{kind=link}
{kind=link}
The capability to ingest thousands or millions of records per second while allowing for simultaneous queries in real time is required by many use cases across multiple industries, e.g. equity trade processing, fraud detection, IoT applications including anomaly detection and real time OEE, etc. Gartner calls this capability "HTAP" (Hybrid Transactional Analytical Processing). Others such as Forrester call it Translytics. InterSystems IRIS is a powerful, scalable, high performance and resource efficient transactional-analytic data platform that provides the performance of in-memory databases with the consistency, availability, reliability and lower costs of traditional databases.
This demo shows how InterSystems IRIS can ingest thousands of records per second while allowing for simultaneous queries on the data on the same cluster with very high performance for both ingestion and querying, and with low resource utilization. The demo works on a single InterSystems IRIS instance or on an InterSystems IRIS cluster on the cloud.
The same demo can be run on SAP HANA, MySQL, SqlServer and Amazon Aurora to compare performance and resource utilization in “apples-to-apples” comparisons.
You can run the tests on AWS! Here are some results:
- InterSystems IRIS x SAP HANA Express 2.0 run on AWS. InterSystems IRIS:
- Ingested 59.9% more records
- Was ingesting them 59.9% faster in average
- Retrieved 2732.8% more records
- Was retrieving them 2732.1% faster in average
- InterSystems IRIS x AWS Aurora (MySQL) 5.6.10a (parallel query). InterSystems IRIS:
- Ingested 1456.7% more records
- Was ingesting them 1456.3% faster
- Retrieved 360.9% more records
- Was retrieving them 360.7% faster
- InterSystems IRIS x AWS RDS SQL Server 2017. InterSystems IRIS:
- Ingested 466% more records
- Was ingesting them 465.9% faster
- Retrieved 3688164.7% more records!!
- Was retrieving them 3567650.8% faster!! - clearly there is something wrong with SQL Server
- InterSystems IRIS x Sybase ASE 16.0 SP03 PL08, public cloud edition, premium version. InterSystems IRIS:
- Ingested 4862.8% more records
- Was ingesting them 6733.4% faster AEOT
- Retrieved 3282% more records
- Was retrieving them 5654.6% faster AEOT
- InterSystems IRIS x AWS RDS PostgreSQL 12.3. InterSystems IRIS:
- Ingested 110.2% more records
- Was ingesting them 108.2% faster AEOT
- Retrieved 592.7% more records
- Was retrieving them 718% faster AEOT
- InterSystems IRIS x AWS MariaDB. InterSystems IRIS:
- Ingested 620.9% more records
- Was ingesting them 717.3% faster AEOT
- Retrieved 313.6% more records
- Was retrieving them 296.5% faster AEOT
- InterSystems IRIS x AWS RDS Oracle Enterprise 19.0. InterSystems IRIS:
- Ingested 402.1% more records
- Was ingesting them 400.3% faster
- Retrieved 176.3% more records
- Was retrieving them 176.2% faster
You can run the tests on your own PC using Dockers (3 CPUs and 7GB of RAM)! Here are some results:
- InterSystems IRIS x MySQL 8.0:
- InterSystems IRIS ingests 3043% more records than MySQL 8.0
- InterSystems IRIS is 643% faster than MySQL 8.0 at querying
- InterSystems IRIS x SQL Server 2019 for Ubuntu
- InterSystems IRIS ingests 223% more records than faster than SQL Server 2019
- InterSystems IRIS is 134,632% faster (really, not a typo) than SQL Server 2019 at querying.
- To be fair, we will be testing SQL Server on AWS and Azure in the future. Stay tuned!
Follow this link to see instructions on how to run this Speed Test on AWS comparing InterSystems IRIS with other databases such as SAP HANA and AWS Aurora.
The pre-requisites for running the speed test on your PC are:
- Docker and Docker Compose
- Git - If you want to run all the the tests on your PC or in AWS. If you just want to run the test with InterSystems IRIS, you may not need git.
You can currently run this demo on your PC with InterSystems IRIS, MySQL, SqlServer and SAP HANA.
To run the demo on your PC, make sure you have Docker installed on your machine. You can quickly get it up and running with the following commands on your Mac or Linux PC:
wget https://raw.githubusercontent.com/intersystems-community/irisdemo-demo-htap/master/docker-compose.yml
docker-compose upIf you are runing on Windows, download the docker-compose.yml file to a folder. Open a command prompt and change to that folder. Then type:
c:\MyFolder\docker-compose upYou can also clone this repository to your local machine using git to get the entire source code. You will need git installed and you would need to be on your git folder:
git clone https://github.com/intersystems-community/irisdemo-demo-htap
cd irisdemo-demo-htap
docker-compose upBoth techniques should work and should trigger the download of the images that compose this demo and it will soon start all the containers.
When starting, you will see lots of messages from all the containers that are staring. That is fine. Don't worry!
When it is done, it will just hang there, without returning control to you. That is fine too. Just leave this window open. If you CTRL+C on this window, docker compose will stop all the containers and stop the demo.
After all the containers have started, open a browser at http://localhost:10000 to see the demo UI.
Just click on the Run Test button to run the HTAP Demo! It will run for a maximum time of 300 seconds or until you manually stop it.
If you want to change the maximum time to run the test, click the Settings button at the top right of the UI. Change the maximum time to run the speed test to whatever you want.
After clicking on Run Test, it should immediately change to Starting.... If you are testing InterSystems IRIS or SQL Server, it may stay on this status for a long time since we are pre-expanding the database to its full capacity before starting the test (something that we would normally do on any production system). InterSystems IRIS is a hybrid database (In Memory performance with all the benefits of traditional databases). So InterSystems IRIS still needs to have its disk database properly expanded. Just wait for it. For some databases, we could not find a way of doing this right from start (Aurora and MySQL) so what we did was to run the Speed Test once to "warm it up". Then we run it again (which causes the table to be truncated) with the database warmed up.
Warning: InterSystems IRIS Database expansion can take some time. Fortunately, when running on your PC, we will pre-expand the database only to up to 9Gb since InterSystems IRIS Community has a limit on the database size.
When the test finishes running, a green button will appear, allowing you to download the test results statistics as a CSV file.
When you are done testing, go back to that terminal and enter CTRL+C. You may also want to enter with the following commands to stop containers that may still be running and remove them:
docker-compose stop
docker-compose rmThis is important, specially if you are going back and forth between running the speed test on one database (say InterSystems IRIS) and some other (say MySQL).
To run this demo against MySQL:
wget https://raw.githubusercontent.com/intersystems-community/irisdemo-demo-htap/master/docker-compose-mysql.yml
docker-compose -f ./docker-compose-mysql.yml upNow, we are downloading a different docker-compose yml file; one that has the mysql suffix on it. And we must use -f option with the docker-compose command to use this file. As before, leave this terminal window open and open a browser at http://localhost:10000.
When you are done running the demo, go back to this terminal and enter CTRL+C. You may also want to enter with the following commands to stop containers that may still be running and remove them:
docker-compose -f ./docker-compose-mysql.yml stop
docker-compose -f ./docker-compose-mysql.yml rmThis is important, specially if you are going back and forth between running the speed test on one database (say InterSystems IRIS) and some other.
In our tests, we found InterSystems IRIS to ingest data 25X faster than MySQL and Amazon Aurora.
There is a docker-compose-mariadb.yml file for MariaDB as well.
To run this demo against SQL Server:
wget https://raw.githubusercontent.com/intersystems-community/irisdemo-demo-htap/master/docker-compose-sqlserver.yml
docker-compose -f ./docker-compose-sqlserver.yml upAs before, leave this terminal window open and open a browser at http://localhost:10000.
In our tests running on a local PC, we found InterSystems IRIS to ingest data 2.5X faster than SQL Server while query rates were 400X faster! We will test it against AWS RDS SQL Server and report.
To run the speed test with SAP HANA on your PC you will need:
- A VM with Ubuntu 18 VM, docker and docker-compose - because SAP HANA requires some changes to the Linux Kernel parameters that we otherwise couldn't do using Docker for Mac or Docker for Windows. Also, SAP HANA requires a Linux Kernel version 4 or superior.
- Provision at least 9 GB of RAM to this VM otherwise it will not even start! It will crash with an unhelpful error message.
To run this demo against SAP HANA:
git clone https://github.com/intersystems-community/irisdemo-demo-htap
cd ./irisdemo-demo-htap
./run.sh hanaWait for the images to download and for the containers to start. You will know when everything is up once docker-compose stops writing to the screen. But be patient - SAP HANA takes about 6 minutes to start! So, your screen will freeze for a minute or so and then you will see SAP HANA writing more text. It will repeat this for about 6 minutes.. Once you see the text "Startup finished!" you should be good to go. If it crashes with an error, it is probably because you need to give it more memory.
As you can see, it is not just a matter of running docker-compose up as it is with InterSystems IRIS and MySQL. SAP HANA requires some configurations to the Linux Kernel. The run.sh will do these configurations for you.
In our tests running the Speed Test on a VM, we found InterSystems IRIS to be 1.3X faster than SAP HANA for ingesting data, and 20X faster for querying data, and uses a fraction of the memory.
A video about this demo is in the works! In the meantime, here is an interesting article that talks about InterSystems IRIS architecture and what makes it faster.
The open source sysbench tool can certainly be extended but as of now it can only be used to test MySQL, PostgreSQL and other databases that are based on MySQL (ex.: AWS Aurora) or implement MySQL wire protocol. We could certainly modify it to test other databases but we wanted to use JDBC (not the C based driver that sysbench is using) and we needed the tool to be less dependent of the backend database for metrics collection.
Our tests are also simpler in the sense that we only have one single table. sysbench allows you to run INSERTS and SELECTS in parallel, in multiple copies of the same table which is not fair for our use case. We want to test how efficient the database engine is with the same available IOPS on a single table. How does it deal with lock contention and memory caching. We could certainly using Sharding on InterSystems IRIS, which, in a sense, is liking allowing INSERTS and SELECTS to ocurr in parallel in multiple copies of the data. But then they would be running on different nodes, with more available IOPS, which would not be fair to sysbench. Finally, real applications don't generally keep multiples copies of the same table and when they do, most transactions and searches happen on the "master copy" while the other copies just hold historical data. So we think that sysbench is more oriented at testing the infrastructure setup, not the database itself.
The open-source Yahoo Cloud Serving Benchmark (YCSB) project aims to develop a framework and common set of workloads for evaluating the performance of different “key-value” and “cloud” serving stores.
Although there are workloads on YCSB that could be described as HTAP, YCSB doesn't necessarily rely on SQL to do it. This benchmark does.
TPC-H is focused on decision support systems (DSS) and that is not the use case we are exploring.
On financial services applications (for example), data is coming in fast into a single table and how the data base deals with lock contention, out of memory pressure (blue on the diagram), and in memory pressure (yellow on the diagram). Lock contention issues is also critical. Allowing the test to be run on multiple tables (like sysbench) mitigates the lock contention problem and masks it. We don't want that. So we are running on a single node and a single table so we can really measure the database efficiency and memory caching intelligence.
The next diagram shows what we mean by out of memory pressure and in memory pressure:
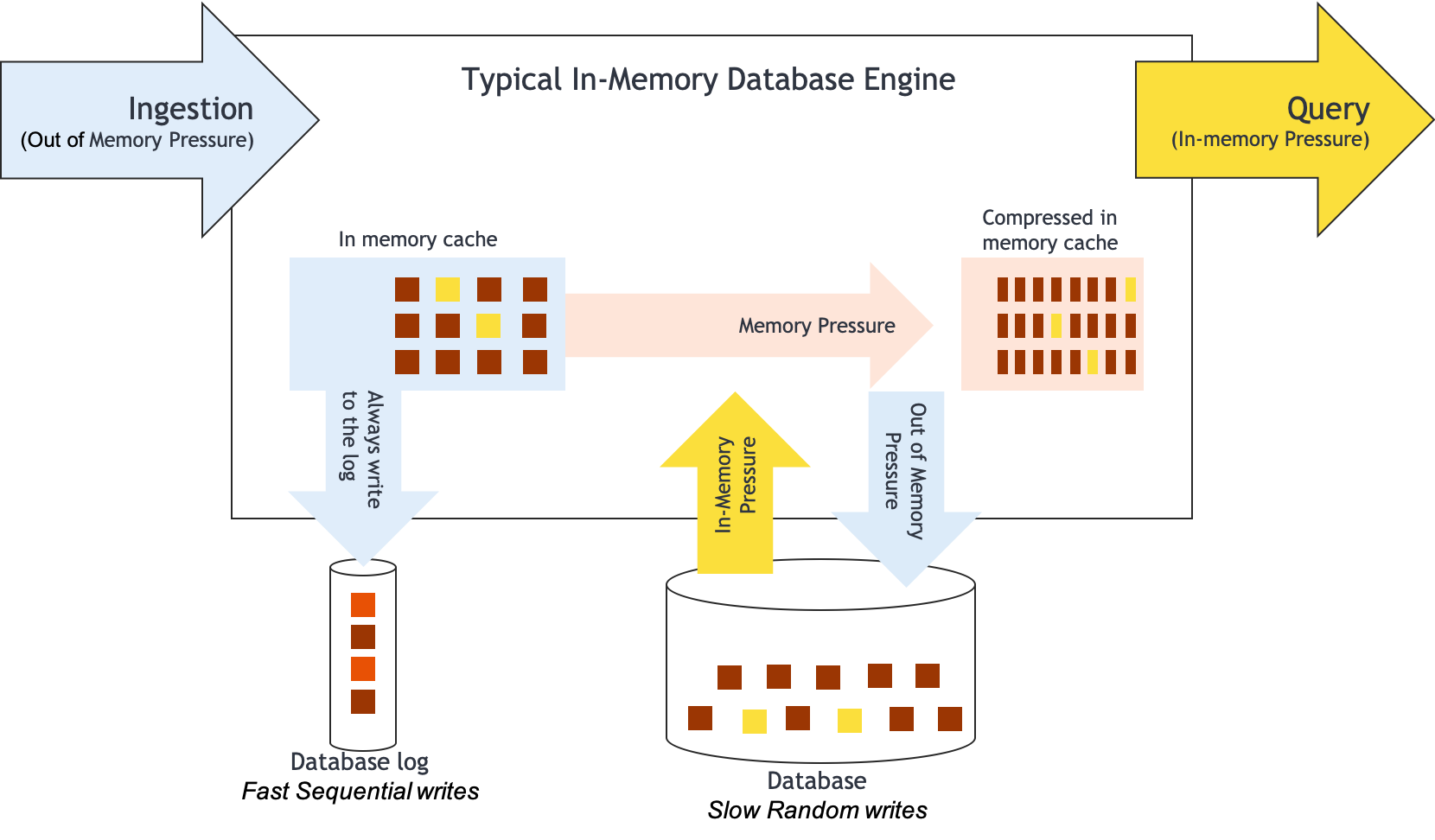
On the left, you can see data coming in fast, probably through several JDBC/ODBC connections. In order to provide Durability (see ACID), databases will immediately write the new transaction to a sequential log file (also known as journal) on disk. In a simplistic view, that is the only requirement for a succesful COMMIT and for the data to be considered "durable". Both traditional database and in-memory database do this (unless it is a pure in-memory database, which is out of the scope of this test).
Databases will also keep this data in memory as a memory cache, as long as possible so that queries for this data can be answered very fast, without having to read data from disk. What is kept in memory is the current state of the database. For instance, many updates may have happened to a database row. The database log has all these updates. The current state of the database is the cummulative result of all these updates. The current state is the final truth. Both types of database (traditional and in-memory) will do their best to keep the current state of the database entirely in memory so that queries can be done very fast.
