Nesse artigo descreverei algumas ferramentas importantes e rotinaieras na vida de um cientista de dados. Será abordado a funcionalidade e aplicações práticas de cada uma delas. Além disso, trechos de sintaxe das ferramentas será descrito para recorrer ao artigo quando necessária a consulta.
- Numpy
- Pandas
- Matplotlib
- Seaborn
- Requests
- BeautifulSoup
- SQLAlchemy
- Keras
- OpenRefine
- One Hot Encode
- Glob
- Links Úteis
Numpy é o principal pacote para desenvolvimento de projetos utilizando ciência dos dados, em Python.
- Traz a facilidade de criação de arrays N-dimensionais, com o intuito de otimizar cálculos;
- Pode utilizar a maioria dos operadores lógicos e matemáticos presentes no Python;
- (continuar)
- (continuar)
Algumas funcionalidades importantes:
import numpy as np
np_array= np.array([1, 2, 3],
[4, 5, 6])
# Soma de todos os elementos
np_array.sum()
# Encontra o menor valor no array
np_array.min()
# Encontra o maior valor no array
np_array.max()
# Cria um array 3x4 com 12 elementos
np_array = np.arange(12).reshape(3, 4)
# Os valores acima de 4 recebem True
b_bool = np_array > 4
# Imprime apenas os valores True
print(np_array[b_bool])
output: array([5, 6, 7, 8, 9, 10, 11])
# Melhor utilizar Pandas para essa aplicação
data = np.genfromtxt('file.csv', delimiter=',', names=True, dtype=None)
O primeiro argumento é o nome do arquivo, o segundo especifica da delimitação, o terceiro diz que tem um Header e o quarto diz que o tipo é None (qualquer um).
- Utilizar arrays de apenas um tipo (int, float, string), e de preferência valores numéricos, não mesclando-os.
Pandas incorpora na linguagem Python um ambiente completo para análise de dados, sem a necessidade de utilizar outra liguagem específica, como R.
Algumas funcionalidades importantes:
import pandas as pd
# Ler documentos
file = pd.read_csv('file.csv', nrows=5) # Número de linhas q irá salvar
file = pd.read_json('file.json', header=None) # Sem Header
file = pd.read_excel('file.xml', sep='\t') # Separado por Tab
file = pd.read_html('file.html', na_values='Nothing') # NA/NaN valores viram Nothing
# Escrever em documentos
file = pd.to_csv('file.csv')
file = pd.to_json('file.json')
file = pd.to_excel('file.xml')
file = pd.to_html('file.html')
Loc e Iloc são métodos para encontrar valores em tabelas. Com o .loc passa-se o nome da linha e depois o da coluna (.loc['linha', 'coluna']) equanto que o .iloc passa-se o index da linha e da coluna (iloc[nlinha, ncoluna]), retornado nos dois casos o valor desejado. O tempo de processamento utilizando esses métodos é mais rápido que da maneira usual (tabela['coluna']['linha']).
Consiste na junção de dados (colunas para linhas) de uma tabela para facilitar sua análise. Em pandas a função .melt() faz esse trabalho.
Consiste na separação de dados (linhas para colunas) de uma tabela para facilitar sua análise. No pandas usa-se a função .pivot_table().
Muitas vezes, um mesmo tipo de dado pode vir em diferentes tabelas, em diferentes arquivos e podemos afzer ajunção deles em uma só tabela utilizando Pandas. Para isso, existe a função pd.concat(). Passando uma lista de tabelas, ela faz a concatenação destas, deixando todos os dados intactos, até mesmo o 'id', podendo existir mais de um indice por linha, Para isso, existe o parâmetro ignore_index=True que rearranja os id's.
Existem casos em que tabelas não estão organizadas da mesma forma que outras, portanto, sua concatenação gerará problemas, juntando linhas erroneamente. Pandas dispõem uma função pd.merge(left=tabela_esquerda, right=tabela_direita, left_on='nome_coluna', right_on='nome_coluna'). Ela permite informar quais colunas devem ser analisadas para a fusão ocorrer perfeitamente.
