Lora and Dora finetuning produces identical results #2250
Comments
|
Hi @AndrewMead10 thanks for creating the issue. I am able to repro this, dug in a bit and can see that the DoRA magnitudes are not being updated across iterations. I need to do some further investigation, will keep you posted on my findings. But I think this should be pretty high-priority for us to figure out. Also tagging @SLR722 and @calvinpelletier who are familiar with this code to possibly take a look. |
|
Hey @AndrewMead10 thanks for your patience while I investigated this. I think this is a legit bug. I need to do some more investigation but here's what I've found so far: post-#1909 we stopped updating the DoRA magnitudes during training, which is why you're seeing identical loss curves across DoRA and LoRA. That PR fixed another issue where we were seeing NaN losses on DoRA runs (see #1903). However, I think it did not actually fix the root cause.. if you note the second item in that issue you will see that I observed NaN loss when training Llama 3.2 Vision with DoRA. Interestingly the NaN loss occurs only for certain models (e.g. you can check out the commit just before #1909 and run Llama 3 8B with DoRA without any NaNs). Actually Llama 3.1 is an interesting example, because the NaN losses actually started sometime after our initial DoRA PR (#1115). I bisected and found that #1554 is the offending PR. I need to look a bit more closely to figure out the root cause and the right fix but wanted to give you the update so far. So please bear with us while we unwind this and figure out the right fix. But really appreciate you surfacing this critical bug to us. |
|
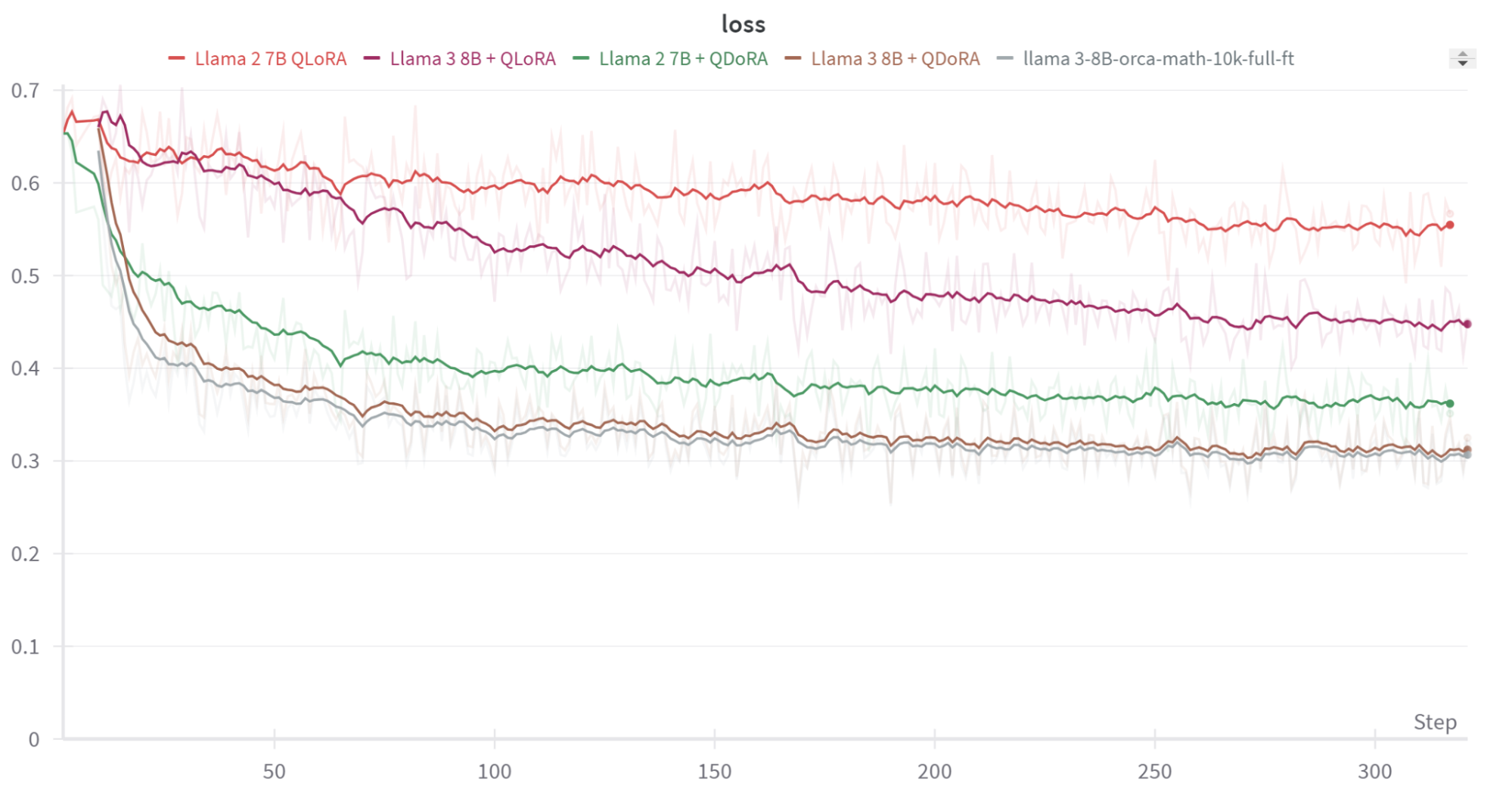
@AndrewMead10 thanks for your patience, this has been a bit of a pain to figure out. TLDR: Use fp32, not bf16. Otherwise DoRA's magnitude vector may not actually update for small learning rates due to numerical precision issues. Full explanation follows. I mentioned the PR #1554 previously -- this is actually not the source of the bug. However, it did expose that (at that time) we were not properly initializing the DoRA magnitude params. This is kind of an aside from DoRA and doesn't impact what you're seeing, but we shouldn't use our As for the behavior you're observing, I now understand the actual issue. When I previously said that "we stopped updating the DoRA magnitudes during training after #1909", that actually was not correct. In fact, we have always been updating the DoRA magnitudes in theory, but after #1909 we stopped updating them in practice. To explain what I mean: the pre-#1554 DoRA magnitudes were visibly updating during training. But this was actually only because they were not properly initialized and so their gradients were quite large. Our default DoRA config uses full-bf16 training, so all model weights are kept in bf16. By cranking up our learning rate to 
The above figure contains three runs using our
The disadvantage of (2) is that it's slower and uses more memory, but it's probably the most accurate. If you have memory to spare (which you would for 1B on a 3090), then maybe mixed precision is the way to go. We don't currently support it (historically we focus a lot on memory efficiency, hence why full-bf16 is our default), but given other requests like #2267 it's something we could look into adding. Separately it's possible that we can update our default configs to a higher learning rate. All of the above needs a bit more experimentation prior to landing the changes. But pending reasonable results I would hope to land some version of (3) to balance memory/training time vs model quality. |
|
@ebsmothers thank you for looking into this so deeply, but this doesnt seem right to me; the magnitude vector should not be very small where numerical properties of the dtype are preventing it from learning. You can see in the graph shown in the answer.ai post that dora and lora diverge quite a bit very early on in the training. Based on your loss graph it is still acting identical to lora, the small changes are most likely due to numerical precision differences but we see no actual change in the loss over time. I compared the torchtune impl of dora with the answer.ai one, but it seem like (for the first step anyway) your results match. Comparison code here. Also of note is they did not run into/mention any dtype issue when training with dora, which seems to support the hypothesis that this is not the issue. The dataset that have config'd up above is a subset of the one that they use in their post, which is why i have been using it for testing. I am busy the next few days, but I want to run the same training in the qlora_fsdp repo and see if the training is the same or not there as well and then going from there. My guess is that the magnitude layer is not being updated correctly. I also slapped my dora layer comparison pretty quick as well, so i would want to double check that also. |
{kind=link}
|
Thanks @AndrewMead10 for continuing to push for answers here; I do think there's still more to sort out. Personally I'm not so familiar with the answer.ai implementation, but we have run pretty extensive comparisons to Hugging Face (which in fact is where the official DoRA repo currently points). When I was first looking into this I actually checked the HF implementation as well -- I've attached some loss curves below and you can see the behavior is closer to what we see in torchtune than what's on the answer.ai blog. Happy to share a script to reproduce if that's helpful. 
Separately, we also did parity checks against the Hugging Face implementation prior to landing the initial code. We have a test running in our CI for this, and the value you see there was set by running forward on the version in PEFT to ensure things line up (see this intermediate commit comparing a full forward/backward pass). Of course this is still not a full training run (hence why we missed the grad underflow issue), but just want to make it clear that we have done pretty extensive testing against another known implementation. Also, just to clarify one point: the issue is not that the magnitude vector itself is small, it's actually of a reasonable size (individual elements around O(1) in the layers I was inspecting). The grads of the magnitude vector are small though, so when we multiply by a small LR we wind up not actually updating the params. Let me take a closer look at the answer.ai implementation to see if I can figure out where the divergence is occurring. |
I was trying to compare lora, dora, and full finetuning on llama 1B, but i found that lora and dora finetuning produced identical results. I am using the orca 10k dataset, like they did in the answer.ai post comparing the 2 methods.
here is the wandb report for the runs
here is my config file, the only thing that i changed between runs was the use_dora field from true to false. The command i ran was
tune run lora_finetune_single_device --config benchmark_methods/llama_3_2_1b_lora_adam.yamlI am using a 3090 gpu.
The text was updated successfully, but these errors were encountered: