涅普提努开发的小型 RPC 框架
参考资料: 掘金小册:《Java 开发者 RPC 实战课》 极客时间:《RPC 实战核心原理》 JavaGuid《从零开始实现 RPC 框架》
如何实现不同服务间的相互调用?
RPC (Remote Procedure Call ) 全称为远程过程调用,主要负责解决处于不同服务器上的系统相互调用的问题;分布式系统中各个服务之间不可避免的存在相互调用的情况,可是因为各个服务都处于不同的操作系统,所以无法直接通过内存实现调用本地方法;所以最终就只能将调用方法的语义通过网络传输到其他服务执行,然后在其他服务处理完调用后再将响应通过网络传输到本地
如果完全手动采用网络编程来实现方法调用的交互过程是非常麻烦的,需要考虑 连接方式 (TCP / UDP)、寻址方式、序列化协议、编码协议等等内容,所以 RPC 框架出现的目的就是简化远程过程调用的复杂度
RPC 框架主要由哪些部分组成?
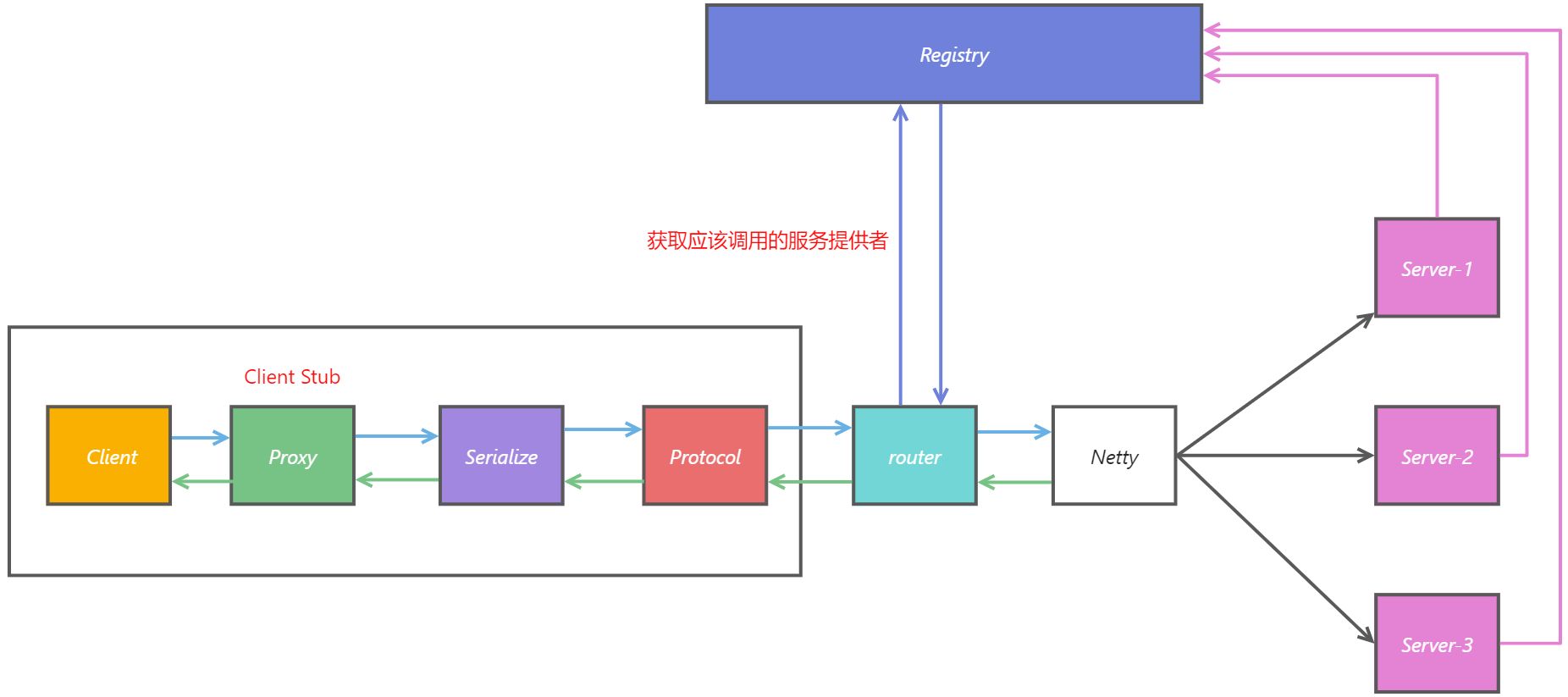
RPC 框架核心主要由客户端 + 网络 + 服务器端三部分组成,通常还要提供负载均衡、注册中心、熔断限流等服务
- 客户端主要由客户端应用和客户端桩 (Stub) 两个部分组成
- 客户端应用:发起远程过程调用方
- 客户端 Stub:负责将调用方法、调用参数等信息封装成协议消息体后通过网络发送到服务端
- 利用动态代理生成代理类,然后代理类采用序列化将需要调用的方法和传递的参数封装成消息体
- 然后使用编码协议将原有的代码转为和语言无关的数据,最后通过网络框架找到服务器地址发送数据
- 网络传输:网络传输就是负责将传递客户端和服务器发送的数据 (原生实现 Socket / 框架实现 Netty)
- 服务器端主要也是由服务端应用和服务端桩 (Stub) 两个部分组成
- 服务器端应用:提供远程过程调用方
- 服务器端 Stub:负责接收客户端发送的协议消息体,然后通过反射执行相应的方法
- 从网络中接收到数据采用解码协议解码,然后将数据反序列化成消息体,然后反射调用方法执行
- 最后将反射执行的结果封装成响应消息,再通过网络框架序列化发送给客户端
RPC 框架可以采用哪两种实现方式?两者有什么区别和联系?
RPC 框架本质就是用于各个服务实现相互调用的网络通信框架,也就是说如果要实现 RPC 框架,那么就需要基于网络协议实现各个结点间的通信;传输层的 TCP 协议和应用层的 HTTP 协议本质都是可以实现各个结点间的网络通信的,那么也就意味着 RPC 框架就是可以采用 TCP 协议或者 HTTP 协议来实现:

