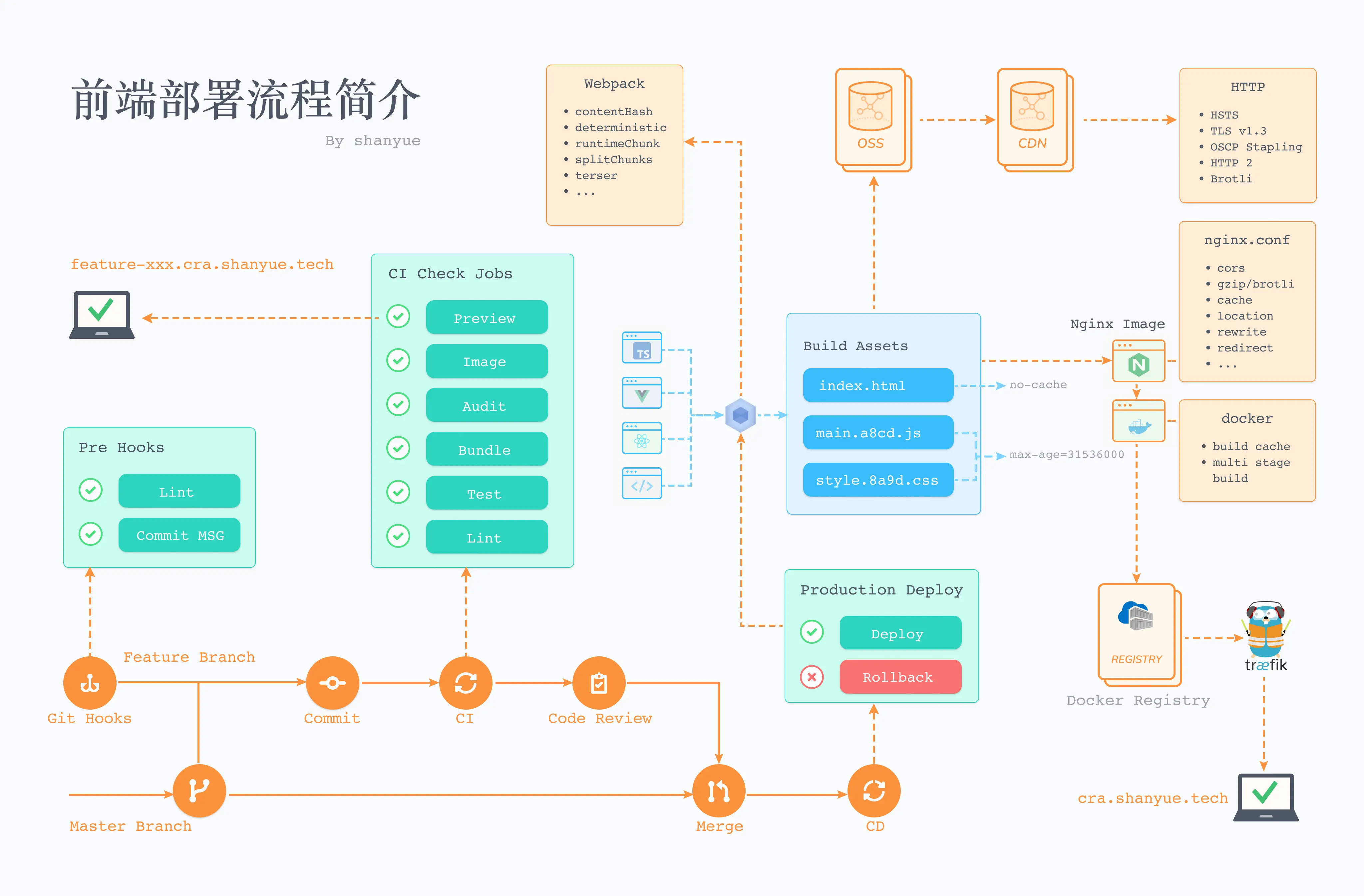
为了更深入理解前端部署,我们将从最原始的部署方案过渡到 Docker 与 Kubernetes,逐步进行优化,并使用 CICD 完善工程质量及部署效率。
你们公司的前端是如何进行部署的?很多人对前端部署感到陌生。
一方面,这些事情与业务无关,也很少有人注意到。另一方面,即便注意到,前端部署一般交给前端负责人或运维同学来负责,也很少有权限接触到相关事项。即使身在大厂,前端部署高度封装,仅需点点点即可完成部署,很多人对其中原理也难以捕捉。
实际上我们对于前端的部署,就是对其静态资源的服务。本专栏通过使用 nodejs 写一个简单的静态服务器,来简单理解前端部署。接下来本专栏将引导你使用 Docker 部署,并优化镜像、优化 Pipeline,一步一步探索前端部署优化及发展,并以单页应用为例进行实践部署。
本专栏需要您了解一些前置知识,如 docker/docker-compose/traefik/cicd 等基础用法。
在学习本专栏过程中,您可以随时查阅文档,在文章涉及到的相关配置,会指明具体配置所对应的文档地址。
本专栏尽量做到图文轻松阅读便于理解,并有代码示例保障能真实跑得起来。
- 每段代码都可运行
- 每篇文章都可实践
- 每次实践都有示例
示例代码开源,置于 Github 中,演示如何对真实项目进行部署上线。
- simple-deploy: 了解最简单的部署,不涉及打包等内容。
- cra-deploy: 了解如何部署单页应用,这里以 create-react-app 为例,但实际上所讲述东西与 React 无关,仅与单页应用有关。
本专栏分为以下若干篇,其中前三篇以simple-deploy作为示例项目,而余下若干篇以cra-deploy作为示例项目。
- 更加了解前端部署方案,并可独立部署个人应用到域名
- 更加了解自己公司的前端部署方案,并发现其中的不足
- 更加了解如何使用 Docker 优化前端部署
- 更加了解如何使用对象存储云服务,并对其进行时间与空间的优化
- 更加了解如何使用 CICD 优化 Pipeline 时间,并压缩每次部署时间,敏捷开发,快速迭代
- 身在小公司,对前端部署好奇,并有权限进行部署上升级
- 身在大公司,对运维知识好奇,但无权限窥得前端部署流程
- 想进一步扩展自己的技术宽度的前端
- 想将个人应用部署到个人服务器并发布
在所有人入门编程及学习更多编程语言时,敲下的第一行代码是: 输出 hello, world。
console.log('hello, world')初学部署前端,如同学习编程一样,不能一开始就要求将生产环境的项目进行部署要从简单的开始学习。
比如本系列专栏,先部署一个最简单 HTML 如下所示,只有几行代码,无任何 CSS/Javascript 代码,我称它为hello 版前端应用。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title></title>
</head>
<body>
hello, shanyue.
</body>
</html>PS: 本文以 simple-deploy 仓库作为实践
我们将带着两个疑问,一步一步了解前端部署:
- 如何手写一个简单的静态资源服务器用以部署前端
- 为何需要 nginx、docker 等工具辅助前端部署
HTTP 是在互联网中进行数据交互的协议,你可从互联网中拿到文档、图片、音频及视频各种资源。HTTP 可视为 Web 的基石,更是前端的
而最简部署可看做,你向服务器发送一个获取 HTML 资源的请求,而服务端将响应一段 HTML 资源。我们在请求资源的过程中将发送一段请求报文(Request Message),而服务端返回的 HTML 资源为响应报文(Response Message)。
我们写一段服务器代码,在 HTTP 响应报文中设置响应体为 HTML,便完成了对极简前端的部署。
以下是对hello版前端应用的真实的 HTTP 请求及响应报文。
通过
curl -vvv localhost:3000可获得报文信息。
# 请求报文
GET / HTTP/1.1
Host: localhost:3000
# 响应报文
HTTP/1.1 200 OK
Content-Length: 133
Content-Type: text/html; charset=utf-8
Date: Fri, 31 Dec 2021 04:19:14 GMT
Connection: keep-alive
Keep-Alive: timeout=5
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title></title>
</head>
<body>
hello, shanyue.
</body>
</html>以下是对hello版前端应用的 HTTP 请求及响应报文的图文表示

好,那接下来我们写一段服务器代码,用以响应 HTML。
作为前端,以我们最为熟悉的 Node 为例,写一段最简单的前端部署服务。该服务监听本地的 3000 端口,并在响应体返回我们的hello 版前端应用。
为求简单,我们直接将hello 版前端应用以字符串的形式进行响应。
在 Node 中写服务端最重要的内置模块(builtinModule)为 node:http,通过 node: 前缀,可指明其为内置模块,被称作 Protocol Import。从而避免了 node 内置模块与第三方模块的命名冲突。
const http = require('node:http')通过 http.createServer 可对外提供 HTTP 服务,而 res.end() 可设置 HTTP 报文的响应体。以下是一段 hello 版本的 nodejs 服务。
const server = http.createServer((req, res) => res.end('hello, world'))
server.listen(3000, () => {
console.log('Listening 3000')
})我们将hello 版前端应用以字符串的方式在代码中进行维护,并通过 res.end() 设置其为响应报文的响应体。最终代码如下。
PS: 该段服务器 nodejs 代码位于 simple-deploy/server.js
const http = require('node:http')
const html = `<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title></title>
</head>
<body>
hello, shanyue.
</body>
</html>`
const server = http.createServer((req, res) => res.end(html))
server.listen(3000, () => {
console.log('Listening 3000')
})通过 node server.js 启动服务,成功运行。
$ node server.js
Listening 3000启动服务后,在浏览器端打开 localhost:3000,可查看到响应头及响应体 hello, shanyue。
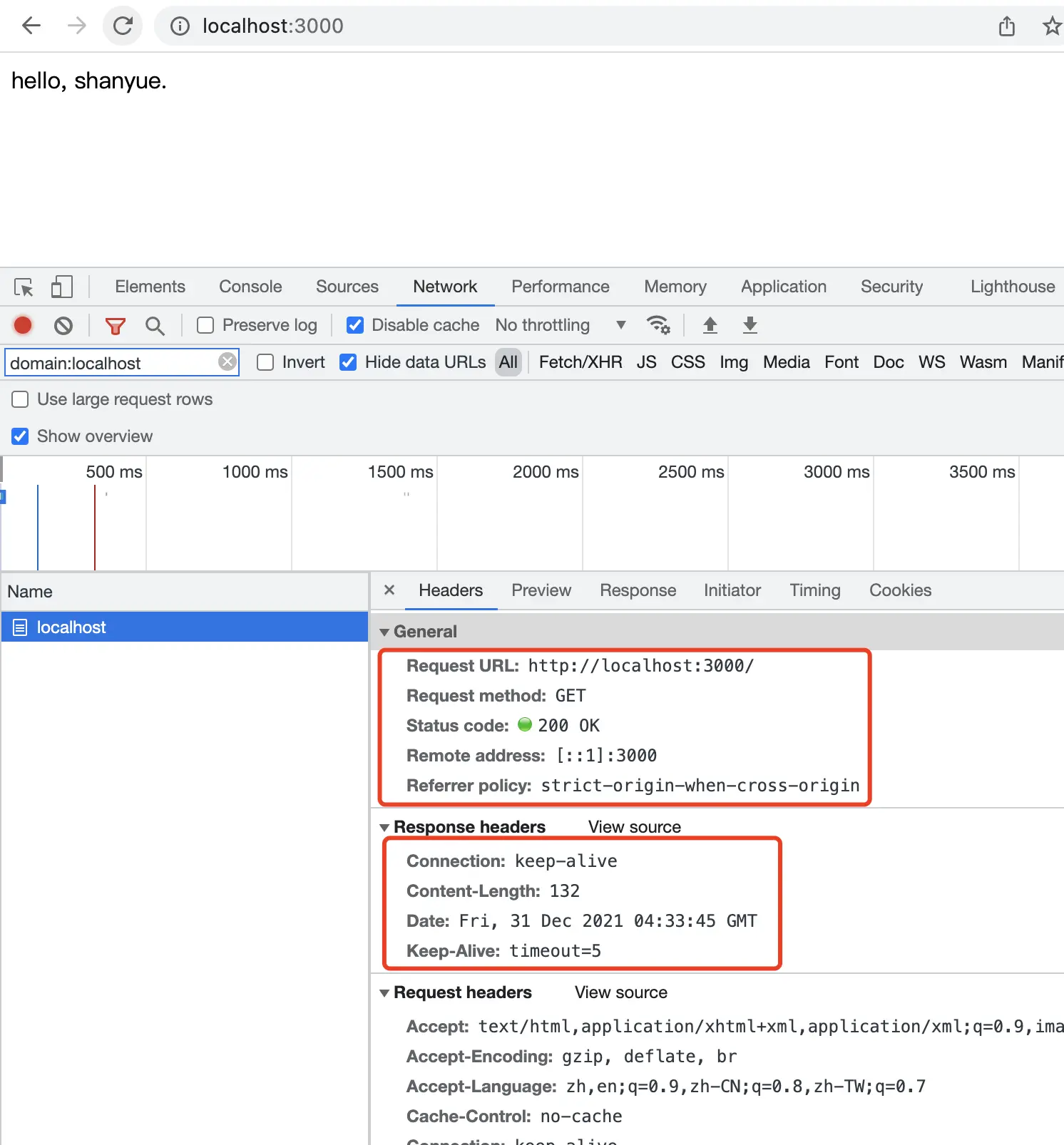
恭喜你,部署成功!
但是前端静态资源总是以文件的形式出现,我们需对代码进一步优化。
当然,部署前端作为纯静态资源,需要我们使用文件系统(file system)去读取资源并将数据返回。
在代码中,html 以前以字符串形式进行维护,现在将其置于文件系统中的 index.html 中,并通过 nodejs 中文件系统读取文件的相关 API fs.readFileSync('./index.html') 进行获取文件内容,代码如下。
// fs 为内置模块,
const fs = require('node:fs')
// 通过 fs.readFileSync 可读取文件内容
const html = fs.readFileSync('./index.html')我们将hello 版前端应用以文件系统的方式进行维护,并通过 res.end() 设置其为响应报文的响应体。最终代码如下。
PS: 该段服务器 nodejs 代码位于 simple-deploy/server-fs.js
const http = require('node:http')
const fs = require('node:fs')
// 上段代码这里是一段字符串,而这里通过读取文件获取内容
const html = fs.readFileSync('./index.html')
const server = http.createServer((req, res) => res.end(html))
server.listen(3000, () => {
console.log('Listening 3000')
})接下来启动代码,成功运行。
$ node server-fs.js
Listening 3000当然,对于前端这类纯静态资源,自己写代码无论从开发效率还是性能而言都是极差的,这也是我们为何要求助于专业工具 nginx 之类进行静态资源服务的原因所在。
比如将文件系统修改为 ReadStream 的形式进行响应将会提升该静态服务器的性能,代码如下。
const server = http.createServer((req, res) => {
// 此处需要手动处理下 Content-Length
fs.createReadStream('./index.html').pipe(res)
})因此,有诸多工具专门针对静态资源进行服务,比如 serve,比如 nginx。
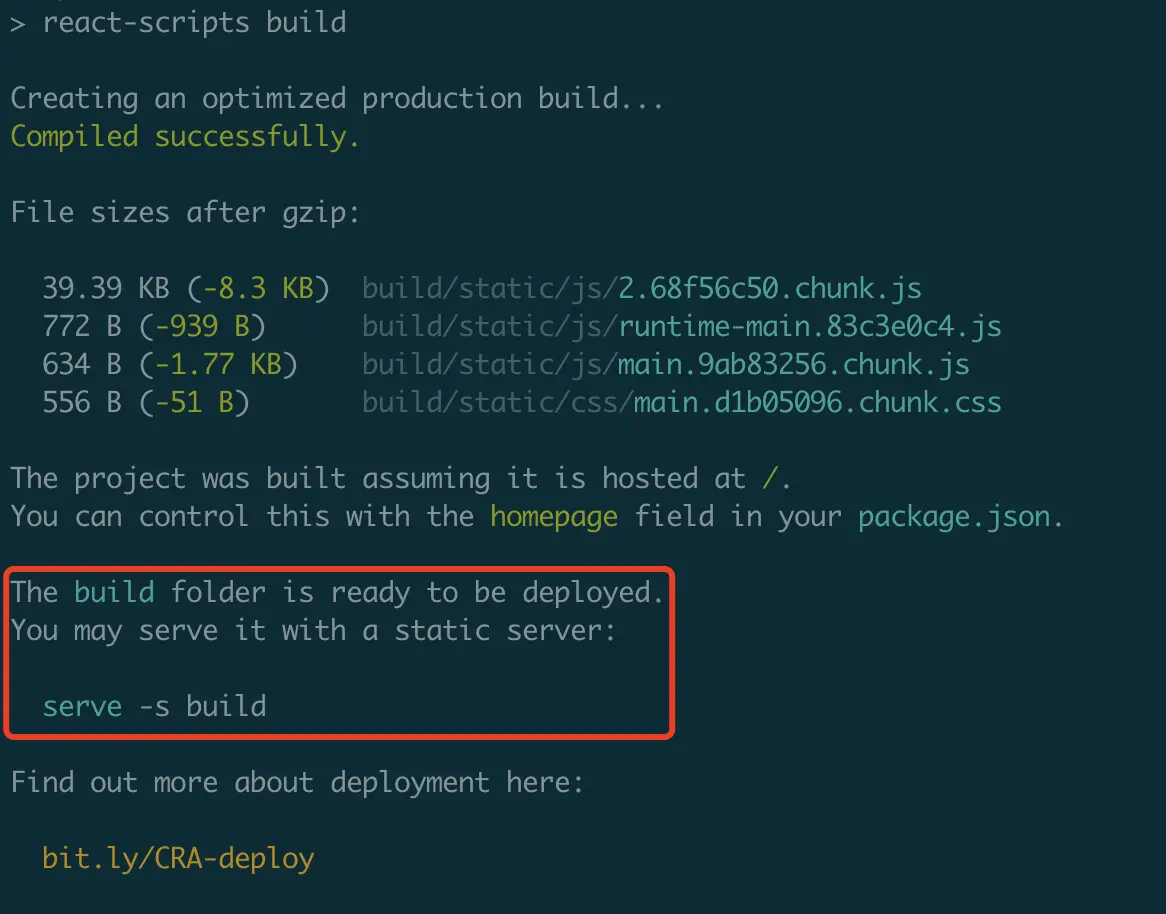
$ npx serve .serve 是 next.js 的母公司 vercel 开发的一款静态资源服务器。作为前端久负盛名的静态服务器,广泛应用在现代前端开发中,如在 create-react-app 构建成功后,它会提示使用 serve 进行部署。本地环境而言,还是 serve 要方便很多啊。
然而,Javascript 的性能毕竟有限,使用 nginx 作为静态资源服务器拥有更高的性能。
通过以上两个最简服务的成功运行,可以使我们更加深入的了解前端部署。我们再回头看,什么是部署呢,为什么说你刚才部署成功?
假设此时你有一台拥有公共 IP 地址的服务器,在这台服务器使用 nodejs 运行刚才的代码,则外网的人可通过 IP:3000 访问该页面。那这可理解为部署,使得所有人都可以访问。
假设你将该服务器作为你的工作环境,通过 npm start 运行代码并通过,所有人都可访问他,即可视为部署成功。看来你离所有人都可访问的部署只差一台拥有公共 IP 的服务器。
实际上,有极少数小微企业在生产环境中就是直接 ssh 进生产环境服务器,并通过 npm start 部署成功后,通过 IP 与端口号的方式进行访问。当然通过 IP 地址访问的项目一般也非公开项目,如果公开使用域名的话,则用 nginx 配置域名加一层反向代理。
不管怎么说,你现在已经可以通过裸机(宿主机)部署一个简单的前端应用了。
我们现在已经可以在本地跑起服务了,但是在生产环境部署为什么还需要 nginx,甚至 docker 呢?
