This repository contains Ansible roles and playbooks for OpenShift for automating the interactions with the OpenShift operators under the responsibility Red Hat PSAP team.
- Performance & Latency Sensitive Application Platform
To date, this includes:
- NVIDIA GPU Operator (most of the repository relates to the deployment, testing and interactions with this operator)
- the Special Resource Operator (deployment and testing currently under development)
- the Node Feature Discovery
- the Node Tuning Operator
See the documentation pages.
Requirements:
ansible(>= 2.9.5),yq,jq
pip3 install yq ansible==2.9.*
dnf install jq- OpenShift Client (
oc)
wget --quiet https://mirror.openshift.com/pub/openshift-v4/x86_64/clients/ocp/latest/openshift-client-linux.tar.gz
tar xf openshift-client-linux.tar.gz oc- An OpenShift cluster accessible with
$KUBECONFIGproperly set
oc version # fails if the cluster is not reachableThe original purpose of this repository was to perform nightly testing of the OpenShift Operators under responsibility.
This CI testing is performed by OpenShift PROW instance. Is is controlled by the configuration files located in these directories:
- https://github.com/openshift/release/tree/master/ci-operator/config/openshift-psap/ci-artifacts
- https://github.com/openshift/release/tree/master/ci-operator/jobs/openshift-psap/ci-artifacts
The main configuration is written in the config directory, and
jobs are then generated with make ci-operator-config
jobs. Secondary configuration options can then be modified in the
jobs directory.
The Prow CI jobs run in an OpenShift Pod. The ContainerFile is used to build their base-image, and the
run (build/root/usr/local/bin/run) file is used as entrypoint.
From this entrypoint, we trigger the different high-level tasks of the operator end-to-end testing, eg:
run gpu-operator test-master-branchrun gpu-operator test-operatorhubrun gpu-operator validate-deploymentrun gpu-operator undeploy-operatorhubrun cluster upgrade
These different high-level tasks rely on the toolbox scripts to automate the deployment of the required dependencies (eg, the NFD operator), the deployment of the operator from its published manifest or from its development repository and its non-regression testing.
