中文 • English





Compatible with Windows7 x64 and above
- Free: All the code of this project is open-source and completely free.
- Convenient: Unzip and use, run offline, no need for network.
- Efficient: Comes with a highly efficient offline OCR engine. As long as the computer performance is sufficient, it can be faster than online OCR services.
- Flexible: Supports customizable interface, and supports multiple calling methods such as command-line and HTTP API.
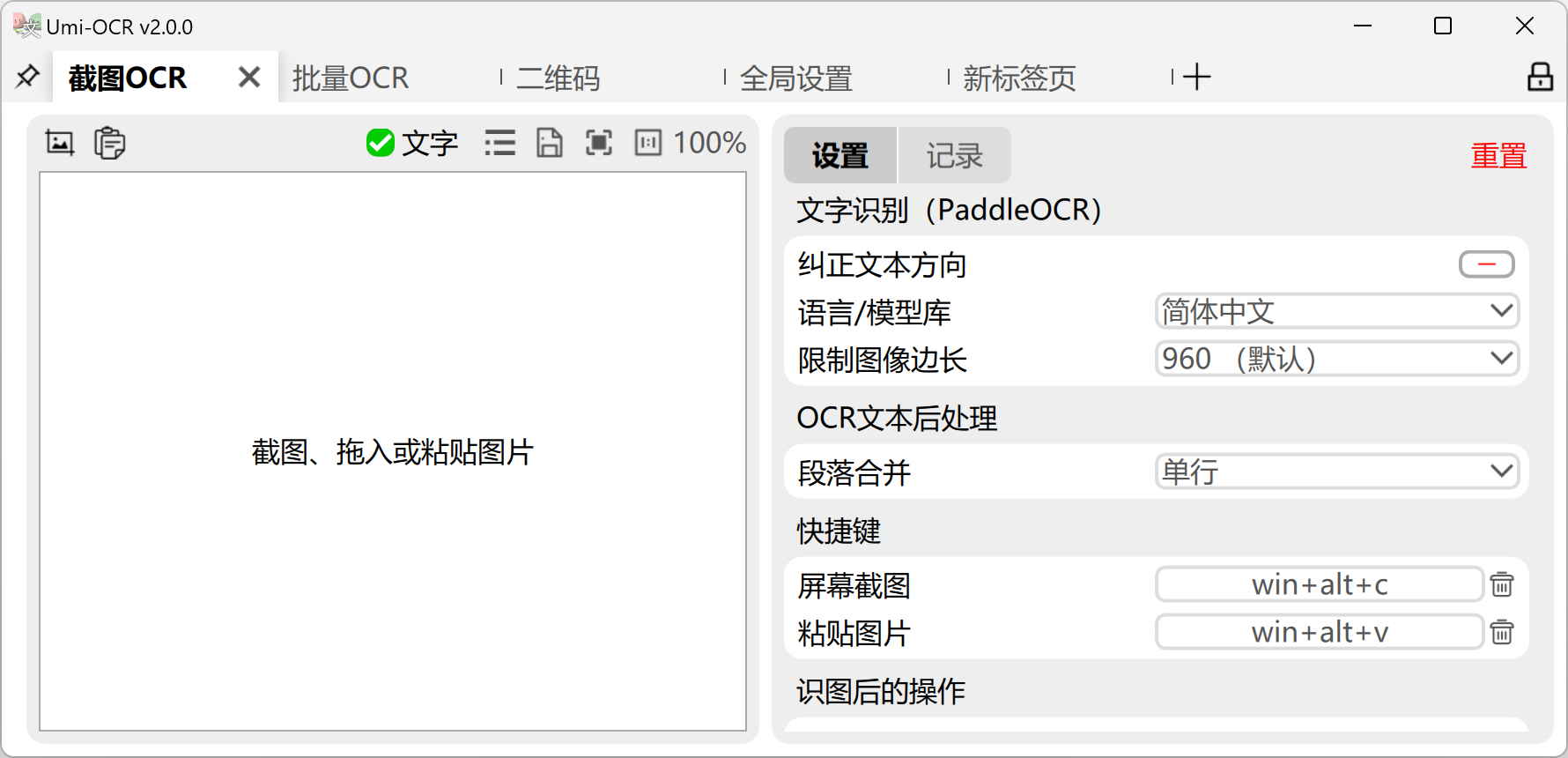
Developers should read Building the Project before proceeding.
The software release package is available in .7z compressed format or as a self-extracting .7z.exe package. The self-extracting package can be used to extract files on a computer without compression software installed.
This software does not require installation. After extraction, simply click on Umi-OCR.exe to start the program.
If you encounter any problems, please submit an Issue and I will do my best to assist you.