接下来,我回应一些关于前端部署的更多疑问。
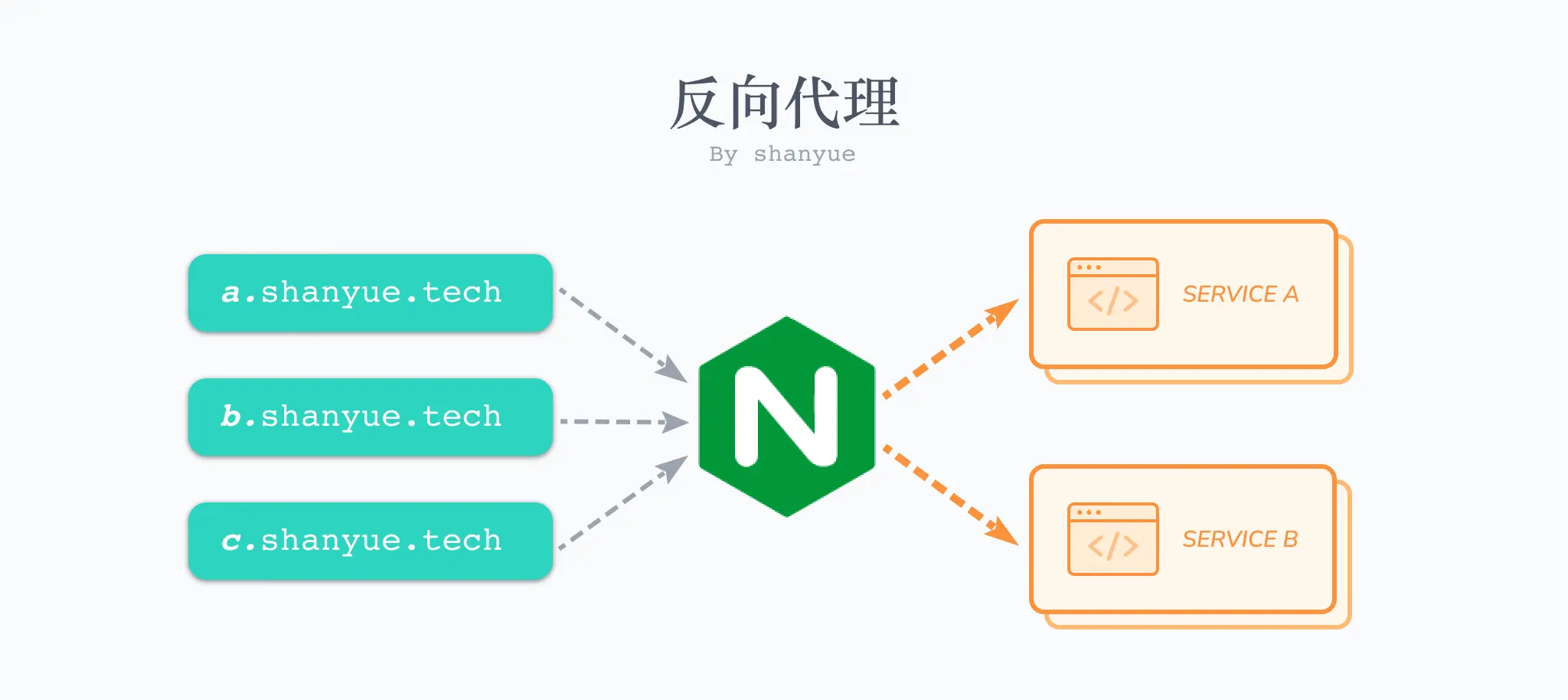
你需要管理诸多服务(比如A网站、B网站),通过 nginx 进行路由转发至不同的服务,这也就是反向代理,另外 TLS、GZIP、HTTP2 等诸多功能,也需要使用 nginx 进行配置。
当然,如果你不介意别人通过端口号去访问你的应用,不用 nginx 等反向代理器也是可以的。
关于 nginx 的学习可以查看后续章节。
可以,但是非常不推荐。npm run dev 往往需要监听文件变更并重启服务,此处需要消耗较大的内存及CPU等性能。
比如针对 Typescript 写的后端服务器,不推荐在服务器中直接使用 ts-node 而需要事先编译的理由同样如此。
当然,如果你也不介意性能问题也是可以的。
用以隔离环境。
假设你有三个后端服务,分别用 Java、Go、Node 编写,你需要在服务器分别安装三者的环境,才能运行所有语言编写的代码,这对于开发者而言非常麻烦。
假设你有三个 Node 服务,分别用 node10、node12、node14 编写,你需要在服务器分别安装三个版本 nodejs 才能运行各个版本 nodejs 编写的代码,对于开发者而言也非常麻烦。
而有了 Docker,就没有这种问题,它可单独提供某种语言的运行环境,并同时与宿主机隔离起来。
对于前端而言,此时你可以通过由自己在项目中单独维护 nginx.conf 进行一些 nginx 的配置,大大提升前端的自由性和灵活度,而无需通过运维或者后端来进行。
关于 docker 的学习可以查看后续章节。
本篇文章介绍了了一些对于前端部署的简单介绍,并使用 nodejs 写了两段代码用以提供静态服务,加深对前端部署的理解。虽然我们可自写代码对前端静态资源进行部署,但从功能性与性能而讲,都是远不如专业工具的。
在本文章,将应用在本地或者宿主机进行成功运行,但是现代流行的前端部署方案,都是使用 docker 对前端进行部署。
而在下篇文章中,我们将介绍如何使用 Docker 将仅有十几行代码的 hello 版前端应用 跑起来。
本篇文章介绍如何使用 Docker 将一个极简前端页面进行部署,而极简资源内容如下。也就是上篇文章的 hello 版前端应用。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title></title>
</head>
<body>
hello, shanyue.
</body>
</html>你可以在本地安装 docker完成本篇文章的部署实践内容,部署内容与上篇文章一致。在本篇文章之前,你需要先做一些功课:
- 在本地安装 docker/docker-compose。通过 Docker Desktop 下载 docker 后,双击安装即可。
- 了解 Dockerfile Reference。了解最常见的 FROM/ADD/CMD 即可。不需要全部过一遍,遇到没见过的指令及时查阅即可。
- 了解 Compose file Reference。不需要全部过一遍,遇到没见过的指令及时查阅即可。
- 了解 Docker Hub。在该网站,可查找适合于自己的诸多基础镜像,比如 node 与 nginx。
PS: 本项目以 simple-deploy 仓库作为实践,配置文件位于 node.Dockerfile
由上篇文章可知,我们主要是将该资源服务化,此时可借助于一个工具 serve 进行静态资源服务化。
# 将 serve 置于 dependencies 中
$ npm i
# 通过 serve 启动服务
# 可通过 npm scripts 命令封装成 start
$ npx serve .通过 npm scripts,将启动服务命令封装成 npm start
{
start: 'serve .'
}一般来说,根据以下三步,可以将脚本命令翻译成 Dockerfile。
- 选择一个基础镜像。可在 Docker Hub 中进行查找镜像。由于前端项目依赖于 Node 环境,我们选择 node:14-alpine 作为基础镜像,其中基于轻量操作系统
alpine,内置了node14/npm/yarn等运行环境。 - 将以上几个脚本命令放在 RUN 指令中。
- 启动服务命令放在 CMD 指令中。
翻译如下:
PS: 该 Dockerfile 配置位于 simple-deploy/node.Dockerfile
# 选择一个体积小的镜像 (~5MB)
FROM node:14-alpine
# 设置为工作目录,以下 RUN/CMD 命令都是在工作目录中进行执行
WORKDIR /code
# 把宿主机的代码添加到镜像中
ADD . /code
# 安装依赖
RUN yarn
EXPOSE 3000
# 启动 Node Server
CMD npm start还差两步,就可以将该最简单示例运行起来:
- 通过 Dockfile 构建镜像 (Image)
- 通过镜像运行容器 (Container)
使用 docker build 命令可基于 Dockerfile 构建镜像。
镜像构建成功后,我们可以将仓库上传至 Docker 仓库,如 Docker Hub。而对于业务项目而言,一般会上传至公司内部的私有镜像仓库,比如通过 harbor 搭建的私有镜像仓库。
# 构建一个名为 simple-app 的镜像
# -t: "name:tag" 构建镜像名称
$ docker build -t simple-app .
# git rev-parse --short HEAD: 列出当前仓库的 CommitId
# 也可将当前 Commit 作为镜像的 Tag
# 如果该前端项目使用 git tag 以及 package.json 中的 version 进行版本维护,也可将 version 作为生产环境镜像的 Tag
$ docker build -t simple-app:$(git rev-parse --short HEAD)
# 构建成功后,可用该命令列出所有的镜像
# 发现该镜像占用体积 133MB
$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
simple-app latest c1571917d2c2 17 seconds ago 133MB此时构建镜像成功,通过 docker images 可知镜像体积为 133MB。记住这个数字,以后优化镜像体积时用得到。
我们可以基于镜像运行 N 个容器,而本次启动的容器也是我们最终所要提供的静态服务。
# 根据该镜像运行容器
# 如果需要在后台运行则添加 -d 选项
# --rm: 当容器停止运行时,自动删除容器
# -p: 3000:3000,将容器中的 3000 端口映射到宿主机的 3000 端口,左侧端口为宿主机端口,右侧为容器端口
$ docker run --rm -p 3000:3000 simple-app
# 运行成功后可在另一个窗口查看所有容器
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
50784910f758 simple-app "docker-entrypoint.s…" 20 seconds ago Up 20 seconds 0.0.0.0:3000->3000/tcp, :::3000->3000/tcp wizardly_solomon此时在本地访问 http://localhost:3000 访问成功
然而,通过冗余繁琐的命令行构建镜像和容器,比如管理端口,存储、环境变量等,有其天然的劣势,不易维护。
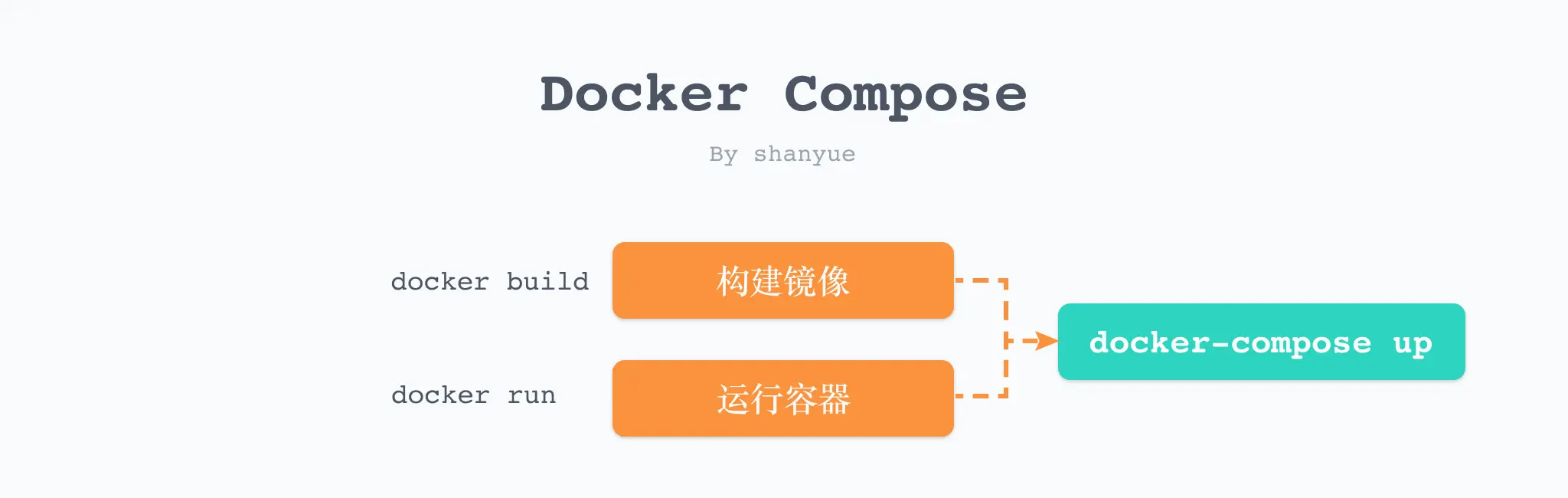
将命令行的选项翻译成配置文件,是更为简单且更容易维护的方式。比如对于 webpack 而言,基本上基于 webpack.config.js 配置文件使用。
而 docker compose 即可将 docker cli 的选项翻译成配置文件,除此之外,它还有更强大的功能。
编辑 docker-compose.yaml 配置文件如下所示。当然,由于这是一个最简项目,因此配置文件也极其简单。
PS: 该 docker compose 配置位于 simple-deploy/docker-compose.yaml
version: "3"
services:
app:
# build: 从当前路径构建镜像
build: .
ports:
- 3000:3000配置结束之后,即可通过一行命令 docker-compose up 替代以前关于构建及运行容器的所有命令。
# up: 创建并启动容器
# --build: 每次启动容器前构建镜像
$ docker-compose up --build此时在本地访问 http://localhost:3000 访问成功
此时,通过 docker/docker-compose 便部署成功了第一个前端应用。
以下,再介绍一个使用 Docker 的小技巧。
在使用 docker build 进行构建时,通过 RUN 指令可以通过打印一些关键信息进行调试,
但是,在我们进行 docker build 时,无法查看其输出结果。
此时可以通过 --progress plain 来查看其输出结果。
FROM node:14-alpine
RUN echo shanyue对以上镜像构建,可拿到 echo shanyue 的输出结果。
$ docker build --progress plain --no-cache .
4 [1/2] FROM docker.io/library/node:14-alpine
4 sha256:4641ddabdab058bf21b1550827533213f023ec21abf1ceb322993c137532f760
4 CACHED
5 [2/2] RUN echo shanyue
5 sha256:37883e3cbc36146a836ad89f3cf147723bcda1d2cf4e97655c9ed1afceb59517
5 0.237 shanyue
5 DONE 0.3s通过本篇文章,我们已经可以通过 Docker 完成对极简前端项目的部署。
但是,前端静态资源并不需要 nodejs 环境,且 nodejs 镜像较大,我们可以使用 nginx 作为基础镜像来部署前端。
正如上一篇章所言,对于仅仅提供静态资源服务的前端,实际上是不必将 nodejs 作为运行环境的。
在实际生产经验中,一般选择体积更小,性能更好,基于 nginx 的镜像。
PS: 本项目以 simple-deploy 仓库作为实践,配置文件位于 nginx.Dockerfile
在传统方式中,我们一般通过 Linux 服务器来学习如何使用 nginx 进行部署。但是,学习 nginx 的成本太高,需要额外购买一台服务器,不够方便。
也许有人会提出反对意见: 在个人电脑上也可以部署 nginx。
确实是这样,但是 nginx 一般部署在 linux 服务器,很少有人的电脑是 linux 系统,而且即便在 mac 中,其环境和 linux 环境也有很大的不同。
那我们完全可以在本地通过 docker 来简单学习下 nginx。如此,既学习了 docker,又实践了 nginx。
如果你初学 nginx,强烈建议使用 docker 进行学习。本篇文章最后会附上如何启动 nginx 镜像用以学习。
通过以下一行命令可进入 nginx 的环境当中,并且了解 nginx 的目录配置,该命令将在以下章节用到。
$ docker run -it --rm nginx:alpine sh
# 进入容器中,在容器中可通过 exit 退出容器环境
$ exit通过以下一行命令可直接访问 nginx 的默认页面
# -p 3000:80,在本地 3000 端口访问 nginx 页面
$ docker run -it --rm -p 3000:80 nginx:alpine
/docker-entrypoint.sh: /docker-entrypoint.d/ is not empty, will attempt to perform configuration
/docker-entrypoint.sh: Looking for shell scripts in /docker-entrypoint.d/
/docker-entrypoint.sh: Launching /docker-entrypoint.d/10-listen-on-ipv6-by-default.sh
10-listen-on-ipv6-by-default.sh: info: Getting the checksum of /etc/nginx/conf.d/default.conf
10-listen-on-ipv6-by-default.sh: info: Enabled listen on IPv6 in /etc/nginx/conf.d/default.conf
/docker-entrypoint.sh: Launching /docker-entrypoint.d/20-envsubst-on-templates.sh
/docker-entrypoint.sh: Launching /docker-entrypoint.d/30-tune-worker-processes.sh
/docker-entrypoint.sh: Configuration complete; ready for start up
2022/01/01 09:12:25 [notice] 1#1: using the "epoll" event method
2022/01/01 09:12:25 [notice] 1#1: nginx/1.21.4
2022/01/01 09:12:25 [notice] 1#1: built by gcc 10.3.1 20210424 (Alpine 10.3.1_git20210424)
2022/01/01 09:12:25 [notice] 1#1: OS: Linux 5.10.47-linuxkit
2022/01/01 09:12:25 [notice] 1#1: getrlimit(RLIMIT_NOFILE): 1048576:1048576
2022/01/01 09:12:25 [notice] 1#1: start worker processes
2022/01/01 09:12:25 [notice] 1#1: start worker process 34
2022/01/01 09:12:25 [notice] 1#1: start worker process 35
2022/01/01 09:12:25 [notice] 1#1: start worker process 36
2022/01/01 09:12:25 [notice] 1#1: start worker process 37
2022/01/01 09:12:25 [notice] 1#1: start worker process 38
2022/01/01 09:12:25 [notice] 1#1: start worker process 39

嗯,熟悉的界面。
以下所有命令均在基于 nginx 的容器中进行,可通过 docker run -it --rm nginx:alpine sh 命令进入容器环境中。
默认配置文件位于 /etc/nginx/conf.d/default.conf,通过 cat 可查看配置。
# 该命令在 nginx 的容器中执行
$ cat /etc/nginx/conf.d/default.conf把所有注释都删掉,默认配置为以下文件:
server {
listen 80;
server_name localhost;
location / {
root /usr/share/nginx/html;
index index.html index.htm;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root /usr/share/nginx/html;
}
}
该配置文件做了以下两个事情。
- 监听本地 80 端口
- 为
/usr/share/nginx/html目录做静态资源服务
那我们将我们的示例资源添加到镜像中的 /usr/share/nginx/html 岂不可以正确部署了?
那我们将我们的配置文件添加到镜像中的 /usr/share/nginx/html 岂不可以学习 nginx 的一些指令了。
正是如此。
写一个 Dockerfile 将我们的示例项目跑起来,仅仅需要两行代码。由于 nxinx 镜像会默认将 80 端口暴露出来,因此我们无需再暴露端口。
PS: 该 Dockerfile 配置位于 simple-deploy/nginx.Dockerfile
FROM nginx:alpine
ADD index.html /usr/share/nginx/html/继续完成 docker-compose.yaml,并创建容器。
version: "3"
services:
nginx-app:
build: .
ports:
- 4000:80$ docker-compose up --build此时,访问 https://localhost:4000 即可访问成功。在控制台查看响应头,可发现有: Server: nginx/1.21.4。
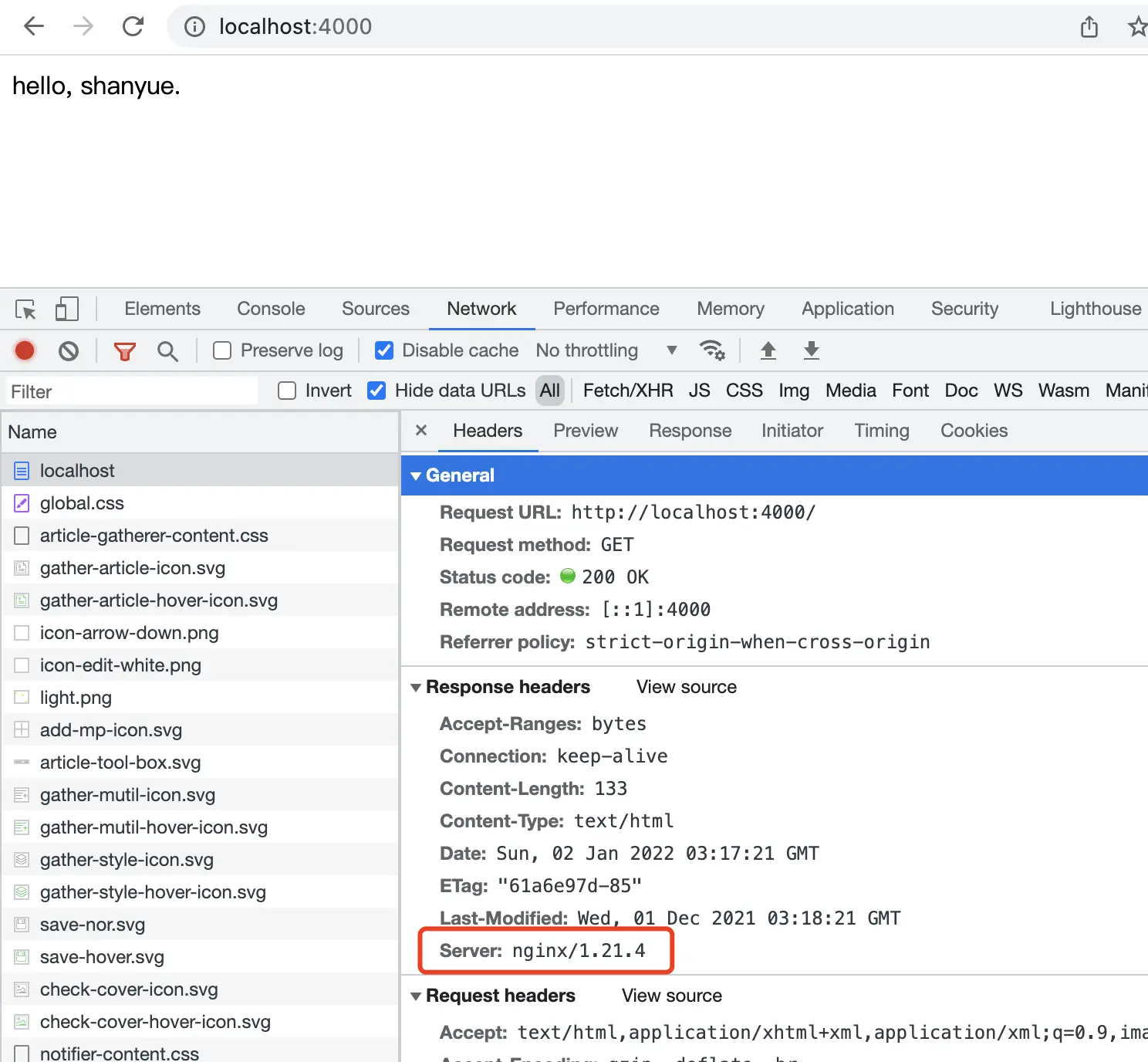
通过 docker-compose 同时将基于 node/nginx 镜像构建容器,配置文件如下。
PS: 该 docker compose 配置位于 simple-deploy/docker-composey.yaml
version: "3"
services:
node-app:
build:
context: .
dockerfile: node.Dockerfile
ports:
- 3000:3000
nginx-app:
build:
context: .
