A full-stack salary prediction pipeline that integrates Python, SQLite, Julia, Go, SQL, and Bash. Built to demonstrate working knowledge of ML pipelines, API development, and multi-language system design — and to learn Julia and Go, two languages I picked up the same day I built this. The model uses a fixed random seed for more consistent predictions, but variations may still occur.
- 🐍 Python – Ingests and populates salary data into an SQLite database.
- 🗃️ SQLite – Lightweight relational DB used for structured storage.
- 🧠 Julia (MLJ) – Trains a regression model to predict salary using
job_title,experience_level, andlocation. - 💻 Go – Serves a lightweight HTTP API with HTML form and JSON endpoint.
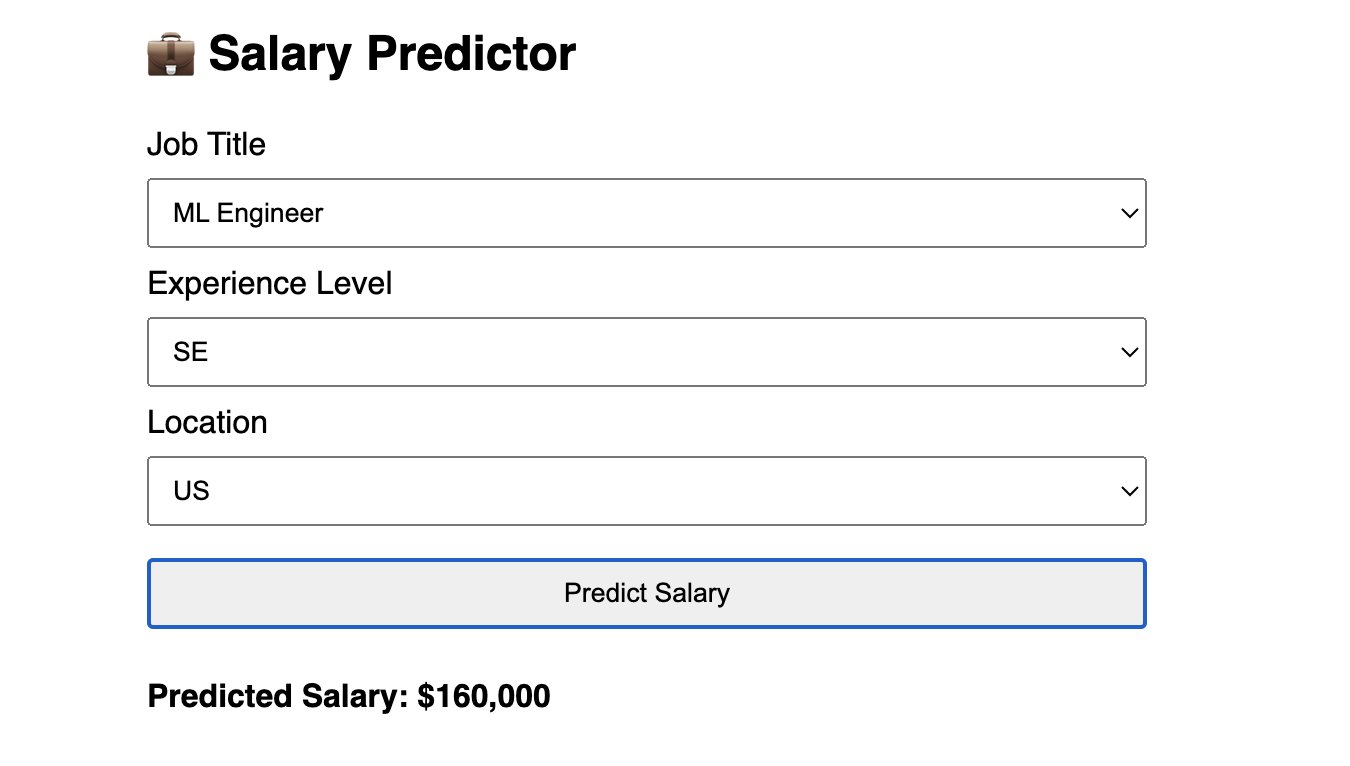
- 🌐 HTML – Clean UI served from a static folder via Go.
- 🖥️ Bash – End-to-end pipeline runner (
run_pipeline.sh). - 🎯 RMSE on test set: $43,664
The model is a DecisionTreeRegressor from the MLJ.jl ecosystem. It was chosen for its simplicity, interpretability, and ability to handle categorical features without manual one-hot encoding.
Preprocessing:
- Converted
job_title,experience_level, andlocationcolumns to categorical types in Julia. - No feature scaling was required due to the nature of the tree-based model.
Hyperparameters:
- Used default parameters (
max_depth = -1, etc.) to keep the model configuration lightweight. - Random seed set for reproducibility, though slight variation in predictions may still occur.
To benchmark model performance, a simple DecisionTreeRegressor was trained in Python using scikit-learn on the same dataset and features (job_title, experience_level, company_location).
Python (scikit-learn) baseline results:
- RMSE: $49,820
- MAE: $37,564
- R²: 0.37
The Julia model (MLJ.jl) achieved an RMSE of $43,664, indicating slightly better performance while maintaining cross-language consistency.
This baseline comparison validates the effectiveness of the Julia model and provides a familiar point of reference for Python developers.
salary-predictor/
│
├── data/ # Raw CSV from Kaggle
├── Julia/ # Model training in Julia
├── go-api/ # Go web server and HTML UI
│ └── static/index.html
├── Screenshots/ # UI screenshots
├── init.sql # DB schema
├── run_pipeline.sh # End-to-end bash runner
├── salary.db # SQLite database
└── utl.py # Python ETL scriptTable: predictions
| Column | Type | Description |
|---|---|---|
| job_title | TEXT | Role title |
| experience_level | TEXT | Entry / Mid / Senior |
| location | TEXT | Country or region code |
| predicted_salary | INTEGER | Model-predicted salary |
git clone https://github.com/daniel-mehta/Salary-Predictor.git
cd salary-predictor
chmod +x run_pipeline.sh
./run_pipeline.shGo to http://localhost:8080 Fill the dropdowns and click Predict Salary.
Kaggle – Data Science Salaries
| Language | Purpose |
|---|---|
| Python | Data ingestion & DB fill |
| SQL | DB schema/querying |
| Julia | ML model training |
| Go | API + web frontend |
| Bash | Full pipeline automation |
| HTML/CSS | User interface (form) |
MIT — free to use, modify, or extend.