Existem 3 tipos diferentes de fusão de tabelas, todas usam a mesma função:
- One-to-one: Os valores das colunas aparecem apenas uma vez em cada uma das tabelas.
- Many-to-one / one-to-many: Os valores de uma das tabelas repete mais de uma vez, duplicando, na hora da fusão, os valores da tabela que tem valores únicos.
- Many-to-many: Os valores das tabelas que serão fundidas contém elementos com o mesmo nome.
São muitas as possibilidades para se juntar tabelas em Pandas, cada possibilidade com suas vantagens. Abaixo, demonstrarei os tipos existentes e seus usos.
- .append(): Método mais simples, apenas juntando uma tabela com a outra verticalmente, não lidando com índices iguais e outros problemas, faz um 'outer join'.
- .concat([]): Com ele é possível concatenar DataFrames tanto verticalmente quanto horizontalmente, com 'inner join' ou 'outer join'. É um método mais completo, podendo fazr mais modificações e melhorias na hora da agrgação.
- .join(): Disponiliza agrupar utilizando 'inner', 'outer', 'left', 'right join'.
- .merge([]): A função merge pertime vários 'joins' em múltiplas colunas.
import matplotlib.pyplot as plt
pd.DataFrame.hist(data) # data.hist() -> outra formar
# Nome do eixo X
plt.xlabel('Age (years)')
# Nome do eixo Y
plt.ylabel('count')
plt.show()
Disponibiliza uma interface para busca de dados na internet
import requests
url = "https://github.com/"
# Manda uma requisição para a url e pega a resposta
r = requests.get(url)
# Retorna para 'text' o html da página
text = r.text
Analiza e extrai estruturas de dados do HTML
# Importar bibliotecas
import requests
from bs4 import BeautifulSoup
# Manda uma requisição para a url e pega a resposta
r = requests.get('https://www.python.org/~guido/')
# Extrai o HTML
html_doc = r.text
# Cria um objeto BeautifulSoup do HTML
soup = BeautifulSoup(html_doc)
# Imprime o título da página
print(soup.title)
# Encontra todas as tags 'a'
a_tags = soup.find_all('a')
# Imprime as URLs das tags 'a'
for link in a_tags:
print(link.get('href'))
É uma ferramenta SQL open source para Python que disponibiliza o diálogo entre a linguagem e o banco de dados SQL. Funciona com diversos sistemas relacionais, como SQLite, PostgreSQL e MySQL.
# Importar a biblioteca
from sqlalchemy import create_engine
import pandas as pd
# Criar uma conexão com o banco SQLite
engine = create_engine('sqlite:///Northwind.sqlite')
# 'With as' é útil para não necessitar fechar a conexão após o uso do banco
with engine.connect() as con:
# Atribuir a execução do comando para 'rs'
rs = con.execute('SELECT OrderID, OrderDate, ShipName FROM Orders')
# Criar tabela com todos os dados até a linha 5
df = pd.DataFrame(rs.fetchmany(size=5))
# Atribuir nome as colunas da tabela
df.columns = rs.keys()
# OU
# Com uma linha você pode fazer a mesma coisa
df = pd.read_sql_query('SELECT OrderID, OrderDate, ShipName FROM Orders', engine)
Keras é uma biblioteca open source de redes neurais escrita em Python.
- OpenRefine é uma ferramenta desktop open-source criada pela Google para limpeza e análise de dados. Com ela, pode-se corrigir erros de tabelas, arquivos .csv e visualizar padrões em gráficos. Uma alternativa válida para pequenos projetos e ou pessoais.
-
Machine learning não trabalha com dados categóricos diretamente, eles precisam ser convertidos para números. Isso se aplica quando se está trabalhando com um problema de classificação e planeja usar estratégias de Deep Leaning como Long Short-Term Memory. Para conversão desses dados existe uma técnica chamada One Hot Encoding, que é a representação do dado como um vetor binario de 0's e apenas um 1.
-
Com a biblioteca Scikit-Learn e Numpy da pra transformar o texto em One Hot Encoding facilmente.
Exemplo:
from numpy import array
from numpy import argmax
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import OneHotEncoder
# define example
data = ['cold', 'cold', 'warm', 'cold', 'hot', 'hot', 'warm', 'cold', 'warm', 'hot']
values = array(data)
print(values)
# integer encode
label_encoder = LabelEncoder()
integer_encoded = label_encoder.fit_transform(values)
print(integer_encoded)
# binary encode
onehot_encoder = OneHotEncoder(sparse=False)
integer_encoded = integer_encoded.reshape(len(integer_encoded), 1)
onehot_encoded = onehot_encoder.fit_transform(integer_encoded)
print(onehot_encoded)
# invert first example
inverted = label_encoder.inverse_transform([argmax(onehot_encoded[0, :])])
print(inverted)
OneHotEncoder scikit-learn API documentation
LabelEncoder scikit-learn API documentation
- Como alternativa, a lib Keras tem disponível uma função chamada to_categorical() que faz One Hot Encode em inteiros.
Exemplo:
from numpy import array
from numpy import argmax
from keras.utils import to_categorical
# define example
data = [1, 3, 2, 0, 3, 2, 2, 1, 0, 1]
data = array(data)
print(data)
# one hot encode
encoded = to_categorical(data)
print(encoded)
# invert encoding
inverted = argmax(encoded[0])
print(inverted)
O Glob é uma biblioteca built-in do python que encontra todos os arquivos de uma pasta dado um padrão de busca previamente exigido.
import glob
# Padrão exigido
pattern = '*.zip'
# Define em forma de lista todos os arquivos que seguem o padrão
zip_files = glob.glob(pattern)
print(zip_files)
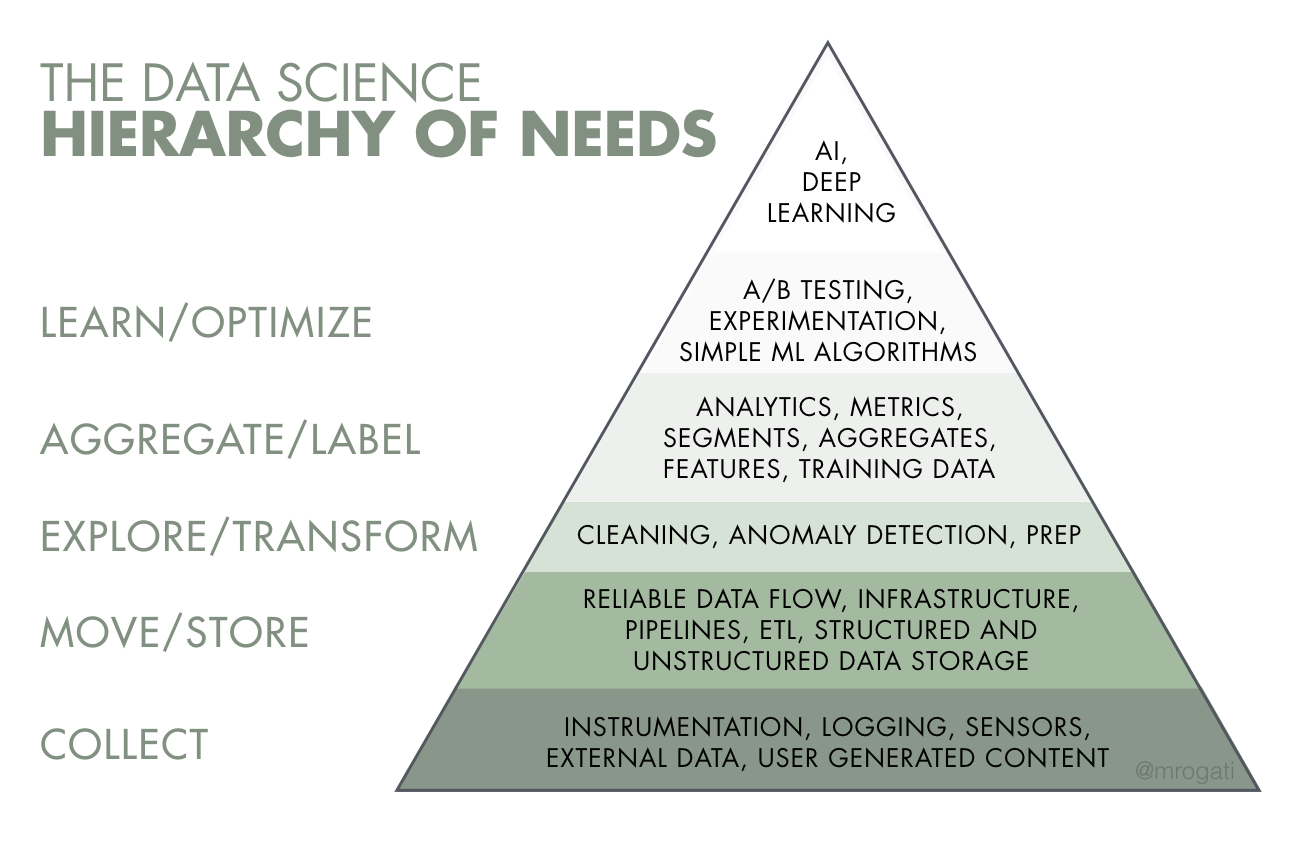
