- While I didn't get nearly as far as I wanted to, I am happy with the current solutions for thresholding to identify the code + clustering to differentiate between the code and any other objects
- All in all I spent a few hours working on this (including research)
- All the code is in the main directory
- Images are stored in subdirectories (the original images are in raw_images)
run.pyis where all of the actual outputs are intended to be generatedanalysis.py,boundboxing.py,canny_contouring.py,image_compression.py,thresholding.py, andutil.pyare all modules that hold the functions used inrun.pyor by each other.
- First you'll need to get Python. I used python 3.7.1 (for 64-bit windows, but that shouldn't matter).
- Next, you'll need to install the right python packages to allow the code to run
- You can use
pennairapp_reqs.ymlto create the environment- Ex:
> conda env create --file pennairapps_req.yml --name pennairapp
> conda activate pennairapp- pip is the
- numpy
- scipy
- matplotlib
- scikit-image
- scikit-learn
- Run
> pip install numpy
> pip install scipy
...- If things aren't working out and you want specific versions of each package, see
pennairapp_reqs.txt- See here for the docs for pip if you need to install a specific version of a package
- (if you are using conda make sure you activate the environment. If you are using pip's virtual env, make sure you activate that)
> python ..../run.py - Where
..../run.pyis the path torun.pyon your system
Email me at [email protected] if you have any trouble! If need be, I can simply email you images after each stage of the image pipeline.
- Within
run.pyyou can similarly see where I was planning to go - Below you can find some research and thinking I did before I started and also some of how my solution evolved
- 4 parts to the QR code
- All of approximately equal size
- May be some ovealap between the pieces
- Pieces may need to be re-oriented to fit
- QR code is of version 1 and error correction level H
- The qr codes are of roughly equal sizes
- Version 1 means a 21 x 21 px qr code
- V1 QR code in H mode can store up to 41
- Sizing information

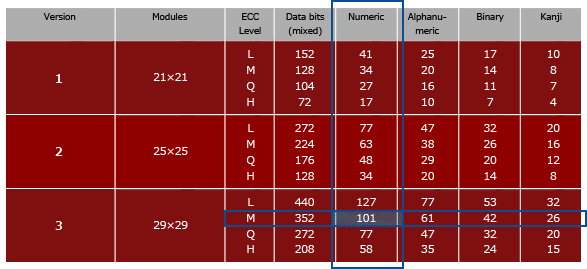
- Level H is 30% ECC
- Means if 30% of 8bit code words are lost, the value of the QR code can still be recovered
- Potentially, this means only 3 quarters are needed
- Uses reed-solomon
- Core unit appears to be 4x2 rectangle (total of 8 bits, 1 byte)
- This is called a module (per this detailed doc on QR specs)
- According to this, the module are read right to left, bottom to top (when we look at the QR code s.t. the eyes are at top left, bottom left, top right)
- There is a mode indicator at the bottom right
- 0001 indicates numerical
- Then above that is the char count indicator ()
- Then data starts by snaking around each column
- 3 eyes in top left, bottom left, top right
- Potentially a small orientation one in the bottom right
- Data is masked to ensure best efficiency

- When scanned, produces a value of 0106
- We can also see by examining the very bottom left 2x2 square that the encoding mode must be numerical
- What processes did I use to piece it together?
- Orientation of the 3 eyes
QR code pieces are square, which means that they will always have 4 corners (no matter angle of photography etc)
- Our QR codes are white with black data
- This contrast with their background which is black (but also can have lots of glare, making it appear close to yellow)
- The given QR code has a greater lustrousness than its surroundings
- The QR alternates between white and black, producing high contrast regions
- The QR has eyes which encode orientation
- Core problem is to determine where the relevant pixels lie
- see above
- In: an image (rgb?)
- Out: any of
- a list of pixels
- bounding box (l, r) (t, b)
- lines
- The given images (visually analyzing them)
- Any additional test cases will be added under test
- The method of using the color difference seems most promising
- Potentially will need to fit the pixels we get to a quadrilateral
- Rather than try to cut out the entire QR code section, only look at the white part of the QR code since that has greatest contrast
- Since QR codes are binary, we can easily define negative space later on
- Thresholding often yields QR code + a shoe + some noise -> need to seperate them
- Usually all of these are spaced far apart
- A clustering algorithm like DBSCAN could be used