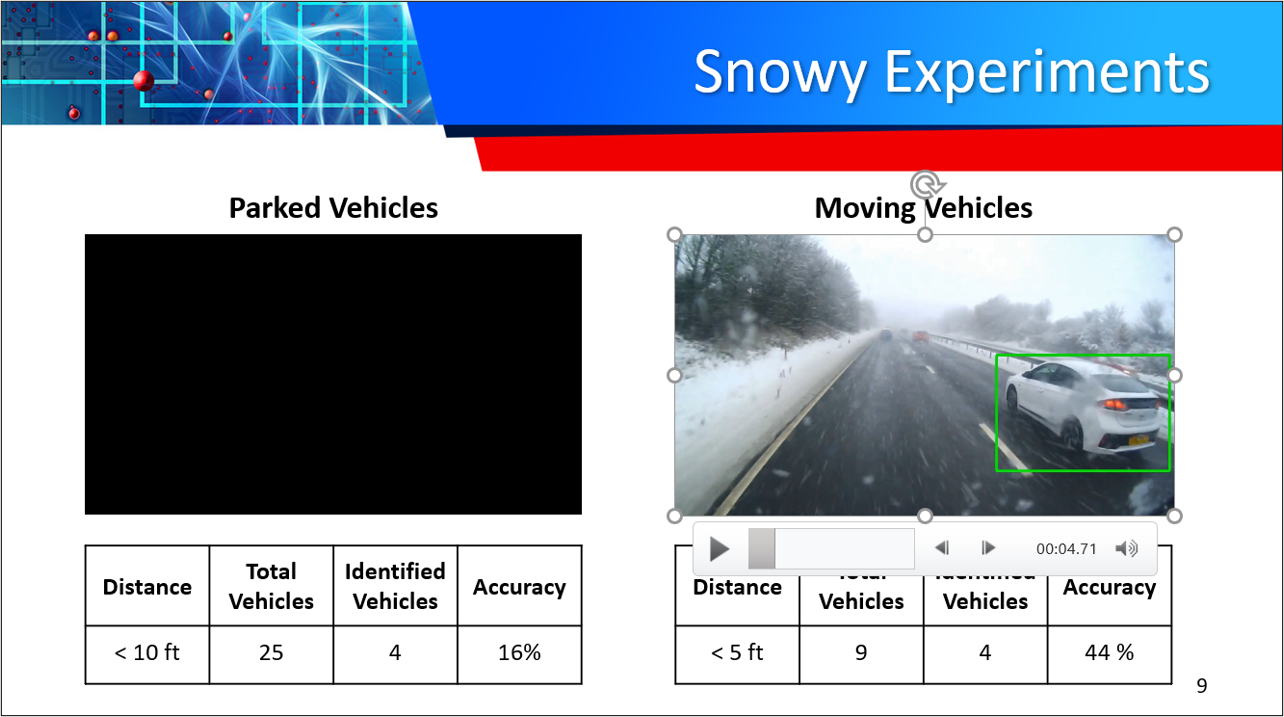
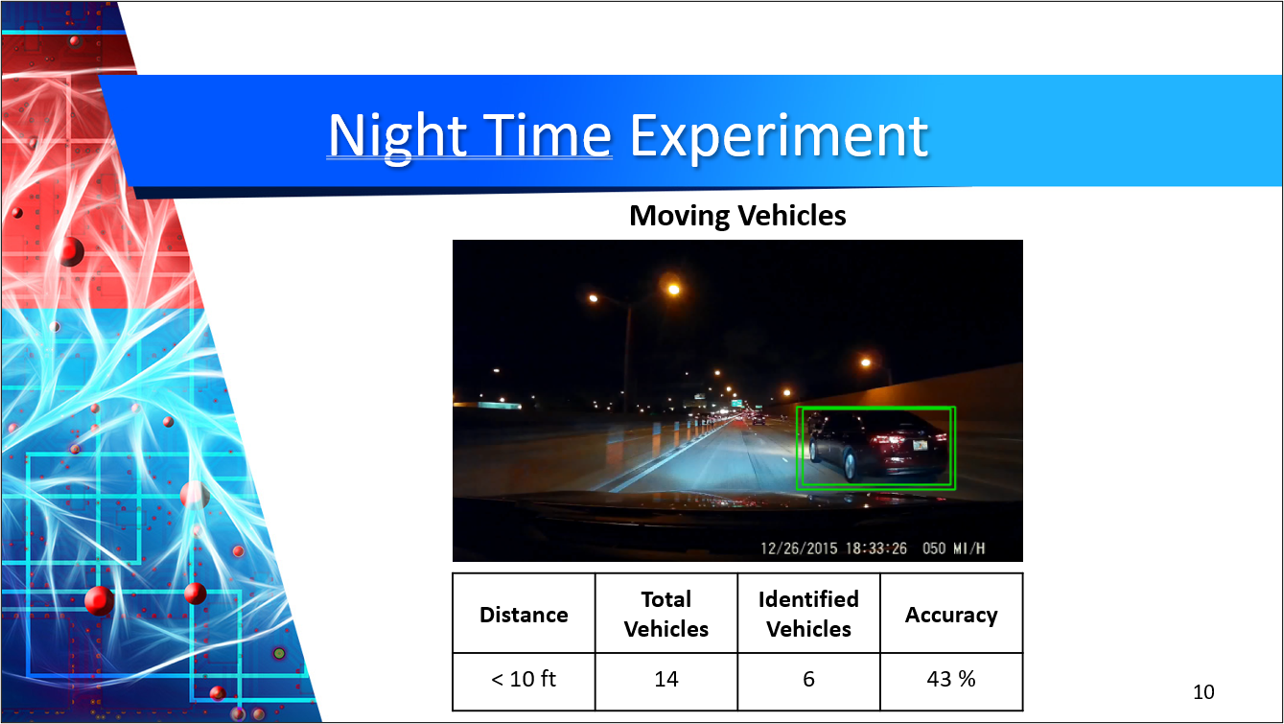
Safety comes from the autonomous vehicle being able to detect and respond to many traffic situations. The more input the computer can handle and analyze at a fast processing time will give the autonomous vehicle increased decision making. To visualize how a CNN performs on an input with poor weather conditions, our team gathered dashcam videos from Youtube of vehicles operating in harsh conditions. The input Youtube videos concentrate on snowy, and nighttime videos to apply Single Shot Detection (SSD) to classify the vehicles and bound them in green boxes.
The main advantages we believe this method will have are:
- Real Time Vehicle Detection: Ability to use live feed camera input into cycle GAN and CNN and using onboard CPU and GPU computing to visualize vehicles on the road in real time.
- In-network Architecture: All components in our method are within one network and trained in an end-to-end fashion.
- Data Augmentation: 720p video input is resized to 300x300x3 image segments which at a much lower resolution and requires less storage and computing power.