- RPC 框架没有出现前:各个服务间的相互调用通常都是采用 HTTP 协议实现的
- RPC 框架:Dubbo、Thrift 是采用 TCP 协议实现的,SpringCloud、gRPC 是采用 HTTP 协议实现的
- 自研框架:我自己研发的 Neptune RPC 框架也是基于 TCP 协议实现的
基于 HTTP 协议和基于 TCP 协议的区别:
- 使用方式:基于 HTTP 协议封装性好,调用起来简单,天生跨语言;基于 TCP 协议实现是完全自定义,相对复杂
- 连接方式:基于 HTTP 协议默认就是短连接,频繁通信就会有大量的断开重连开销;基于 TCP 是天生的长连接
- 传输协议:基于 HTTP 协议就意味着协议格式无法改变,基于 TCP 的协议那么就可以自定义协议格式的扩展
- HTTP 协议基本采用请求头 + 请求体的方式设计协议,格式完全固定,无法根据需求自定义
- TCP 协议则是可以基于魔术 + 长度 + 序列号 + 协议版本 + 消息类型 + 序列化方式的模板自定义构建
- 传输效率:HTTP 协议在后续版本中已经提供不少的改进,但是整体效率还是低于基于 TCP 协议的框架
- HTTP 协议只能采用文本的形式传输请求头,会造成很多无效数据的传输,并且存在安全问题
- TCP 协议完全采用二进制的方式传输首部信息,占用的空间会更小,相应的效率也会更高
- 序列化协议:HTTP 协议和 TCP 协议本质都可以采用文本或者二进制序列化的方式,不过通常 HTTP 还是采用 JSON
- HTTP 协议主要采用 JSON 序列化协议来实现数据传输,本质还是以文本的形式传输,效率会相对较低
- TCP 协议主要采用 Protobuf、Hessian 这样的二进制序列化方式实现数据传输,整体效率更高
- 负载均衡:无论是采用 HTTP 还是 TCP 构建 RPC,理论都可以构建服务治理相关的功能 (熔断限流、注册中心等功能)
- HTTP 协议通常都是采用 Nginx 类似的组件来实现负载均衡策略,使用起来相对简单
- TCP 协议通常都是自定义负载均衡的算法然后去实现,构建起来相对麻烦

| 框架 | Dubbo | gRPC | Thrift | SpringCloud |
|---|---|---|---|---|
| 设计方 | 阿里 | Spring | ||
| 支持语言 | Java | 任何语言 | 任何语言 | Java |
| 序列化框架 | dubbo、rmi、hessian、http、thrift、redis | protobuf | thrift | json |
| 注册中心 | zookeeper、redis、simple、multicast | 无 | 无 | eureka、zookeeper、consul、nacos |
| 服务治理 | 轻量级 | 无 | 无 | 全套解决方案 |
理论上所有项目在开始编码前都应该有最基本的技术方案设计,这样才能够确保在开发的过程中有最基本的逻辑,否则很容易在开发的过程中出现推倒重来的情况;不过合理的技术方案或者框架设计是非常吃个人能力的,所以不要指望从一开始就设计出非常合理的架构,优秀的架构从来都是不断迭代得出的
RPC 框架的核心其实只有网络通信,非核心的服务治理就是注册中心、负载均衡、容错处理、熔断限流等部分组成;最简单的就是 Thrift 这样仅提供网络通信功能的 RPC 框架,相对复杂的就是 Dubbo 这样提供网络通信、注册中心、负载均衡、容错处理的 RPC 框架,最复杂的就是 SpringCloud 这样全套的 RPC 解决方案;这里主要就是仿照 Dubbo 进行实现
注:太简单或者太复杂都没有太多的意义,并且中文互联网中仿照 Dubbo 实现的资料也比较多
- 网络通信
简单来说,网络通信的过程主要分为发送和接收两部分:(1) 客户端调用服务端时将需要调用的接口、调用的方法和方法参数等内容都封装好后调用网络通信接口发送到服务端 (2) 服务端处理完请求后返回响应,客户端就将接收到的响应中携带的数据给提取出来
- 动态代理:本质降低客户端和网络通信框架间的耦合度并且提升框架的可扩展性
本质上可以将发送和接收行为封装成方法,然后在每次客户端和服务端进行网络通信时就直接调用方法,可是这样就会导致客户端直接和网络通信框架交互,明显会增加框架的耦合度;如果采用代理类来负责维护发送和接收的行为,那么客户端就完全看不到实现的细节,全权由代理类负责实现
动态代理的实现手段:(1) 采用现成的实现方式 (2) 自己编写
- JDK 动态代理 (CGLIB 动态代理是无法使用,服务端仅提供接口)
- Javassist 框架手动实现动态代理

- 序列化协议:本质就是将文本数据和二进制数据之间相互转换的框架,核心就是用于网络传输
客户端的动态代理类发送的数据只能采用二进制形式在网络中传输,那么就需要相应的序列化协议将传输内容序列化成二进制数据,然后再封装成相应的数据报提交给网络通信框架进行传输 (如果在网络通信框架中进行序列化,那么其实也是可以的)
序列化框架:(1) 采用现成的框架 (2) 手写序列化协议 (没有太多必要,效率很低)
- JDK 序列化:最简单的序列化方式,效率也是最低的
- JSON 序列化:文本序列化的方式,还需要调用转换字节的方法才行
- Kryo 序列化:最好用也是性能较高和序列化数据体积较小的
- Hessian 序列化:相对比较老旧的框架,但是性能依然比较高而且体积比较小
-
Protobuf、Avro、Thrift 序列化

- 传输协议:协议本质就是确保通信双方能够识别有效或者合法的消息,避免存在的黏包半包等问题,核心就是标准化
基于 TCP 的 RPC 矿机的传输协议非常灵活,可以任意添加或者修改传输协议模板中的字段来满足 RPC 框架的需要;传输协议的基本模板主要包含七个部分:魔数字段 + 协议版本号 + 消息序列号 + 消息类型 + 序列化协议 + 消息长度 + 消息正文 (如果不提供多种序列化方式,那么就没有必要保留序列化协议这个字段)

- 网络通信:本质就是负责处理客户端和服务端之间的调用请求,是整个 RPC 框架的基石
网络通信不仅需要保证客户端和服务端之间可以正常通信,其实还需要维护在客户端和服务端之间建立的长连接 (定期发送心跳检测来判断服务端是否存活),并不是发送和响应完调用请求连接就会断开的 (不同于 HTTP 请求)
Netty:入门篇
- 注册中心:本质就是协调客户端和服务端之间的调用关系,不过分布式协调服务不止提供这个功能
分布式式集群系统中通常都会由集群中的多个服务器提供相同或不同的服务,如果在分布式集群的环境下依然让客户端直接面向服务端调用,那么只要服务端的配置数据 (IP 地址) 发生变化就会迫使客户端重新配置相应的数据,这就造成整个框架耦合度比较高
此时分布式协调服务 (注册中心) 就可以完美解决这个问题,所有的客户端都从注册中心获取服务提供者的信息后再去调用服务而不再是直接调用服务;注册中心负责对服务的上下线以及修改进行监控 (服务发现 + 服务发现 + 服务修改) ,那么即使服务提供者发生变化,那么客户端本身也不会直接受到影响
注册中心的主流实现框架:
- Zookeeper:几乎绝大多数的服务治理框架都是这个来进行实现
- Nacos:SpringCloud 强推的分布式协调框架,后续考虑接入
- Eureka:SpringCloud 貌似现在已经不再推荐使用 Eureka 作为注册中心了

- 负载均衡:本质就是替客户端选择合适的服务端进行通信,也就是选择压力最小的服务端通信
客户端可以从注册中心获取到所有在线或者说已经注册过的服务提供者,那么客户端就需要选择合适的服务提供者来调用提供的服务;如果没有负载均衡,那么很有可能出现所有调用请求全部打入相同机器,从而导致服务器端完全瘫痪;因此合适的负载均衡策略能够保证请求不会过于集中,从而减轻服务器的压力
负载均衡主要有两种实现方式,RPC 框架通常都是手动实现:
- 完全随机策略:直接调用随机函数来选择调用哪个服务器
- 加权随机策略:根据服务端的权重值 + 随机函数来选择调用哪个服务器
- 完全轮询策略:根据服务端的注册顺序依次调用
- 加权轮询策略:根据服务端的权重 + 注册顺序来进行调用
- 平滑加权轮询
- 一致性哈希算法
- 容错处理