This is a Machine Learning 'operationalization' project [showcasing the know-how by determining deployments targets, enabling foresights, baselining performance metrics, scaning logs and benchmarking], which was part of the ML Engineer for Microsoft Azure Nanodegree Scholarship (preparing for Microsoft [Designing and Implementing a Data Science Solution on Azure] Exam DP-100).
The business goal/objective was binary classification inferencing [for decision intel foresights] on product sales (predicting if the product (term deposit) could be subscribed to (or not), when a bank client is contacted?). ... more on the Bank [Direct] Marketing dataset whitepaper
Rather than the usual "VotingEnsemble", the best performing model was an Azure AutoML [MaxAbsScaler & LightGBM] algorithm having had scored a %95.09 AUC weighted (in contrast to the other run type which was a pipeline same algorithm's best model having scored a %94.5 AUC weighted); using such AutoML to train the best ML model before its OpenAPI endpoint gets deployed for production-ready consumption by the other ecosystem microservices (including azure automation and/or logic apps) for optimal 'Decision Intelligence MLSecOps' synergy.
Below is the formal diagram related to the visualization of the project's main steps (as listed in the next section):

Potential future improvements could be identified as:
- Retraining Hyperparameter Tuning with HyperDrive using Bayesian and/or 'Entire Grid' sampling.
- Extending AutoML config to include more parameters.
