Home
主题模型是文本挖掘的重要工具,近年来在工业界和学术界都获得了非常多的关注。虽然研究人员提出了多种多样的主题模型来适应不同的场景,这些工作主要集中在“建模”层面,即设计合理的模型来适配各色各样数据,而指导主题模型在工业场景“落地”的文献和资料却非常稀少。在Familia开源项目中,我们汇总了主题模型在工业界的一些典型应用案例,方便软件工程师们按图索骥,找到适合自己任务的模型以及该模型的应用方式。希望这里汇总的经验可以帮助软件工程师们跨越“建模”和“落地”之间的鸿沟,使主题模型技术在工业界发挥更大的价值。
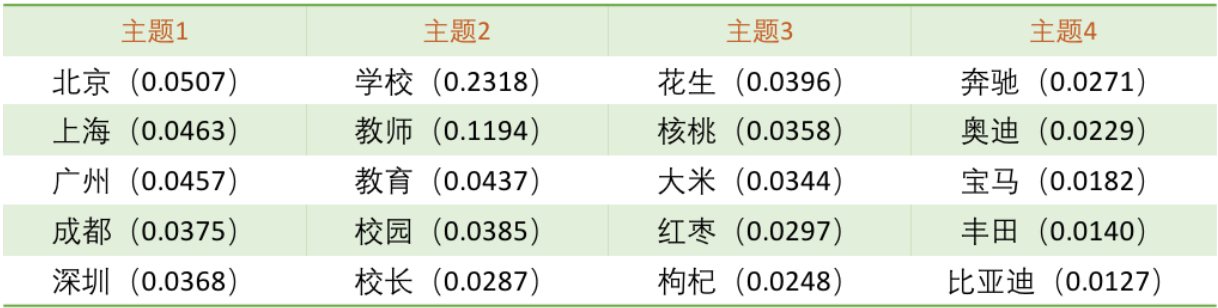
在主题模型中,“主题”通常被定义为一系列语义相关的词。Latent Dirichlet Allocation(LDA)是其中最具代表性的模型。下表中给出了LDA的部分训练结果。其中,每列词是一个主题,每个词后的数值表示该词在主题中的重要程度。
由于LDA中采用文档内的Bag-of-Words假设,词与词之间的位置信息是被忽略的。在很多工业界场景中,我们往往需要限制某些位置相近的词产生自同一主题,通过SentenceLDA能很好地满足这个需求。SentenceLDA假设同一个句子里的词产生自同一主题,对句子内的词进行了进一步的建模,能捕捉到更加细粒度的共现关系。LDA产生的主题往往被高频词占据,这种现象导致低频词在实际应用中的作用非常有限。Topical Word Embedding (TWE) 利用LDA训练获得的主题为词向量的训练提供补充信息,进而得到词和主题的向量表示。有鉴于向量表示可以较好地建模低频词的语义信息,通过利用词和主题的向量表示,我们可以更好地捕捉每个主题下的低频词的语义信息,提升下游应用的效果。
主题模型在工业界的应用范式可以分为两类:语义表示和语义匹配。我们选取一些成功的应用案例加以介绍。