dockerfile: nginx.Dockerfile
ports:
- 4000:80通过 docker-compose images 命令,可查看该配置文件的所有镜像体积。此时发现基于 nginx 的镜像为 23.2 MB,而基于 node 的镜像为 133MB (还记得上篇文章的数据吗)。
docker-compose images
Container Repository Tag Image Id Size
-------------------------------------------------------------------------------------
simple-deploy_nginx-app_1 simple-deploy_nginx-app latest 62f362825a0a 23.2 MB
simple-deploy_node-app_1 simple-deploy_node-app latest 14054cb0f1d8 133 MB最后,推荐一种高效学习 nginx 的方法: 在本地使用 nginx 镜像并挂载 nginx 配置启动容器。
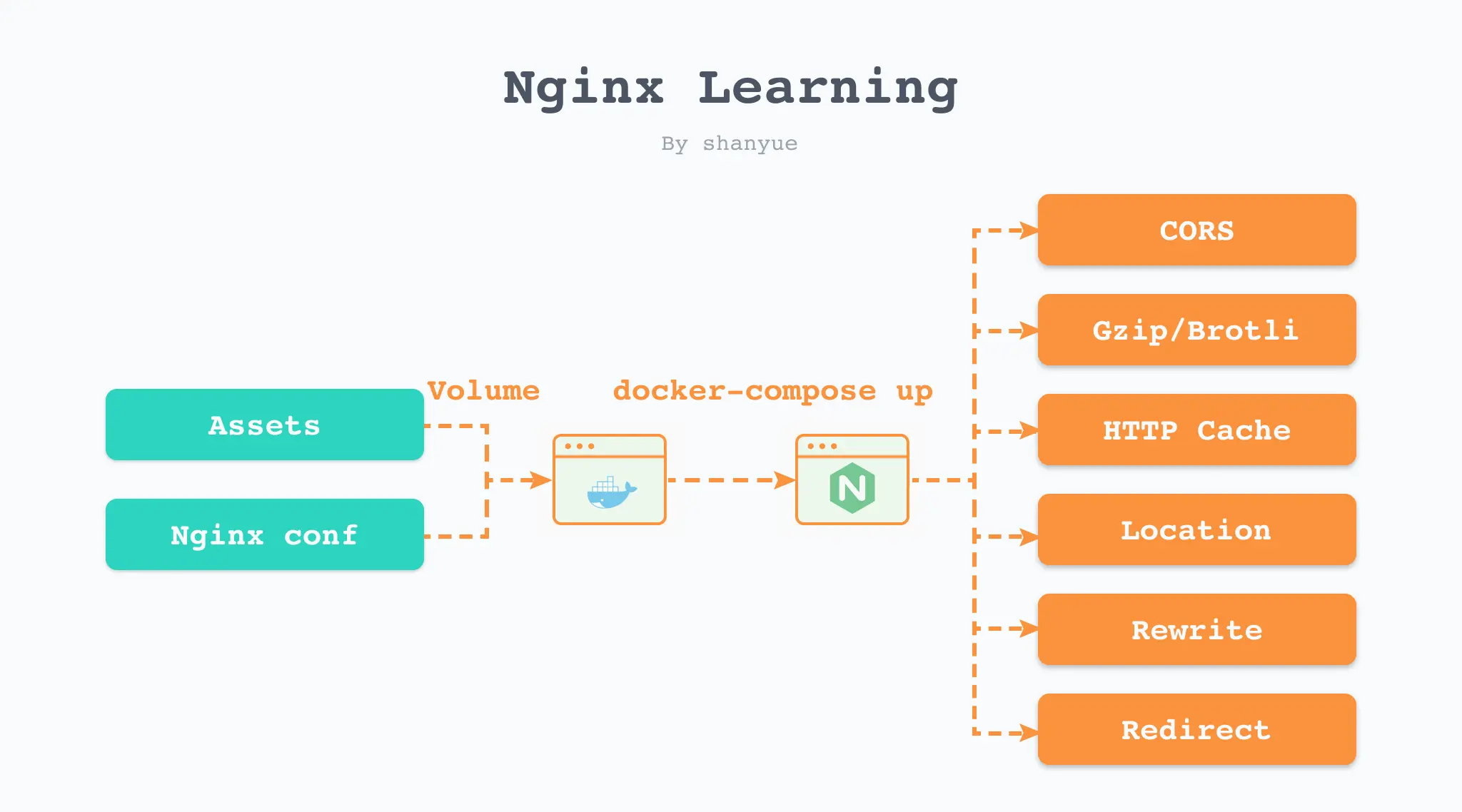
无需 Linux 环境,也无需自购个人服务器,你可以通过该方法快速掌握以下 nginx 的常用配置。
- 如何配置静态资源缓存策略
- 如何配置 CORS
- 如何配置 gzip/brotli 配置
- 如何配置路由匹配 Location
- 如何配置 Rewrite、Redirect 等
我们将注意力集中在静态资源与nginx配置两个点,在本地进行更新及维护,并通过 Volume 的方式挂载到 nginx 容器中。
配置文件如下,通过此配置可在 Docker 环境中学习 nginx 的各种指令。
PS: docker-compose 配置文件位于 simple-deploy 中,可通过它实践 nginx 的配置
version: "3"
services:
learn-nginx:
image: nginx:alpine
ports:
- 4000:80
volumes:
- nginx.conf:/etc/nginx/conf.d/default.conf
- .:/usr/share/nginx/html通过 docker-compose 启动该容器,如果需要修改配置,验证配置是否生效,可通过 docker-compose 重新启动该容器。
$ docker-compose -f learn-nginx.docker-compose.yaml up learn-nginx通过本篇文章,已基于 nginx 镜像成功部署前端,镜像体积也由 133MB 下降到 23.2MB。并且了解了如何基于 nginx 镜像来更好地学习 nginx 配置部署知识。
然而此三篇文章仅仅部署了一个 hello 版的页面。
下一篇文章以 create-react-app 为例,部署一个复杂的单页应用,与业务项目完全一致。
在部署完一个简单页面后,此时对于 Docker 与服务部署也有了简单理解。
终于可以来一个与真实项目接近带有复杂度的项目,以 CRA 部署为例:
部署一个 Creact React APP 单页应用,并通过构建缓存与多阶段构建进行优化。
实际上,即使你们技术栈是 Vue 也无所谓,本系列文章很少涉及 React 相关内容,只要你们项目是单页应用即可。
PS:本项目以 cra-deploy 仓库作为实践,配置文件位于 simple.Dockerfile。
所有的前端单页应用对于部署,最重要的就是两点:
- 静态资源如何构建:大部分项目都是
npm run build。 - 静态资源目录在哪:有的项目是
/dist,有的项目是/build。CRA 是/build目录。
以下,便是在 CRA 中获得静态资源的命令。
# 创建一个 cra 应用
$ npx create-react-app cra-deploy
# 进入 cra 目录
$ cd cra-deploy
# 进行依赖安装
$ yarn
# 对资源进行构建
$ npm run build
# ./build 目录为静态资源目录,可使用 tree 命令进行打印
$ tree build -L 2
build
├── asset-manifest.json
├── favicon.ico
├── index.html
├── logo192.png
├── logo512.png
├── manifest.json
├── robots.txt
└── static
├── css
├── js
└── media
4 directories, 7 files在本地将 CRA 应用跑起来,可通过以下步骤:
$ yarn
$ npm run build
$ npx serve -s build将命令通过以下几步翻译为一个 Dockerfile:
- 选择一个基础镜像。由于需要在容器中执行构建操作,我们需要 node 的运行环境,因此
FROM选择 node。 - 将以上几个脚本命令放在
RUN指令中。 - 启动服务放在
CMD指令中。
FROM node:14-alpine
WORKDIR /code
ADD . /code
RUN yarn && npm run build
CMD npx serve -s build
EXPOSE 3000构建完成。然而还可以针对以下两点进行优化。
- 构建镜像时间过长,优化构建时间
- 构建镜像文件过大,优化镜像体积
我们注意到,一个前端项目的耗时时间主要集中在两个命令:
- npm i (yarn)
- npm run build
在本地环境中,如果没有新的 npm package 需要下载,不需要重新 npm i。
那 Docker 中是不也可以做到这一点?
在 Dockerfile 中,对于 ADD 指令(官方文档)来讲,如果添加文件内容的 checksum 没有发生变化,则可以利用构建缓存(Best practices for writing Dockerfiles)。
而对于前端项目而言,如果 package.json/yarn.lock 文件内容没有变更,则无需再次 npm i。
将 package.json/yarn.lock 事先置于镜像中,安装依赖将可以获得缓存的优化,优化如下。
FROM node:14-alpine as builder
WORKDIR /code
# 单独分离 package.json,是为了安装依赖可最大限度利用缓存
ADD package.json yarn.lock /code/
# 此时,yarn 可以利用缓存,如果 yarn.lock 内容没有变化,则不会重新依赖安装
RUN yarn
ADD . /code
RUN npm run build
CMD npx serve -s build
EXPOSE 3000进行构建时,若可利用缓存,可看到 CACHED 标记。
$ docker-compose up --build
...
=> CACHED [builder 2/6] WORKDIR /code 0.0s
=> CACHED [builder 3/6] ADD package.json yarn.lock /code/ 0.0s
=> CACHED [builder 4/6] RUN yarn 0.0s
...我们的目标是提供静态服务(资源),完全不需要依赖于 node.js 环境进行服务化。node.js 环境在完成构建后即完成了它的使命,它的继续存在会造成极大的资源浪费。
我们可以使用多阶段构建进行优化,最终使用 nginx 进行服务化。
- 第一阶段 Node 镜像:使用 node 镜像对单页应用进行构建,生成静态资源。
- 第二阶段 Nginx 镜像:使用 nginx 镜像对单页应用的静态资源进行服务化。
该 Dockerfile 配置位于 cra-deploy/simple.Dockerfile
FROM node:14-alpine as builder
WORKDIR /code
# 单独分离 package.json,是为了安装依赖可最大限度利用缓存
ADD package.json yarn.lock /code/
RUN yarn
ADD . /code
RUN npm run build
# 选择更小体积的基础镜像
FROM nginx:alpine
COPY --from=builder code/build /usr/share/nginx/html我们将 Dockerfile 命名为 simple.Dockerfile
该 docker compose 配置位于 cra-deploy/simple.Dockerfile
version: "3"
services:
simple:
build:
context: .
dockerfile: simple.Dockerfile
ports:
- 4000:80使用 docker-compose up --build simple 启动容器。
访问 http://localhost:4000 页面成功。
本篇文章,通过构建缓存与多阶段构建优化了体积和时间,然而还有两个个小问题需要解决:
- 单页应用的路由配置
- 单页应用的缓存策略
在上篇文章中,我们介绍了在 Docker 中使用构建缓存与多阶段构建进行缓存优化。
但是在部署单页应用时,仍然有一个问题,那就是客户端路由。
在这篇文章中,将会由 react-router-dom 实现一个简单的单页路由,并通过 Docker 进行部署。
PS: 本项目以 cra-deploy 仓库作为实践,配置文件位于 router.Dockerfile
使用 react-dom 为单页应用添加一个路由,由于路由不是本专栏的核心内容,省略掉路由的用法,最终代码如下。
import logo from './logo.svg';
import './App.css';
import { Routes, Route, Link } from 'react-router-dom';
function Home() {
return (
<div>
<header className="App-header">
<img src={logo} className="App-logo" alt="logo" />
<h1>当前在 Home 页面</h1>
<Link to="/about" className="App-link">About</Link>
</header>
</div>
)
}
function About() {
return (
<div>
<header className="App-header">
<img src={logo} className="App-logo" alt="logo" />
<h1>当前在 About 页面</h1>
<Link to="/" className="App-link">Home</Link>
</header>
</div>
)
}
function App() {
return (
<div>
<Routes>
<Route index element={<Home />} />
<Route path="about" element={<About />} />
</Routes>
</div>
);
}
export default App;此时拥有两个路由:
/,首页/about,关于页面
根据上篇文章的 docker-compose 配置文件重新部署页面。
$ docker-compose up --build simple此时访问 https://localhost:4000/about,将会显示 404。
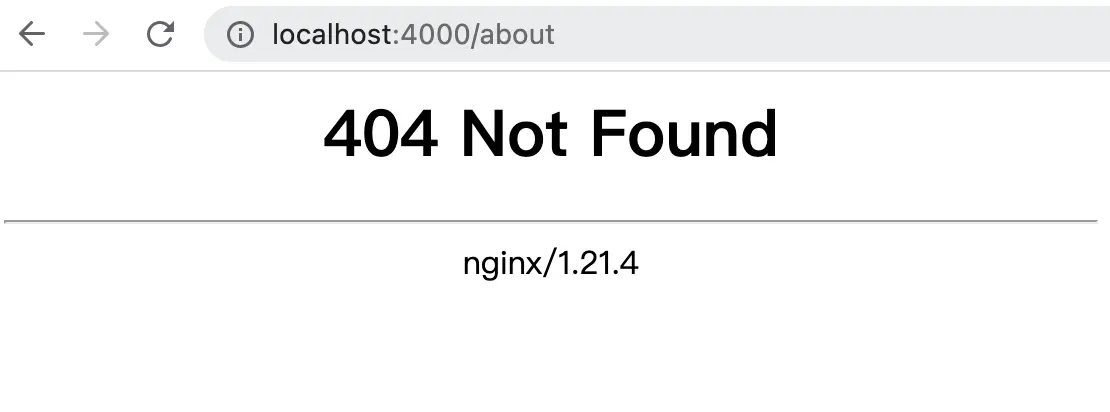
其实道理很简单:在静态资源中并没有 about 或者 about.html 该资源,因此返回 404 Not Found。而在单页应用中,/about 是由前端通过 history API 进行控制。
解决方法也很简单:在服务端将所有页面路由均指向 index.html,而单页应用再通过 history API 控制当前路由显示哪个页面。
在 nginx 中,可通过 try_files 指令将所有页面导向 index.html。
location / {
# 如果资源不存在,则回退到 index.html
try_files $uri $uri/ /index.html;
}
此时,可解决服务器端路由问题。
在 CRA 应用中,./build/static 目录均由 webpack 构建产生,资源路径将会带有 hash 值。
$ tree ./build/static
./build/static
├── css
│ ├── main.073c9b0a.css
│ └── main.073c9b0a.css.map
├── js
│ ├── 787.cf6a8955.chunk.js
│ ├── 787.cf6a8955.chunk.js.map
│ ├── main.a3facdf8.js
│ ├── main.a3facdf8.js.LICENSE.txt
│ └── main.a3facdf8.js.map
└── media
└── logo.6ce24c58023cc2f8fd88fe9d219db6c6.svg
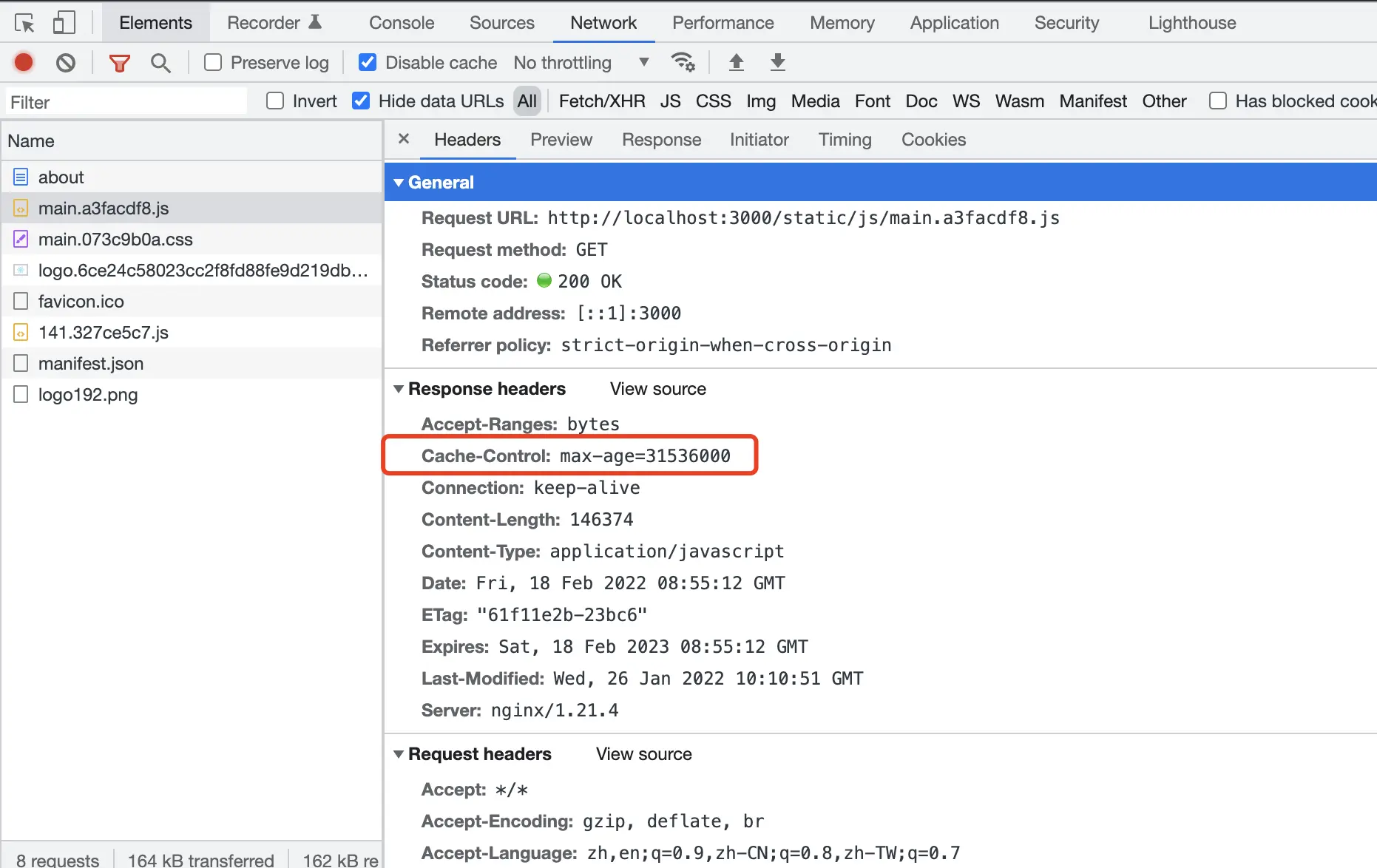
3 directories, 8 files此时可通过 expires 对它们配置一年的长期缓存,它实际上是配置了 Cache-Control: max-age=31536000 的响应头。
那为什么带有 hash 的资源可设置长期缓存呢: **资源的内容发生变更,他将会生成全新的 hash 值,即全新的资源路径。**而旧有资源将不会进行访问。
location /static {
expires 1y;
}
总结缓存策略如下:
- 带有 hash 的资源一年长期缓存
- 非带 hash 的资源,需要配置 Cache-Control: no-cache,避免浏览器默认为强缓存
nginx.conf 文件需要维护在项目当中,经过路由问题的解决与缓存配置外,最终配置如下:
该 nginx 配置位于 cra-deploy/nginx.conf
server {
listen 80;
server_name localhost;
root /usr/share/nginx/html;
index index.html index.htm;
location / {
# 解决单页应用服务端路由的问题
try_files $uri $uri/ /index.html;
# 非带 hash 的资源,需要配置 Cache-Control: no-cache,避免浏览器默认为强缓存
expires -1;
}
location /static {
# 带 hash 的资源,需要配置长期缓存
expires 1y;
}
}
此时,在 Docker 部署过程中,需要将 nginx.conf 置于镜像中。
修改 router.Dockerfile 配置文件如下:
PS: 该 Dockerfile 配置位于 cra-deploy/router.Dockerfile
FROM node:14-alpine as builder
WORKDIR /code
# 单独分离 package.json,是为了 yarn 可最大限度利用缓存
ADD package.json yarn.lock /code/
RUN yarn
# 单独分离 public/src,是为了避免 ADD . /code 时,因为 Readme/nginx.conf 的更改避免缓存生效
# 也是为了 npm run build 可最大限度利用缓存
ADD public /code/public
ADD src /code/src
RUN npm run build
# 选择更小体积的基础镜像
FROM nginx:alpine
ADD nginx.conf /etc/nginx/conf.d/default.conf
COPY --from=builder code/build /usr/share/nginx/htmlPS: 该 docker compose 配置位于 cra-deploy/router.Dockerfile
version: "3"
services:
route:
build:
context: .
dockerfile: router.Dockerfile
ports:
- 3000:80使用 docker-compose up --build route 启动容器。
- 访问
http://localhost:3000页面成功。 - 访问
http://localhost:3000/about页面成功。
访问 https://localhost:3000 页面,打开浏览器控制台网络面板。
此时对于带有 hash 资源, Cache-Control: max-age=31536000 响应头已配置。
此时对于非带 hash 资源, Cache-Control: no-cache 响应头已配置。
在前端部署流程中,一些小小的配置能大幅度提升性能,列举一二,感兴趣的同学可进一步探索。
构建资源的优化:
- 使用 terser 压缩 Javascript 资源
- 使用 cssnano 压缩 CSS 资源
- 使用 sharp/CDN 压缩 Image 资源或转化为 Webp
- 使用 webpack 将小图片转化为 DataURI
- 使用 webpack 进行更精细的分包,避免一行代码的改动使大量文件的缓存失效
网络性能的优化:
- HTTP2,HTTP2多路复用、头部压缩功能提升网络性能
- OSCP Stapling,减少浏览器端的 OSCP 查询(可验证证书合法性)
- TLS v1.3,TLS 握手时间从 2RTT 优化到了 1RTT,并可 0-RTT Resumption
- HSTS,无需301跳转,直接使用 HTTPS,但更重要的是安全性能
- Brotli,相对 gzip 更高性能的压缩算法
其实,从这里开始,前端部署与传统前端部署已逐渐显现了天壤之别。
传统的前端部署由运维进行主导,每次上线都要邮件通知运维该项目前端的上线步骤,由运维完成,前端对部署的自由度较小。
如 gzip/brotli 压缩的开启、Cache-Control 等响应头的控制、不同路由的缓存策略,均需告知运维完成,且很难有版本管理。
而前端关于部署自由度的延长,体现在以下两个方面:
- 通过 Docker 对前端进行容器化,再也无需邮件通知运维上线步骤
- 通过 Docker 与 nginx 配置文件对前端进行 nginx 的配置,一些细小琐碎但与项目强相关的配置无需运维介入
此时,关于如何将前端在 Docker 中进行部署的篇章已经结束,而在工作实践中,往往会将静态资源置于 CDN 中。
那又该如何处理呢?