- Documenting XAI and [operationalizing] model [explanation] as a web service, using the [interpretability package] to explain ML models & predictions.
- Exporting Models with ONNX to be deployed to a DLT connected Dapp device.
- Integrating App Insights with Sentinel and/or CASB.
Pending standout suggestions that were attempted include:
- Completing the optional items about load-testing the endpoint.
- Using a Parallel Run Step in a pipeline. - Testing a local container with a downloaded model.
- Exporting the model for supportting ONNX.
- 1st MLSecOps Project (C2) Screencast Demo in 10 mins: https://vimeo.com/510089644/b87c5d0480
- 1st MLSecOps Project (C2) Screencast Demo in 5 mins: https://vimeo.com/510089284/85418699a2
Above recordings' links were for the MLSecOps demo of the entire process of the actionable [production ready] project; including showcasing of:
- Working deployed ML model endpoint.
- Deployed Pipeline.
- Available AutoML Model.
- Successful API requests to the endpoint with a JSON payload.
Below are the required screenshots to demonstrate [along with the above screencasts and describtions] the completed project [overall end-to-end workflow's] critical stages criteria meeting its various main steps's specifications:
Mainly creating a Service Principal account and associating it with a specific workspace.
!az ml workspace share -w workspace1st -g dsvm1st --user --- --role owner
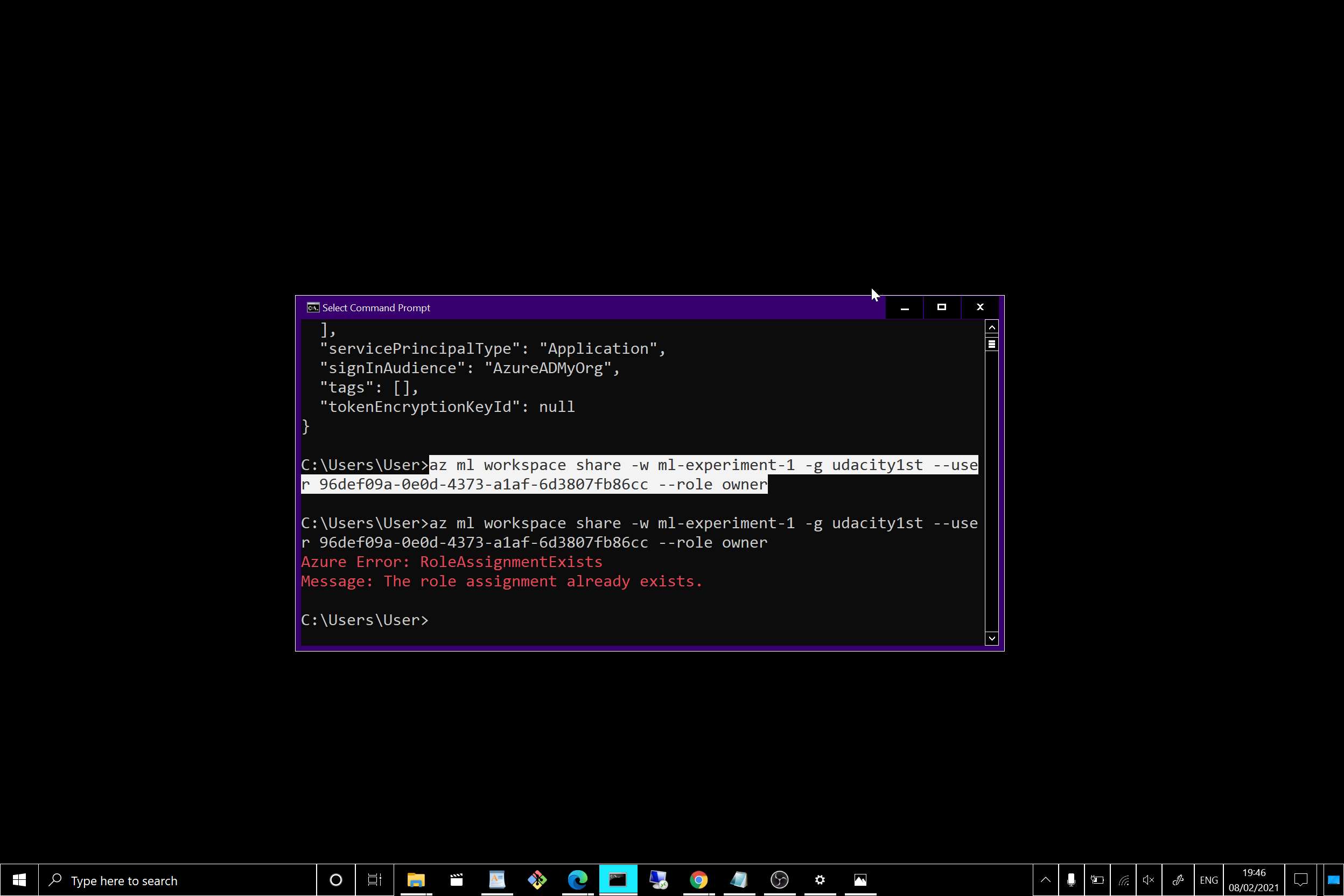
 Udacity no authorization to perform roleAssignmentswrite over scope
Udacity no authorization to perform roleAssignmentswrite over scope

