Server Configuration
External dependencies
Server properties
Security configuration
Systems Configuration - System Catalogue and Systems Config
Core Systems
Non-core Systems
There are two main system properties that titanoboa server checks during its startup:
| Property | Description |
|---|---|
| boa.server.dependencies.path | clj file containing a map with external dependencies that need to be loaded - it may contain maven repositories, coordinates and items that need to be required or imported; the dependencies are loaded before the server configuration is which allows for great extensibility, e.g. if proper dependencies are added to external dependencies file then in the server configuration a user may define additional systems for 3rd party RDBS or MQ connection pooling etc... If this system property is not defined, titanoboa uses a default configuration ext-dependencies.clj stored in the root of titanoboa's jar. It will be extracted from the jar upon startup and thus may not retain any changes if titanoboa is repeatedly restarted. |
| boa.server.config.path | server configuration clj file - this clj file will be evaluated in titanoboa.server namespace and allows for very flexible server configuration since additional code may be executed. Primarily this clj file may alter var titanoboa.server/server-config. If this system property is not defined, titanoboa uses a default configuration boa-server-config.clj stored in the root of titanoboa's jar. |
e.g.:
java -Dboa.server.dependencies.path=/home/miro/titanoboa/ext-dependencies.clj -cp "./build/titanoboa.jar:./lib/*" titanoboa.server
Note: Alternatively also environmental properties BOA_CONFIG_PATH and BOA_DEPS_PATH can be used. This is beneficial when running tboa in a container.
External dependencies are specified in a clj file containing a map with maven repositories, maven coordinates and items that need to be required or imported. These dependencies can be added during titanoboa's runtime (!) and can be freely used in server configuration as well as in any workflows.
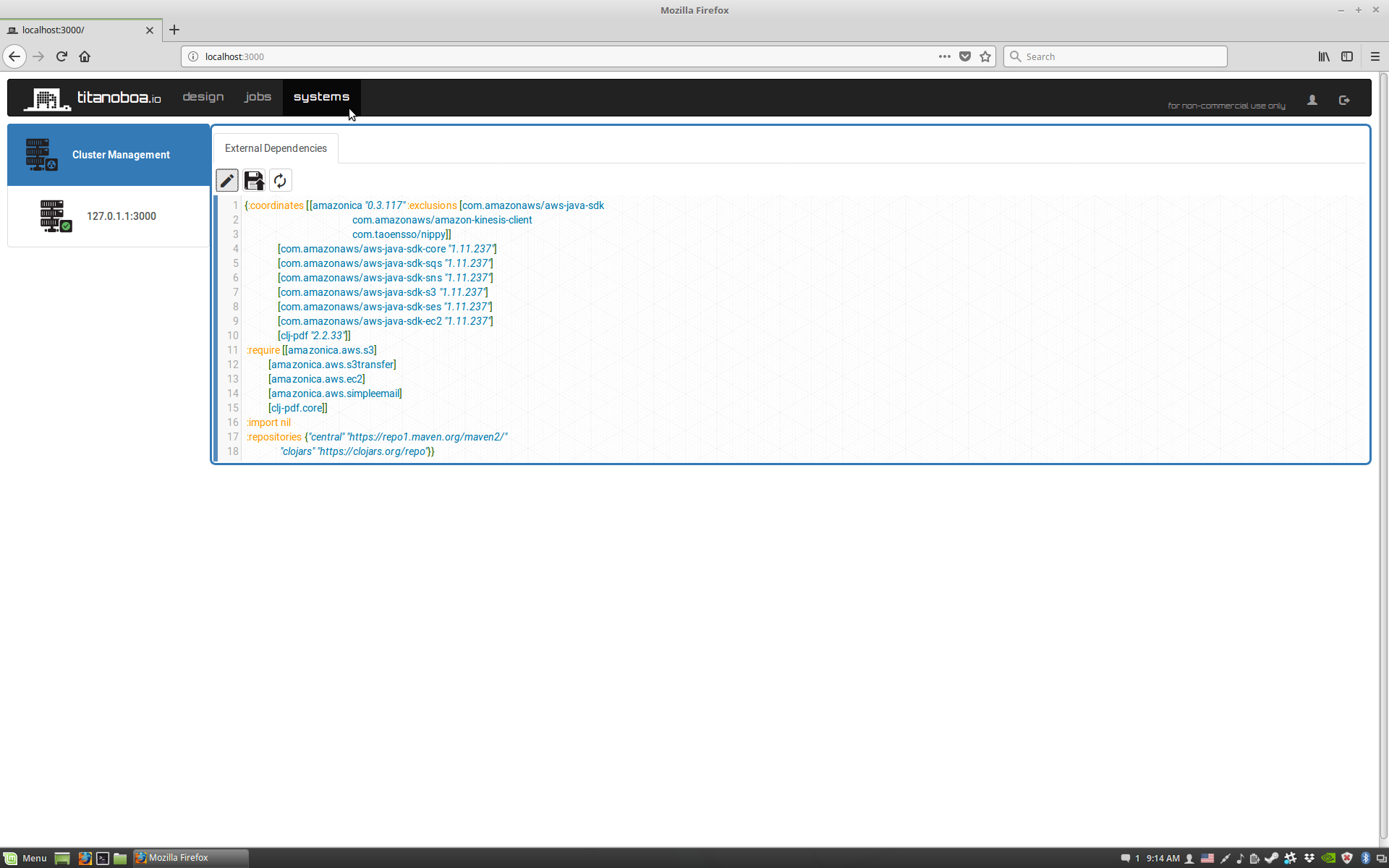
External dependencies file sample:
{:coordinates [[amazonica "0.3.117" :exclusions [com.amazonaws/aws-java-sdk
com.amazonaws/amazon-kinesis-client
com.taoensso/nippy]]
[com.amazonaws/aws-java-sdk-core "1.11.237"]
[com.amazonaws/aws-java-sdk-sqs "1.11.237"]
[com.amazonaws/aws-java-sdk-sns "1.11.237"]
[com.amazonaws/aws-java-sdk-s3 "1.11.237"]
[com.amazonaws/aws-java-sdk-ses "1.11.237"]
[com.amazonaws/aws-java-sdk-ec2 "1.11.237"]
[clj-pdf "2.2.33"]]
:require [[amazonica.aws.s3]
[amazonica.aws.s3transfer]
[amazonica.aws.ec2]
[amazonica.aws.simpleemail]
[clj-pdf.core]]
:import nil
:repositories {"central" "https://repo1.maven.org/maven2/"
"clojars" "https://clojars.org/repo"}}This file is also visible via titanoboa's GUI (under systems tab) and can be edited during runtime. Its changes will trigger automatic reload (in clustered environment all nodes will perform the reload).
It is possible also to reference maven repositories stored in an S3 bucket. Whenever s3-wagon-private dependency is found in ext-dependencies it is automatically initiated and registered in aether prior to other dependencies' retrieval. This way private s3 can be supported without including s3-wagon-private in project.clj by default (and potentially unnecessarily bloating titanoboa since most ppl dont need s3 private mvn repos).
So to enable this feature simply add [s3-wagon-private "1.3.2" :exclusions [ch.qos.logback/logback-classic]] into ext-dependencies.
You then should be able to add S3 repos into your ext-dependencies.clj file in a format as follows:
:repositories {"central" "https://repo1.maven.org/maven2/"
"clojars" "https://clojars.org/repo"
"privateS3" {:url "s3p://bucket/releases/"
:username "xxxxxxxx"
:passphrase "xxxxxxxx"
:private-key-file "/key/file/path"}}}See also #12
Server properties sample:
(in-ns 'titanoboa.server)
(log/info "Hello, I am core.async server-config and I am being loaded...")
(defonce archival-queue-local (clojure.core.async/chan (clojure.core.async/dropping-buffer 1024)))
(alter-var-root #'server-config
(constantly {:systems-catalogue
{:core {:system-def #'titanoboa.system.local/local-core-system
:worker-def #'titanoboa.system.local/local-worker-system
:autostart true}}
:job-folder-path "job-folders/"
:enable-cluster false
:jetty {:join? false
:port 3000}
:auth? false
:systems-config {:core
{:new-jobs-chan (clojure.core.async/chan (clojure.core.async/dropping-buffer 1024))
:jobs-chan (clojure.core.async/chan (clojure.core.async/dropping-buffer 1024))
:finished-jobs-chan archival-queue-local
:eviction-interval (* 1000 60 5)
:eviction-age (* 1000 60 60)}}}))This is probably the most minimalist server configuration. It contains Systems catalogue with just one core system. This core system just uses local (in-memory) core.async [job channel] (https://github.com/mikub/titanoboa/wiki#job-channel). There is no other non-core system defined - none to archive jobs (these end up in another core.async channel) or to secure the server etc.
Following sample is more extensive as it contains an archival system (that archives processed jobs into a postgres DB) and a security system (that verifies user credentials against a database). It also contains yet another system "test-db" that presumably contains another DB connection pool that is probably used from some workflow:
(in-ns 'titanoboa.server)
(log/info "Hello, I am core.async server-config and I am being loaded...")
(defonce archival-queue-local (clojure.core.async/chan (clojure.core.async/dropping-buffer 1024)))
(alter-var-root #'server-config
(constantly {:systems-catalogue
{:core {:system-def #'titanoboa.system.local/local-core-system
:worker-def #'titanoboa.system.local/local-worker-system
:worker-count 2
:autostart true}
:test-db {:system-def #'titanoboa.system.jdbc/jdbc-pool
:autostart true}
:archival-system {:system-def #'titanoboa.system.local/archival-system
:autostart true}
:auth-system {:system-def #'titanoboa.system.auth/auth-system
:autostart true}}
:jobs-repo-path "repo/"
:steps-repo-path "step-repo/"
:job-folder-path "job-folders/"
:log-file-path "titanoboa.log"
:enable-cluster false
:jetty {:ssl-port 443
:join? false
:ssl? true
:http? false
:keystore "keystore.jks"
:key-password "somepwdgoeshere"}
:archive-ds-ks [:archival-system :system :db-pool]
:auth-ds-ks [:auth-system :system :db-pool]
:auth? true
:auth-conf {:privkey "auth_privkey.pem"
:passphrase "Ilovetitanoboa!"