本篇文章需要 OSS(Object Storage) 云服务服务,一个月几毛钱,可自行购买。我们可以把静态资源上传至 OSS,并对 OSS 提供 CDN 服务。
本篇文章还是以项目 cra-deploy 示例,并将静态资源上传至 OSS 处理。
假设将带有 hash 值的静态资源推至 CDN 中,此时静态资源的地址为: https://cdn.shanyue.tech。而它即是我们将要在 webpack 中配置的 config.output.publicPath。
module.exports = {
output: {
publicPath: 'https://cdn.shanyue.tech'
}
}在 create-react-app 中,对 webpack config 做了进一步封装,阅读其源码,了解其 webpack.config.js 配置。
const publicUrlOrPath = getPublicUrlOrPath(
process.env.NODE_ENV === 'development',
require(resolveApp('package.json')).homepage,
process.env.PUBLIC_URL
)
const config = {
output: {
// webpack uses `publicPath` to determine where the app is being served from.
// It requires a trailing slash, or the file assets will get an incorrect path.
// We inferred the "public path" (such as / or /my-project) from homepage.
publicPath: paths.publicUrlOrPath,
},
}可知在 cra 中通过设置环境变量 PUBLIC_URL 即可配置 CDN 地址。
export PUBLIC_URL=https://cdn.shanyue.tech- aliyun_access_key_id
- aliyun_access_key_secret
在将静态资源上传至云服务时,我们需要 AccessKey/AccessSecret 获得权限用以上传。可参考文档创建AccessKey
Bucket 是 OSS 中的存储空间。对于生产环境,可对每一个项目创建单独的 Bucket,而在测试环境,多个项目可共用 Bucket。
在创建 Bucket 时,需要注意以下事项。
- 权限设置为公共读 (Public Read)
- 跨域配置 CORS (manifest.json 需要配置 cors)
- 记住 Endpoint,比如
oss-cn-beijing.aliyuncs.com。将会在配置 PUBLIC_URL 中使用到
最终的 PUBLIC_URL 为 $Bucket.$Endpoint,比如本篇文章示例项目的 PUBLIC_URL 为 shanyue-cra.oss-cn-beijing.aliyuncs.com。
但是,你也可以配置 CNAME 记录并使用自己的域名。
在以下命令行及代码示例中,我们将 cra-deploy 项目的静态资源全部上传至 shanyue-cra 该 Bucket 中。
在 OSS 上创建一个 Bucket,通过官方工具 ossutil 将静态资源上传至 OSS。
在进行资源上传之前,需要通过 ossutil config 进行权限配置。
$ ossutil config -i $ACCESS_KEY_ID -k $ACCESS_KEY_SECRET -e $ENDPOINT命令 ossutil cp 可将本地资源上传至 OSS。而缓存策略与前篇文章保持一致:
- 带有 hash 的资源一年长期缓存
- 非带 hash 的资源,需要配置 Cache-Control: no-cache,避免浏览器默认为强缓存
# 将资源上传到 OSS Bucket
$ ossutil cp -rf --meta Cache-Control:no-cache build oss://shanyue-cra/
# 将带有 hash 资源上传到 OSS Bucket,并且配置长期缓存
# 注意此时 build/static 上传了两遍 (可通过脚本进行优化)
$ ossutil cp -rf --meta Cache-Control:max-age=31536000 build/static oss://shanyue-cra/static为求方便,可将两条命令维护到 npm scripts 中
{
scripts: {
'oss:cli': 'ossutil cp -rf --meta Cache-Control:no-cache build oss://shanyue-cra/ && ossutil cp -rf --meta Cache-Control:max-age=31536000 build/static oss://shanyue-cra/static'
}
}另有一种方法,通过官方提供的 SDK: ali-oss 可对资源进行精准控制:
- 对每一条资源进行精准控制
- 仅仅上传变更的文件
- 使用 p-queue 控制 N 个资源同时上传
{
scripts: {
'oss:script': 'node ./scripts/uploadOSS.js'
}
}脚本略过不提。
PS: 上传 OSS 的配置文件位于 scripts/uploadOSS.js 中,可通过它使用脚本控制静态资源上传。
PS: 该 Dockerfile 配置位于 cra-deploy/oss.Dockerfile
由于 Dockerfile 同代码一起进行管理,我们不能将敏感信息写入 Dockerfile。
故这里使用 ARG 作为变量传入。而 ARG 可通过 docker build --build-arg 抑或 docker-compose 进行传入。
FROM node:14-alpine as builder
ARG ACCESS_KEY_ID
ARG ACCESS_KEY_SECRET
ARG ENDPOINT
ENV PUBLIC_URL https://shanyue-cra.oss-cn-beijing.aliyuncs.com/
WORKDIR /code
# 为了更好的缓存,把它放在前边
RUN wget http://gosspublic.alicdn.com/ossutil/1.7.7/ossutil64 -O /usr/local/bin/ossutil \
&& chmod 755 /usr/local/bin/ossutil \
&& ossutil config -i $ACCESS_KEY_ID -k $ACCESS_KEY_SECRET -e $ENDPOINT
# 单独分离 package.json,是为了安装依赖可最大限度利用缓存
ADD package.json yarn.lock /code/
RUN yarn
ADD . /code
RUN npm run build && npm run oss:cli
# 选择更小体积的基础镜像
FROM nginx:alpine
ADD nginx.conf /etc/nginx/conf.d/default.conf
COPY --from=builder code/build /usr/share/nginx/htmlPS: 该 compose 配置位于 cra-deploy/docker-compose.yaml
在 docker-compose 配置文件中,通过 build.args 可对 Dockerfile 进行传参。
而 docker-compose.yaml 同样不允许出现敏感数据,此时通过环境变量进行传参。在 build.args 中,默认从同名环境变量中取值。
PS: 在本地可通过环境变量传值,那在 CI 中呢,在生产环境中呢?待以后 CI 篇进行揭晓。
version: "3"
services:
oss:
build:
context: .
dockerfile: oss.Dockerfile
args:
# 此处默认从环境变量中传参
- ACCESS_KEY_ID
- ACCESS_KEY_SECRET
- ENDPOINT=oss-cn-beijing.aliyuncs.com
ports:
- 8000:80RUN 起来,成功!
$ docker-compose up --build oss经过几篇文章的持续优化,当我们使用对象存储服务之后,实际上在我们的镜像中仅仅只剩下几个文件。
index.htmlrobots.txtfavicon.ico- 等
那我们可以再进一步,将所有静态资源都置于公共服务中吗?
可以,实际上 OSS/COS (对象存储服务) 也可以如此配置,但是较为繁琐,如 Rewrite、Redirect 规则等配置。
如果,你既没有个人服务器,也没有属于个人的域名,可将自己所做的前端网站置于以下免费的托管服务平台。
- Vercel
- Github Pages
- Netlify
通过本篇文章,我们已将静态资源部署至 CDN(近乎等同于 CDN),与大部分公司的生产环境一致。
但在测试环境中最好还是建议无需上传至 OSS,毕竟上传至 OSS 需要额外的时间,且对于测试环境无太大意义。
但实际上 OSS 在上传及存储阶段,还可以进一步优化,请看下一篇文章。
当公司内将一个静态资源部署云服务的前端项目持续跑了 N 年后,部署了上万次后,可能出现几种情况。
- 时间过长。如构建后的资源全部上传到对象存储,然而有些资源内容并未发生变更,将会导致过多的上传时间。
- 冗余资源。前端每改一行代码,便会生成一个新的资源,而旧资源将会在 OSS 不断堆积,占用额外体积。 从而导致更多的云服务费用。
在前端构建过程中存在无处不在的缓存
- 当源文件内容未发生更改时,将不会对 Module 重新使用 Loader 等进行重新编译。这是利用了 webpack5 的持久化缓存。
- 当源文件内容未发生更改时,构建生成资源的 hash 将不会发生变更。此举有利于 HTTP 的 Long Term Cache。
那对比生成资源的哈希,如未发生变更,则不向 OSS 进行上传操作。这一步将会提升静态资源上传时间,进而提升每一次前端部署的时间。
对于构建后含有 hash 的资源,对比文件名即可了解资源是否发生变更。
PS: 该脚本路径位于 cra-deploy/scripts/uploadOSS.mjs
伪代码如下:
// 判断文件 (Object)是否在 OSS 中存在
// 对于带有 hash 的文件而言,如果存在该文件名,则在 OSS 中存在
// 对于不带有 hash 的文件而言,可对该 Object 设置一个 X-OSS-META-MTIME 或者 X-OSS-META-HASH 每次对比来判断该文件是否存在更改,本函数跳过
// 如果再严谨点,将会继续对比 header 之类
async function isExistObject (objectName) {
try {
await client.head(objectName)
return true
} catch (e) {
return false
}
}而对于是否带有 hash 值,设置不同的关于缓存的响应头。
// objectName: static/css/main.079c3a.css
// withHash: 该文件名是否携带 hash 值
async function uploadFile (objectName, withHash = false) {
const file = resolve('./build', objectName)
// 如果路径名称不带有 hash 值,则直接判断在 OSS 中不存在该文件名,需要重新上传
const exist = withHash ? await isExistObject(objectName) : false
if (!exist) {
const cacheControl = withHash ? 'max-age=31536000' : 'no-cache'
// 为了加速传输速度,这里使用 stream
await client.putStream(objectName, createReadStream(file), {
headers: {
'Cache-Control': cacheControl
}
})
console.log(`Done: ${objectName}`)
} else {
// 如果该文件在 OSS 已存在,则跳过该文件 (Object)
console.log(`Skip: ${objectName}`)
}
}另外,我们可以通过 p-queue 控制资源上传的并发数量。
const queue = new PQueue({ concurrency: 10 })
for await (const entry of readdirp('./build', { depth: 0, type: 'files' })) {
queue.add(() => uploadFile(entry.path))
}Rclone,rsync for cloud storage,是使用 Go 语言编写的一款高性能云文件同步的命令行工具,可理解为云存储版本的 rsync,或者更高级的 ossutil。
它支持以下功能:
- 按需复制,每次仅仅复制更改的文件
- 断点续传
- 压缩传输
# 将资源上传到 OSS Bucket
$ rclone copy --exclude 'static/**' --header 'Cache-Control: no-cache' build alioss:/shanyue-cra --progress
# 将带有 hash 资源上传到 OSS Bucket,并且配置长期缓存
$ rclone copy --header 'Cache-Control: max-age=31536000' build/static alioss:/shanyue-cra/static --progress为求方便,可将两条命令维护到 npm scripts 中
{
"scripts": {
"oss:rclone": "rclone copy --exclude 'static/**' --header 'Cache-Control: no-cache' build alioss:/shanyue-cra --progress && rclone copy --header 'Cache-Control: max-age=31536000' build/static alioss:/shanyue-cra/static --progress",
}
}在生产环境中,OSS 只需保留最后一次线上环境所依赖的资源。(多版本共存情况下除外)
此时可根据 OSS 中所有资源与最后一次构建生成的资源一一对比文件名,进行删除。
// 列举出来最新被使用到的文件: 即当前目录
// 列举出来OSS上的所有文件,遍历判断该文件是否在当前目录,如果不在,则删除
async function main() {
const files = await getCurrentFiles()
const objects = await getAllObjects()
for (const object of objects) {
// 如果当前目录中不存在该文件,则该文件可以被删除
if (!files.includes(object.name)) {
await client.delete(object.name)
console.log(`Delete: ${object.name}`)
}
}
}通过 npm scripts 进行简化:
{
"scripts": {
"oss:rclone": "rclone copy --exclude 'static/**' --header 'Cache-Control: no-cache' build alioss:/shanyue-cra --progress && rclone copy --header 'Cache-Control: max-age=31536000' build/static alioss:/shanyue-cra/static --progress",
}
}而对于清除任务可通过定时任务周期性删除 OSS 上的冗余资源,比如通过 CRON 配置每天凌晨两点进行删除。由于该脚本定时完成,所以无需考虑性能问题,故不适用 p-queue 进行并发控制
而有一种特殊情况,可能不适合此种方法。生产环境发布了多个版本的前端,如 AB 测试,toB 面向不同大客户的差异化开发与部署,此时可针对不同版本对应不同的 output.path 来解决。
output.path可通过环境变量注入 webpack 选项,而环境变量可通过以下命令置入。(或置入 .env)
export COMMIT_SHA=$(git rev-parse --short HEAD)
export COMMIT_REF_NAME=$(git branch --show-current)
export COMMIT_REF_NAME=$(git rev-parse --abbrev-ref HEAD)以上两个环境变量非常重要,将会在以后篇章经常用到。
通过对 OSS 进行优化后,OSS 篇基本完结。
接下来,如何将部署自动化完成呢,如何将应用使得可通过域名访问呢?
通过该专栏的前序文章,我们已经很熟练地在服务器中通过 Docker 进行前端应用的部署。
但如何使它可通过域名对外提供访问呢?
假设你在服务器中,现在维护了 N 个前端应用,起了 N 个容器。但好像,除了使用容器启动服务外,和传统方式并无二致,以前管理进程,现在管理容器。
对,还差一个服务的编排功能。
比如
- 我使用 docker 新跑了一个服务,如何让它被其它服务所感知或直接被互联网所访问呢?
- 我使用 docker 跑了 N 个服务,我怎么了解所有的服务的健康状态及路由呢?
这就需要一个基于服务发现的网关建设: Traefik
traefik 是一个现代化的反向代理与负载均衡器,它可以很容易地同 Docker 集成在一起使用。每当 Docker 容器部署成功,便可以自动在网络上进行访问。
目前 traefik 在 Github 拥有 36K 星星,可以放心使用。
配置一下 docker compose 可启动 traefik 服务。
version: '3'
services:
traefik:
image: traefik:v2.5
command: --api.insecure=true --providers.docker
ports:
- "80:80"
- "8080:8080"
volumes:
- /var/run/docker.sock:/var/run/docker.sock使用 docker-compose up 启动 traefik 后,此时会默认新建一个 traefik_network 的网络。这个网络名称很重要,要记住。

启动一个 whoami 的简易版 Web 服务,它将会在页面上打印出一些头部信息。
version: '3'
services:
# 改镜像会暴露出自身的 `header` 信息
whoami:
image: containous/whoami
labels:
# 设置Host 为 whoami.docker.localhost 进行域名访问
- "traefik.http.routers.whoami.rule=Host(`whoami.shanyue.local`)"
# 使用已存在的 traefik 的 network
networks:
default:
external:
name: traefik_default那 whoami 服务做了什么事情呢
- 暴露了一个
http服务,主要提供一些header以及ip信息 - 配置了容器的
labels,设置该服务的Host为whoami.shanyue.local,给traefik提供标记
此时我们可以通过主机名 whoami.shanyue.locol 来访问 whoami 服务,我们使用 curl 做测试
PS:
whoami.shanyue.locol可以是任意域名,此处仅做测试。如果你拥有个人域名,替换成个人域名后,可在任意互联网处进行访问。
# 通过 -H 来指定 Host
$ curl -H Host:whoami.shanyue.local http://127.0.0.1
Hostname: f4b29ed568da
IP: 127.0.0.1
IP: 172.20.0.3
RemoteAddr: 172.20.0.2:42356
GET / HTTP/1.1
Host: whoami.shanyue.local
User-Agent: curl/7.29.0
Accept: */*
Accept-Encoding: gzip
X-Forwarded-For: 172.20.0.1
X-Forwarded-Host: whoami.shanyue.local
X-Forwarded-Port: 80
X-Forwarded-Proto: http
X-Forwarded-Server: 9f108517e2ca
X-Real-Ip: 172.20.0.1服务正常访问。
此时如果把 Host 配置为自己的域名,则已经可以使用自己的域名来提供服务。
由于本系列文章重点在于部署,因此对于 Traefik 以下两点将不再过多研究
- 如何配置 https
- 如何配置 Dashboard
使用以下配置文件,直接配置生效。
终极配置文件已经配置好了 LTS、Access Log 等,但是细节就不讲了,直接上配置。
编辑配置文件 traefik.toml,内容如下。
[global]
checkNewVersion = true
sendAnonymousUsage = true
################################################################
# Entrypoints configuration
################################################################
# Entrypoints definition
#
# Optional
# Default:
[entryPoints]
[entryPoints.web]
address = ":80"
[entryPoints.web.http]
[entryPoints.web.http.redirections]
[entryPoints.web.http.redirections.entryPoint]
to = "websecure"
scheme = "https"
[entryPoints.websecure]
address = ":443"
################################################################
# Traefik logs configuration
################################################################
# Traefik logs
# Enabled by default and log to stdout
#
# Optional
#
[log]
filePath = "log/traefik.log"
format = "json"
################################################################
# Access logs configuration
################################################################
# Enable access logs
# By default it will write to stdout and produce logs in the textual
# Common Log Format (CLF), extended with additional fields.
#
# Optional
#
[accessLog]
# Sets the file path for the access log. If not specified, stdout will be used.
# Intermediate directories are created if necessary.
#
# Optional
# Default: os.Stdout
#
filePath = "log/traefik-access.json"
# Format is either "json" or "common".
#
# Optional
# Default: "common"
#
format = "json"
[accessLog.fields]
defaultMode = "keep"
[accessLog.fields.headers]
defaultMode = "keep"
################################################################
# API and dashboard configuration
################################################################
# Enable API and dashboard
[api]
# Enable the API in insecure mode
#
# Optional
# Default: true
#
insecure = true
# Enabled Dashboard
#
# Optional
# Default: true
#
dashboard = true
################################################################
# Ping configuration
################################################################
# Enable ping
[ping]
# Name of the related entry point
#
# Optional
# Default: "traefik"
#
# entryPoint = "traefik"
################################################################
# Docker configuration backend
################################################################
# Enable Docker configuration backend
[providers.docker]
# Docker server endpoint. Can be a tcp or a unix socket endpoint.
#
# Required
# Default: "unix:///var/run/docker.sock"
#
# endpoint = "tcp://10.10.10.10:2375"
# Default host rule.
#
# Optional
# Default: "Host(`{{ normalize .Name }}`)"
#
# Expose containers by default in traefik
#
# Optional
# Default: true
#
# exposedByDefault = false
[metrics.prometheus]
buckets = [0.1,0.3,1.2,5.0]
entryPoint = "metrics"
[certificatesResolvers.le.acme]
email = "[email protected]"
storage = "acme.json"
[certificatesResolvers.le.acme.tlsChallenge]
[certificatesResolvers.le.acme.httpChallenge]
entryPoint = "web"启动容器时,将 traefik.toml 挂载到容器当中。
version: '3'
services:
reverse-proxy:
image: traefik:v2.5
ports:
- "80:80"
- "443:443"
- "8080:8080"
volumes:
- ./traefik.toml:/etc/traefik/traefik.toml
- ./acme.json:/acme.json
- ./log:/log
- /var/run/docker.sock:/var/run/docker.sock
container_name: traefik
env_file: .env
labels:
- "traefik.http.routers.api.rule=Host(`traefik.shanyue.local`)"
- "traefik.http.routers.api.service=api@internal"最终,根据以下命令启动容器。
$ touch acme.json
$ chmod 600 acme.json
$ touch .env
$ docker-compose up此时,一个反向代理的 Traefix 已经完美配置。当部署一个前端应用后,将会自动实现以下功能:
- TLS。部署域名将可直接使用 HTTPS 进行访问。
- AccessLog。会自动收集每个服务的请求日志。
- 自动收集每个服务的健康状态。
在上一篇文章,我们已成功搭建了 traefik 网关。
回到我们的 create-react-app 部署示例,我们如何将此项目可使他们在互联网通过域名进行访问?
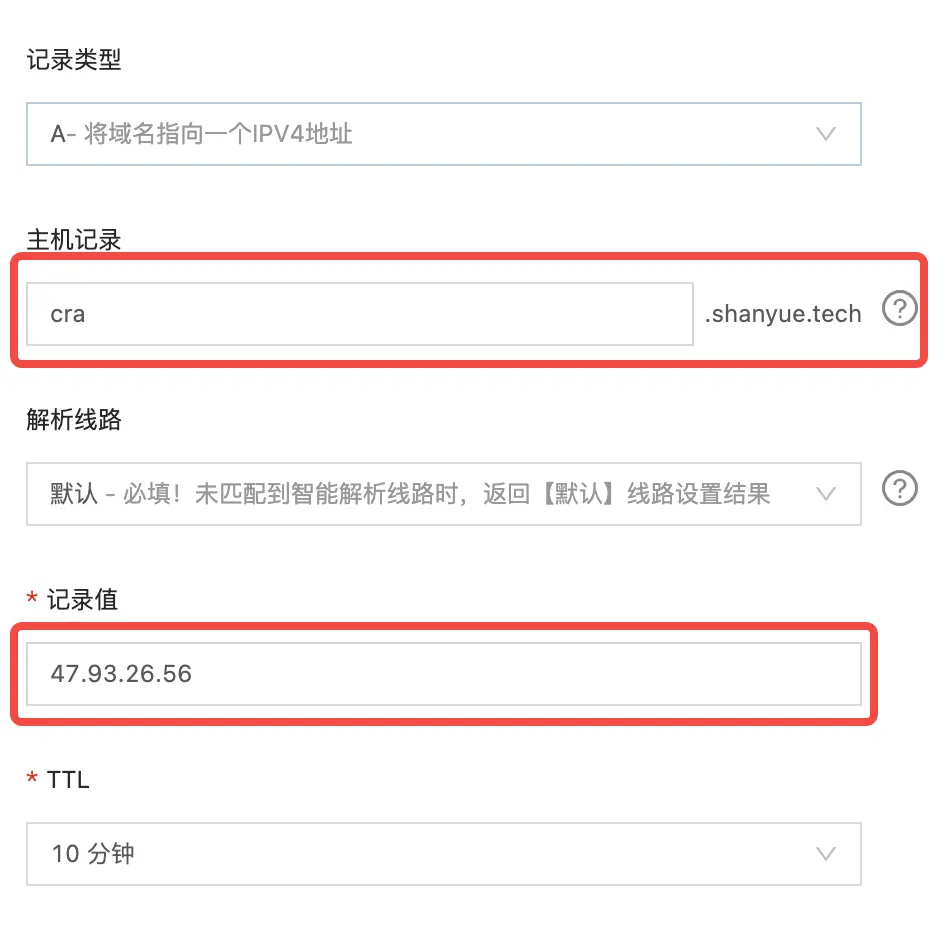
我们将它部署到 https://cra.shanyue.tech 中作为示例。在此之前,我需要做两件事
cra.shanyue.tech域名属于我个人。域名可自行在域名提供商进行购买。cra.shanyue.tech域名通过 A 记录指向搭建好 traefik 网关的服务器的 IP 地址。此处需要通过域名提供商的控制台进行配置。
我们在容器中配置 labels 即可配置域名,启动容器域名即可生效。而无需像传统 nginx 方式需要手动去配置 proxy_pass。
而在 traefik,在 container labels 中配置 traefik.http.routers 可为不同的路由注册域名。
labels:
- "traefik.http.routers.cra.rule=Host(`cra.shanyue.tech`)"编辑 domain.docker-compose.yaml,配置文件如下。
PS: 该配置文件位于 cra-deploy/domain.docker-compose.yaml
version: "3"
services:
domain:
build:
context: .
dockerfile: router.Dockerfile
labels:
# 为 cra 配置我们的自定义域名
- "traefik.http.routers.cra.rule=Host(`cra.shanyue.tech`)"
# 设置 https,此时我们的 certresolver 为 le,与上篇文章配置保持一致
- traefik.http.routers.cra.tls=true
- traefik.http.routers.cra.tls.certresolver=le
networks:
default:
external:
name: traefik_default根据 docker-compose up 启动服务,此时可在互联网访问。
$ docker-compose -f domain.docker-compose.yaml up domain访问 https://cra.shanyue.tech 成功。
在 nginx 中可以通过 server_name 配置多域名。
在 traefik 中通过 traefik.https.routers 可配置多域名。
- cra.shanyue.tech
- preview.cra.shanyue.tech
- feature-a.cra.shanyue.tech
labels:
- "traefik.http.routers.cra.rule=Host(`cra.shanyue.tech`)"
- "traefik.http.routers.cra-preview.rule=Host(`preview.cra.shanyue.tech`)"
- "traefik.http.routers.cra-feature-a.rule=Host(`feature-a.cra.shanyue.tech`)"在我们启动 traefik 时,traefik 容器将 /var/run/docker.sock 挂载到容器当中。
通过 docker.sock 调用 Docker Engine API 可将同一网络下所有容器信息列举出来。
# 列举出所有容器的标签信息
$ curl --unix-socket /var/run/docker.sock http:/containers/json | jq '.[] | .Labels'目前为止,终于将一个前端应用使用域名进行部署。此时除了一些部署知识外,还需要一些服务器资源,包括
- 一台拥有公网IP地址的服务器
- 一个自己申请的域名
当然,针对前端开发者而言,更重要的还是
- 如何使用 docker 将它跑起来
- 如何将它更快地跑起来
- 如何自动将它跑起来
下一篇文章内容便是 CICD 相关。
在前边的篇章中,我们在服务器中搭建了 Traefik 网关,并使用 docker-compose 部署前端并发布成功。
但前边的部署流程都是基于手动部署,那我们如何将部署进行自动化:
即每当我们将前端代码更新到仓库后,代码将会拉取仓库代码并自动部署到服务器。
这就是 CICD 要做的事情。
CI,Continuous Integration,持续集成。CD,Continuous Deployment,持续部署。(或者 Continuous Delivery,持续交付)
CICD 与 git 集成在一起,可理解为服务器端的 git hooks: 当代码 push 到远程仓库后,借助 WebHooks 对当前代码在构建服务器(即 CI 服务器,也称作 Runner)中进行自动构建、测试及部署等。
为了方便理解,我们将上篇篇章中所指的服务器称为部署服务器,而 CI 中所指的服务器,称为构建服务器。
- 部署服务器: 对外提供服务的服务器,容器在该服务器中启动。
- 构建服务器: 进行CI构建的服务器,一般用以构建、测试和部署,构建镜像以及自动部署服务。一般也可以是 Docker 容器。
在以前的篇章中,相当于构建服务器和部署服务器为同一个服务器,而在工作中,二者往往为独立服务器。但是为了更好的 CICD,构建服务器会赋予控制部署服务集群的权限,在构建服务器中通过一条命令,即可将某个服务在部署服务器集群中进行管理。
在 CICD 中,构建服务器往往会做以下工作,这也是接下来几篇篇章的内容:
- 功能分支提交后,通过 CICD 进行自动化测试、语法检查、npm 库风险审计等前端质量保障工程,如未通过 CICD,则无法 Code Review,更无法合并到生产环境分支进行上线
- 功能分支提交后,通过 CICD 对当前分支代码构建独立镜像并生成独立的分支环境地址进行测试如对每一个功能分支生成一个可供测试的地址,一般是
<branch>.dev.shanyue.tech此种地址 - 功能分支测试通过后,合并到主分支,自动构建镜像并部署到生成环境中 (一般生成环境需要手动触发、自动部署)
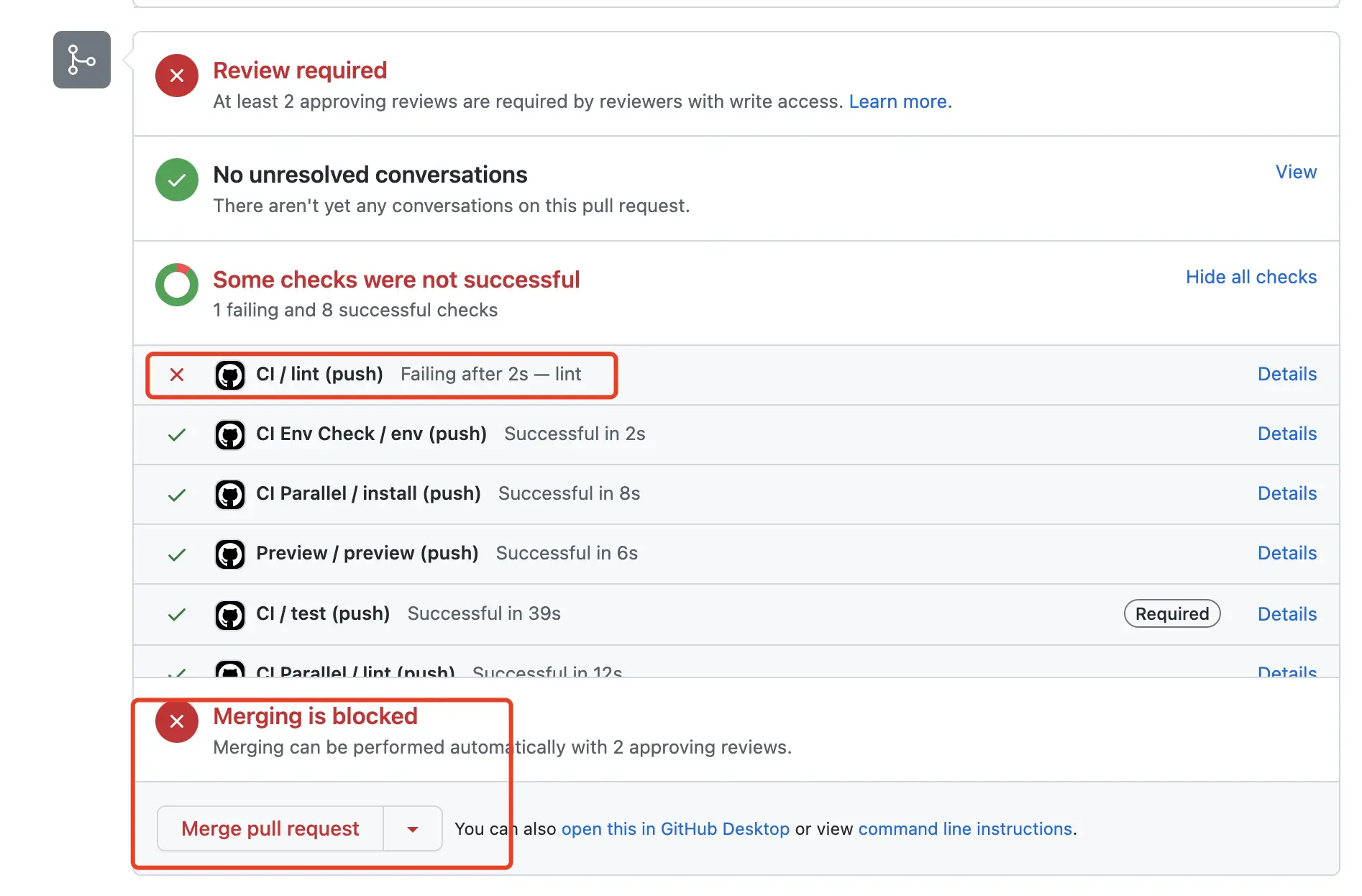
如下图,当所有 Checks 通过后,Merge pull request 才会变绿允许进行合并。
由于近些年来 CICD 的全面介入,项目开发的工作流就是 CICD 的工作流,请看一个比较完善的 CICD Workflow。
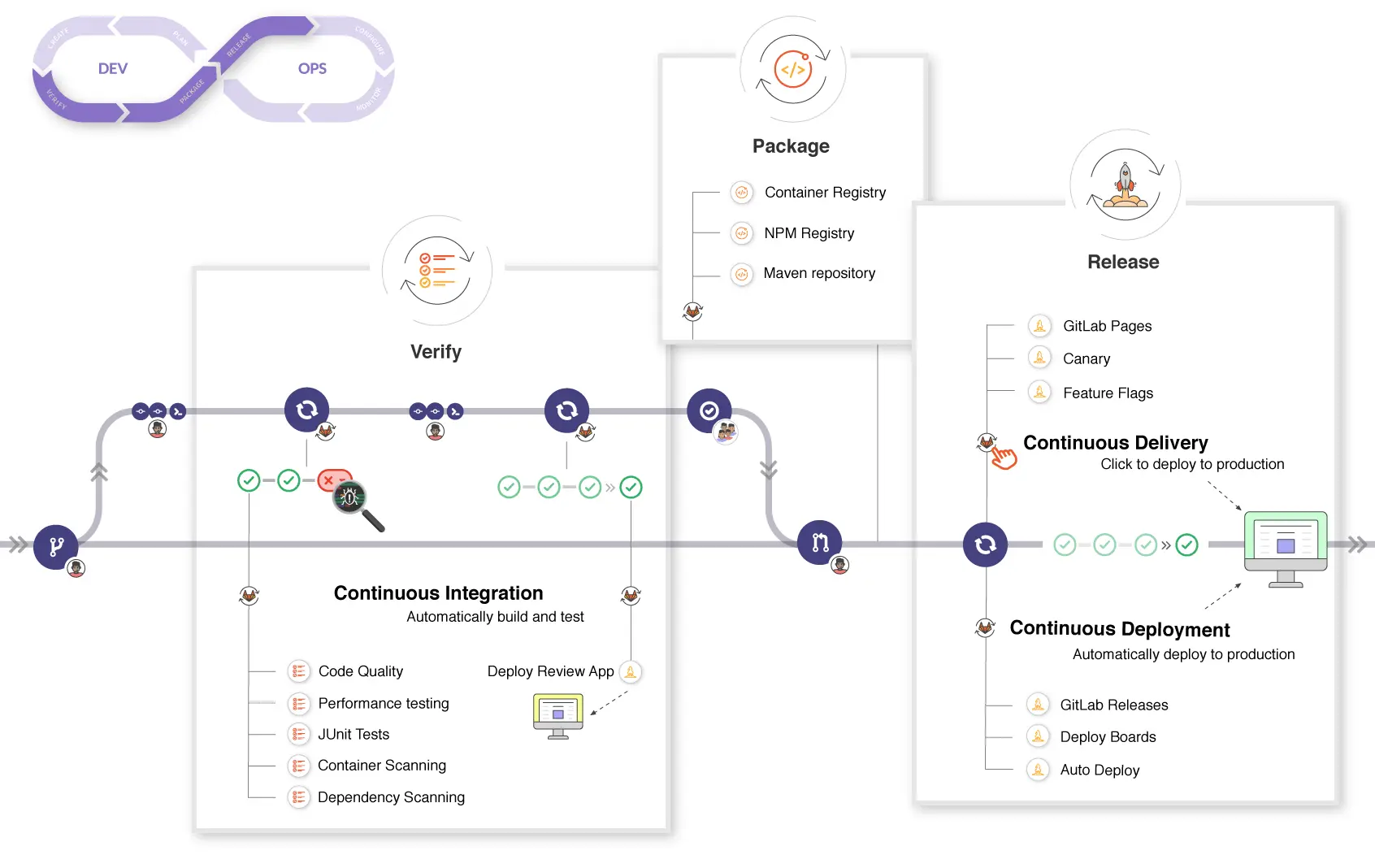
PS: 该图出自 Gitlab CICD Workflow
- CI: 切出功能分支,进行新特性开发。此时为图中的
Verify、Package阶段 - CD: 合并功能分支,进行自动化部署。此时为图中的
Release阶段。
国内公司一般以 gitlab CI 作为 CICD 工具,此时需要自建 Gitlab Runner 作为构建服务器。
如果你们公司没有 CICD 基础设置,但是个人对 CICD 有极大兴趣,那么可以尝试 github 免费的 CICD 服务: github actions。
每一家 CICD 产品,都有各自的配置方式,但是总体上用法差不多。我们了解下 CICD 的基本术语
Runner: 用来执行 CI/CD 的构建服务器workflow/pipeline: CI/CD 的工作流。(在大部分 CI,如 Gitlab 中为 Pipeline,而 Github 中为 Workflow,但二者实际上还是略有不同)job: 任务,比如构建,测试和部署。每个workflow/pipeline由多个job组成
在本系列专栏中,以 Github Actions 为主,并配有全部关于 Github Actions 的配置代码,并可成功运行,配置目录见 .github/workflows。以 Gitlab CI 为辅,并配有部分配置代码。
以下是关于 Github Actions 与 Gitlab CI 的配置文档,在以后篇章中可自行查阅。
在文首提到 CICD 的主要意义:
每当我们将前端代码更新到仓库后,代码将会拉取仓库代码并自动部署到服务器。
我们进行拆分成两个阶段,并在以下简单介绍如何对其进行配置
- 事件: push
- 命令: 前端部署
该 CI/CD 触发时的事件。如果需要上传代码自动部署的功能时,应该选择 on: push
on: push更多 Github Actions Event 可以参考官方文档 Events that trigger workflows
# 仅仅当 master 代码发生变更时,用以自动化部署
on:
push:
branches:
- master
# 仅当 feature/** 分支发生变更时,进行 Preview 功能分支部署 (见 Preview 篇)
on:
pull_request:
types:
# 当新建了一个 PR 时
- opened
# 当提交 PR 的分支,未合并前并拥有新的 Commit 时
- synchronize
branches:
- 'feature/**'
# 在每天凌晨 0:30 处理一些事情,比如清理多余的 OSS 资源,清理多余的功能分支 Preview (见 Preview 篇)
on:
schedule:
- cron: '30 8 * * *'如,在 push 到最新代码时,使用 docker-compose up 进行部署。
name: push
on: [push]
jobs:
test:
# 将代码跑在 ubuntu 上
runs-on: ubuntu-latest
steps:
# 切出代码,使用该 Action 将可以拉取最新代码
- uses: actions/checkout@v2
# 运行部署的脚本命令
- run: docker-compose up -d生产环境的代码必须通过 CI 检测才能上线,但这也需要我们进行手动设置。
一般而言,我们会设置以下策略加强代码的质量管理。
- 主分支禁止直接 PUSH 代码
- 代码都必须通过 PR 才能合并到主分支
- 分支必须 CI 成功才能合并到主分支
- 代码必须经过 Code Review (关于该 PR 下的所有 Review 必须解决)
- 代码必须两个人同意才能合并到主分支
在 Gitlab 与 Github 中均可进行设置:
如下示例,未通过 CI,不允许 Merge。可见示例 PR #22。
终于到了最重要的内容了,如何使用 CICD 自动部署前端?
通过以前的篇章,我们了解到部署前端,仅仅需要在部署服务器执行一条命令即可 (简单环境下)
$ docker-compose up --build以下是对于简单部署在个人服务器的一个 Github Actions 的案例,由于构建服务器无部署服务器管理集群应用的能力与权限 (kubernetes 拥有这种能力)。如果部署到服务器,只能简单粗暴地通过 ssh 进入服务器并拉取代码执行命令。
deploy:
runs-on: ubuntu-latest
steps:
- |
ssh [email protected] "
# 假设该仓库位于 ~/Documents 目录
cd ~/Documents/cra-deploy
# 拉取最新代码
get fetch origin master
git reset --hard origin/master
# 部署
docker-compose up --build -d
"在本次实践中,将构建服务器与部署服务器置于一起,则可以解决这个问题。在 Github Actions,可以在自有服务器中自建 Runner,文档如下。
此时部署仅仅需要一行 docker-compose up。
更详细关于自动部署的配置可见 cra-deploy/production.yaml
production:
# 该 JOB 在自建 Runner 中进行运行
runs-on: self-hosted
steps:
# 切出代码,使用该 Action 将可以拉取最新代码
- uses: actions/checkout@v2
- run: docker-compose up --build -d而在真实的工作环境中,部署更为复杂,往往通过一些封装的命令来完成,分为三步:
- 构建镜像
- 推送镜像到自建的镜像仓库
- 将镜像仓库中的镜像拉取到部署服务器进行部署 (kubectl)
伪代码如下:
production:
# 该 JOB 在自建 Runner 中进行运行
runs-on: self-hosted
steps:
# 构建镜像
- docker build -t cra-deploy-app .
# 推送镜像
- docker push cra-deploy-app
# 拉取镜像并部署,deploy 为一个伪代码命令,在实际项目中可使用 helm、kubectl
- deploy cra-deploy-app .
# 或者通过 kubectl 进行部署
# - kubectl apply -f app.yaml
# 或者通过 helm 进行部署
# - helm install cra-app cra-app-chart本篇文章介绍了 CICD 的基础概念,并通过自建 Runner 进行了简单部署。
在下一篇章,将会上手对 create-react-app 在 CICD 中进行前端质量保障。
在上一篇章,我们了解到什么是 CICD。
本篇文章通过 github actions 介绍如何通过 CI 进行前端的质量检查。
话不多说,先以一个流程简单的 CI 配置开始,在 CI 中介入以下流程。
- Install。依赖安装。
- Lint。保障统一的代码风格。
- Test。单元测试。
- Preview。生成一个供测试人员进行检查的网址。
由于,Preview 是一个较为复杂的流程,留在以后篇章详解,今天先来说一下 Lint/Preview。
我们假设一个极其简单的 Git Workflow 场景。
- 每个人在功能分支进行新功能开发,分支名
feature-*。每一个功能分支将会有一个功能分支的测试环境地址,如<branch>.dev.shanyue.tech。 - 当功能分支测试完毕没有问题后,合并至主分支
master。在主分支将会部署到生产环境。 - 当生产环境出现问题时,切除一条分支
hotfix-*,解决紧急 Bug。
为了保障代码质量,线上的代码必须通过 CI 检测,但是应选择什么时机 (什么分支,什么事件)?