Creating an experiment using Automated ML, configuring a compute cluster, and using it to run an experiment.
- “Registered Datasets” in ML Studio shows "Bankmarketing" dataset available:
![1st-AutoML-002 Registered Datasets in ML Studio shows [Bankmarketing] dataset available](/c6ai/C2/blob/main/images/201.png?raw=true)
- The Auto ML experiment is shown as completed:


Deploying the AutoML run's Best Model for interacting with the HTTP API service and or the model [over POST requests].
- Endpoints section in Azure ML Studio, showing that “Application Insights enabled” says “true”:

Retrieving logs by enabling Application Insights at deploy time [with a check-box, or later by runing a code].
- Logging is enabled by running the provided logs.py script:

Consuming the deployed model using the [OpenAPI] Swagger JSON file to interact with the trained model.
- Swagger runs on localhost showing the HTTP API methods and responses for the model:
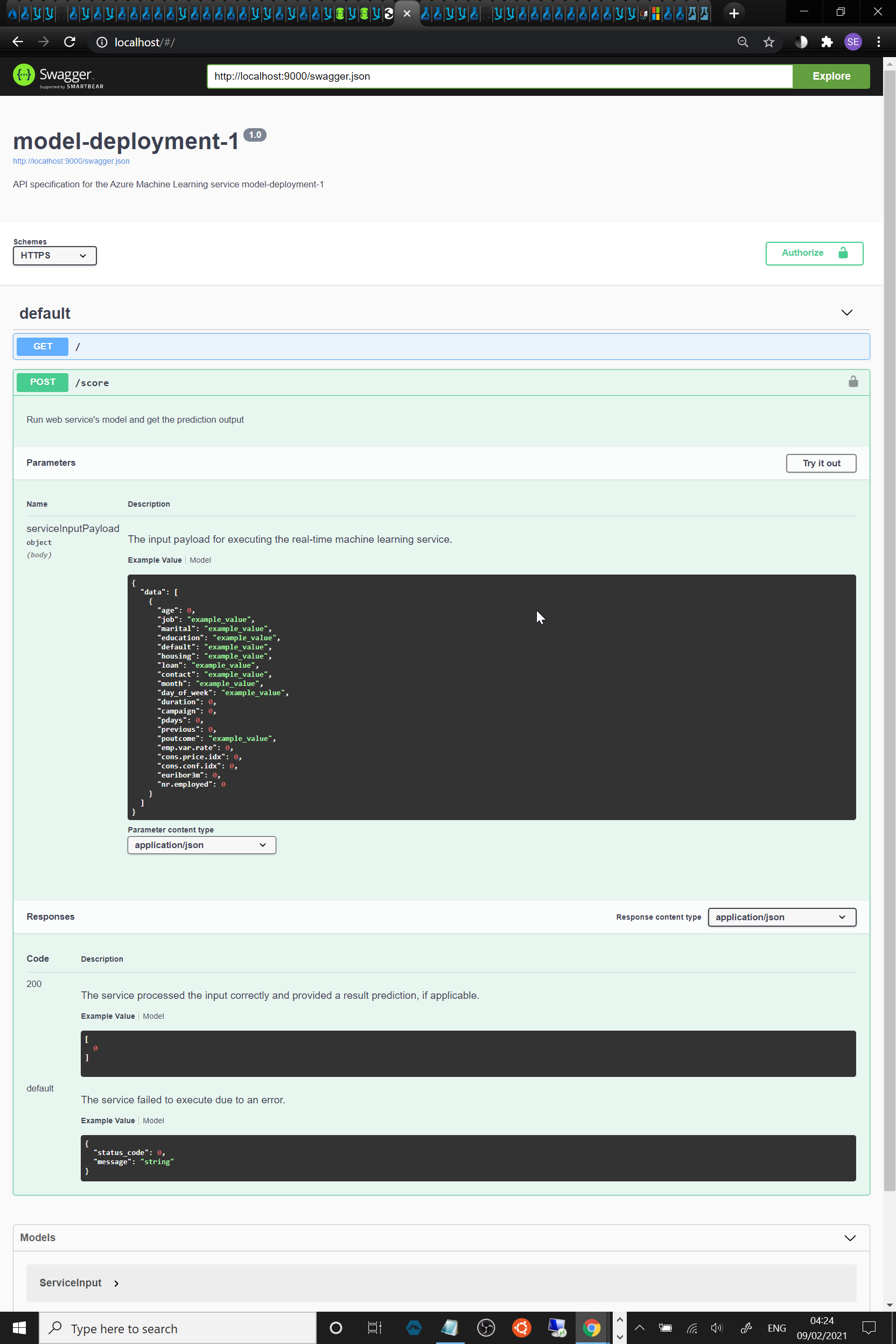
Consuming the deployed model using the endpoint's scoring_uri and its key that was generated post deployment.
- endpoint.py script runs against the API producing JSON output from the model:

- [OPTIONAL] Apache Benchmark (ab) runs against the HTTP API using authentication keys to retrieve performance results:

Updating a Jupyter Notebook with already created [same AutoMl's] keys, URI, dataset, cluster, and model names.
- The pipeline section of Azure ML studio, showing that the pipeline has been created:

- The Bankmarketing dataset with the AutoML module:
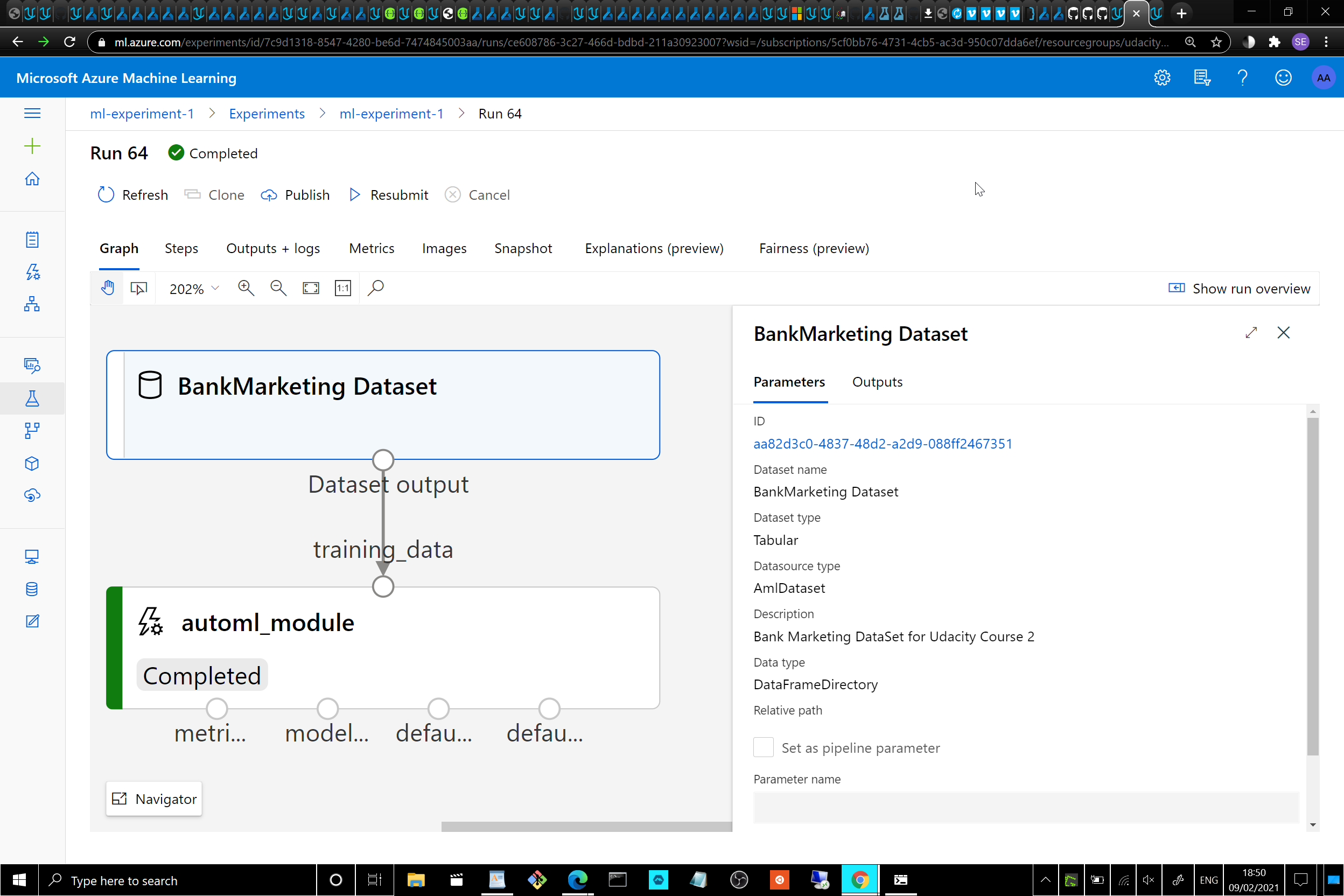 Registered Datasets in ML Studio shows [Bankmarketing] dataset available
Registered Datasets in ML Studio shows [Bankmarketing] dataset available
- The “Published Pipeline overview”, showing a REST endpoint and a status of ACTIVE:



- showing the “Use RunDetails Widget” with the step runs:

-
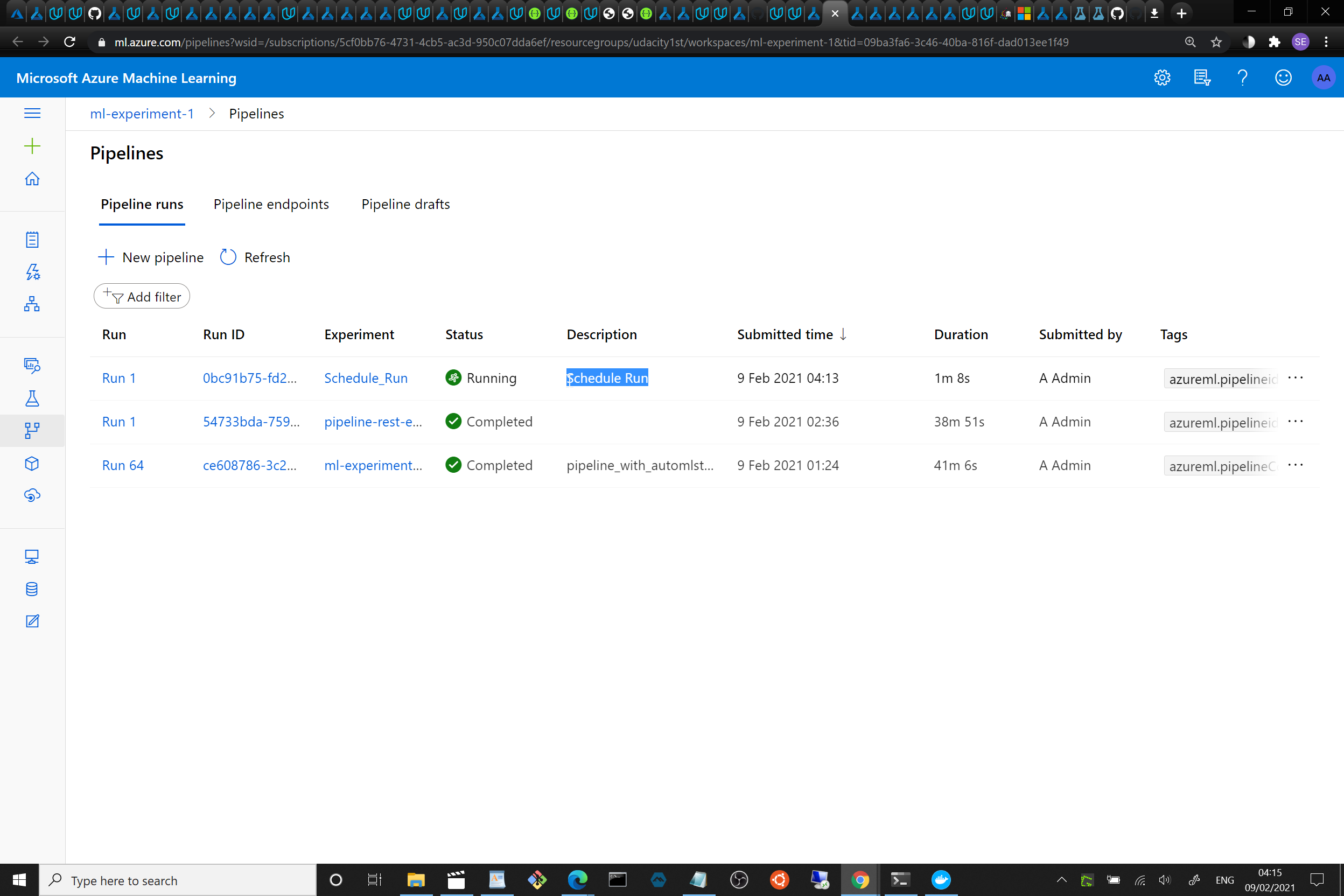
ML studio showing the pipeline endpoint as Active:

-
ML studio showing the scheduled run: