This repository has been archived by the owner on Jan 24, 2024. It is now read-only.
Code Structure
本页面介绍代码章节。
-
cinn包含了核心大部分代码 -
cmake为 CMAKE 的封装及第三方库的 CMAKE 配置 -
docs预计为文档页面 -
python为 python 封装 -
testscinn 整体相关的测试,目前包含test01和test02,主要包含了向量、矩阵乘的 C 源码生成的性能测试
进入 cinn 之后
-
backends为各种硬件后端的封装,包括CodeGen,JIT等 -
common为 IR 层次的复用函数方法 -
hlir包含了 IR 以上的组网封装,包括 primitive, Op, Model 等等 -
ir包含了最底层 IR 相关的实现 -
lang包含了 CINN DSL 的相关代码 -
optim包含底层 IR 的各类改写及优化 -
poly包含了polyhedral compilation相关封装 -
pybind包含了 pyton 相关封装(TODO 整理到 python 下) -
python包含了 python 相关封装 (TODO 整理到 上层 python 下) -
runtime包含了执行时的一些封装 -
utils包含了各类通用的工具方法
以下介绍 CINN 相关的一部分概念
- CINN IR,类似 + - * %,跟 LLVM IR 有一定对应关系,是 CINN 的最底层表示
- CINN DSL,CINN 底层用于表示计算的一套专有语法,比如
auto C = Compute({10, 20}, [](Expr i) { return A(i) + 1.f; })- 目前有 C++ 和 Python 两种支持
- Primitive,基础原语,表示计算的最基本单元,比如
Dot,Broadcast等等;根据不同后端,Primitive 可能会进一步lower成 基础 CINN IR - HLIR(Hight Level IR) ,包含了 CINN IR 上层所有的组网的模块封装
- PE (Peirmitive Emitter) ,目录在
cinn/hlir/pe,包含了一些计算的 helper function,比如matmul(...等等
CINN 中计算的定义是一个组织 SSA 的过程,Tensor 在其中就是 SSA 节点,其特性是
- 名字不同的 Tensor 严格表示不同的计算过程,反之,名字相同表示相同的过程
Tensor 一般由 Compute 来创建,比如
Expr M(100), N(200);
Placeholder<float> A("A", {M, N});
Placeholder<float> B("B", {M, N});
Tensor C = Compute({M,N}, [=](Expr i, Expr j) { return A(i,j) + B(i,j); });Compute 有多种使用方法,比较重要的方法声明
ir::Tensor Compute(const std::vector<Expr> &domain,
compute_handler_t fn,
const std::string &name = "",
const std::vector<Var> &reduce_axis = {},
const std::vector<Expr> &shape = {});有关 reduce axis 的使用方法可以参考 tests/test02_matmul_main.cc .
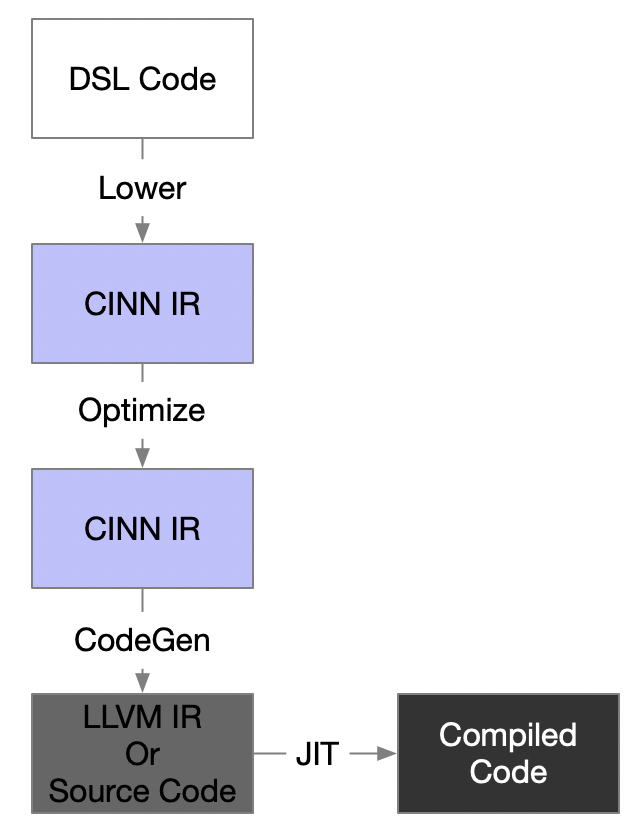
输入前端传入的 DSL 定义,返回底层的 CINN IR。
中间包含的步骤:
- polyhedral 表示 经过 AstGen 生成 AST
- AST 扩展为 CINN IR
- 一系列的后处理,针对 polyhedral 不方便处理的部分做修改
- 一系列的优化处理
CodeGen 用于给定 CINN IR,生成最终的 LLVMIR 或者硬件源代码,目前有以下后端
- CodeGenC: C 源码生成
- CodeGenCX86:带 X86 SIMD 的 C 源码生成
- CodeGenLLVM:LLVM IR CodeGen 的基类
- CodeGenX86: 面向 X86 LLVM IR 生成的后端
- CodeGenCUDA_Dev, CodeGenCUDA_Host, 面向 CUDA 的 device 以及 Host 的代码生成
基于 LLVM 的 JIT 实现,目前有两个
-
ExecutionEngine,带优化的实现,用于生产环境 -
SimpleJIT, 最简实现,用于debug
- matrix mulplication 相关
tests/test02_matmul_main.cc