
Face recognition learning model for Japanese people
- About the learning model posted here.
- Intended for facial recognition of Japanese people.
- Free to use. Please display copyright notice when using.
- A license is required if you want to use it commercially.
Facial recognition technology is used in every aspect of our lives, from unlocking smartphones to airport systems.
However, the existing face recognition model of OSS, dlib_face_recognition_resnet_model_v1.dat from Dlib, demonstrates high accuracy for Caucasian faces. Yet, it has a notable issue with its accuracy for other races, especially young Japanese women.
Dlib is an open source library for machine learning and data analysis originally written in C++. Development began in 2002 by Davis King. Dlib is well known in the field of facial recognition, but its capabilities don't stop there. This library covers a variety of tasks such as image processing, machine learning, natural language processing, and numerical optimization. This library, developed in C++, also provides Python bindings. Development is currently continuing at dlib(GitHub).
This model is a ResNet-based deep learning model that is capable of facial recognition with extremely high accuracy. It was launched in 2017. Accuracy on the Labeled Faces in the Wild (LFW) dataset is reported to be 99.38%. This high degree of accuracy is one reason Dlib and its facial recognition model are widely adopted.
However, although this model was highly accurate for Caucasians, it was less accurate for other races, especially young Japanese women. Therefore, in the past, it was necessary to take measures such as adjusting the threshold to improve recognition accuracy. Also, even after adjusting the threshold, there was still a problem where a certain number of False Positives still existed.

Example of Dlib giving false positives
Therefore, we decided to develop a new face recognition model using a Japanese face dataset.
As a result, the newly developed learning model is 26MB, which is slightly larger than the existing dlib model (22.5MB), but it is possible to perform more accurate facial recognition of Japanese people with the same computational resources.
EfficientNetV2, which was pre-trained on ImageNet, a large-scale image dataset, was fine-tuned using ArcFace on a Japanese face dataset.
This improved separation in the feature space and significantly increased the accuracy of Japanese face recognition.
Visualization results using UMAP

In order to compare and evaluate the performance of these face learning models, we performed the following verification. Please note that the face dataset used is not included in the dataset used to create JAPANESE FACE v1.
We randomly selected 300 images from a facial image database of famous Japanese people and created a facial image dataset of ordinary Japanese people. We performed face recognition on this dataset using dlib_face_recognition_resnet_model_v1.dat and calculated ROC-AUC. The result is below.

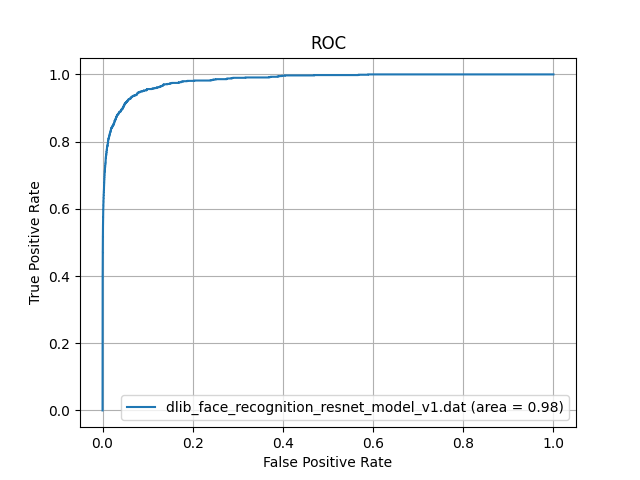
For ordinary Japanese people, the AUC of dlib_face_recognition_resnet_model_v1.dat is 0.98, indicating very high accuracy.
This time, we randomly selected 300 facial images of young Japanese women from a database of facial images of famous Japanese people, and created a dataset of facial images of young Japanese women. We performed face recognition on this dataset using dlib_face_recognition_resnet_model_v1.dat and calculated ROC-AUC. The result is below.

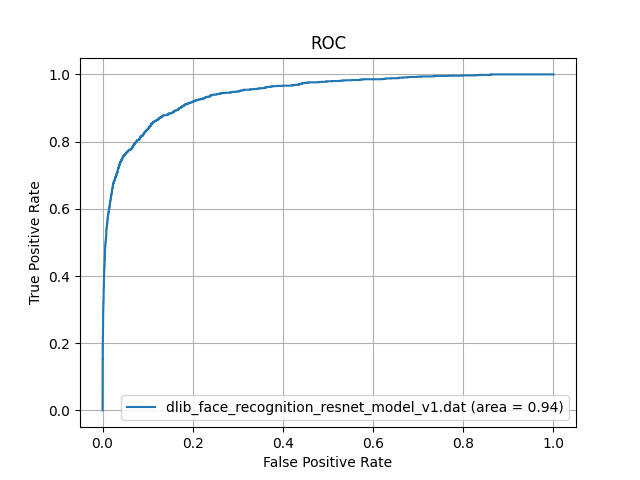
When we evaluated the performance of ordinary Japanese people using facial images of young Japanese women, the AUC decreased from 0.98 to 0.94. This is probably due to the fact that Dlib's face learning model mainly uses the face scrub dataset and VGG dataset. These datasets contain almost no facial images of young Japanese women, so it is thought that the performance will be degraded for facial images of young Japanese women. (See High Quality Face Recognition with Deep Metric Learning)
In order to solve this problem, JAPANESE FACE v1 is a model trained using a unique Japanese face dataset. This model was created by applying ArcFaceLoss to EfficientNetV2. The details of the creation are explained in detail in the article [Creating a new learning model for Japanese face recognition ~ EfficientNetV2 fine tuning ~] (https://zenn.dev/ykesamaru/articles/bc74ec27925896) .
The results of comparing this model with the Dlib learning model are shown below.
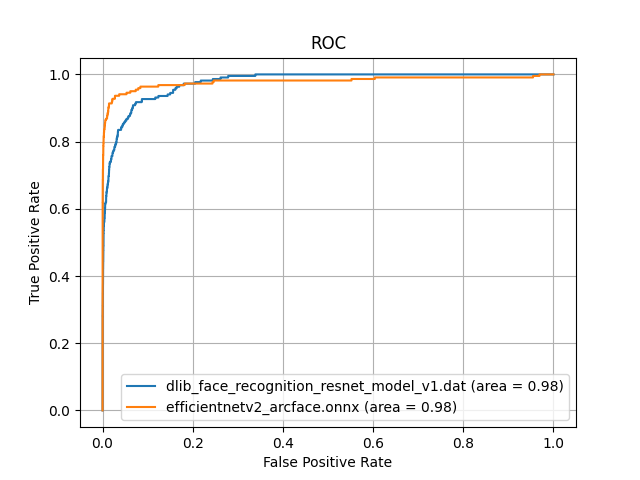
Compared to the Dlib learning model, the AUC is 0.98, showing comparable performance. Looking at the ROC curve, you can see that JAPANESE FACE v1 has a higher performance than dlib as the upper left part is convex.

For face images of young Japanese women, Dlib's AUC is 0.94, while `JAPANESE FACE v1' maintains 0.98.
Next, compare the F1-score. Here we only compare datasets for young Japanese women.
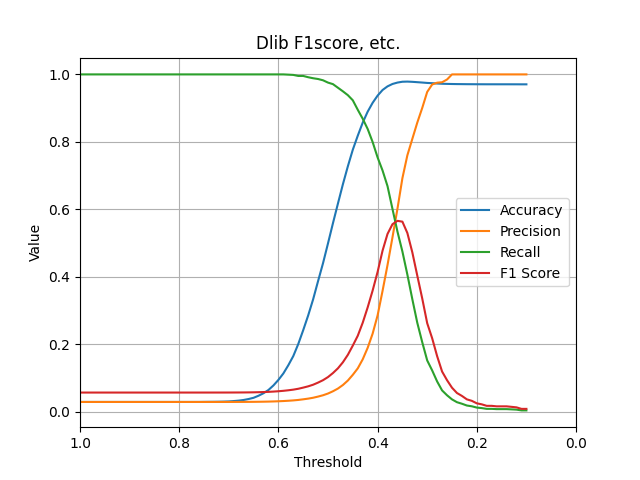
As Dlib's blog says, "The network training started with randomly initialized weights and used a structured metric loss that tries to project all the identities into non-overlapping balls of radius 0.6," the threshold is set to 0.6. However, when targeting the dataset of young Japanese women, the graph shows that 0.35 is the optimal threshold. Even in this case, the F1-score was around 0.55, which is not a very high value.
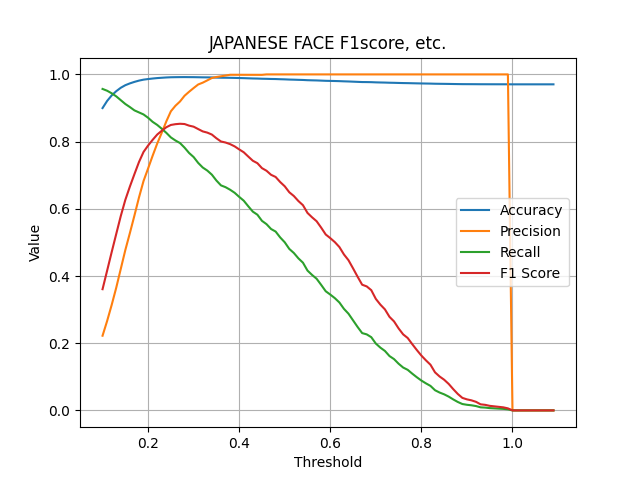
This model has an F1-score of over 0.8. This is thought to be because JAPANESE FACE v1 is trained using a dataset of young Japanese women, resulting in high accuracy.
https://github.com/yKesamaru/FACE01_SAMPLE
Please install FACE01 from the above URL.
It can be installed in bulk using setup.py or used with Docker.
Once the installation is complete, run the code below.
# Activate virtual environment
$ source ./bin/activate
# Run the example code
$ python example/simple_efficientnetv2_arcface.pyExample where all the people are judged to be the same person when using dlib_face_recognition_resnet_model_v1.dat (incorrect) was verified using the newly created learning model. In the new model, all were judged to be different people (correct answer).
import glob
import os
import sys
from itertools import combinations
import numpy as np
sys.path.append('FACE01')
from face01lib.Calc import Cal
from face01lib.utils import Utils
Utils_obj = Utils()
Cal_obj = Cal()
# Load images and calculate similarity
image_dir = "predict_test"
# Get the image file path
image_paths = glob.glob(os.path.join(image_dir, "*.png"))
embeddings = []
for image_path in image_paths:
embedding = Utils_obj.get_face_encoding(image_path)
embeddings.append(embedding)
# Calculate similarity
pairs = list(combinations(range(len(embeddings)), 2))
for i, j in pairs:
distance = np.linalg.norm(embeddings[i] - embeddings[j])
percent = round(Cal_obj.to_percentage(distance), 2)
print(f'{image_paths[i]}, {image_paths[j]}, {percent}%')- Hirofumi Arai, Nao Omori

- New learning model (
efficientnetv2_arcface.onnx)predict_test/Hirofumi Arai.png_align_resize.png, predict_test/Nantomo Omori.png_align_resize.png, False, 87.98%- Judgment; Someone else (Correct answer:o:)
- Existing learning model (
dlib_face_recognition_resnet_model_v1.dat)predict_test/Hirofumi Arai.png_align_resize.png, predict_test/Nantomo Omori.png_align_resize.png, 98.97%- Judgment: Same person (Incorrect answer:x:)

- Yua Shinkawa, Rio Uchida

- New learning model (
efficientnetv2_arcface.onnx)predict_test/Yua Shinkawa.png, predict_test/Rio Uchida.png, False, 81.46%- Judgment; Someone else (Correct answer:o:)
- Existing learning model (
dlib_face_recognition_resnet_model_v1.dat)predict_test/Rio Uchida.png_align_resize.png, predict_test/Yua Shinkawa.png_align_resize.png, 99.27%- Judgment: Same person (Incorrect answer:x:)

- Kim Jong Un, Azusa Babazono

- New learning model (
efficientnetv2_arcface.onnx)predict_test/Kim Jong Un.png_align_resize.png, predict_test/Azusa Babazono.png_align_resize.png, False, 79.87%- Judgment; Someone else (Correct answer:o:)
- Existing learning model (
dlib_face_recognition_resnet_model_v1.dat)predict_test/Kim Jong Un.png_align_resize.png, predict_test/Azusa Babazono.png_align_resize.png, 99.44%- Judgment: Same person (Incorrect answer:x:)

- Kiyohiko Ikeda, Yasutoshi Nishimura

- New learning model (
efficientnetv2_arcface.onnx)predict_test/Kiyohiko Ikeda.png_align_resize.png, predict_test/Yasutoshi Nishimura.png_align_resize.png, False, 72.26%- Judgment; Someone else (Correct answer:o:)
- Existing learning model (
dlib_face_recognition_resnet_model_v1.dat)predict_test/Kiyohiko Ikeda.png_align_resize.png, predict_test/Yasutoshi Nishimura.png_align_resize.png, 98.87%- Judgment: Same person (Incorrect answer:x:)

- Kim Jong Un, Nasa Hataoka

- New learning model (
efficientnetv2_arcface.onnx)predict_test/Kim Jong Un.png_align_resize.png, predict_test/Nasa Hataoka.png_align_resize.png, False, 77.82%- Judgment; Someone else (Correct answer:o:)
- Existing learning model (
dlib_face_recognition_resnet_model_v1.dat)predict_test/Kim Jong Un.png_align_resize.png, predict_test/Nasa Hataoka.png_align_resize.png, 99.37%- Judgment: Same person (Incorrect answer:x:)

- Yumiko Udo, Ringo Shiina

- New learning model (
efficientnetv2_arcface.onnx)predict_test/Yumiko Udo.png_align_resize.png, predict_test/Ringo Shiina.png_align_resize.png, False, 82.17%- Judgment; Someone else (Correct answer:o:)
- Existing learning model (
dlib_face_recognition_resnet_model_v1.dat) -predict_test/Yumiko Udo.png_align_resize.png, predict_test/Ringo Shiina.png_align_resize.png, 99.16%- Judgment: Same person (Incorrect answer:x:)

- Haru, Anna Iriyama

- New learning model (
efficientnetv2_arcface.onnx)predict_test/Haru.png_align_resize.png, predict_test/Anna Iriyama.png_align_resize.png, False, 81.46%- Judgment; Someone else (Correct answer:o:)
- Existing learning model (
dlib_face_recognition_resnet_model_v1.dat)predict_test/Haru.png_align_resize.png, predict_test/Anna Iriyama.png_align_resize.png, 99.07%- Judgment: Same person (Incorrect answer:x:)

- Mai Asada, Mao Asada

- New learning model (
efficientnetv2_arcface.onnx)predict_test/Mao Asada.png_align_resize.png, predict_test/Mao Asada.png_align_resize.png, False, 83.06%- Judgment; Someone else (Correct answer:o:)
- Existing learning model (
dlib_face_recognition_resnet_model_v1.dat)predict_test/Mao Asada.png_align_resize.png, predict_test/Mao Asada.png_align_resize.png, 99.27%- Judgment: Same person (Incorrect answer:x:)

In this article, we explained the development of a new model using EfficientNetV2 and ArcFace to improve the accuracy of facial recognition for Japanese people.
This new model showed better performance than the existing model (dlib_face_recognition_resnet_model_v1.dat) in recognizing Japanese faces. This will enable facial recognition technology to respond to even more diverse situations, and is expected to expand its range of applications.
- FACE01
- Face recognition library that integrates various functions and can be called from Python.
- EfficientNetV2: Smaller Models and Faster Training
- ArcFace: Additive Angular Margin Loss for Deep Face Recognition
- pytorch-image-models