Traditional databases will then do their best to write the current state in a structured database file. This is a slow process since the database has to update specific blocks on the database file to reflect the changes happening to the current state (random writes). Traditional databases will do this asynchronously as soon as possible. This has the advantage that, in case you need to restart your database, the current state of the database can be read directly from the database file (and completed with just a few records from the log file) instead of being reconstructed transaction by transaction entirely from the database log file.
In-Memory databases, on the other hand, will only write to the database file if they can't hold the full database state in memory anylonger. They will apply data compression in memory as well to make the best usage of available memory. Some in-memory databases will not even have a database file to write to, relying completely on the log file when it is time to restart the database. These In-memory databases will crash if they run out of memory. But most enterprise In-Memory databases such as SAP HANA will write to the database file just like InterSystems IRIS does, but only when they are running out of memory and data compression doesn't help anymore.
So, as you can realize, if we are constantly inserting records (Data ingestion) to the database, there is a out of memory pressure building up, in order to open up more space in memory for the new records which will force these databases to write to disk. On the other hand, we are running parallel queries as well for a specifc set of records which will force the database to try their best to keep those constantly requested records in memory. That is what we call in-memory pressure.
We want to measure how fast a database can ingest the records while, at the same time, allowing for responsive queries:
- The table has just one table with 19 columns and 3 very different data types
- The table has a Primary Key declared on it.
- The queries we do, fetch records by the Primary Key (account id), with fixed 8 keys we query for randomly: W1A1, W1A10, W1A100, W1A1000, W1A10000, W1A100000, W1A1000000 and W1A10000000. Here is why we do this:
- We know it is impossible to hold all data in memory in production systems. Even In memory databases have complex architectures that will move data out of memory when they are running out of it. To make the test simple and comparable, we are fetching this fixed set of records by primary key in order to avoid comparing different types of indices that databases may have.
- Fetching customer account data records by account number (PK) is a real workload that is happening in many of our customers. While data is being ingested at high speeds, the database needs to be responsive for queries.
- As the account id is a primary key, it will be indexed by the database using its preferred (and supposedly optimal) index for it. That will allow us to be fair when comparing the databases, while keeping this simple.
- The database will be given the opportunity to cache this data in memory as we are asking for the same account numbers over and over. We thought that would be an easy task for In Memory databases.
InterSystems IRIS is a hybrid database. As with traditional databases, it will also try to keep data in memory. But as thousands of records por second are coming in fast due to the ingestion work, the memory is purged very fast. This test allows you to see how InterSystems IRIS is smart about its cache when compared to other traditional databases and In Memory databases. You will see that:
- Traditional databases will perform poorly at ingestion and query
- In Memory databases will:
- Perform well at ingestion during the first minutes of the test as memory fills up, compression becomes harder and writing to disk becomes unavoidable
- Perform poorly at querying since the system will be too busy with ingestion, compressing data, moving data out of memory, etc.
Here is the the statement we send to all databases we support:
CREATE TABLE SpeedTest.Account
(
account_id VARCHAR(36) PRIMARY KEY,
brokerageaccountnum VARCHAR(16),
org VARCHAR(50),
status VARCHAR(10),
tradingflag VARCHAR(10),
entityaccountnum VARCHAR(16),
clientaccountnum VARCHAR(16),
active_date DATETIME,
topaccountnum VARCHAR(10),
repteamno VARCHAR(8),
repteamname VARCHAR(50),
office_name VARCHAR(50),
region VARCHAR(50),
basecurr VARCHAR(50),
createdby VARCHAR(50),
createdts DATETIME,
group_id VARCHAR(50),
load_version_no BIGINT
)The Ingestion Worker will send as many INSERTs as possible as measure the number of records/sec inserted as well as the number of Megabytes/sec.
The Query Worker will SELECT from this table by account_id and try to select as many records as possible measuring it as records/sec selected as well as Megabytes/sec select to test the end-to-end performance and to provide proof of work.
End-to-end performance has to do with the fact that some JDBC drivers have optmizations. If you just execute the query, the JDBC driver may not fetch the record from the server until you actually request for a value of a column.
To proove that we are actually reading the columns we are SELECTing, we sum up the bytes of all the filds reeturned as proof of work.
To achieve maximum throughput, each ingestion worker will start multiple threads that each will:
- Prepare a set of 1000 random values for each column of the table above. This is done because each column can have a different data type and a different size. So we want to genererate records that can vary accordingly
- For each new record to be inserted, the ingestion worker will randomly select one value out of the 1000 values for each column and once a record is ready, it will be added to the batch
- Use batch inserting with a default batch size of 1000 records per batch
The default number of ingestion worker threads is 15. But it can be changed during the test by clicking at the Settings button.
The query workers, on the other hand, also start multiple threads to query as many records as possible. But as we explained above, we are also providing proof of work. We are reading the columns returned and summing up the number of bytes read to make sure the data is actually traveling from the database, through the wire and into the query worker. That is to avoid optimizations implemented by some JDBC drivers that will only bring the data over the wire if it is actually used. We are actually consuming the data returned and providing a sum of MB read/s and total number of MB read as proof of it.
I filled up a 70Gb DATA file system after ingesting 171,421,000 records. That would mean that each records would take an avergage of 439 bytes (rounding up).
I also filled 100% of my first journal directory and about 59% of the second. Both filesystems had 100Gb which means that 171,421,000 would take about 159Gb of journal space or that each records would take an average of 996 bytes.
The architecture of the HTAP demo is shown below:
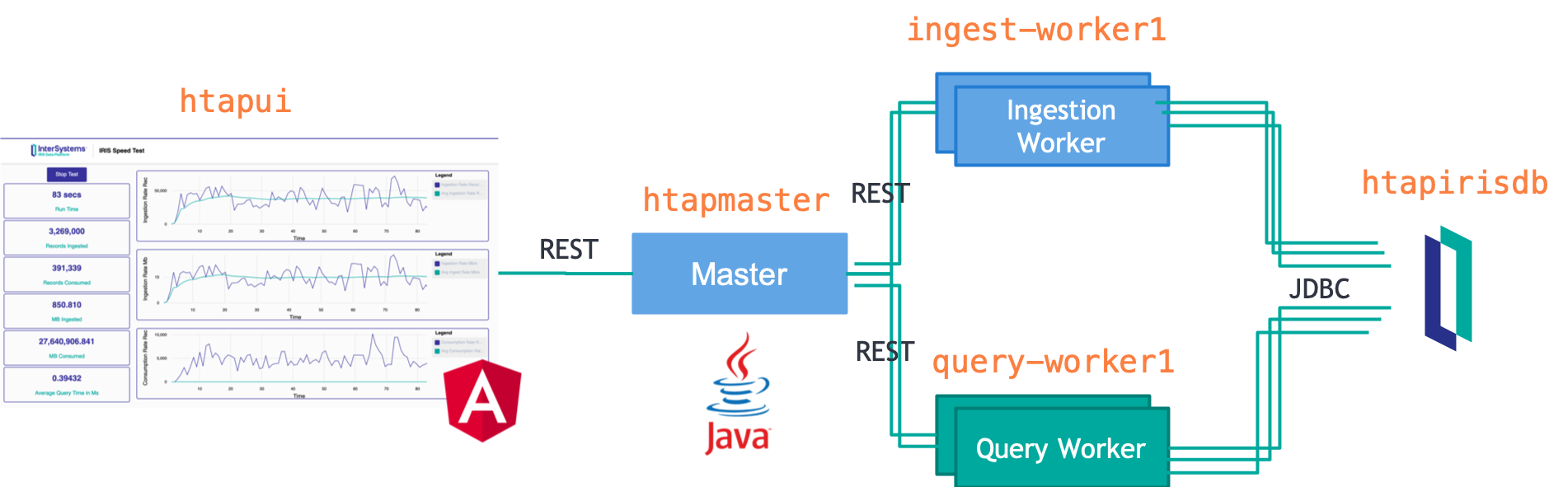
This demo uses docker compose to start five services:
- htapui - this is the Angular UI you use to run the demo.