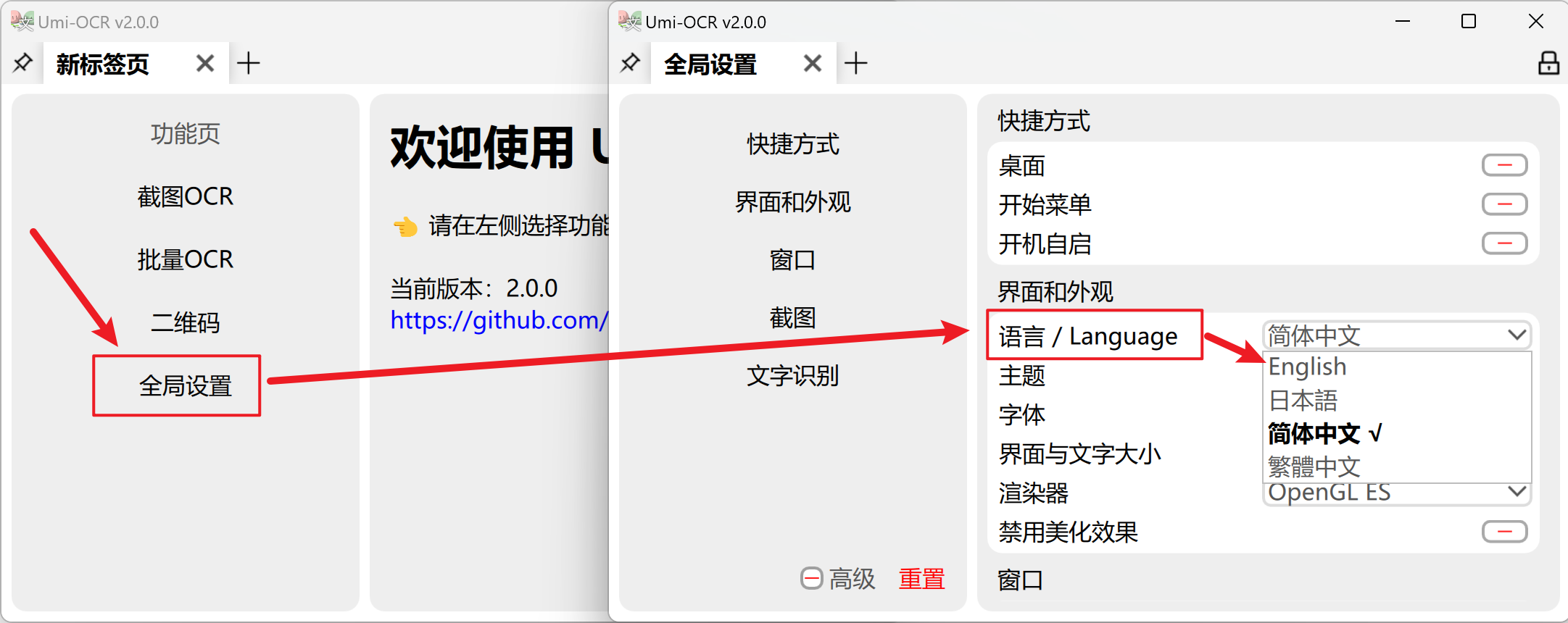
Umi-OCR supports multiple languages for its interface. When you open the software for the first time, it will automatically switch to the language based on your computer's system settings.
If you need to manually switch languages, please refer to the following figure, 全局设置→语言/Language .
- 翻译
Readme_en.md文档 - 翻译 软件界面
Umi-OCR v2 is composed of a series of flexible and easy-to-use tabbed interfaces. You can open the required tabbed interface according to your preferences.
The top left corner of the tab bar can be used to switch window always on top. The top right corner can be used to lock the tabbed interface to prevent accidental closure during daily use.
