4. 数据清洗
数据清洗是一种任务,包括几十个子模块, 这些子模块包含四类:生成, 转换, 过滤和执行。

数据清洗可以通过组合多个不同的子模块,生成多样的功能,通过拖拽构造出一个工作流,它能够产生一个有限或无限的文档序列。比如下面:
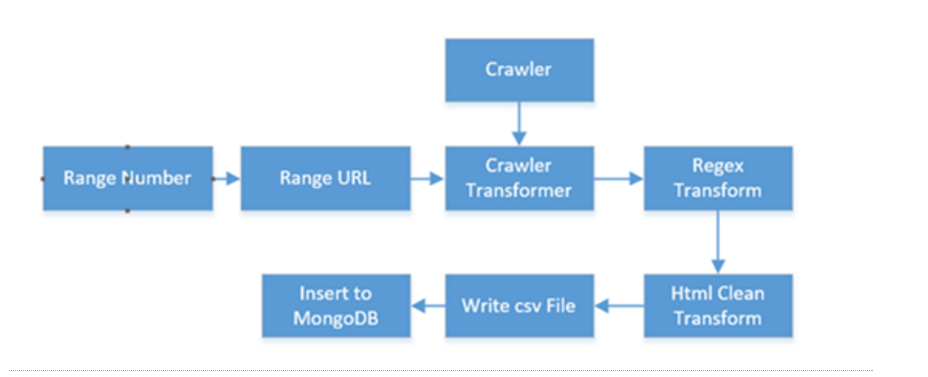
拖入的模块顺序是非常重要的,一个常见问题是顺序不对,导致生成的数据不符合预期。数据清洗可通过从爬虫转换来调用网页采集器,也可以通过子任务来调用其他数据清洗,是组合各种模块和任务的工厂。
基本概念:
- 列名: 一个模块的输入,如果有多个输入,中间可以用空格分割
- 新列名: 一个模块的输出, 有些模块的
新列名有自己的定义
本例子不包含爬虫,仅演示清洗的部分功能:
- 拖入(不是双击)生成区间数,添加一列,列名叫A,范围为1-20,间隔为1:
- 再拖入另外一个生成区间数,列名为B,范围1-40,间隔为2,注意生成模式为Merge。
- 向B列拖入数值过滤器,最大值和最小值分别为30和20
- 拖入写入数据表,表名随意填写
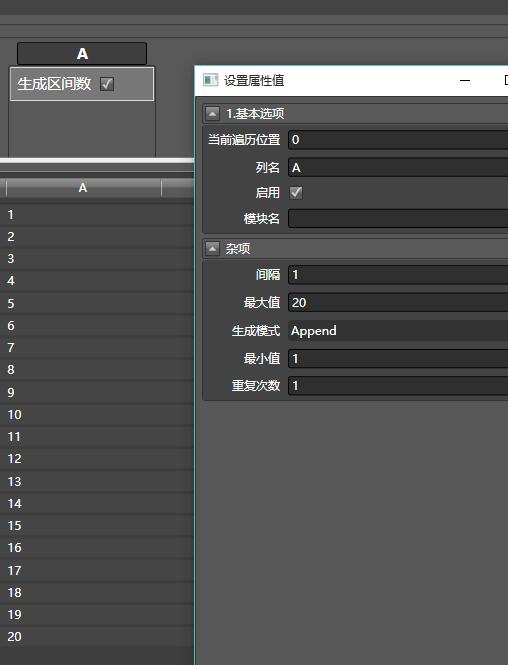
点击执行,查看生成的表格。
从这个例子我们可以看出数据清洗的一般模式。将一个模块拖入到一列,该模块就会作用到该列上。四类模块的详细使用方法,将会在各自的文档中说明。
为在编辑任务的过程中,处于调试模式,它具备如下特点:
- 所有执行器都不工作,避免副作用
- 点击下方中间的刷新按钮,或修改配置,展示的数据会自动刷新
- 只能运行在串行模式上
- 所见即所得,只显示一定数量的数据(通过采样量修改)
- 可以禁用或启用某些模块,观察效果
- 会加入web请求和读取文件的缓存, 来提升预览速度(可能会导致一些问题)
- 输入列和输出列会用不同的颜色进行表示
在调试时,从爬虫转换模块可能会请求web数据,为了提升性能,该模块对请求做了缓存。保证数据只需获取一次,如果想强制刷新数据,将从爬虫转换模块禁用,再启用,原始缓存数据就会被擦除。
Hawk模仿了播放器和调试器,在调试模式下有步的概念,例如所在位置是6/20, 则说明总共有20个模块,只展现前面6个模块的效果。 可以通过左右单击,或直接回退到开头、末尾来进行调试。在当前步拖入模块,模块会在本步之后的位置插入。
步的概念,同样会出现在子任务中
左侧显示了当前所有的模块,顺序和它们的输入输出列,双击上面的模块可对其进行配置,右键可删除,上下移动这些模块。