:pubkey "auth_pubkey.pem"}
:systems-config {:core
{:new-jobs-chan (clojure.core.async/chan (clojure.core.async/dropping-buffer 1024))
:jobs-chan (clojure.core.async/chan (clojure.core.async/dropping-buffer 1024))
:finished-jobs-chan archival-queue-local}
:archival-system
{:jdbc-url "jdbc:postgresql://localhost:5432/mydb?currentSchema=titanoboa"
:user "postgres"
:password "postgres"
:finished-jobs-chan archival-queue-local}}}))Titanoboa supports JWT authentication. It can be easily configured as a part of the server-config under :auth-conf key:
:auth? true
:auth-conf {:privkey "auth_privkey.pem"
:passphrase "Ilovetitanoboa!"
:pubkey "auth_pubkey.pem"}
:auth-ds-ks [:auth-system :system :db-pool]:auth-conf contains information regarding private/public key used for signing and :auth-ds-ks should provide link to a system property that provides a connection to the user database (more specifically to a datasource).
In this particular case it is the :auth-system defined in :systems-catalogue and the datasource is :db-pool so the whole keyword sequence is [:auth-system :system :db-pool].
Each job definition has its own webhook URI that can be used to start a job. Naturally not all consumers of webhooks will support JWT - and so titanoboa makes it possible to define custom authentication function for any URI. In case an extension function is defined for give URI and no JWT token is found, this function is then used to authenticate. It takes the request as an argument and it is supposed to return a transformed request (e.g. to add :auth-user to the request or to return {:status 401} instead etc.)
For example Github can call webhooks, but it does not support JWT, instead it can provide a HMAC hex digest of the request body as a signature.
To unsign webhook requests from Github, one could use following custom security extension in server-config:
:auth-conf {:privkey "auth_privkey.pem"
:passphrase "Ilovetitanoboa!"
:pubkey "auth_pubkey.pem"
:extensions {"/systems/%3Acore/jobs/github2slack" (fn [request]
(let [x-hub-signature (get-in request [:headers "x-hub-signature"])
payload (slurp (:body request))]
(let [payload-signature (str "sha1=" (pandect.algo.sha1/sha1-hmac payload "qnscAdgRlkIhAUPY44oiexBKtQbGY0orf7OV1I50"))]
(if (crypto.equality/eq? payload-signature x-hub-signature)
(assoc request :auth-user "github")
{:status 401 :body "x-hub-signature does not match"}))))}}This extension is simple and would just need following dependencies added to the External dependencies file:
{:coordinates [[pandect "0.6.1"]
[crypto-equality "1.0.0"]]
:require [[pandect.algo.sha1]
[crypto.equality]]}This way all requests going to URI /systems/%3Acore/jobs/github2slack (i.e. all requests starting a job "github2slack") will be authenticated using this custom security extension.
All systems are specified in the server config under systems catalogue map (:systems-catalogue) as follows:
:systems-catalogue {:core {:system-def #'titanoboa.system.local/local-core-system
:worker-def #'titanoboa.system.local/local-worker-system
:autostart true
:worker-count 2}}The map :systems-catalogue contains all systems (core and non-core). Core systems are identified simply by having also a :worker-def property specified. The id of the system (:core in this example) could of course be different, but :core is the most used convention.
Nothing is preventing titanoboa from running multiple core systems, with different ids, presumably running on different MQ providers.
:system-def and :worker-def point to declaration of core and worker systems that should be used.
:worker-count specifies how many workers should by started on startup. If not specified, titanoboa will start the same number of workers as is the number of CPUs of given server. As this reading does not always work in all versions of java in virtualized environment (older versions of java return the physical number, not the virtual) it is recommended to be set in any virtualized environment.
In titanoboa's community edition, following two core systems are provided out of the box:
| Job Channel MQ Provider | Core System | Worker System |
|---|---|---|
In-memory core.async queues |
titanoboa.system.local/local-core-system | titanoboa.system.local/local-worker-system |
| Rabbit MQ | titanoboa.system.rabbitmq/distributed-core-system | titanoboa.system.rabbitmq/distributed-worker-system |
Here is a sample of a non-core system, a JDBC connection pool. The system is defined here.
We can simply add this stystem to the :systems-catalogue in server config:
:test-db {:system-def #'titanoboa.system.jdbc/jdbc-pool
:autostart true}and a configuration in the :systems-config could look as follows:
:test-db
{:jdbc-url "jdbc:postgresql://localhost:5432/mydb?currentSchema=titanoboa"
:user "postgres"
:password "postgres"
:driver-class "org.postgresql.Driver"}The connection pool will start on titanoboa's startup and we can then simply use it in our workflow steps!