O Airflow é um framework criado pelo Airbnb para construir a parte ETL (Extract, Transform, Load) do sistema. É uma ferramenta para manipulação da base da piramide de Ciência dos Dados. su
{kind=link}
- What is one-hot encoding and when is it used in data science?
- Data Preparation for Gradient Boosting with XGBoost in Python
- Multi-Class Classification Tutorial with the Keras Deep Learning Library
- Data Engineering: Como cientista de dados, os engenheiros de dados escrevem código, são muito analíticos e interessados em visualização de dados. Não como cientistas de dados, mas como engenheiros de software, os engenheiros de dados controem ferramentas, infraestruturas, frameworks e serviços. Pode-se dizer que engenheiros de dados são mais parecidos com engenheiros de software do que com cientista de dados.
- Data Modeling: Essa parte do desenvolvimento se baseia na ideia de modelar os dados, reorganizando tabelas e bases de dados, utilizando padrões de projetos e demais técnicas.
- Data Partitioning: a ideia básica da partição de dados é simples - ao invés de armazenar todos os dados em um chunk, quebra-se em chunks independentes e self-contained. Data from the same chunk will be assigned with the same partition key, which means that any subset of the data can be looked up extremely quickly. This technique can greatly improve query performance.
- Data Warehouse
- Data Infrastructure
- Data Collection: É a base da pirâmide de hierarqioa de ciência dos dados. Responsável por responder algumas perguntas, tais como: quais dados você precisa, e quais estãp disponíveis? Se existe um produto-usuário, você está explorando todas as interações relevantes qa o usuário esá fazendo? Se tem um sensor, quais dados estão sendo recebidos e como? O quão díficil é explorar uma interação que ainda não foi realizada? Após isso, como que os dados estão percorrendo ao longo do sistema? Você tem ETL? Onde você o armazena, e quão fácil é acessá-lo e analizá-lo.
- Star Schema: o Star Schema é um padrão de projetos utilizado na área de modelagem de dados, com foco em construir fact and dimension tables, especificamente tabelas dimensionais.