Clustering, sometimes called unsupervised learning, is one of the most fundamental step in understanding a dataset, aiming to discover the unknown nature of data through the separation of a finite dataset, with little or no ground truth, into a finite and discrete set of “natural,” hidden data structures. Given a set of n points in a multidimensional space, the purpose of clustering is to group them into several sets based on similarity measures and distance vectors.
Most clustering algorithms have a quadratic complexity with n, making then inadequate to analyze large amounts of data. In addition, many clustering algorithms are methods are inherently difficult to parallelize.
PatchWork is a novel clustering algorithm to address those issues. It is a mixture of density and grid-based clustering algorithm. It has linear complexity and near linear horizontal scalability. As a result, PatchWork can cluster a billion points in a few minutes only, a 40x improvement over Spark MLLib native implementation of the well-known K-Means.
We evaluated and compared PatchWork against the Spark MLLib implementation of the k-means|| algorithm, as well as Spark_DBSCAN.
We evaluated PatchWork using four synthetic datasets commonly used to evaluate clustering algorithms. Those datasets simulate different distributions of the data: Jain, Spiral, Aggregation and Compound datasets. The size of those datasets is very limited and not suitable for big-data applications. Hence, for each of those four datasets, we generated datasets of increasing size, up to 1.2 billion entries. Those datasets have the same data distribution as the original datasets while allowing us to test the scalability of the algorithms.