| Conditions | Accuracy |
|---|---|
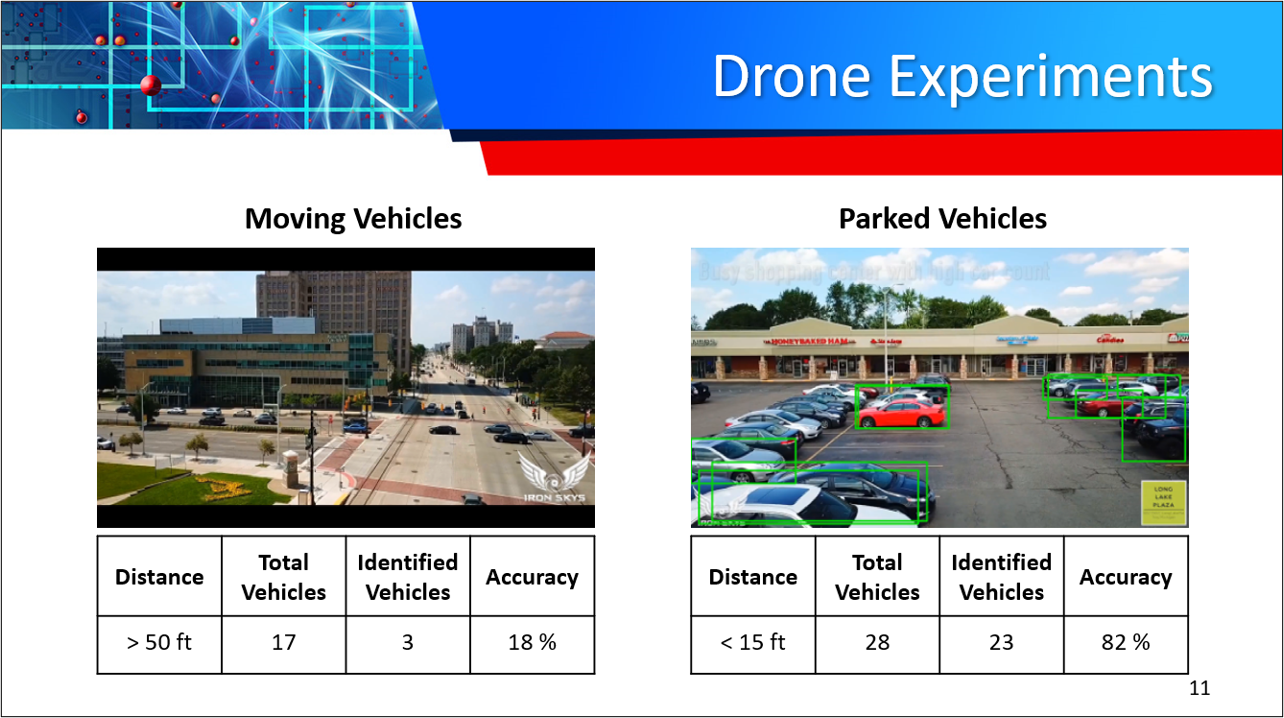
| Drone Aerial | 18% |
| Drone Parking Lot | 82% |
| Nighttime | 43% |
| Snow Moving | 44% |
| Snow Parked | 17% |
Our preliminary results using SSD for object detection has exceeded project expectations. Our observed results include: Snowy – 44% and 16%, Night time – 43%, and Drone – 18% and 82%. GANs and SSDs are still a developing technology which comes with many challenges including: Unproven technology, no economies of scale, and CPU/GPU limitations.
We proposed the implementation of a single-shot detection (SSD) for vehicle recognition. SSD's provide an advantage for real-time vehicle detection, in-network architecture, and data augmentation that uses on-board computing within one network to resize video images. The SSD, is a fast single-shot object detector for multiple categories. SSD's are a feed-forward convolutional network that uses a fixed number of bounding boxes and scores to detect VoC object classes using bounding boxes. A key feature of our experiments is the use of bounding box outputs attached to multiple feature maps trained from VoC dataset against night time, snowy, and drone videos. The experiment conducted used VOC dataset with SSDs 11,530 training images. The inputs for the experiments were dashcam videos from YouTube tested with CNN using SSD for vehicle box bounding area. With similar technological impacts, GAN's and SSD's are promising for the development of Advanced Driving Assistance Systems (ADAS), military transportation and bomb disposal, and emergency applications. A future direction is to explore its use as part of a system using recurrent neural networks to detect and track objects in video simultaneously.
@inproceedings{liu2016ssd,
title = {SSD: Single Shot MultiBox Detector},
author = {Liu, Wei and Anguelov, Dragomir and Erhan, Dumitru and Szegedy, Christian and Reed, Scott and Fu, Cheng-Yang and Berg, Alexander C.},
booktitle = {ECCV},
year = {2016}
}- Get the code. We will call the directory that you cloned Caffe into
$CAFFE_ROOT
git clone https://github.com/kyle-w-brown/vehicle-recongition-ssd.git
cd caffe
git checkout ssd- Build the code. Please follow Caffe instruction to install all necessary packages and build it.
