Replies: 2 comments
-
|
@rootsid 👋 Hello! Thanks for asking about CUDA memory issues. YOLOv5 🚀 can be trained on CPU, single-GPU, or multi-GPU. When training on GPU it is important to keep your batch-size small enough that you do not use all of your GPU memory, otherwise you will see a CUDA Out Of Memory (OOM) Error and your training will crash. You can observe your CUDA memory utilization using either the
CUDA Out of Memory SolutionsIf you encounter a CUDA OOM error, the steps you can take to reduce your memory usage are:
AutoBatchYou can use YOLOv5 AutoBatch (NEW) to find the best batch size for your training by passing
Good luck 🍀 and let us know if you have any other questions! |


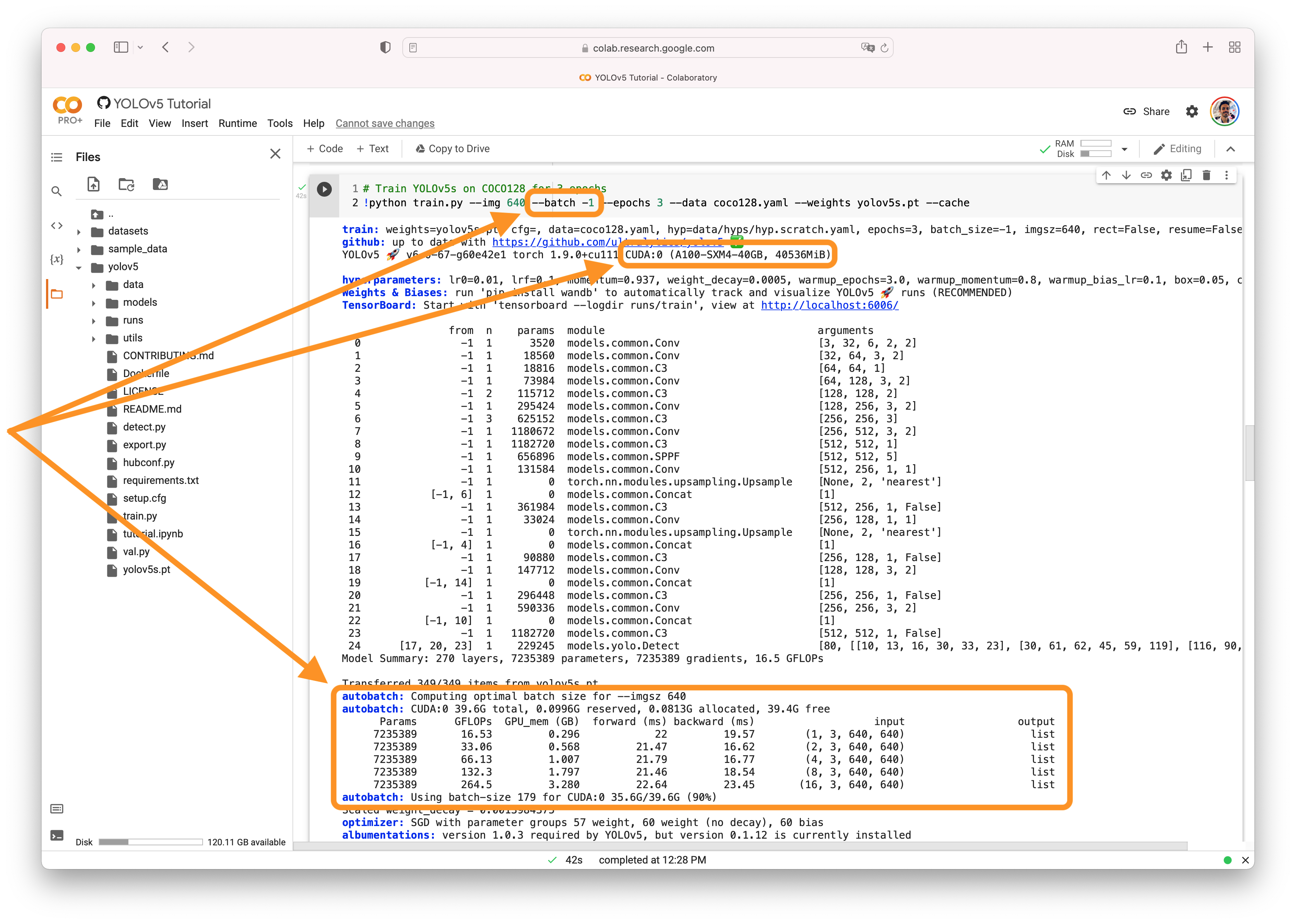
Beta Was this translation helpful? Give feedback.
-
|
Hi, can i check if size of training dataset (number of images) will affect GPU resources because I am currently using google colab pro and not sure if I can increase my dataset to fit into 16gb |
Beta Was this translation helpful? Give feedback.
-
I have to limit down the memory usage to 1GB to run multiple experiment at same time. In tensorflow we can use experimental growth limit, is there any way to limit down memory usage in yolov5 or pytorch?
I can reduce it down to 1.1GB by reducing the batch and image size, is it possible to reduce it further. I'm on minimum right now.
python train.py --img 64 --batch 1 --epochs 10 --data ./data.yaml --cfg ./models/yolov5s.yaml --weights '' --name yolov5s_results --cache.While this quiet doesn't satisfy what i'm looking for as i reduce batch size, all threads use 100% cpu all the time to there is huge cpu contention and i'm looking for multiple threads so there is area to optimize the execution time.
I got 8GB GPU memory, right now in a single run it consumes 3GB , i want to run 4 experiments together under 8GB memory. I'm trying a linux kernel config changes to optimize the machine learning experiments.
Beta Was this translation helpful? Give feedback.
All reactions