Hongjin Su*, Shizhe Diao*, Ximing Lu, Mingjie Liu, Jiacheng Xu, Xin Dong, Yonggan Fu, Peter Belcak, Hanrong Ye, Hongxu Yin, Yi Dong, Evelina Bakhturina, Tao Yu, Yejin Choi, Jan Kautz, Pavlo Molchanov
NVIDIA · The University of Hong Kong
*Equal Contribution
-
2025/12/5: Our generated dataset ToolScale became the #1 most-downloaded dataset on Hugging Face, and Nemotron-Orchestrator-8B ranked #3 among all models.
-
2025/12/2: 🏆 ToolOrchestra ranks #1 on GAIA benchmark!
-
2025/11/27: We release the code, training data, and model checkpoints of ToolOrchestra.
 |
 |
We introduce ToolOrchestra, a method for training small orchestrators that coordinate the use of intelligent tools. By using both tools and specialized models, ToolOrchestra surpasses GPT-5 while being much more efficient. Given a task, the Orchestrator alternates between reasoning and tool calling in multiple turns to solve it. The Orchestrator interacts with a diverse tool set, including basic tools (e.g., web search, code interpreter), specialized LLMs (e.g., coding models, math models), and generalist LLMs (e.g., GPT-5, Llama-Nemotron-Ultra-253B, Claude Opus 4.1). During training, Orchestrator is jointly optimized by outcome, efficiency, and preference rewards via end-to-end reinforcement learning. To aid RL training, we develop an automatic pipeline to synthesize both environment and tool-call tasks at scale.
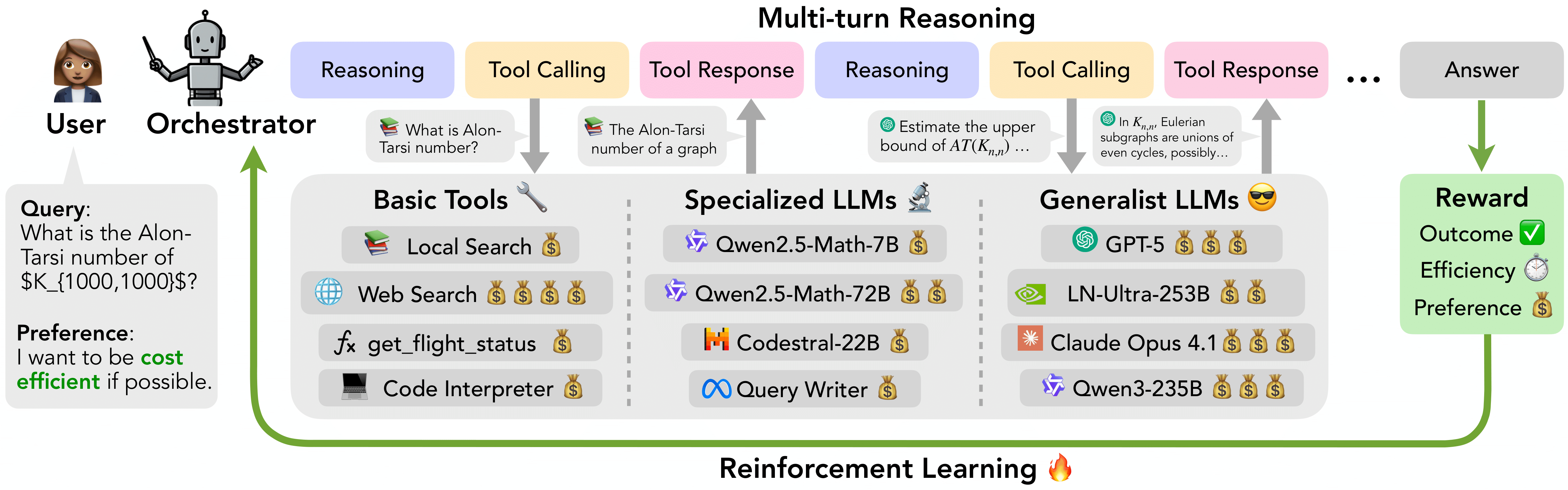
With ToolOrchestra, we produce Orchestrator-8B, a state-of-the-art 8B parameter orchestration model designed to solve complex, multi-turn agentic tasks by coordinating a diverse set of expert models and tools.
Key Results:
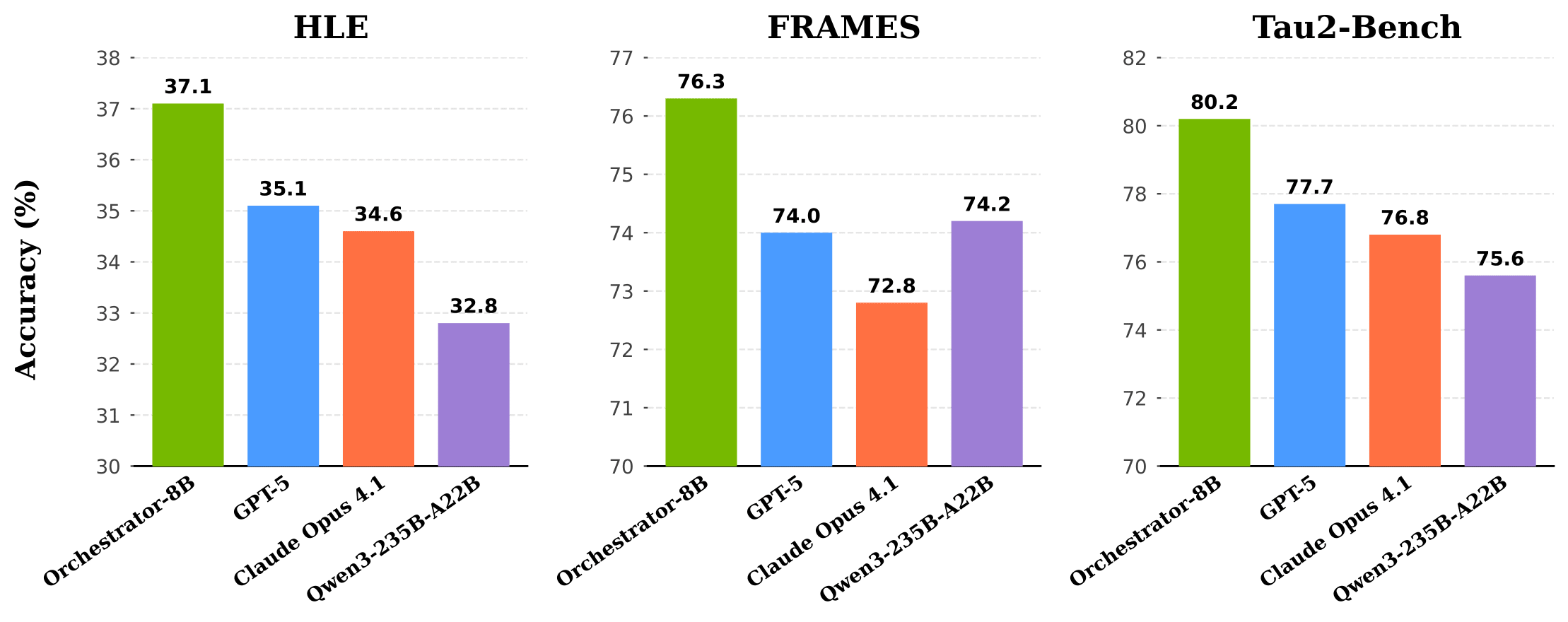
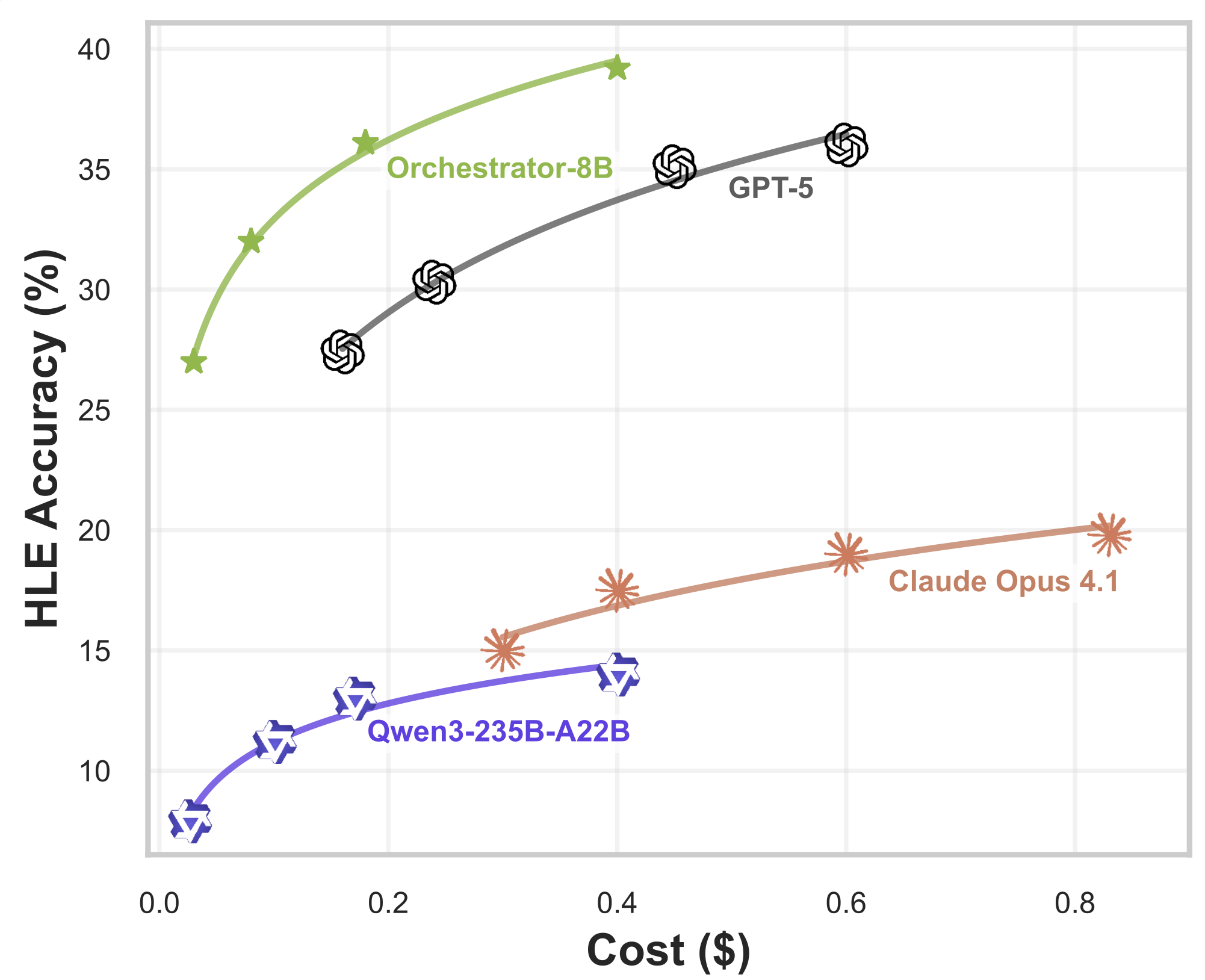
- On HLE, Orchestrator-8B achieves a score of 37.1%, outperforming GPT-5 (35.1%) while being 2.5× more efficient
- On τ2-Bench and FRAMES, Orchestrator-8B surpasses GPT-5 by a wide margin while using only ~30% of the cost
# Clone this repository
git clone https://github.com/NVlabs/ToolOrchestra.git
cd ToolOrchestra
# Download index files and checkpoints
git clone https://huggingface.co/datasets/multi-train/index
export INDEX_DIR='/path/to/index'
git clone https://huggingface.co/nvidia/Nemotron-Orchestrator-8B
export CHECKPOINT_PATH='/path/to/checkpoint'
# Set environment variables
export HF_HOME="/path/to/huggingface"
export REPO_PATH="/path/to/this_repo"
export CKPT_DIR="/path/to/checkpoint"conda create -n toolorchestra python=3.12 -y
conda activate toolorchestra
pip install -r requirements.txt
pip install -e training/rolloutconda create -n retriever python=3.12 -y
conda activate retriever
conda install pytorch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 pytorch-cuda=12.1 -c pytorch -c nvidia
pip install transformers datasets pyserini
conda install -c pytorch -c nvidia faiss-gpu
pip install uvicorn fastapiconda create -n vllm1 python=3.12 -y
conda activate vllm1
pip install torch transformers vllm
cd evaluation/tau2-bench
pip install -e .cd training
python resume_h100.pycd evaluation
# Evaluate on HLE (requires env: vllm1 and retriever)
python run_hle.py
# Evaluate on FRAMES (requires env: vllm1 and retriever)
python run_frames.py
# Evaluate on τ2-Bench (requires env: vllm1)
cd tau2-bench/
python run.pyPlease go to Tavily and apply for an API key.
export TAVILY_KEY="your_key"- LLM Calls: Modify the
get_llm_responsefunction inLLM_CALL.pyto change LLM calls to services beyond vLLM and OpenAI - Prompts: Modify lines
455-458ineval_hle.pyand506-509ineval_frames.py - Tool Configuration: Substitute
tool_configin line 27 ofeval_frames.pyandeval_hle.pyfor different tool sets - Tools & Models: Modify
tools.jsonand thecall_toolfunction ineval_hle.py - Parallel Experiments: Modify variables
{EXPERIMENT_NAME1},{EXPERIMENT_NAME2},{EXPERIMENT_NAME3}intraining/resume_h100.py, which should correspond to the file names in the directory
To prevent connection errors to host models in HLE, you may comment this line, then run:
# In separate processes
python run_hle.py
python eval_hle.py --model_name {cur_ckpt_dir} --output_dir {cur_output_dir} --model_config model_configs/serve2.json --example_path hle.jsonlThis project is licensed under the Apache 2.0 License.
If you find this repository useful, please consider giving a ⭐ and citing our paper:
@misc{toolorchestra,
title={ToolOrchestra: Elevating Intelligence via Efficient Model and Tool Orchestration},
author={Hongjin Su and Shizhe Diao and Ximing Lu and Mingjie Liu and Jiacheng Xu and Xin Dong and Yonggan Fu and Peter Belcak and Hanrong Ye and Hongxu Yin and Yi Dong and Evelina Bakhturina and Tao Yu and Yejin Choi and Jan Kautz and Pavlo Molchanov},
year={2025},
eprint={2511.21689},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2511.21689},
}