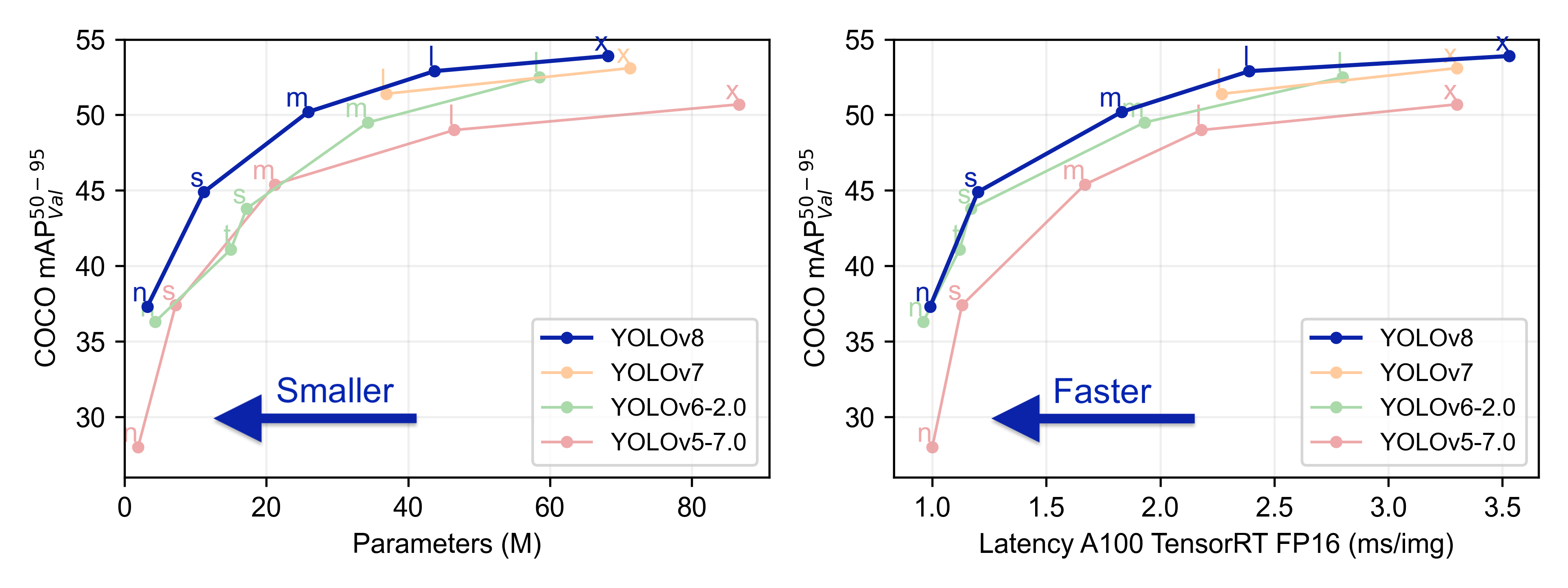
Ultralytics YOLOv8, developed by Ultralytics, is a cutting-edge, state-of-the-art (SOTA) model that builds upon the success of previous YOLO versions and introduces new features and improvements to further boost performance and flexibility. YOLOv8 is designed to be fast, accurate, and easy to use, making it an excellent choice for a wide range of object detection, image segmentation and image classification tasks.
performance tested on Ascend 910(8p) with graph mode
| Name | Scale | BatchSize | ImageSize | Dataset | Box mAP (%) | Params | Recipe | Download |
|---|---|---|---|---|---|---|---|---|
| YOLOv8 | N | 16 * 8 | 640 | MS COCO 2017 | 37.2 | 3.2M | yaml | weights |
| YOLOv8 | S | 16 * 8 | 640 | MS COCO 2017 | 44.6 | 11.2M | yaml | weights |
| YOLOv8 | M | 16 * 8 | 640 | MS COCO 2017 | 50.5 | 25.9M | yaml | weights |
| YOLOv8 | L | 16 * 8 | 640 | MS COCO 2017 | 52.8 | 43.7M | yaml | weights |
| YOLOv8 | X | 16 * 8 | 640 | MS COCO 2017 | 53.7 | 68.2M | yaml | weights |
performance tested on Ascend 910*(8p)
| Name | Scale | BatchSize | ImageSize | Dataset | Box mAP (%) | ms/step | Params | Recipe | Download |
|---|---|---|---|---|---|---|---|---|---|
| YOLOv8 | N | 16 * 8 | 640 | MS COCO 2017 | 37.3 | 373.55 | 3.2M | yaml | weights |
| YOLOv8 | S | 16 * 8 | 640 | MS COCO 2017 | 44.7 | 365.53 | 11.2M | yaml | weights |
performance tested on Ascend 910(8p) with graph mode
| Name | Scale | BatchSize | ImageSize | Dataset | Box mAP (%) | Mask mAP (%) | Params | Recipe | Download |
|---|---|---|---|---|---|---|---|---|---|
| YOLOv8-seg | X | 16 * 8 | 640 | MS COCO 2017 | 52.5 | 42.9 | 71.8M | yaml | weights |
- Box mAP: Accuracy reported on the validation set.
- We refer to the official YOLOV8 to reproduce the P5 series model.
Please refer to the GETTING_STARTED in MindYOLO for details.
It is easy to reproduce the reported results with the pre-defined training recipe. For distributed training on multiple Ascend 910 devices, please run
# distributed training on multiple GPU/Ascend devices
msrun --worker_num=8 --local_worker_num=8 --bind_core=True --log_dir=./yolov8_log python train.py --config ./configs/yolov8/yolov8n.yaml --device_target Ascend --is_parallel TrueSimilarly, you can train the model on multiple GPU devices with the above msrun command. Note: For more information about msrun configuration, please refer to here.
For detailed illustration of all hyper-parameters, please refer to config.py.
Note: As the global batch size (batch_size x num_devices) is an important hyper-parameter, it is recommended to keep the global batch size unchanged for reproduction or adjust the learning rate linearly to a new global batch size.
If you want to train or finetune the model on a smaller dataset without distributed training, please run:
# standalone training on a CPU/GPU/Ascend device
python train.py --config ./configs/yolov8/yolov8n.yaml --device_target AscendTo validate the accuracy of the trained model, you can use test.py and parse the checkpoint path with --weight.
python test.py --config ./configs/yolov8/yolov8n.yaml --device_target Ascend --weight /PATH/TO/WEIGHT.ckpt
See here.
[1] Jocher Glenn. Ultralytics YOLOv8. https://github.com/ultralytics/ultralytics, 2023.