- 功能分支提交后(CI 阶段),进行 Build、Lint、Test、Preview 等,如未通过 CICD,则无法 Preview,更无法合并到生产环境分支进行上线
- 功能分支通过后(CI 阶段),合并到主分支,进行自动化部署。
在 CI 操作保障代码质量的环节中,可确定以下时机:
# 当功能分支代码 push 到远程仓库后,进行 CI
on:
push:
branches:
- 'feature/**'或者将 CI 阶段提后至 PR 阶段,毕竟能够保障合并到主分支的代码没有质量问题即可。(但同时建议通过 git hooks 在客户端进行代码质量检查)
# 当功能分支代码 push 到远程仓库以及是 Pull Request 后,进行 CI
on:
pull_request:
types:
# 当新建了一个 PR 时
- opened
# 当提交 PR 的分支,未合并前并拥有新的 Commit 时
- synchronize
branches:
- 'feature/**'通过 CI,我们可以快速反馈,并促进敏捷迭代。这要求我们使用 Git 时尽早提交以发现问题,以功能小点为单位频繁提交发现问题,也避免合并分支时发现重大冲突。
在 CI 中,互不干扰的任务并行执行,可以节省很大时间。如 Lint 和 Test 无任何交集,就可以并行执行。
但是 Lint 和 Test 都需要依赖安装 (Install),在依赖安装结束后再执行,此时就是串行的。
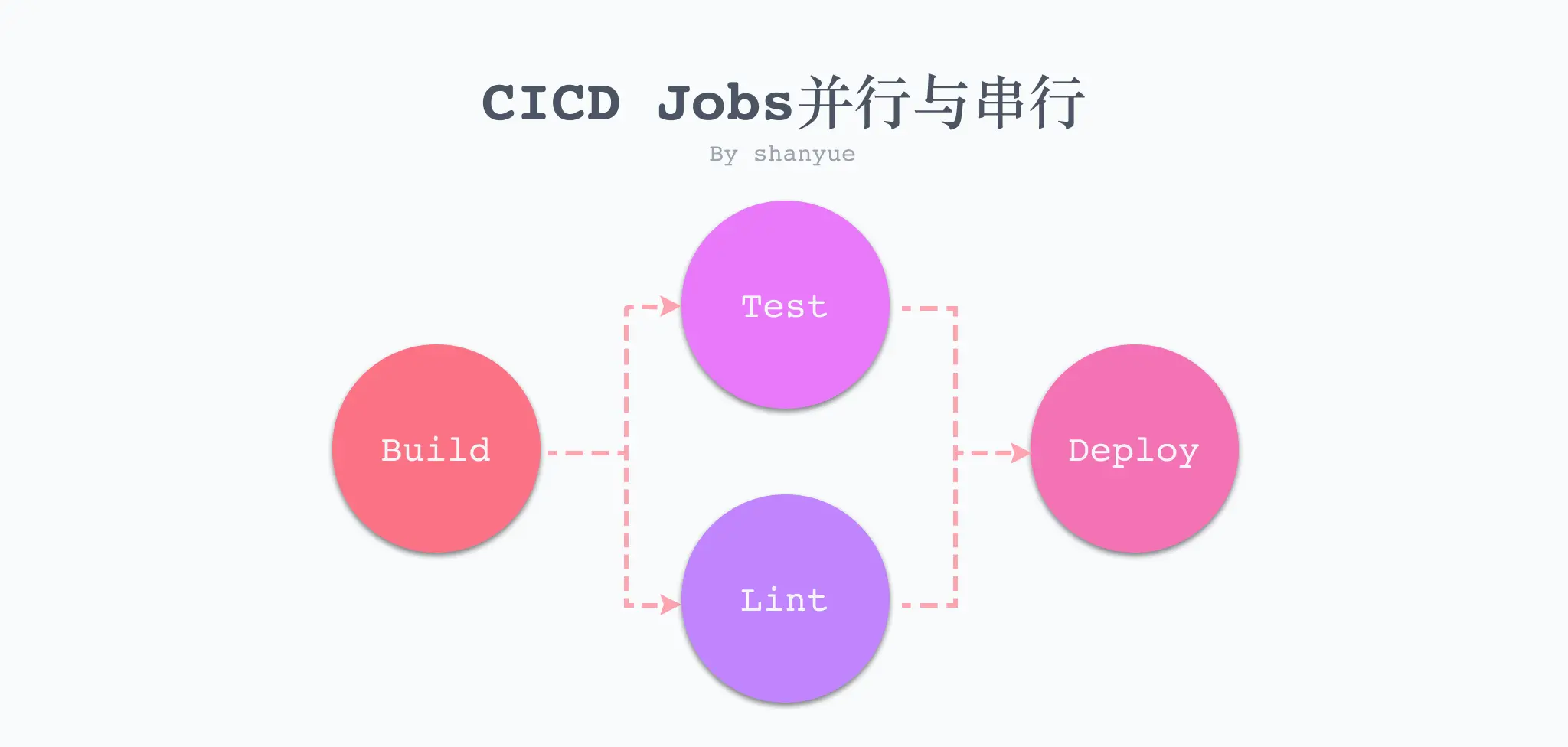
而进行串行时,如果前一个任务失败,则下一个任务也无法继续。即如果测试无法通过,则无法进行 Preview,更无法上线。
PS: 此处可控制某些任务允许失败。如 Github Actions 中的 jobs.<job_id>.continue-on-error
我们写一段 github actions 脚本,用以对我们的试验项目 cra-deploy 进行 Lint/Test。
由于 create-react-app 使用 ESLint Plugin 源码 进行代码检查,而非命令行式命令。
当 ESLint 存在问题时,create-react-app 会判断当前是否 CI 环境来决定报错还是警告,而在 CI 中 npm run build 将会报错。
因此,我这里使用 npm run build 来模拟 Lint 检查。
脚本路径位于 workflows/ci.yaml。
# 关于本次 workflow 的名字
name: CI
# 执行 CI 的时机: 当 git push 代码到 github 时
on: [push]
# 执行所有的 jobs
jobs:
lint:
runs-on: ubuntu-latest
steps:
# 切出代码,使用该 Action 将可以拉取最新代码
- uses: actions/checkout@v2
# 配置 node.js 环境,此时使用的是 node14
# 注意此处 node.js 版本,与 Docker 中版本一致,与 package.json 中 engines.node 版本一致
# 如果需要测试不同 node.js 环境下的表现,可使用 matrix
- name: Setup Node
uses: actions/setup-node@v1
with:
node-version: 14.x
# 安装依赖
- name: Install Dependencies
run: yarn
# 在 cra 中,使用 npm run build 来模拟 ESLint
- name: ESLint
run: npm run build
test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: Setup Node
uses: actions/setup-node@v1
with:
node-version: 14.x
- name: Install Dependencies
run: yarn
- name: Test
run: npm run test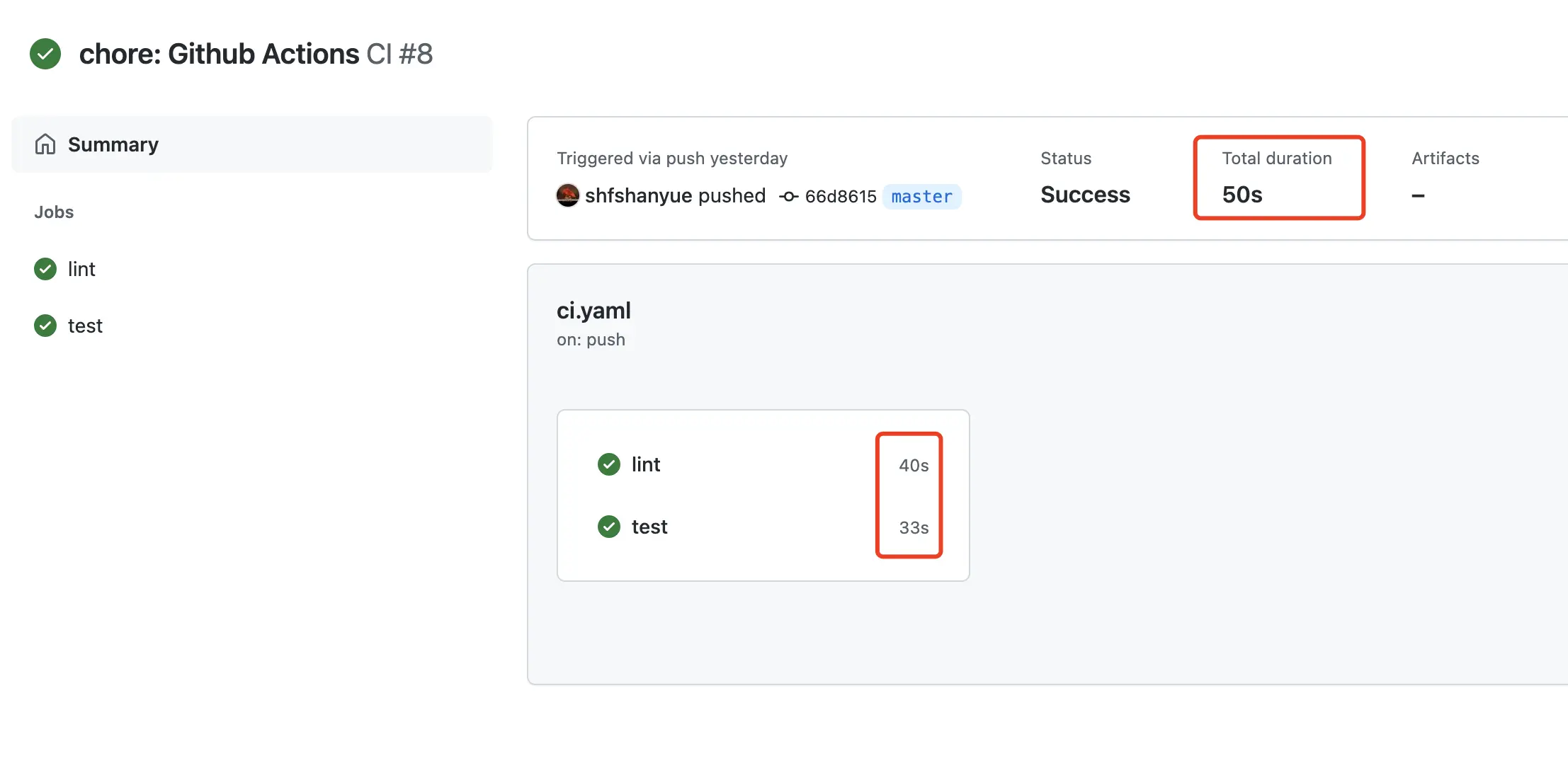
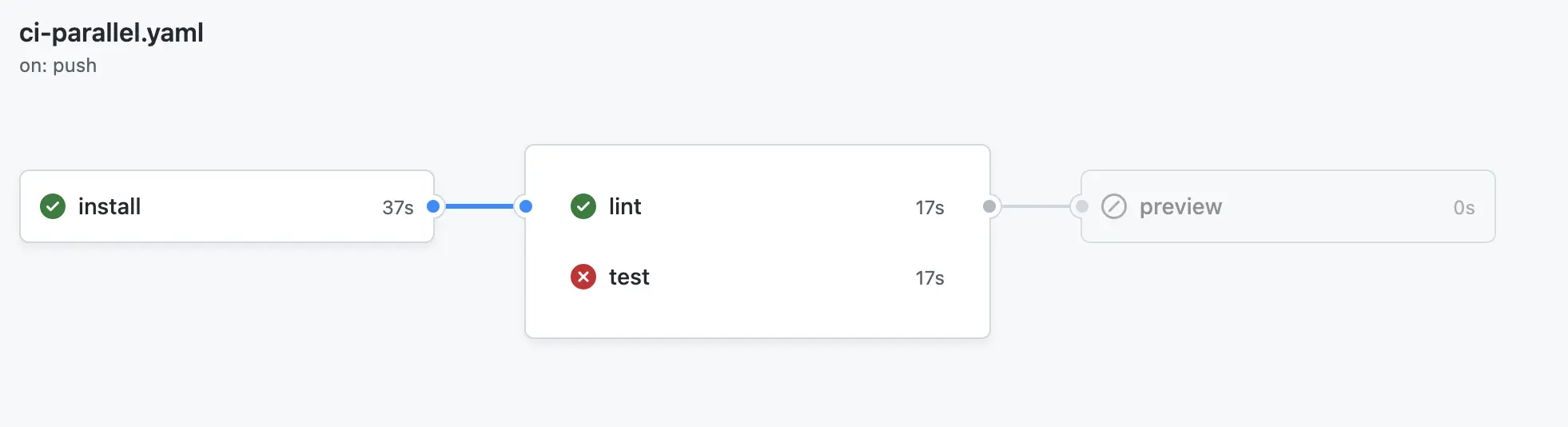
关于截图的本次 Action 执行情况
lint执行了 40stest执行了 33s- 两者并行执行,总共执行了 50s
尽管二者并行执行,但可以把 Install 的过程抽离来减少服务器的并行压力。
首先,将 Install 前置会节省服务器资源,但并不会加快 CI 时间。甚至因为多了一个 JOB,Job 间切换也需要花费时间,总时间还会略有增加。

脚本路径位于 workflows/ci-parallel.yaml。
在 Lint/Test 需要使用到 Install 阶段构建而成的 node_modules 目录,CI Cache 可在不同的 Job 间共享资源数据。此处先忽略,在下一篇文章进行讲解。
一个 Job 依赖另一个 Job,在 Github Actions 中可使用 needs 字段。
install:
lint:
needs: install
test:
needs: install完整配置文件如下,关于 Cache 将在下节篇章讲解。
name: CI Parallel
on: [push]
jobs:
install:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: Setup Node
uses: actions/setup-node@v1
with:
node-version: 14.x
- name: Cache Node Modules
id: cache-node-modules
uses: actions/cache@v2
with:
path: node_modules
key: node-modules-${{ hashFiles('yarn.lock') }}
restore-keys: node-modules-
- name: Install Dependencies
if: steps.cache-node-modules.outputs.cache-hit != 'true'
run: yarn
lint:
runs-on: ubuntu-latest
# 通过 needs 字段可设置前置依赖的 Job,比如 install
needs: install
steps:
- uses: actions/checkout@v2
- name: Setup Node
uses: actions/setup-node@v1
with:
node-version: 14.x
- name: Cache Node Modules
id: cache-node-modules
uses: actions/cache@v2
with:
path: node_modules
key: node-modules-${{ hashFiles('yarn.lock') }}
restore-keys: node-modules-
- name: ESLint
run: npm run build
test:
runs-on: ubuntu-latest
needs: install
steps:
- uses: actions/checkout@v2
- name: Setup Node
uses: actions/setup-node@v1
with:
node-version: 14.x
- name: Cache Node Modules
id: cache-node-modules
uses: actions/cache@v2
with:
path: node_modules
key: node-modules-${{ hashFiles('yarn.lock') }}
restore-keys: node-modules-
- name: Test
run: npm run test
preview:
runs-on: ubuntu-latest
needs: [lint, test]
steps:
- run: echo 'Preview OK'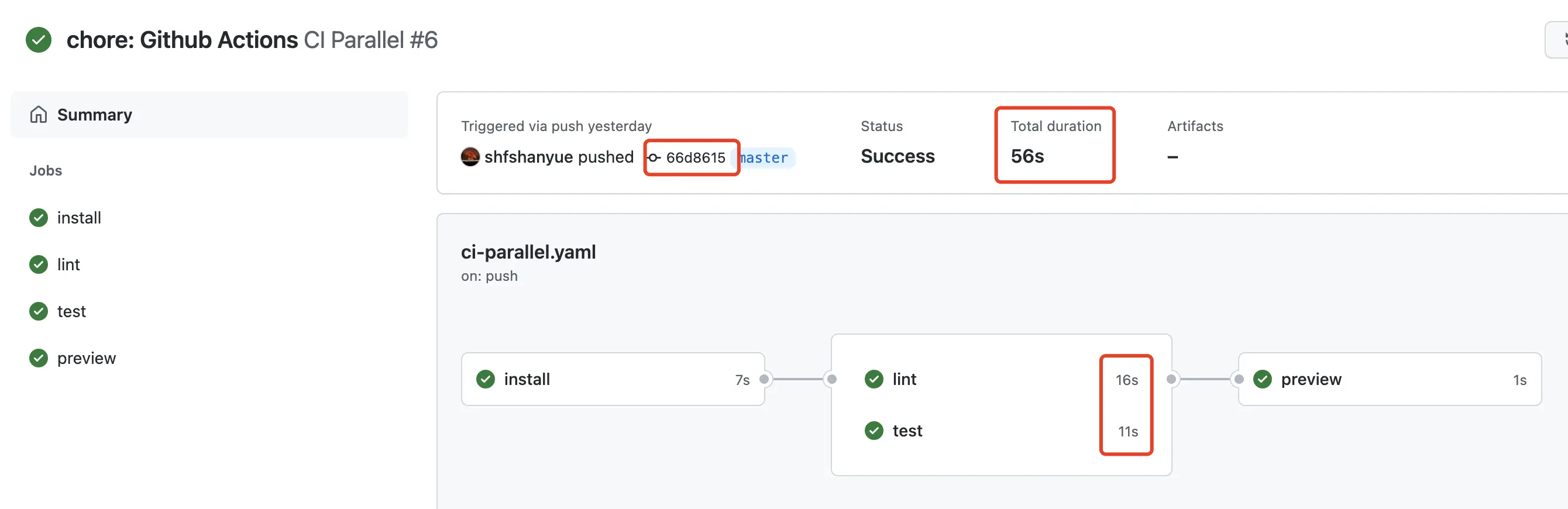
关于截图的本次 Action 执行情况
从图中也可以看出 Lint 和 Test 用了更好的时间,然而总时长还略有增加。
Lint 和 Test 仅是 CI 中最常见的阶段。为了保障我们的前端代码质量,还可以添加以下阶段。
- Audit: 使用
npm audit或者 snyk 检查依赖的安全风险。可详查文章如何检测有风险依赖 - Quality: 使用 SonarQube 检查代码质量。
- Container Image: 使用 trivy 扫描容器镜像安全风险。
- End to End: 使用 Playwright 进行 UI 自动化测试。
- Bundle Chunk Size Limit: 使用 size-limit 限制打包体积,打包体积过大则无法通过合并。
- Performance (Lighthouse CI): 使用 lighthouse CI 为每次 PR 通过 Lighthouse 打分,如打分过低则无法通过合并。
有些细心并知识面广泛的同学可能注意到了,某些 CI 工作也可在 Git Hooks 完成,确实如此。
它们的最大的区别在于一个是客户端检查,一个是服务端检查。而客户端检查是天生不可信任的。
而针对 git hooks 而言,很容易通过 git commit --no-verify 而跳过。

最重要的是,CI 还可对部署及其后的一系列操作进行检查,如端对端测试、性能测试以及容器扫描(见上)等。
本篇文章通过 Github Actions 配置了 Lint/Test,并给出了更多可在 CI 中所做的代码质量检查。
那在 Pipeline 的多个阶段,如何更好利用缓存呢?

在上一篇文章提到 Lint/Test 在 CI Pipeline 不同的阶段共享资源目录需要利用 CI 中的 Cache。
其实不仅如此
- 当我们使用 npm i 进行依赖安装时,由于 node_modules 目录已存在,将只会安装最新添加的依赖。
- 当我们使用 webpack 5 进行构建时,如果使用了
filesystem cache,因为在磁盘中含有缓存 (node_modules/.cache),二次构建往往比一次构建快速十几倍。
而在 CICD 中,这些都失去了意义,因为 CICD 每次 Job 都相当于新建了一个目录,每次构建都相当于是首次构建。
但是,CI 提供了一些缓存机制,可以将一些资源进行缓存。如果每次可以将缓存取出来,则大大加速了前端部署的速度。
以优化 npm run build 为例。
如果不进行任何缓存上的优化,仅需要 install/build
$ yarn
$ npm run build翻译成 Github Actions:
name: Build
on: [push]
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: Setup Node
uses: actions/setup-node@v1
with:
node-version: 14.x
- name: Install Dependencies
run: yarn
- name: Build Dependencies
run: npm run build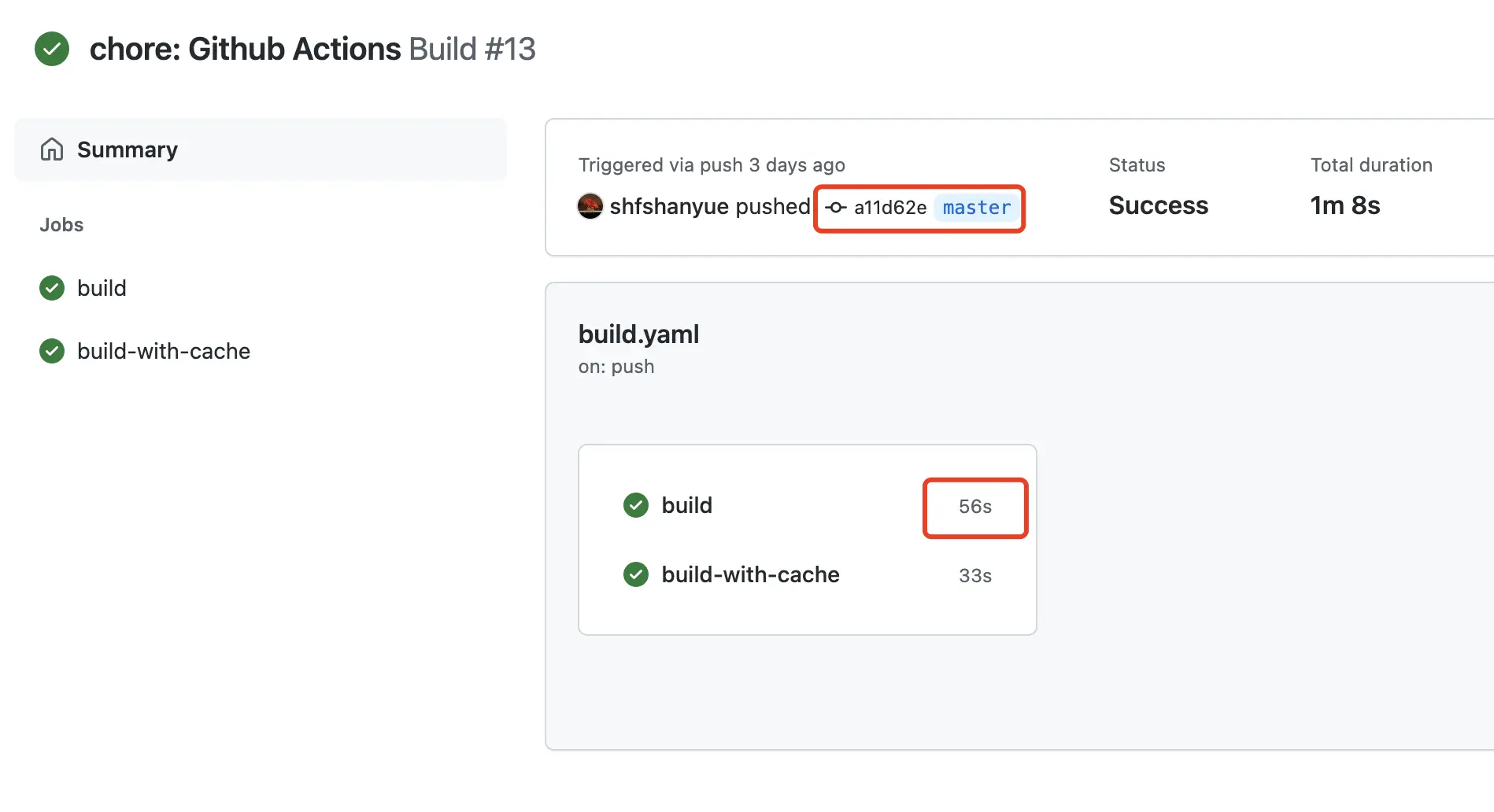
从截图可以看出来此次执行耗时 56s,其中大部分时间花费在依赖安装上
关于截图的本次 Action 执行情况
如果可以对 node_modules 进行缓存,那么有以下两个好处
- 假设没有新的 package 需要安装,则无需再次
npm i/yarn - 假设存有新的 package 需要安装,仅仅会安装变动的 package
在 Github Actions 中,通过 Cache Action
- path: 指需要缓存的目录
- key: 根据 key 进行缓存,如果存在相同的 key,则为命中 (hit)。在 Github Actions 中可利用函数
hashFiles针对文件计算其 hash 值。 - restore-keys: 如果 ke 未命中,则使用 restore-keys 命中缓存。
根据 Cache Action 针对 npm 中的 node_modules 进行缓存
- name: Cache Node Modules
id: cache-node-modules
# 使用 cache action 进行目录资源缓存
uses: actions/cache@v2
with:
# 对 node_modules 目录进行缓存
path: node_modules
# 根据字段 node-modules- 与 yarn.lock 的 hash 值作为 key
# 当 yarn.lock 内容未发生更改时,key 将不会更改,则命中缓存
# 如果使用 npm 作为包管理工具,则是 package-lock.json
key: node-modules-${{ hashFiles('yarn.lock') }}
restore-keys: node-modules-缓存 node_modules 有时会存在问题,比如 npm ci 在 npm i 之前,特意将 node_modules 删除以保障安全性。
如果不想缓存 node_modules,可以缓存 npm/yarn 全局缓存目录。通过以下命令可知他们的全局缓存目录
- npm:
npm config get cache,如~/.npm - yarn:
yarn cache dir
为了保证缓存确实已设置成功,可在依赖安装之前通过 ls -lah node_modules 查看 node_modules 目录是否有文件。
# 查看缓存是否设置成功,输出 node_modules 目录
- name: Check Install/Build Cache
run: ls -lah node_modules | head -5steps.cache-node-modules.outputs.cache-hit 可获得 ID 为 cache-node-modules 该步骤,是否命中缓存。若命中,则无需再次安装依赖。
- name: Install Dependencies
# 如果命中 key,则直接跳过依赖安装
if: steps.cache-node-modules.outputs.cache-hit != 'true'
run: yarn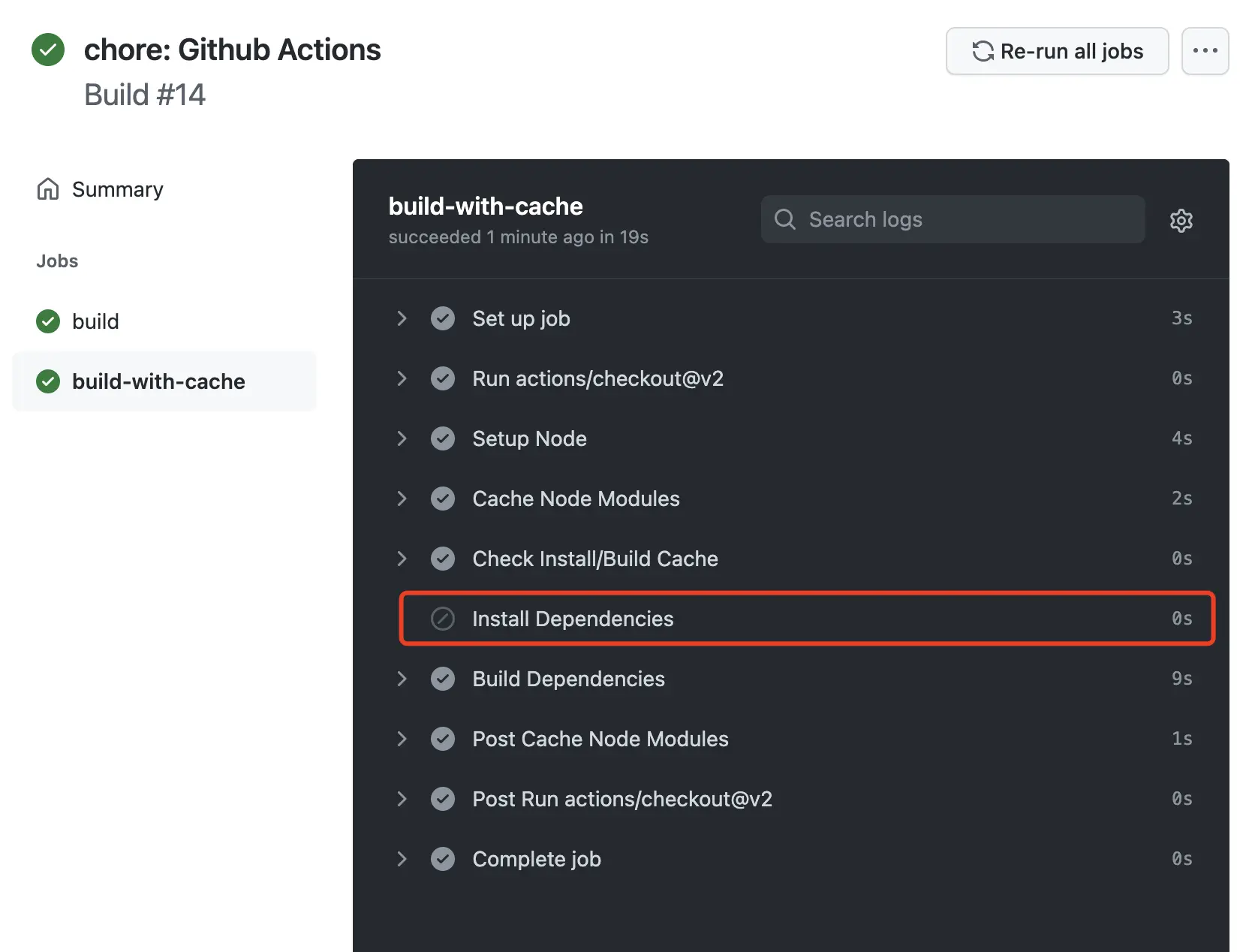
即使缓存未命中,我们也可以同样利用 node_modules 中内容,依赖安装时间也大幅降低。
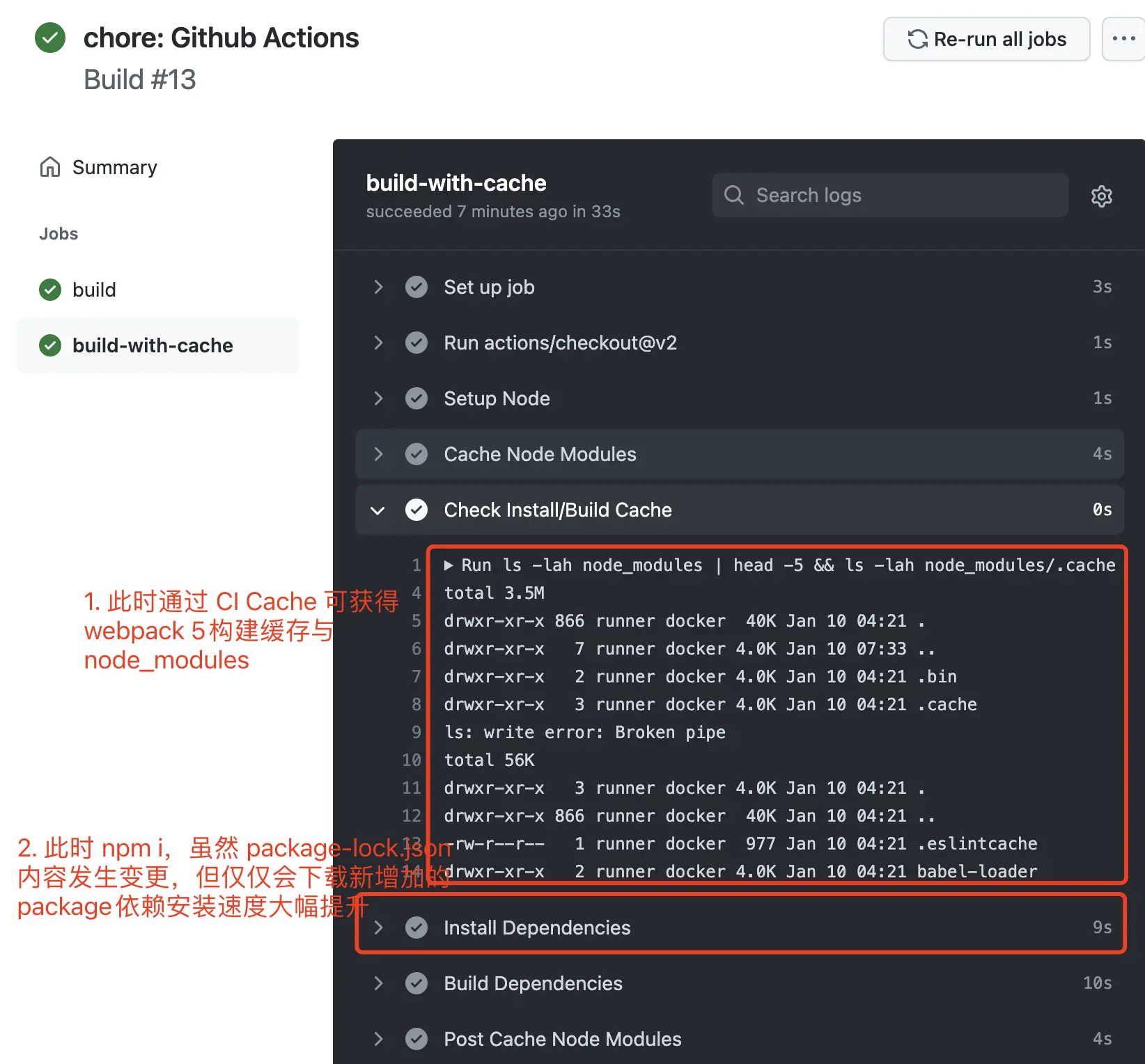
完整配置文件如下所示:
脚本路径位于 workflows/build.yaml。
name: Build
on: [push]
jobs:
build-with-cache:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: Setup Node
uses: actions/setup-node@v1
with:
node-version: 14.x
- name: Cache Node Modules
# 为 step 设置 id,可通过 steps.[id].outputs 获取到该步骤的值
id: cache-node-modules
# 使用 cache action 进行目录资源缓存
uses: actions/cache@v2
with:
# 对 node_modules 目录进行缓存
path: node_modules
# 根据字段 node-modules- 与 yarn.lock 的 hash 值作为 key
# 当 yarn.lock 内容未发生更改时,key 将不会更改,则命中缓存
# 如果使用 npm 作为包管理工具,则是 package-lock.json
key: node-modules-${{ hashFiles('yarn.lock') }}
restore-keys: node-modules-
# 查看缓存是否设置成功,输出 node_modules 目录
- name: Check Install/Build Cache
run: ls -lah node_modules | head -5
- name: Install Dependencies
# 如果命中 key,则直接跳过依赖安装
if: steps.cache-node-modules.outputs.cache-hit != 'true'
run: yarn
- name: Build Dependencies
run: npm run build当我们充分利用了 CI Cache 后,即可充分利用 Pipeline 各个阶段的缓存,如 npm cache、 Webpack 5 的 Cache,Docker 镜像构建时的 Cache。从而降低每次部署的上线时间。
在以前诸多章节中都会使用到环境变量。比如在 OSS 篇使用环境变量存储云服务的权限。在前端的异常监控服务中还会用到 Git 的 Commit/Tag 作为 Release 方便定位代码,其中 Commit/Tag 的名称即可从环境变量中获取。
而在后续章节还会使用分支名称作为功能测试分支的前缀。
在 Linux 系统中,通过 env 可列出所有环境变量,我们可对环境变量进行修改与获取操作,如 export 设置环境变量,${} 操作符获取环境变量。
$ env
USER=shanyue
$ echo $USER
shanyue
# 或者通过 printenv 获取环境变量
$ printenv USER
$ export USER=shanyue2
$ echo $USER
shanyue2
# 获取环境变量 Name 默认值为 shanyue
$ echo ${NAME:-shanyue}我们在前后端,都会用到大量的环境变量。环境变量可将非应用层内数据安全地注入到应用当中。在 node.js 中可通过以下表达式进行获取。
process.env.USERCI 作为与 Git 集成的工具,其中注入了诸多与 Git 相关的环境变量。以下列举一条常用的环境变量
| 环境变量 | 描述 |
|---|---|
CI |
true 标明当前环境在 CI 中 |
GITHUB_REPOSITORY |
仓库名称。例如 shfshanyue/cra-deploy. |
GITHUB_EVENT_NAME |
触发当前 CI 的 Webhook 事件名称 |
GITHUB_SHA |
当前的 Commit Id。 ffac537e6cbbf934b08745a378932722df287a53. |
GITHUB_REF_NAME |
当前的分支名称。 |
| 环境变量 | 描述 |
|---|---|
CI |
true 标明当前环境在 CI 中 |
CI_PROJECT_PATH |
仓库名称。例如 shfshanyue/cra-deploy。 |
CI_COMMIT_SHORT_SHA |
当前的 Commit Short Id。 ffac53。 |
CI_COMMIT_REF_NAME |
当前的分支名称。 |
- Commit/Tag 可作为版本号,注入到日志系统与 Sentry 中追踪异常。如,当在异常系统中收到一条报警,查看其 commit/tag 便可定位到从哪次部署开始出现问题,或者哪次代码提交开始出现问题。
- Branch 可作为 Preview 前缀。
在 Github Actions 中,可通过 env 设置环境变量,并可通过 $GITHUB_ENV 在不同的 Step 共享环境变量。
# 如何在 Github Actions 中设置环境变量
# https://docs.github.com/en/actions/learn-github-actions/environment-variables
- run: echo $CURRENT_USER
env:
CURRENT_USER: shanyue
- name: Check GITHUB_ENV
run: |
echo $GITHUB_ENV
cat $GITHUB_ENV
- run: echo CURRENT_USER=$(echo shanyue) >> $GITHUB_ENV
- run: echo $CURRENT_USER不同的 CI 产品会在构建服务器中自动注入环境变量。
$ export CI=true而测试、构建等工具均会根据环境变量判断当前是否在 CI 中,如果在,则执行更为严格的校验。
如 create-react-app 中 npm test 在本地环境为交互式测试命令,而在 CI 中则直接执行。
在本地环境构建,仅仅警告(Warn) ESLint 的错误,而在 CI 中,如果有 ESLint 问题,直接异常退出。
create-react-app 的源码中,使用了以下语句判断是否在 CI 环境中。
const isCI =
process.env.CI &&
(typeof process.env.CI !== 'string' ||
process.env.CI.toLowerCase() !== 'false');因此,可在本地中通过该环境变量进行更为严格的校验。比如在 git hooks 中。
# 可使用该命令,演示在 CI 中的表现
$ CI=true npm run test
$ CI=true npm run build::: v-pre
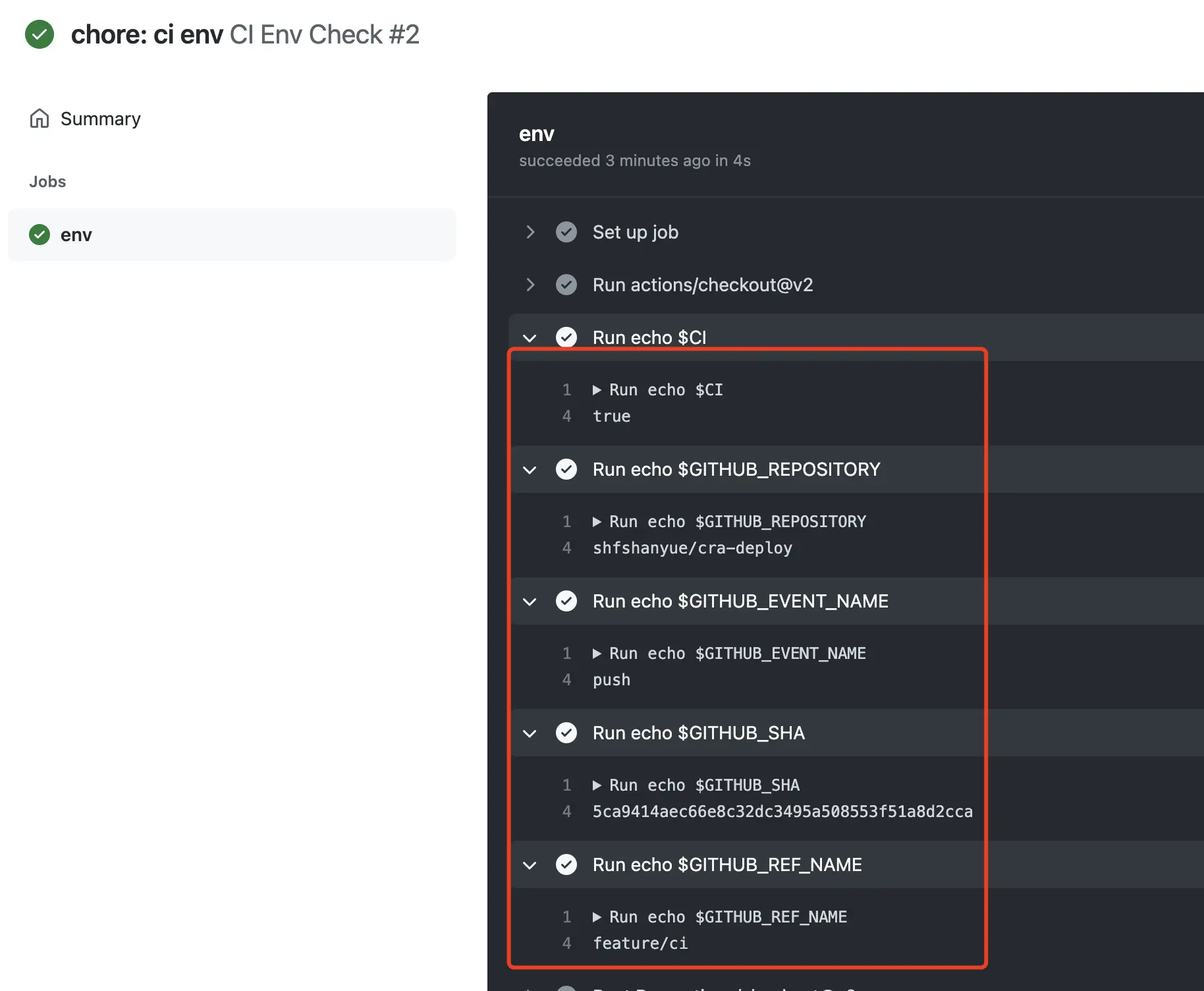
PS: 本次 Action 执行结果 Github Actions Run
为了验证此类环境变量,我们可以通过 CI 进行验证。
另外,在 Github Actions 中还可以使用 Context 获取诸多上下文信息,可通过 ${{ toJSON(github) }} 进行获取。
name: CI Env Check
on: [push]
jobs:
env:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- run: echo $CI
- run: echo $GITHUB_REPOSITORY
- run: echo $GITHUB_EVENT_NAME
- run: echo $GITHUB_SHA
- run: echo $GITHUB_REF_NAME
- run: echo $GITHUB_HEAD_REF
- name: Dump GitHub context
run: echo '${{ toJSON(github) }}'一个项目中的环境变量,可通过以下方式进行设置
- 本地/宿主机拥有环境变量
- CI 拥有环境环境变量,当然 CI Runner 可认为是宿主机,CI 也可传递环境变量 (命令式或者通过 Github/Gitlab 手动操作)
- Dockerfile 可传递环境变量
- docker-compose 可传递环境变量
- kubernetes 可传递环境变量 (env、ConfigMap、secret)
- 一些配置服务,如 consul、vault
而对于一些前端项目而言,可如此进行配置
- 敏感数据放在 [vault] 或者 k8s 的 [secket] 中注入环境变量,也可通过 Github/Gitlab 设置中进行注入环境变量
- 非敏感数据可放置在项目目录
.env中维护 - Git/OS 相关通过 CI 注入环境变量
关于 CI 中的环境变量介绍就到此了,下篇文章将介绍功能分支的 Preview。
关于 Preview,我在前几篇文章提到过几次,即每一个功能分支都配有对应的测试环境。
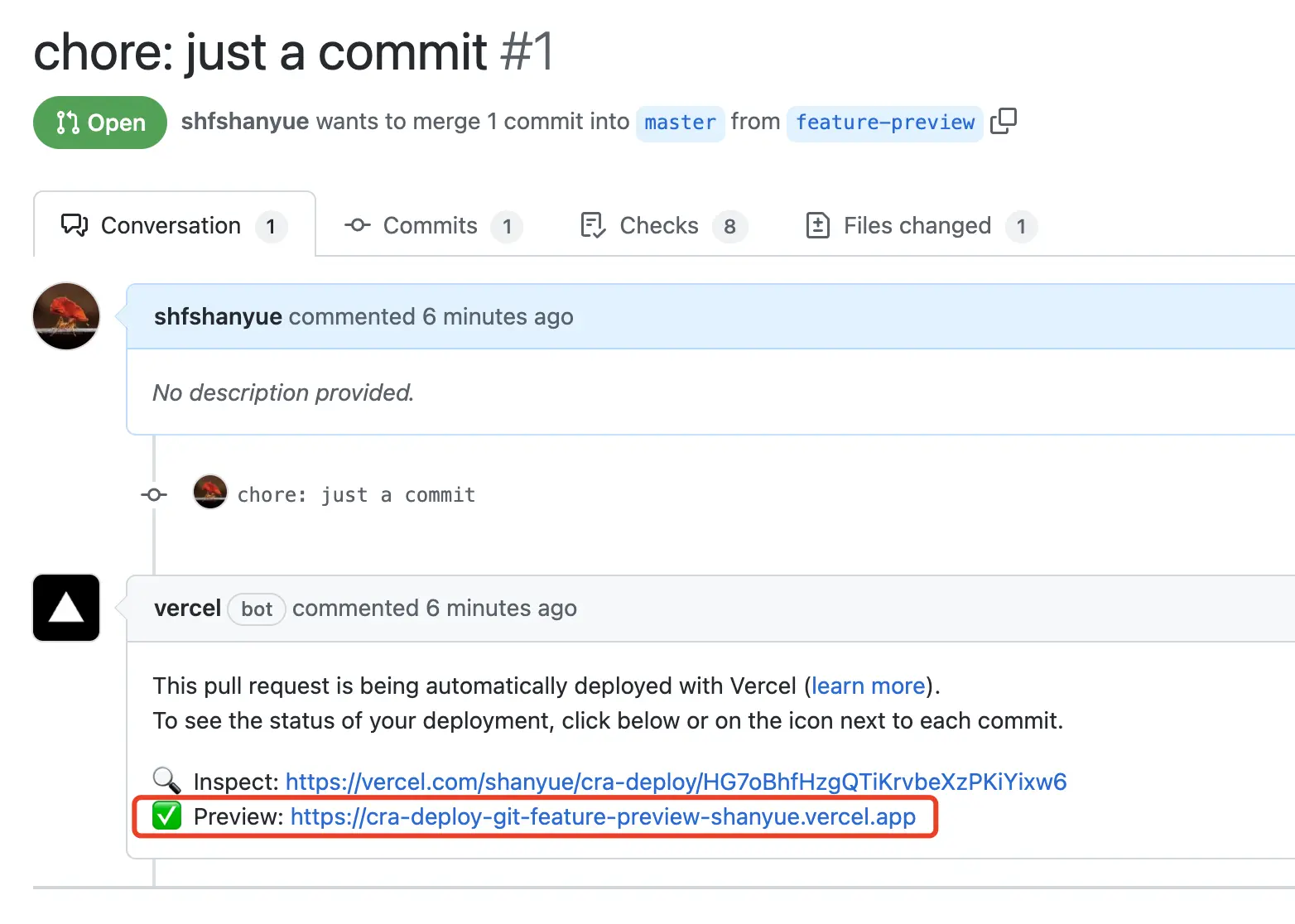
PS: 如果不了解 Preview 的话,可以看看我在 cra-deploy 的一个 PR #21。
项目研发的从开发到上线,一般可以可以划分为三个环境
local:本地环境,把项目 git clone 到自己的工作笔记本或者开发机中,在localhost:8080类似的地址进行调试与开发。此时环境的面向对象主要是开发者。dev:测试环境,本地业务迭代开发结束并交付给测试进行功能测试的环境,在dev.shanyue.tech类似的二级域名进行测试。此时环境的面向对象主要是测试人员。prod:生产环境,线上供用户使用的环境,在shanyue.tech类似的地址。此时环境的面向对象主要是用户。
这里我们增加一个功能分支测试环境,对应于 feature 分支。每个 feature 分支都会有一个环境,一个特殊的测试环境。如对功能 feature-A 的开发在 feature-A.cra.dev.shanyue.tech 进行测试。
本篇文章将实践对 cra-deploy 的 feature-preview 分支部署在 feature-preview.cra.shanyue.tech 中作为示例。
那实现多分支环境部署?
回忆之前关于部署的章节内容,我们可以根据以下 docker-compose.yaml 进行部署,并配置为 cra.shanyue.tech。
version: "3"
services:
domain:
build:
context: .
dockerfile: router.Dockerfile
labels:
# 为 cra 配置我们的自定义域名
- "traefik.http.routers.cra.rule=Host(`cra.shanyue.tech`)"
# 设置 https,此时我们的 certresolver 为 le,与上篇文章配置保持一致
- traefik.http.routers.cra.tls=true
- traefik.http.routers.cra.tls.certresolver=le
networks:
default:
external:
name: traefik_default则仔细一思索,不难得出 docker-compose 的解决方案。
- 对不同分支根据分支名配置不同的 service
- 对每个 service 根据分支名配置响应的
labels
回忆之前关于 CI 的章节内容,我们在构建服务器中,可通过环境变量获取到当前仓库的当前分支,我们基于分支名称进行功能分支环境部署。
假设 COMMIT_REF_NAME 为指向当前分支名称的环境变量,如此
version: "3"
services:
cra-preview-${COMMIT_REF_NAME}:
build:
context: .
dockerfile: router.Dockerfile
labels:
# 配置域名: Preview
- "traefik.http.routers.cra-preview-${COMMIT_REF_NAME}.rule=Host(`${COMMIT_REF_NAME}.cra.shanyue.tech`)"
- traefik.http.routers.cra-preview-${COMMIT_REF_NAME}.tls=true
- traefik.http.routers.cra-preview-${COMMIT_REF_NAME}.tls.certresolver=le
# 一定要与 traefik 在同一网络下
networks:
default:
external:
name: traefik_default大功告成,但还有一点问题: 在 Service Name 上无法使用环境变量。
$ docker-compose -f preview.docker-compose.yaml up
WARNING: The COMMIT_REF_NAME variable is not set. Defaulting to a blank string.
ERROR: The Compose file './preview.docker-compose.yaml' is invalid because:
Invalid service name 'cra-app-${COMMIT_REF_NAME}' - only [a-zA-Z0-9\._\-] characters are allowed在 docker-compose.yaml 中不支持将 Service 作为环境变量,因此 docker-compose up 启动容器失败。
我们可以写一段脚本将文件中的环境变量进行替换,但完全没有这个必要,因为有一个内置于操作系统的命令 envsubst 专职于文件内容的环境变量替换。
PS: 如果系统中无自带
envsubst命令,可使用第三方 envsubst 进行替代。
注意,以下命令中的 COMMIT_REF_NAME 环境变量为当前分支名称,可通过 git 命令获取。而在 CI 当中,可直接通过 CI 相关环境变量获得,无需通过命令。
$ cat preview.docker-compose.yaml | COMMIT_REF_NAME=$(git rev-parse --abbrev-ref HEAD) envsubst
version: "3"
services:
cra-preview-feature-preview:
build:
context: .
dockerfile: router.Dockerfile
labels:
# 配置域名: Preview
- "traefik.http.routers.cra-preview-master.rule=Host(`cra.master.shanyue.tech`)"
- traefik.http.routers.cra-preview-master.tls=true
- traefik.http.routers.cra-preview-master.tls.certresolver=le
# 一定要与 traefik 在同一网络下
networks:
default:
external:
name: traefik_default
# 将代理文件进行环境变量替换后,再次输出为 temp.docker-compose.yaml 配置文件
$ cat preview.docker-compose.yaml | COMMIT_REF_NAME=$(git rev-parse --abbrev-ref HEAD) envsubst > temp.docker-compose.yaml
# 根据配置文件启动容器服务
$ docker-compose -f temp.docker-compose.yaml up --build在我们实施了 Preview/Production 后,我们希望可以看到在 PR 的评论或者其它地方可以看到我们的部署地址。这就是 Environtment。
在 CI 中配置 environment 为期望的部署地址,则可以在每次部署成功后,便可以看到其地址。
environment:
name: review/$COMMIT_REF_NAME
url: http://$COMMIT_REF_NAME.cra.shanyue.tech
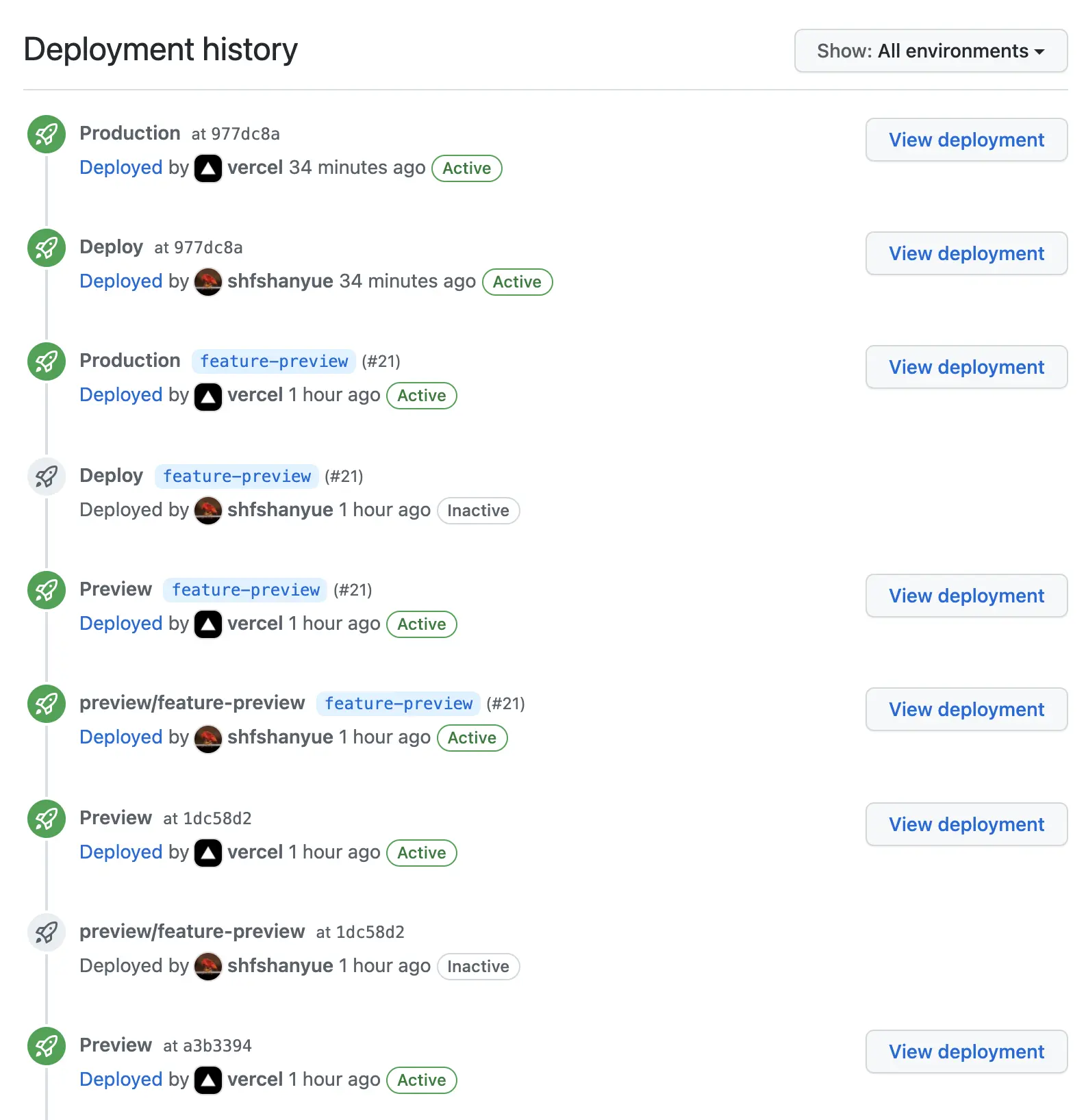
而在 Github 中,你甚至可以看到每个 Environment 的部署历史。
在 CICD 中可根据环境变量获取当前分支名,详情可参考上一篇文章: CI 中的环境变量。
在 Gitlab CI 中可以通过环境变量 CI_COMMIT_REF_SLUG 获取,该环境变量还会做相应的分支名替换,如 feature/A 到 feature-a 的转化。
在 Github Actions 中可以通过环境变量 GITHUB_REF_NAME/GITHUB_HEAD_REF 获取。
CI_COMMIT_REF_SLUG: $CI_COMMIT_REF_NAME lowercased, shortened to 63 bytes, and with everything except 0-9 and a-z replaced with -. No leading / trailing -. Use in URLs, host names and domain names.
以下是一个基于 github actions 的多分支部署的简单示例:
PS: 该 CI 配置位于 cra-deploy/preview.yaml
# 为了试验,此处作为单独的 Workflow,在实际工作中可 Install -> Lint、Test -> Preview 串行检验
name: Preview
# 执行 CI 的时机: 当 git push 到 feature-* 分支时
on:
push:
branches:
- feature-*
# 执行所有的 jobs
jobs:
preview:
# 该 Job 在自建的 Runner 中执行
runs-on: self-hosted
environment:
# 获取 CICD 中的变量: Context
# https://docs.github.com/en/actions/learn-github-actions/expressions
name: preview/${{ github.ref_name }}
url: https://${{ github.ref_name }}.cra.shanyue.tech
steps:
# 切出代码,使用该 Action 将可以拉取最新代码
- uses: actions/checkout@v2
- name: Preview
run: |
cat preview.docker-compose.yaml | envsubst > docker-compose.yaml
docker-compose up --build -d cra-preview-${COMMIT_REF_NAME}
env:
COMMIT_REF_NAME: ${{ github.ref_name }}以下是一个基于 gitlab CI 的多分支部署的简单示例:
deploy-for-feature:
stage: deploy
only:
refs:
- /^feature-.*$/
script:
# 在 CI 中可直接修改为 docker-compose.yaml,因在 CI 中都是一次性操作
- cat preview.docker-compose.yaml | envsubst > docker-compose.yaml
- docker-compose up --build -d
# 部署环境展示,可在 Pull Request 或者 Merge Request 中直接查看
environment:
name: review/$CI_COMMIT_REF_NAME
url: http://$CI_COMMIT_REF_SLUG.cra.shanyue.tech当新建了一个功能分支,并将它 push 到仓库后,CI 将在测试环境部署服务器将会自动启动一个容器。即便该分支已被合并,然而该分支对应的功能分支测试地址仍然存在,其对应的容器也仍然存在。
而当业务迭代越来越频繁,功能分支越来越多时,将会有数十个容器在服务器中启动,这将造成极大的服务器资源浪费。
当然,我们可以将已经合并到主分支的功能分支所对应的容器进行手动停止,但是不够智能。
我们可以通过 CI 做这件事情: 当 PR 被合并后,自动将该功能分支所对应的 Docker 容器进行关停。
PS: 该 CI 配置位于 cra-deploy/stop-preview.yaml
# 为了避免服务器资源浪费,每次当 PR 被合并或者关闭时,自动停止对应的 Preview 容器
name: Stop Preview
on:
pull_request:
types:
# 当 feature 分支关闭时,
- closed
jobs:
stop-preview:
runs-on: self-hosted
steps:
# - name: stop preview
# # 根据 Label 找到对应的容器,并停止服务,因为无需代码,所以用不到 checkout
# run: docker ps -f label="com.docker.compose.service=cra-preview-${COMMIT_REF_NAME}" -q | xargs docker stop
- uses: actions/checkout@v2
- name: stop preview
run: |
cat preview.docker-compose.yaml | envsubst > docker-compose.yaml
docker-compose stop
env:
COMMIT_REF_NAME: ${{ github.head_ref }}PS: 本段内容需要对 k8s 有基本概念的了解,比如
Deployment、Pod、Service。可在下一篇章进行了解。
- Deployment: 对 cra-deploy 项目的部署视作一个 Deployment
- Service: 对 cra-deploy 提供可对集群或外网的访问地址
如此一来
- 根据分支名作为镜像的 Tag 构建镜像。如
cra-deploy-app:feature-A - 根据带有 Tag 的镜像,对每个功能分支进行单独的 Deployment。如
cra-deployment-feature-A - 根据 Deployment 配置相对应的 Service。如
cra-service-feature-A - 根据 Ingress 对外暴露服务并对不同的 Service 提供不同的域名。如
feature-A.cra.shanyue.tech
配置文件路径位于 k8s-preview-app.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: cra-deployment-${COMMIT_REF}
spec:
selector:
matchLabels:
app: cra
replicas: 3
template:
metadata:
labels:
app: cra
spec:
containers:
- name: cra-deploy
image: cra-deploy-app:${COMMIT_REF}
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: cra-service-${COMMIT_REF}
spec:
selector:
app: cra
ports:
- protocol: TCP
port: 80
targetPort: 80但是无论基于那种方式的部署,我们总是可以在给它封装一层来简化操作,一来方便运维管理,一来方便开发者直接接入。如把部署抽象为一个命令,我们这里暂时把这个命令命名为 deploy,deploy 这个命令可能基于 kubectl/heml 也有可能基于 docker-conpose。
该命令最核心 API 如下:
$ deploy service-name --host :host假设要部署一个应用 shanyue-feature-A,设置它的域名为 feature-A.dev.shanyue.tech,则这个部署前端的命令为:
$ deploy shanyue-feature-A --host feature-A.dev.shanyue.tech现在只剩下了一个问题:找到当前分支。
随着 CICD 的发展、对快速迭代以及代码质量提出了更高的要求,基于分支的分支测试环境则成为了刚需。
对于该环境的搭建,思路也很清晰
- 借用现有的 CICD 服务,如
github actions或者gitlab CI获取当前分支信息 - 借用 Docker 快速部署前端或者后端,根据分支信息启动不同的服务,根据 Docker 启动服务并配置标签
- 根据容器的标签与当前 Git 分支对前端后端设置不同的域名
另外,这个基于容器的思路不仅仅使用于前端,同样也适用于后端。而现实的业务中复杂多样,如又分为已下几种,这需要在项目的使用场景中灵活处理。
feature-A的前端分支对应feature-A的后端分支环境feature-A的前端分支对应develop的后端分支环境feature-A的前端分支对应master的后端分支环境
在前边章节中,我们了解了如何部署容器化的前端应用,并可通过 CICD 进行自动化部署。
- 如何进行版本回退
- 如何进行流量控制
在 kubernetes 集群中很容易做到这些事情,本篇文章中绝大部分为运维所做工作,但前端仍需了解。
k8s 搭建需要多台服务器,且步骤繁杂,前端开发者很难有条件购买多台服务器。因此山月推荐以下两种途径学习 k8s:
- 在本地搭建 minikube
- 在官网 Interactive Tutorials 进行学习,它提供了真实的 minikube 环境
- Katacoda 的 Kubernetes Playground
Pod 是 k8s 中最小的编排单位,通常由一个容器组成。
Deployment 可视为 k8s 中的部署单元,如一个前端/后端项目对应一个 Deployment。
Deployment 可以更好地实现弹性扩容,负载均衡、回滚等功能。它可以管理多个 Pod,并自动对其进行扩容。
以我们开始的示例项目 create-react-app 为例,我们在以前章节通过 docker-compose 对其进行了部署。
这次编写一个 Deployment 的资源配置文件,在 k8s 上对其部署。
在部署我们项目之前,先通过 docker build 构建一个名称为 cra-deploy-app 的镜像。
$ docker build -t cra-deploy-app -f router.Dockerfile .
# 实际环节需要根据 CommitId 或者版本号作为镜像的 Tag
$ docker build -t cra-deploy-app:$(git rev-parse --short HEAD) -f router.Dockerfile .我们将配置文件存为 k8s-app.yaml,以下是配置文件个别字段释义:
配置文件路径位于 k8s-app.yaml
spec.template: 指定要部署的 Podspec.replicas: 指定要部署的个数spec.selector: 定位需要管理的 Pod
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: cra
replicas: 3
template:
metadata:
labels:
app: cra
spec:
containers:
- name: cra-deploy
image: cra-deploy-app
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80我们使用 kubectl apply 部署生效后查看 Pod 以及 Deployment 状态。
其中每一个 Pod 都有一个 IP,且应用每次升级后 Pod IP 都会发生该表,那应该如何配置该应用对外访问?
$ kubectl apply -f k8s-app.yaml
$ kubectl get pods --selector "app=cra" -o wide
NAME READY STATUS RESTARTS AGE IP
cra-deployment-555dc66769-2kk7p 1/1 Running 0 10m 172.17.0.8
cra-deployment-555dc66769-fq9gd 1/1 Running 0 10m 172.17.0.9
cra-deployment-555dc66769-zhtp9 1/1 Running 0 10m 172.17.0.10
# READY 3/3 表明全部部署成功
$ kubectl get deploy cra-deployment
NAME READY UP-TO-DATE AVAILABLE AGE
cra-deployment 3/3 3 3 42m从上述命令,列出其中一个 Pod 名是 cra-deployment-555dc66769-zhtp9。
其中 cra-deployment 是 Deployment 名,而该前端应用每次上线升级会部署一个 Replica Sets,如本次为 cra-deployment-555dc66769。
Service 可通过 spec.selector 匹配合适的 Deployment 使其能够通过统一的 Cluster-IP 进行访问。
apiVersion: v1
kind: Service
metadata:
name: cra-service
spec:
selector:
# 根据 Label 匹配应用
app: cra
ports:
- protocol: TCP
port: 80
targetPort: 80根据 kubectl get service 可获取 IP,在 k8s 集群中可通过 curl 10.102.82.153 直接访问。
$ kubectl get service -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
cra-service ClusterIP 10.102.82.153 <none> 80/TCP 10m app=cra
$ curl --head 10.102.82.153
HTTP/1.1 200 OK
Server: nginx/1.21.4
Date: Mon, 14 Feb 2022 04:46:24 GMT
Content-Type: text/html
Content-Length: 644
Last-Modified: Wed, 26 Jan 2022 10:10:51 GMT
Connection: keep-alive
ETag: "61f11e2b-284"
Expires: Mon, 14 Feb 2022 04:46:23 GMT
Cache-Control: no-cache
Accept-Ranges: bytes而且,所有的服务可以通过 <service>.<namespace>.svc.cluster.local 进行服务发现。在集群中的任意一个 Pod 中通过域名访问服务
# 通过 kebectl exec 可进入任意 Pod 中
$ kubectl exec -it cra-deployment-555dc66769-2kk7p sh
# 在 Pod 中执行 curl,进行访问
$ curl --head cra-service.default.svc.cluster.local
HTTP/1.1 200 OK
Server: nginx/1.21.4
Date: Mon, 14 Feb 2022 06:05:41 GMT
Content-Type: text/html
Content-Length: 644
Last-Modified: Wed, 26 Jan 2022 10:10:51 GMT
Connection: keep-alive
ETag: "61f11e2b-284"
Expires: Mon, 14 Feb 2022 06:05:40 GMT
Cache-Control: no-cache
Accept-Ranges: bytes对外可通过 Ingress 或者 Nginx 提供服务。
如何进行回滚?
那我们可以对上次版本重新部署一遍。比如在 Gitlab CI 中,我们可以通过点击升级前版本的手动部署按钮,对升级前版本进行重新部署。但是,此时流程有点长。
此时可以使用 kubectl rollout 直接进行回滚。
$ kubectl rollout undo deployment/nginx-deployment本文仅仅是对 k8s 的相关概念做了一个简单的概述,如果寻求更复杂的部署策略可前往k8s-deployment-strategies。