The artifacts generated during the nightly CI testing are reused to plot a "testing dashboard" that gives an overview of the last days of testing. The generation of this page is performed by the ci-dashboard repository.
Currently, only the GPU Operator results are exposed in this dashboard:
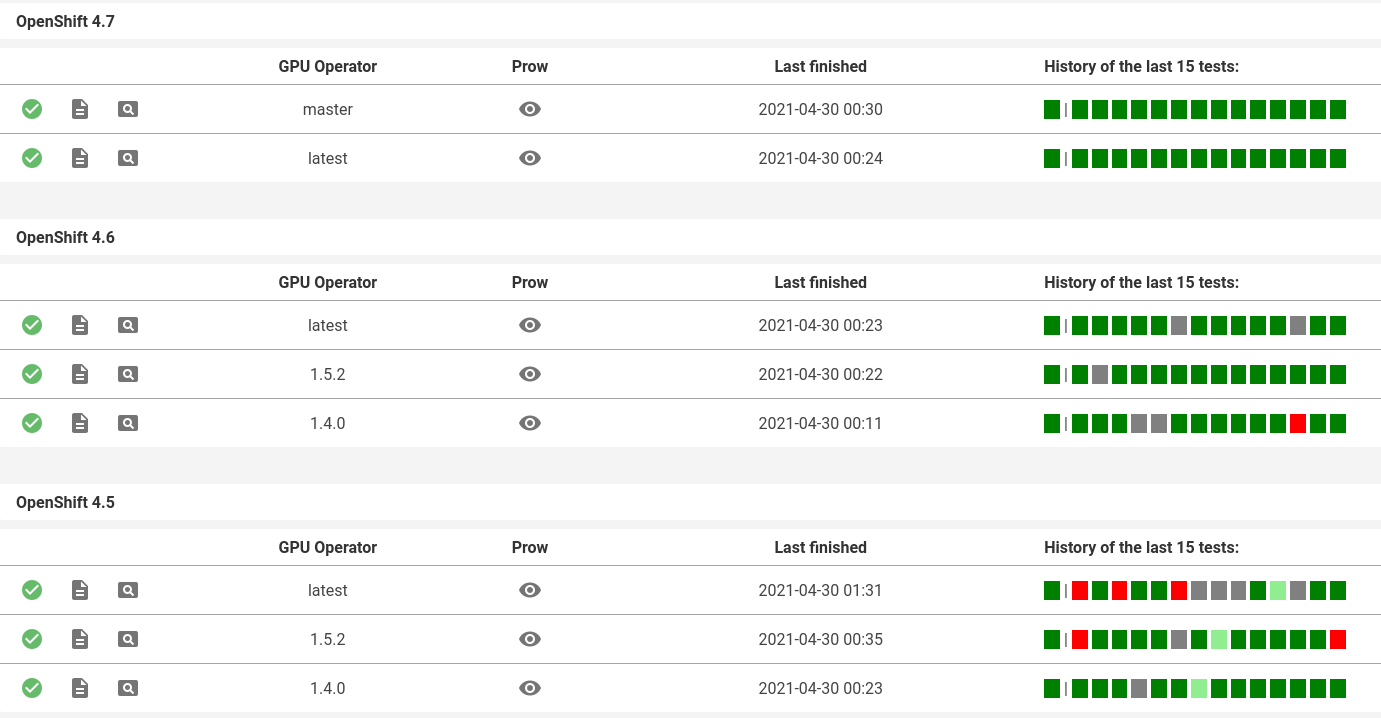
The PSAP Operators Toolbox is a set of tools, originally written for CI automation, but that appeared to be useful for a broader scope. It automates different operations on OpenShift clusters and operators revolving around PSAP activities: entitlement, scale-up of GPU nodes, deployment of the NFD, SRO and NVIDIA GPU Operators, but also their configuration and troubleshooting.
The functionalities of the toolbox commands are described in the documentation page.
$ tree toolbox | grep -v _common
toolbox
├── cluster
│ ├── capture_environment.sh
│ ├── set_scale.sh
│ └── upgrade_to_image.sh
├── entitlement
│ ├── deploy.sh
│ ├── inspect.sh
│ ├── test_cluster.sh
│ ├── test_in_cluster.sh
│ ├── test_in_podman.sh
│ ├── undeploy.sh
│ └── wait.sh
├── gpu-operator
│ ├── capture_deployment_state.sh
│ ├── cleanup_resources.sh
│ ├── deploy_from_commit.sh
│ ├── deploy_from_helm.sh
│ ├── deploy_from_operatorhub.sh
│ ├── diagnose.sh
│ ├── list_version_from_helm.sh
│ ├── list_version_from_operator_hub.sh
│ ├── must-gather.sh
│ ├── run_gpu_burn.sh
│ ├── set_repo-config.sh
│ ├── undeploy_from_commit.sh
│ ├── undeploy_from_helm.sh
│ ├── undeploy_from_operatorhub.sh
│ └── wait_deployment.sh
├── local-ci
│ ├── cleanup.sh
│ └── deploy.sh
├── nfd
│ ├── has_gpu_nodes.sh
│ ├── has_nfd_labels.sh
│ └── wait_nfd_labels.sh
├── nfd-operator
│ ├── deploy_from_operatorhub.sh
│ ├── deploy_from_commit.sh
│ ├── undeploy_from_operatorhub.sh
│ └── wait_gpu_nodes.sh
├── nto
│ └── run_e2e_test.sh
├── repo
│ ├── validate_role_files.py
│ └── validate_role_vars_used.py
└── special-resource-operator
├── capture_deployment_state.sh
├── deploy_from_commit.sh
├── run_e2e_test.sh
└── undeploy_from_commit.sh