- htapirisdb - since the demo is running on InterSystems IRIS Community, you don't need an InterSystems IRIS license to run it. But be aware that InterSystems IRIS Community has two important limitations:
- Max of 5 connections
- Max Database size of 10Gb
- htapmaster - This is the HTAP Demo master. The UI talks to it and it talks to the workers to start/stop the speed test and collect metrics.
- ingest-worker1 - This is an ingestion worker. You can actually have more than one ingestion worker; just give each one a different service name. They will try to INSERT records into the database as fast as possible.
- query-worker1 - This is the consumption worker. You can have more than one of these as well. They will try to read records out of the database as fast as possible.
When running the demo on our PCs, we use Docker and Docker Compose. Docker Compose expects a docker-compose.yml that describes these services and the docker images they use. This demo actually provides many docker-compose.yml files and more will be added soon:
- docker-compose.yml - This is the default demo that runs the speed test against InterSystems IRIS Community described on the bullets and picture above.
- docker-compose-mysql.yml - This is the speed test against MySQL. You will notice that the same test shows that InterSystems IRIS is 25x faster than MySQL. Running this test against Amazon Aurora MySQL (that is a fine tuned version of MySQL) produced the same results.
- docker-compose-sqlserver.yml - This is the speed test against SqlServer for Dockers.
- docker-compose-enterprise-iris.yml - If you want to run the speed test demo on InterSystems IRIS standard, there is an example of a docker-compose.yml file for it.
Yes! The easiest way to get this done is to clone this repo on each server where you are planning on running the master and the UI (they run on the same server) and on each worker type (ingestion and query workers). You may have as many ingestion workers and query workers as you want!
Then, for InterSystems IRIS, look at the files on folder ./standalone_scripts/iris-jdbc. There is a script for every server:
- On the Master: start_master_and_ui.sh - This script will start both the master and the UI.
- On the Ingestion Workers: start_ingestion_worker.sh - This script will start the ingestion worker which in turn will connect and register with the master.
- On the Query Workers: start_query_worker.sh - This script will start the query worker which in turn will connect and register with the master.
What about InterSystems IRIS? You have two choices:
- You can use the start_iris.sh script to start an InterSystems IRIS server on a docker container for a quick test.
- You can provision your InterSystems IRIS cluster by hand or using ICM. Then you could do fancy things such as:
- Have both the ingestion and query workers pointing to the same InterSystems IRIS box
- Configure InterSystems IRIS with ECP and have the ingestion workers pointing to the database server while having the query workers pointing to the ECP servers
- Configure a sharded InterSystems IRIS cluster
- etc.
Just make sure you change your start_master.sh script to configure the environment variables with the correct InterSystems IRIS end points, usernames and passwords.
Look at the docker-compose.yml file and you will notice environment variables that will allow you to configure everything. The provided docker-compose yml files are just good starting points. You can copy them and change your copies to have more workers (it won't make a lot of difference if you are running on your PC), higher number of threads per worker type, change the ingestion batch size, wait time in milliseconds between queries on the consumter, etc.
Yes, but you will have to:
- Fork this repo on your PC
- Change the source code
- Rebuild the demo on your PC using the shellscript build.sh.
Changing the table structure should be simple.
After forking, you need to change the files on folder /image-master/projects/master/src/main/resources.
If you change the TABLE structure, make sure you use the same data types I am using on the existing table. Those are the data types supported. You can also change the name of the table.
Then, change the other *.sql scripts to match your changes. The INSERT script, the SELECT script, etc.
Finally, just run the build.sh to rebuild the demo and you should be ready to go!
After running a test, the UI will allow you to download the test results as a CSV file. Here is what the columns on the Results CSV file mean:
- Ingestion:
- timeInSeconds - A point in time during the test given in seconds.
- numberOfActiveIngestionThreads - The total number of active ingestion threads sending data to the database.