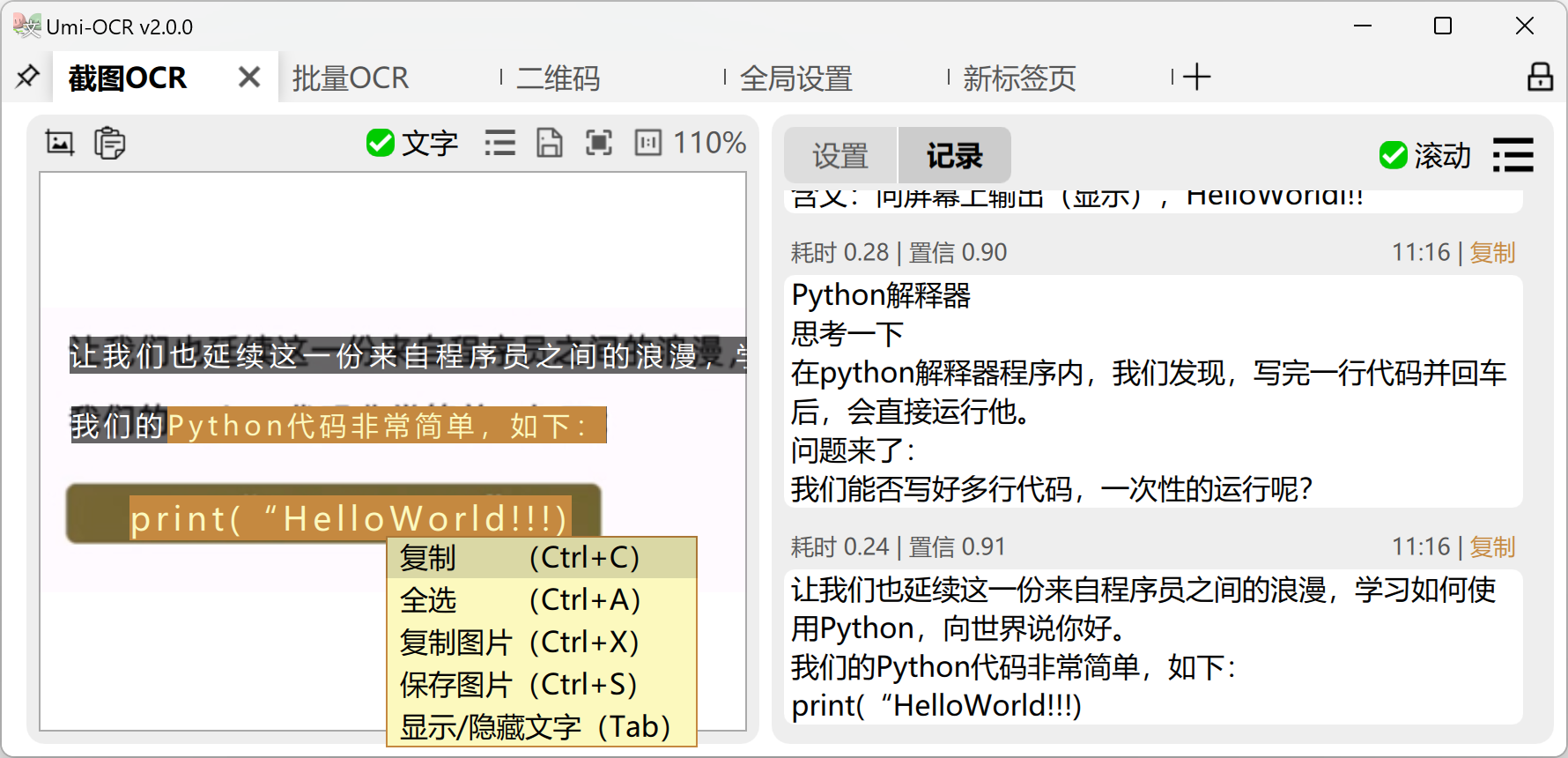
Screenshot OCR: After opening this page, you can use a keyboard shortcut to capture a screenshot and recognize the text in the image.
- The left-side image preview panel allows you to select and copy text with your mouse.
- The right-side recognition record panel allows you to edit text and select and copy multiple records.
- It also supports copying images from elsewhere and pasting them into Umi-OCR for recognition.
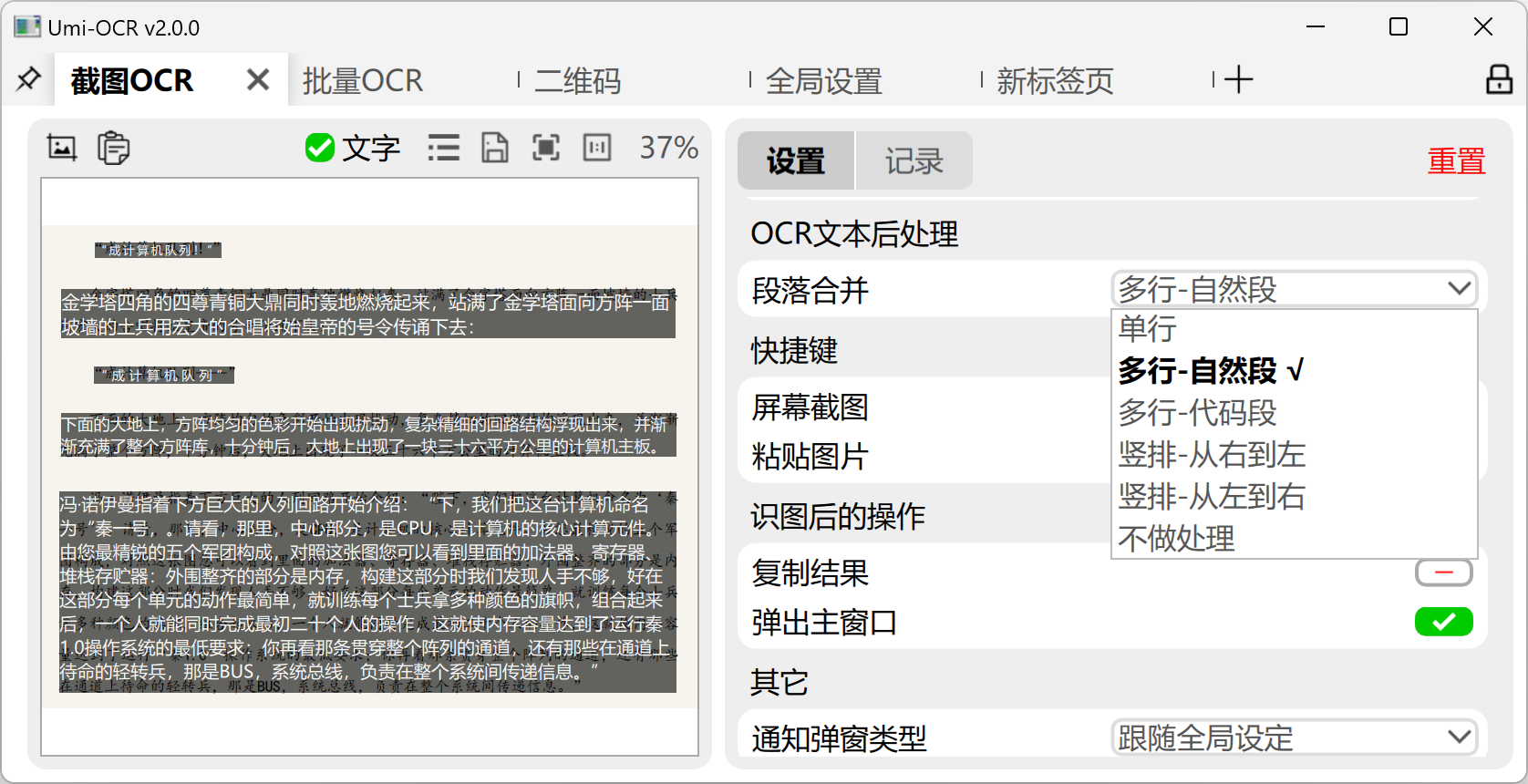
About OCR Text Post-Processing - Paragraph Merge: This feature can organize the layout and order of OCR results to make the text more suitable for reading and use. The preset schemes are:
- Single line: Merge text on the same line, suitable for most scenarios.
- Multiple lines - natural paragraphs: Intelligently recognize and merge text belonging to the same paragraph, suitable for most scenarios, as shown in the figure above.
- Multiple lines - code block: Try to restore the original indentation and spacing of the text. Suitable for recognizing code snippets or scenes that require retaining spaces.
- Vertical layout: Suitable for vertical layout. Needs to be used in conjunction with a model library that also supports vertical layout recognition.
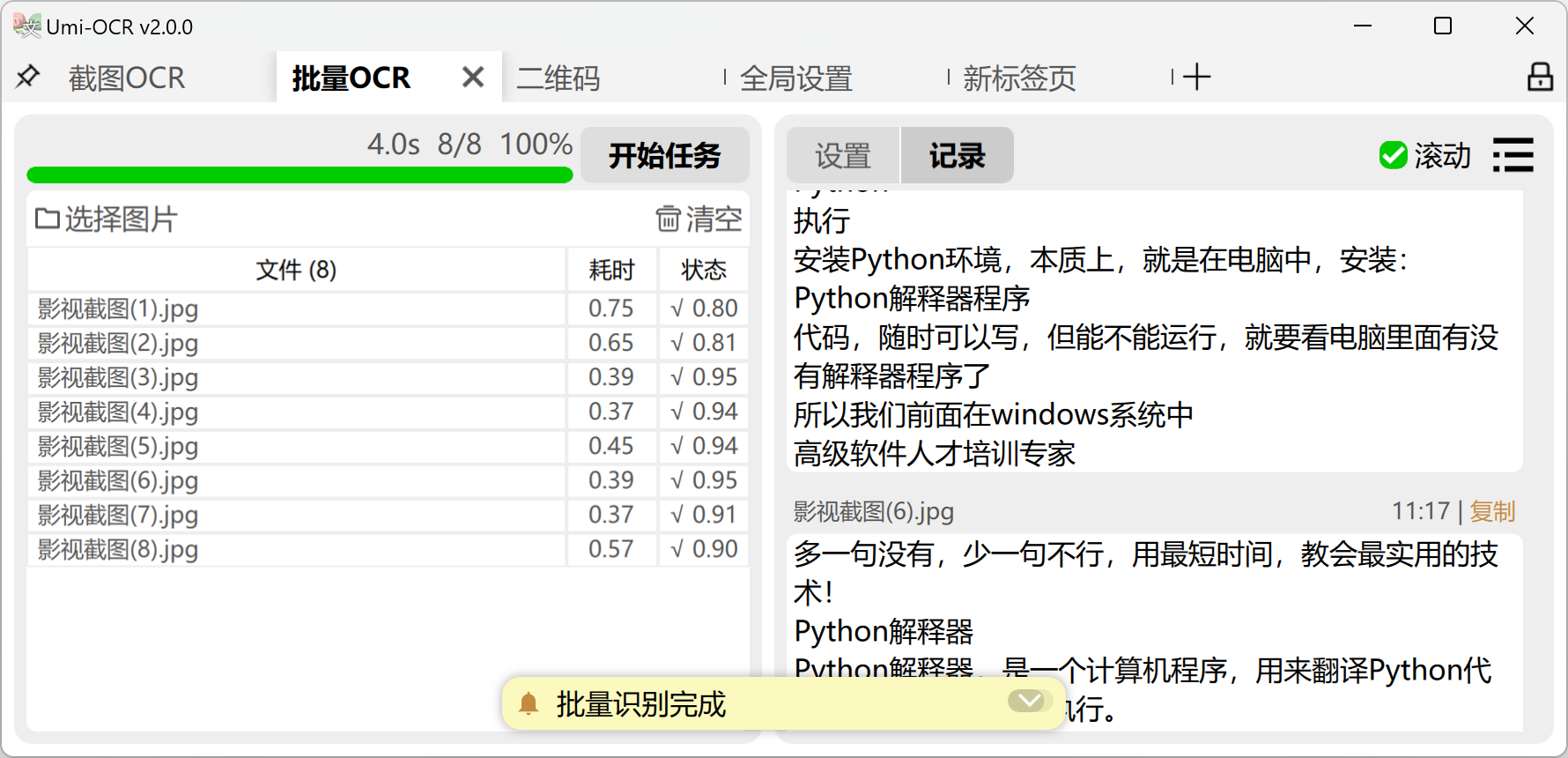
Batch OCR: This page supports batch importing local images for recognition.
- The recognized content can be saved in various formats such as txt/jsonl/md/csv(Excel).
- Supports
text post-processingtechnology, which can recognize text belonging to the same natural paragraph and merge it. It also supports multiple processing schemes such as code blocks and vertical text. - There is no limit on the number of images that can be imported for processing at one time, and the software can automatically shut down or sleep after completing the task.
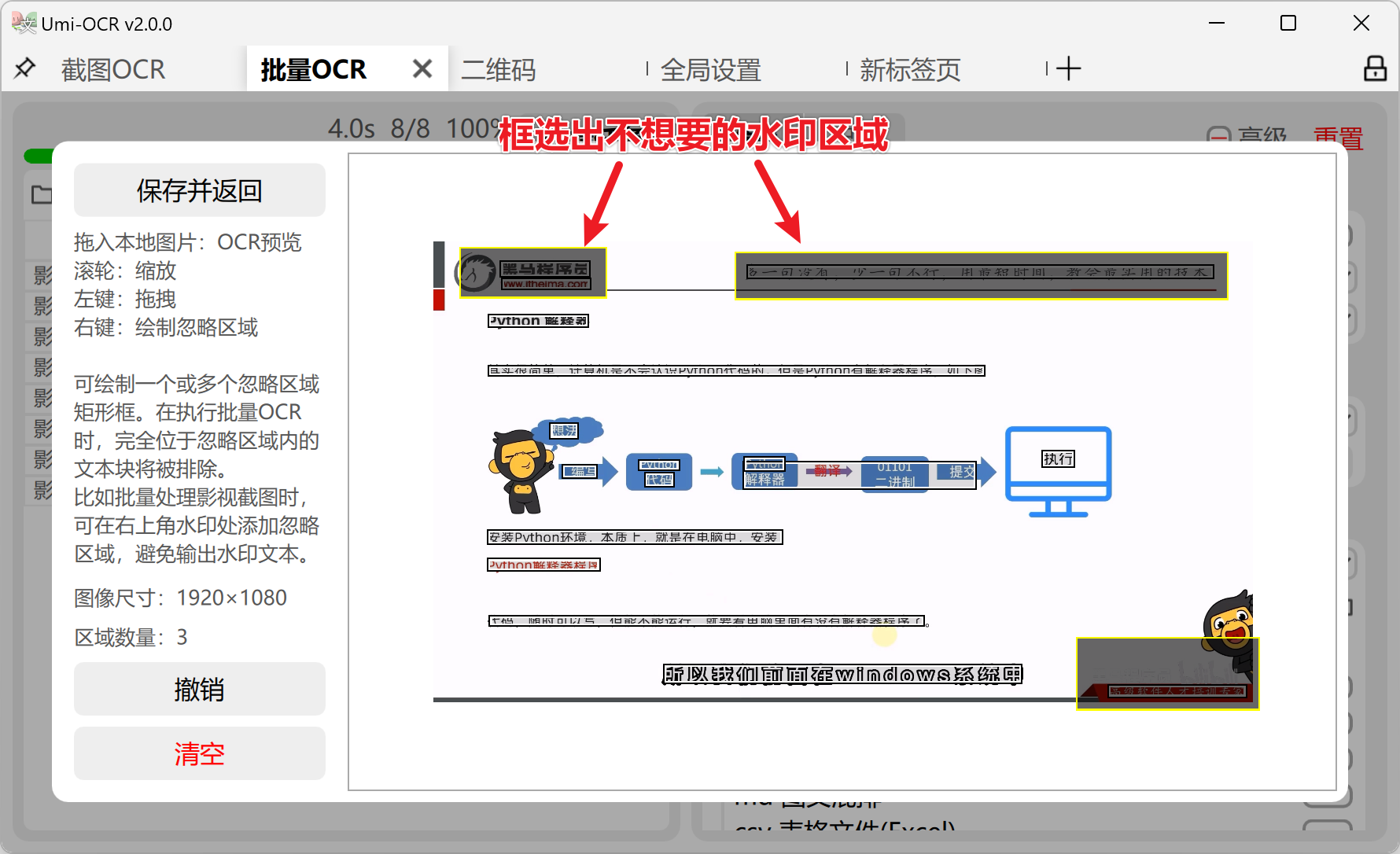
About OCR Text Post-Processing - Ignore Regions: This is a special function in batch OCR that is used to exclude unwanted text in images.
- The ignore region editor can be accessed in the right column of the batch recognition page settings.
- As shown in the example above, there are multiple watermarks/LOGOs at the top and bottom right corner of the image. If these images are recognized in batches, the watermarks will interfere with the recognition results.
- Hold down the right mouse button to draw multiple rectangular boxes. The text inside these areas will be ignored during the task.
- Please try to draw the rectangular boxes larger, completely wrapping all possible positions of the watermark.
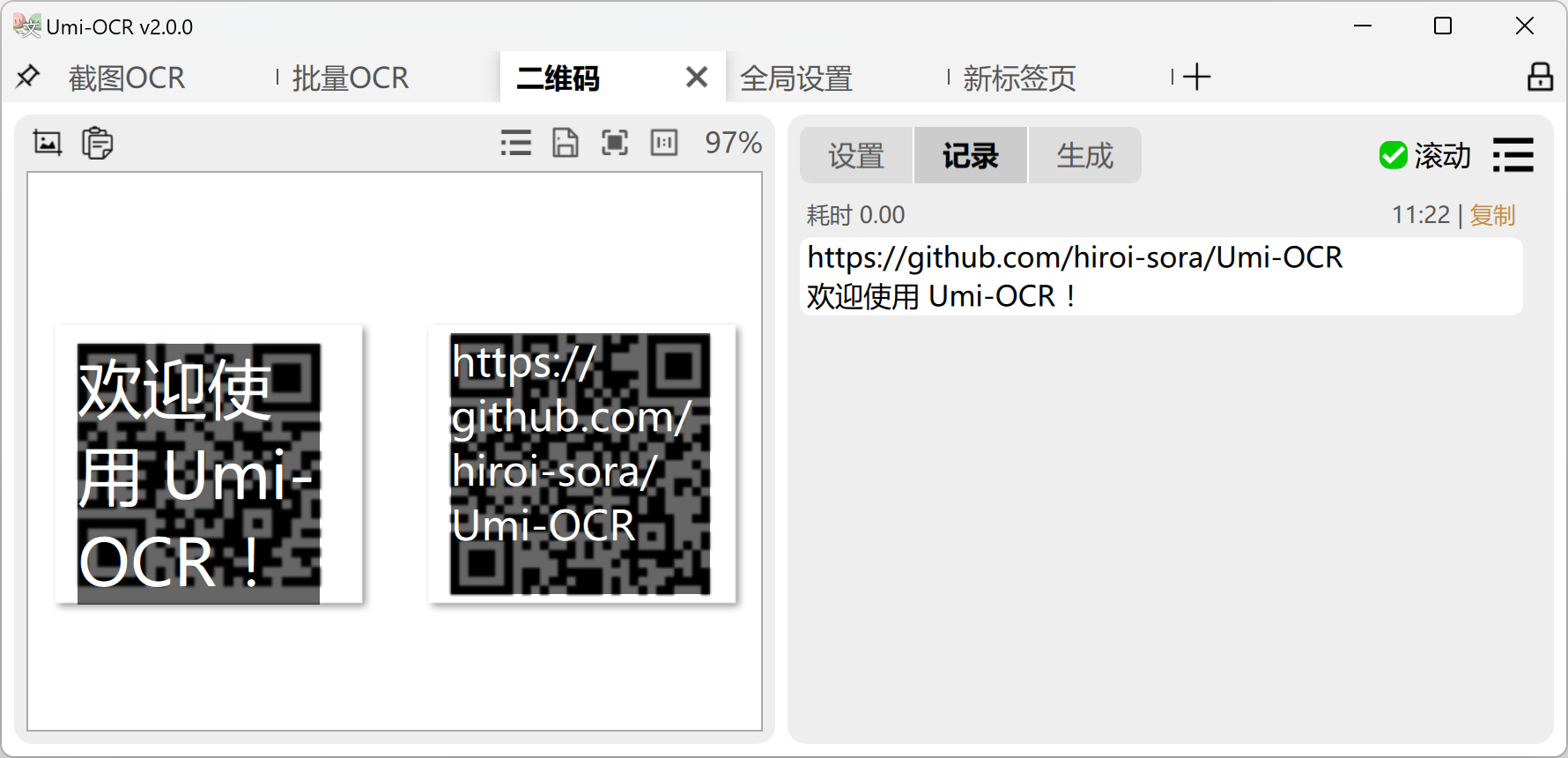
Scan Code:
- You can capture screenshots, paste, or drag local images to read QR codes and barcodes.