# Modify Makefile.config according to your Caffe installation.
cp Makefile.config.example Makefile.config
make -j8
# Make sure to include $CAFFE_ROOT/python to your PYTHONPATH.
make py
make test -j8
# (Optional)
make runtest -j8-
Download fully convolutional reduced (atrous) VGGNet. By default, we assume the model is stored in
$CAFFE_ROOT/models/VGGNet/ -
Download VOC2007 and VOC2012 dataset. By default, we assume the data is stored in
$HOME/data/
# Download the data.
cd $HOME/data
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar
# Extract the data.
tar -xvf VOCtrainval_11-May-2012.tar
tar -xvf VOCtrainval_06-Nov-2007.tar
tar -xvf VOCtest_06-Nov-2007.tar- Create the LMDB file.
cd $CAFFE_ROOT
# Create the trainval.txt, test.txt, and test_name_size.txt in data/VOC0712/
./data/VOC0712/create_list.sh
# You can modify the parameters in create_data.sh if needed.
# It will create lmdb files for trainval and test with encoded original image:
# - $HOME/data/VOCdevkit/VOC0712/lmdb/VOC0712_trainval_lmdb
# - $HOME/data/VOCdevkit/VOC0712/lmdb/VOC0712_test_lmdb
# and make soft links at examples/VOC0712/
./data/VOC0712/create_data.sh- Train your model and evaluate the model on the fly.
# It will create model definition files and save snapshot models in:
# - $CAFFE_ROOT/models/VGGNet/VOC0712/SSD_300x300/
# and job file, log file, and the python script in:
# - $CAFFE_ROOT/jobs/VGGNet/VOC0712/SSD_300x300/
# and save temporary evaluation results in:
# - $HOME/data/VOCdevkit/results/VOC2007/SSD_300x300/
# It should reach 77.* mAP at 120k iterations.
python examples/ssd/ssd_pascal.pyIf you don't have time to train your model, you can download a pre-trained model at here.
- Evaluate the most recent snapshot.
# If you would like to test a model you trained, you can do:
python examples/ssd/score_ssd_pascal.py- Test your model using a webcam. Note: press esc to stop.
# If you would like to attach a webcam to a model you trained, you can do:
python examples/ssd/ssd_pascal_webcam.pyHere is a demo video of running a SSD500 model trained on MSCOCO dataset.
-
Check out
examples/ssd_detect.ipynborexamples/ssd/ssd_detect.cppon how to detect objects using a SSD model. Check outexamples/ssd/plot_detections.pyon how to plot detection results output by ssd_detect.cpp. -
To train on other dataset, please refer to data/OTHERDATASET for more details. We currently add support for COCO and ILSVRC2016. We recommend using
examples/ssd.ipynbto check whether the new dataset is prepared correctly.
We have provided the latest models that are trained from different datasets. To help reproduce the results in Table 6, most models contain a pretrained .caffemodel file, many .prototxt files, and python scripts.
-
PASCAL VOC models:
-
COCO models:
-
ILSVRC models:
[1]We use examples/convert_model.ipynb to extract a VOC model from a pretrained COCO model.
Single Shot MultiBox Detector implemented with TensorFlow
python3.6.1
- numpy
- skimage
- TensorFlow
- matplotlib
- OpenCV
- Import required modules
import tensorflow as tf
import numpy as np
from util.util import *
from model.SSD300 import *
- Load test-image
img = load_image('./test.jpg')
img = img.reshape((300, 300, 3))
- Start Session
with tf.Session() as sess:
ssd = SSD300(sess)
sess.run(tf.global_variables_initializer())
for ep in range(EPOCH):
...
- Training or Evaluating you must just call ssd.eval() !
...
_, _, batch_loc, batch_conf, batch_loss = ssd.eval(minibatch, actual_data, is_training=True)
...
you have to extract data-set from zip files. decompress all zip files in datasets/ and move to voc2007/ dir.
$ ls voc2007/ | wc -l # => 4954
$ ./setup.sh
$ python train.py

{kind=link}