- numberOfRowsIngested - Total number of records inserted at a given point in time
- recordsIngestedPerSec - Instantaneous ingestion rate expressed in number of records inserted per second (rec/s) at a given point in time.
- avgRecordsIngestedPerSec - Average number of records inserted per second up to a given point in time considering all records inserted up to that point in time.
- MBIngested - Total amount of MB (mega bytes) inserted into the database at a given point in time
- MBIngestedPerSec - Instantaneous ingestion rate expressed in amount of MB per second (MB/s) inserted at a given point in time.
- avgMBIngestedPerSec - Average number of records inserted per second at a given point in time considering all records inserted up to that point in time.
- Querying:
- numberOfRowsConsumed - Total number of records fetched from the database at a given point in time
- numberOfActiveQueryThreads - The total number of active query threads fetching data from the database.
- recordsConsumedPerSec Instantaneous query rate expressed in number of records fetched per second (rec/s) at a given point in time.
- avgRecordsConsumedPerSec - Average number of records fetched per second at a given point in time considering all records fetched up to that point in time.
- MBConsumed - Total amount of MB (mega bytes) fetched from the database at a given point in time (as proof of work done by the querying workers)
- MBConsumedPerSec - Instantaneous querying rate expressed in amount of MB per second (MB/s) fetched at a given point in time.
- avgMBConsumedPerSec - Average number of records fetched per second at a given point in time considering all records fetched up to that point in time.
- queryAndConsumptionTimeInMs - Instantaneous time taken to fetch a single record from the database and process it (sum the number of bytes fetched) measured in milliseconds.
- avgQueryAndConsumptionTimeInMs - Average time taken to fetch a single record form the database and process it considering the total number of records fetched and how long the test has been running in milliseconds.
There are other InterSystems IRIS demo applications that touch different subjects such as NLP, ML, Integration with AWS services, Twitter services, performance benchmarks etc. Here are some of them:
- HTAP Demo - Hybrid Transaction-Analytical Processing benchmark. See how fast InterSystems IRIS can insert and query at the same time. You will notice it is up to 20x faster than AWS Aurora!
- Fraud Prevention - Apply Machine Learning and Business Rules to prevent frauds in financial services transactions using InterSystems IRIS.
- Twitter Sentiment Analysis - Shows how InterSystems IRIS can be used to consume Tweets in realtime and use its NLP (natural language processing) and business rules capabilities to evaluate the tweet's sentiment and the metadata to make decisions on when to contact someone to offer support.
- HL7 Appointments and SMS (text messages) application - Shows how InterSystems IRIS for Health can be used to parse HL7 appointment messages to send SMS (text messages) appointment reminders to patients. It also shows real time dashboards based on appointments data stored in a normalized data lake.
- The Readmission Demo - Patient Readmissions are said to be the "Hello World of Machine Learning" in Healthcare. On this demo, we use this problem to show how InterSystems IRIS can be used to safely build and operationalize ML models for real time predictions and how this can be integrated into a random application. This InterSystems IRIS for Health demo seeks to show how a full solution for this problem can be built.
Here is the list of the supported databases so far:
- Runing on your PC with docker-compose (NO mirroring/replication)
- InterSystems IRIS 2020.2
- MySQL 8.0
- MariaDB 10.5.4-focal
- MS SQL Server 2019-GA-ubuntu-16.04
- SAP HANA Express 2.0 (on Linux VM only)
- Postgres 12.3
- Running on AWS:
- InterSystems IRIS (with or without mirroring)
- AWS RDS Aurora (MySql) 5.6.10a (parallel query) with replication
- AWS RDS SQL Server 2017 Enterprise Edition (production deployment) with replication
- AWS RDS Postgres (production deployment) with replication
- AWS RDS MariaDB (production deployment) with replication
- SAP HANA Express Edition 2.0 without replication
- SAP Sybase ASE 16.0 SP03 PL08, public cloud edition, premium version, without replication
- AWS RDS Oracle (production deployment) with replication
Please, report any issues on the Issues section.
All the changes to this project are logged here.