- Supports multiple codes in one image.
- Supports 19 protocols, as follows:
Aztec,Codabar,Code128,Code39,Code93,DataBar,DataBarExpanded,DataMatrix,EAN13,EAN8,ITF,LinearCodes,MatrixCodes,MaxiCode,MicroQRCode,PDF417,QRCode,UPCA,UPCE,
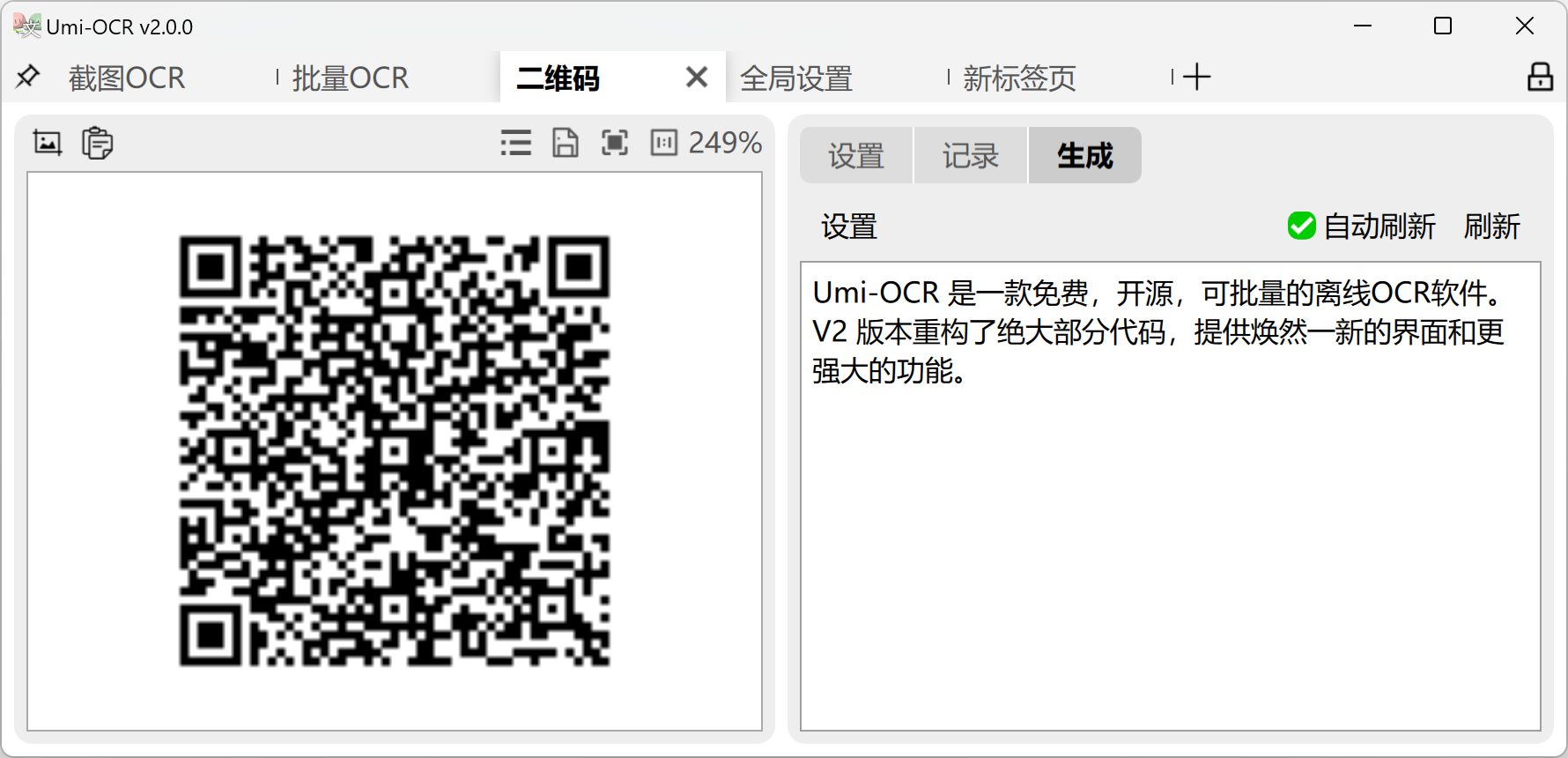
Generate Code:
- Enter text to generate a QR code image.
- Supports 19 protocols and parameters such as error correction level.