有时为了在单步调试过程中查看模块的属性,可勾选界面右下角的调试详情,此时可直接显示当前模块所在的属性。
下面举一个单步调试的例子:已经编写的工作流,可能会因为某些外界环境的变化而出错,此时需要排除错误,我们可以使用单步调试:还是上面A+B=C的例子:
在属性对话框,调试窗口里,填写模块数量为1,点击刷新结果,此时,系统会只执行第一步,显示A列。
点击单步调试,模块数量变为2,显示A和B列。
本质上,单步调试只是提取了工作流的一部分进行操作,你可以在单步调试中,拖入新的模块。模块会自动插入在工作流中间。

只有点击执行时,才会切换到执行模式。执行时,可工作在串行/并行模式。
在串行模式下, 所有任务串行执行,速度慢,但对网站压力小,不容易被封锁。为了进一步降低执行速度,还可以拖入延时,此时每产出一份文档,都会等待指定的时间。
当执行器包含类似"向文件中追加内容"的操作时,强烈建议使用串行模式,因为Hawk没有加入多线程锁,有可能会导致冲突。
建议完成爬虫设计后,先进行串行模式,初步观察是否正确,之后再设置并行模式大量抓取。
并行模式: 极大地加快了抓取速度,但很容易被封锁。 由于Hawk的并行模式有些许复杂,可以在4.6 并行化中获得更全面的信息。
不论是调试还是执行模式,系统都会在任务管理视图中增加一个或多个任务。 你可以勾选,或取消勾选部分或全部任务,暂停或取消它们。当网站限制抓取时,可以暂停所有任务,等恢复后再次执行。
- 注意 当你设计的工作流有误时(比如该列所有数据都空,却在该列添加了【空对象过滤器】,那么所有数据都会被过滤)可能不会产生任何数据输出。此时进度条并不会向前推进,可行的方法就是将其取消掉。
任务取消和暂停机制是基于流模式的,例如一个执行1000次算法A的循环,在执行完某次后即可取消,但如果算法A执行一次消耗的时间非常长,那么系统是无法在算法A执行过程中取消的。此时,即使你点击了取消,任务还是会保留在队列中。因此,建议循环中的任意一个处理单元,都不要做过于复杂的操作。
Hawk可以嵌入Python,从而支持精细的控制,实现用图形界面难以操作的功能。Hawk使用IronPython作为解释器,其语法和Python3接近。
在定制抓取任务时,我们可以在界面上双击模块,修改工作流的参数,如采集不同城市的数据,之后再进行保存。 但这种做法比较麻烦,容易出错。因此,我们可以在工程文件的同一级目录放置Python脚本,在加载任务时,脚本会自动执行。
数据清洗的本质是动态组装Linq,其数据链为IEnumerable<IFreeDocument>。 IFreeDocument是 IDictionary<string, object>
接口的扩展。 Linq的Select函数能够对流进行变换,在本例中,就是对字典不同列的操作(增删改),不同的模块定义了一个完整的Linq
流:
result= source.Take(mount).where(d=>module0.func(d)).select(d=>Module1.func(d)).select(d=>Module2.func(d))….
借助于C#编译器的恩赐, Linq能很方便地支持流式数据,即使是巨型集合(上亿个元素),也能够有效地处理。
由于Python没有Linq, 因此组装的是生成器(generator), 对生成器进行操作,即可定义出类似Linq的完整链条:
for tool in tools:
generator = transform(tool, generator)
详细源代码,可以参考Github上的开源项目https://github.com/ferventdesert/etlpy/