The parameters of each algorithms were empirically tuned for each dataset. The results of these experiments are shown below:

We benchmarked the performance of PatchWork and other algorithms using a cluster of six commodity servers, each with an Intel Xeon CPU E5-2650 processor with 8 cores at 2.60GHz, 192GB of RAM and 30TB of storage. The servers are interconnected using 10 Gigabit Ethernet. Experiments were conducted using HDFS 2.6.0 and Apache Spark 1.3.0 packaged in the Cloudera CDH 5.4.0 distribution.
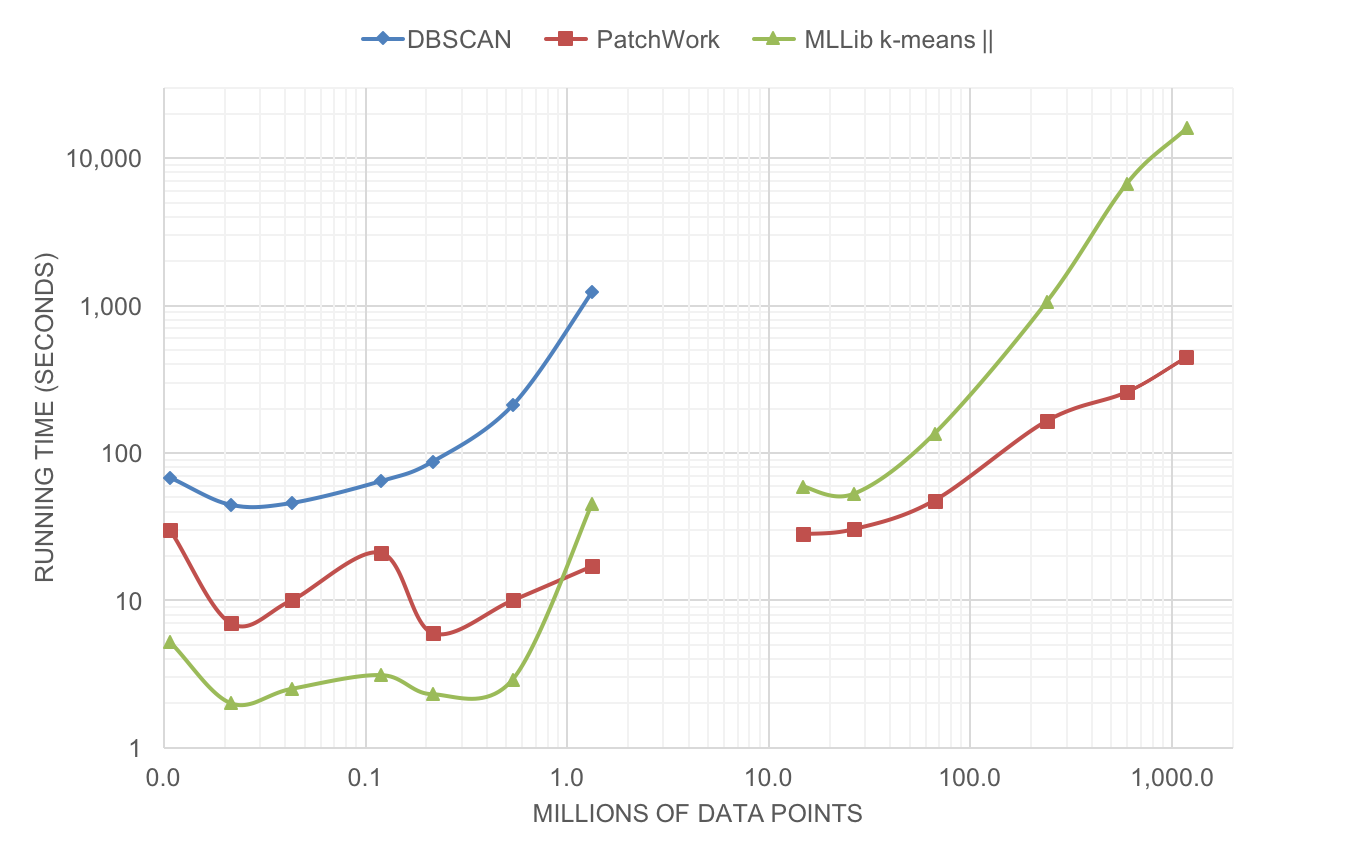
The figure below shows the running-time of the three algorithms to cluster up to 1 billion data points. Both X and Y-axis are logarithmic and represents the running-time in seconds. The quadratic complexity of DBSCAN significantly impact the running-time of the algorithm. For large datasets with over 10 millions entries, Spark-DBSCAN was unable to terminate in a timely fashion, hence is not shown. In fact, in half the time, PatchWork could cluster 1 billion points while Spark-DBSCAN could only cluster 1.2 million points, a 1000-fold improvement.
Both PatchWork and k-means have a linear computation complexity. However, for very large datasets, PatchWork is very significantly faster than the native Spark implementation of k-means: when clustering 1 billion points, PatchWork is 40 times faster.
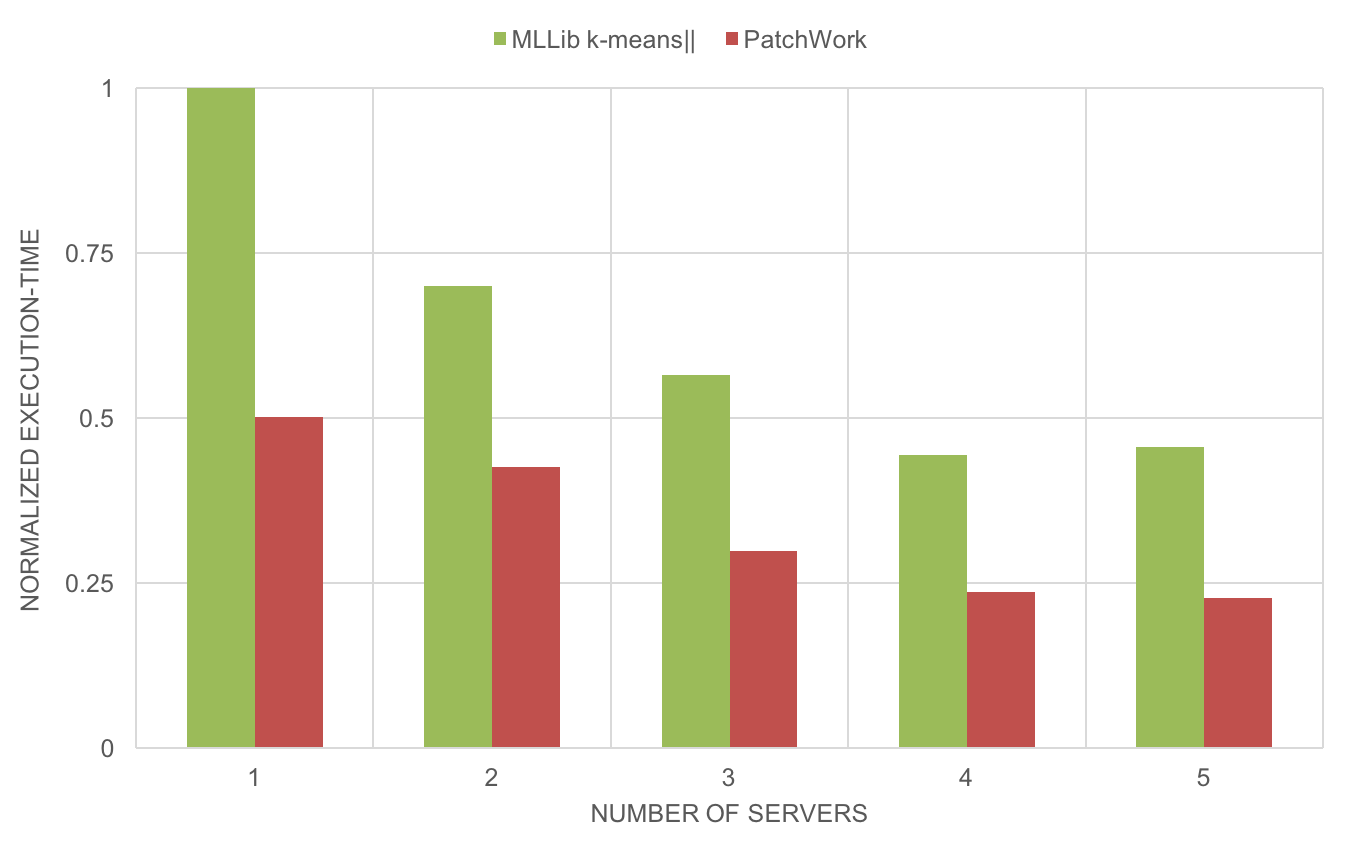
Both MLLib k-means and PatchWork have a near-linear horizontal scalability, a critical property of distributed algorithms for big-data applications:
More details are available in the following technical paper:
Frank Gouineau, Tom Landry and Thomas Triplet (2016) PatchWork, a Scalable Density-Grid Clustering Algorithm. In Proc. 31th ACM Symposium On Applied Computing, Data-Mining track, Pisa, Italia (accepted)
At the root of the project:
./runPatchwork.sh
The demo reads data from a sample file, runs PatchWork to define the clusters, displays the clusters for each data point, then a summary of the clusters. The demo runs in a few seconds. If everything runs smoothly, you will see something like:
-----------------------------------------
number of points : 7826
number of clusters : 5
-----------------------------------------
cluster 1 has 1370 cells
cluster 6 has 689 cells
cluster 14 has 193 cells
cluster 19 has 117 cells
cluster 25 has 299 cells
-----------------------------------------
size of epsilon : [0.2,0.2]
min pts in each cell : 1
time of training : 13450 ms
-----------------------------------------
Tests were executed using a Cloudera CDH 5.4.0 featuring Spark 1.3.0.
By default, you need a running local Spark server. If you want to run the algorithm on a cluster (e.g. on a YARN cluster), you can edit the SparkContext and the runPatchwork.sh script and recompile the project. sbt is required to compile the project.
To compile (at the root of the project): ./build.sh
For all questions, contact me at [email protected].