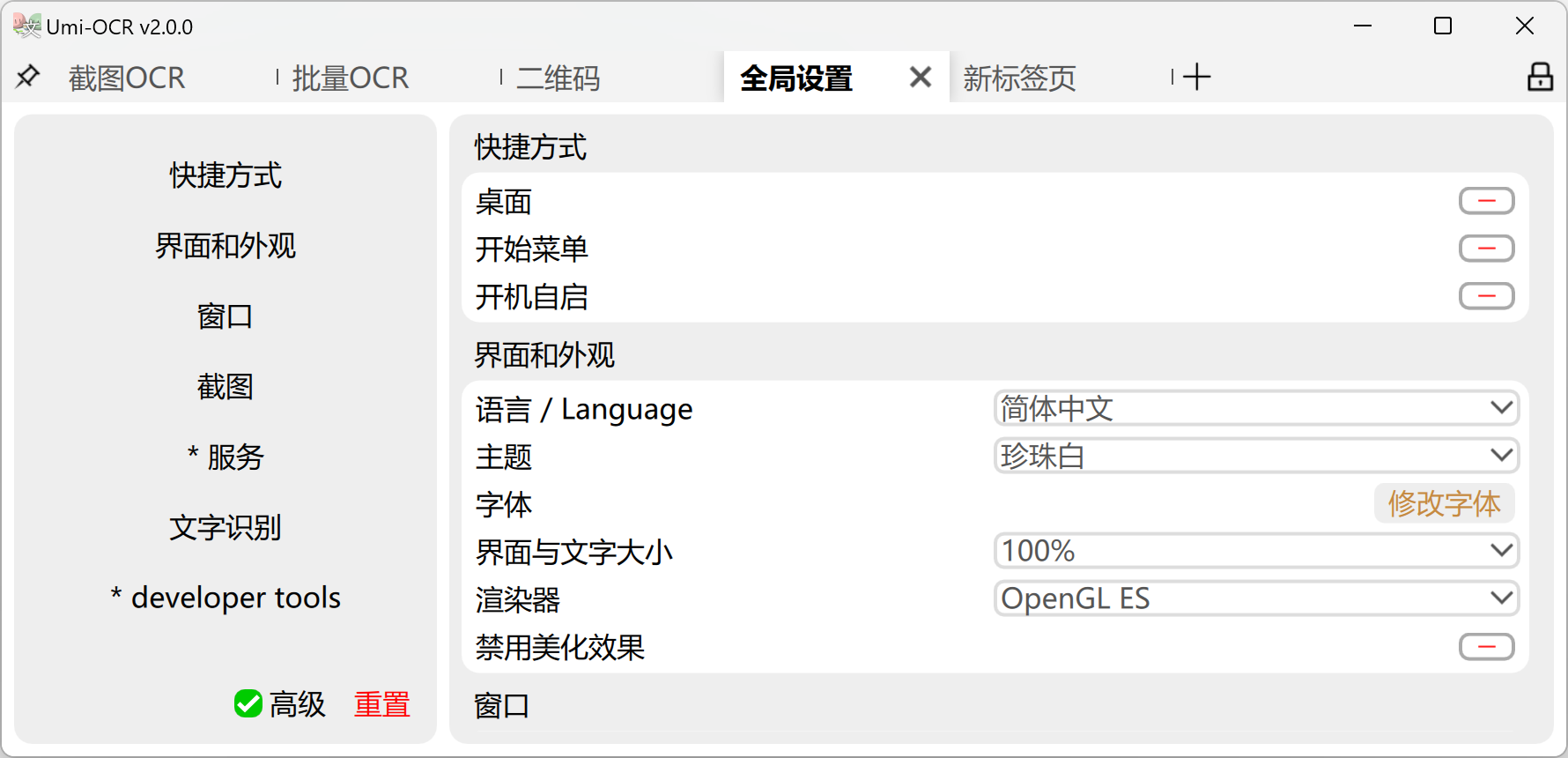
Global Settings: Here you can adjust the global parameters of the software. Common features include:
- One-click to add shortcuts or set auto-startup.
- Change the interface language. Umi supports traditional Chinese, English, Japanese, and other languages.
- Switch interface themes. Umi has multiple light/dark themes.
- Adjust the font size and font of the interface text.
- Switch OCR plugins.
- Renderer: The software interface defaults to support GPU-accelerated rendering. If you encounter screen flickering or UI misalignment on your machine, please adjust
Interface and Appearance→Renderer, try switching to different rendering schemes, or turn off hardware acceleration.
- Command-line manual: README_CLI.md
- HTTP API manual: README_HTTP.md
Refer to dev-tools/i18n
Choose one of the following:
- Pull your forked repository to your local machine
- Download the zip source code package of this repository
- Clone this repository
Please go to the following repositories to complete the development/runtime environment deployment for the corresponding platform.
This project also has a very simple one-click packaging script, which can be found in the following repositories.
- Windows
- Cross-platform support is under development.