-
Notifications
You must be signed in to change notification settings - Fork 33
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
1 parent
4265c16
commit 2e06c50
Showing
1 changed file
with
19 additions
and
0 deletions.
There are no files selected for viewing
19 changes: 19 additions & 0 deletions
19
app/_posts/2025-01-30-preserving-public-u-s-federal-data.md
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,19 @@ | ||
| --- | ||
| title: Preserving Public U.S. Federal Data | ||
| guest-author: Library Innovation Lab Team | ||
| --- | ||
|  | ||
|
|
||
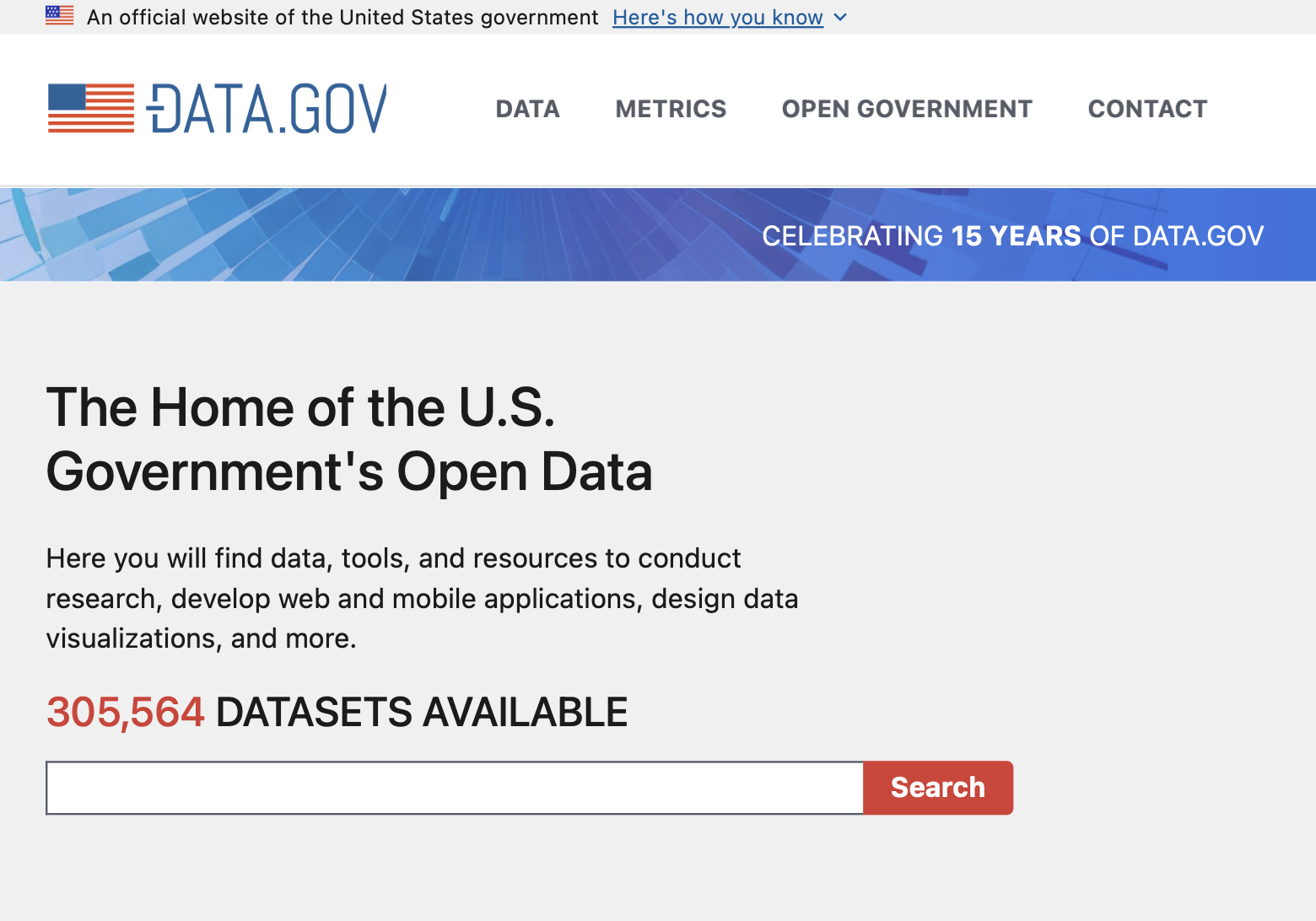
| In recent months the Harvard Law School Library Innovation Lab has created a data vault to download, sign as authentic, and make available copies of public government data that is most valuable to researchers, scholars, civil society and the public at large across every field. To begin, we have collected major portions of the datasets tracked by data.gov, federal Github repositories, and PubMed. | ||
|
|
||
| The Harvard Law School Library has collected government records and made them available to patrons for centuries, and this continues that work. | ||
|
|
||
| We know from our web archiving project, [Perma.cc](http://perma.cc), which preserves millions of links used by courts and law journals, that government documents often change or go away. And we know from our [Caselaw Access Project](http://case.law), which produced free and open copies of nearly all US case law from the inception of each state and Federal court, that collecting government documents in new forms can open up new kinds of research and exploration. | ||
|
|
||
| This effort, focusing on datasets rather than web archives, collects and will make available hundreds of thousands of government datasets that researchers depend on. This work joins the efforts of many other organizations who preserve public knowledge. | ||
|
|
||
| As a first step, we have collected the metadata and primary contents for over 300,000 datasets available on data.gov. As often happens with distributed collections of data, we have observed that [linkrot](http://https://perma.cc/D29D-MV4L) is a pervasive problem. Many of the datasets listed in November 2024 contained URLs that do not work. Many more have come and gone since; there were 301,000 datasets on November 19, 307,000 datasets on January 19, and 305,000 datasets today. This can naturally arise as websites and data stores are reorganized. | ||
|
|
||
| In coming weeks we will share full data and metadata for our collection so far. We look forward to seeing how our archive will be used by scholarly researchers and the public. | ||
|
|
||
| To notify us of data you believe should be part of this collection please contact us at [[email protected]](mailto:[email protected]). |