NanoDB is a CUDA-optimized multimodal vector database that uses embeddings from the CLIP vision transformer for txt2img and img2img similarity search. The demo video above is running in realtime on 275K images from the MS COCO image captioning dataset using Jetson AGX Orin, and shows a fundamental capability in multimodal applications - operating in a shared embedding space between text/images/etc., and being able to query with a deep contextual understanding.
In addition to effectively indexing and searching your data at the edge, these vector databases are often used in tandem with LLMs for Retrieval Augmented Generation (RAG) for long-term memory beyond their built-in context length (4096 tokens for Llama-2 models), and Vision-Language Models also use the same embeddings as inputs.
NanoDB can recursively scan directories of images, compute their CLIP embeddings, and save them to disk in float16 format. To ingest content into the database, start the container with the path to your dataset mounted (or store your dataset under jetson-containers/data, which is automatically mounted into the container under /data) And run the nanodb --scan command:
./run.sh -v /path/to/your/dataset:/my_dataset $(./autotag nanodb) \
python3 -m nanodb \
--scan /my_dataset \
--path /my_dataset/nanodb \
--autosave --validate To download a pre-indexed database and skip this step, see the NanoDB tutorial on Jetson AI Lab
--scanoptionally specifies a directory to recursively scan for images- Supported image extensions are:
'.png', '.jpg', '.jpeg', '.tiff', '.bmp', '.gif' - You can specify
--scanmultiple times to import different directories
- Supported image extensions are:
--pathspecifies the directory that the NanoDB config/database will be saved to or loaded from- This directory will be created for a new database if it doesn't already exist.
- If there's already an existing NanoDB there, it will be loaded first, and any scans performed are added to that database.
- After images have been added, you can launch NanoDB with
--pathonly to load a ready database.
--autosaveautomatically saves the NanoDB embedding vectors after each scan, and after every 1000 images in the scan.--validatewill cross-check each image against the database to confirm that it returns itself (or finds duplicates already included)
Only the embedding vectors are actually saved in the NanoDB database - the images themselves should be retained elsewhere if you still wish to view them. The original images are not needed for search/retrieval after the indexing process - they're only needed for human viewing.
Once the database has loaded and completed any start-up operations like --scan or --validate, it will drop down to a > prompt from which the user can run search queries, perform additional scans, and save the database from the terminal:
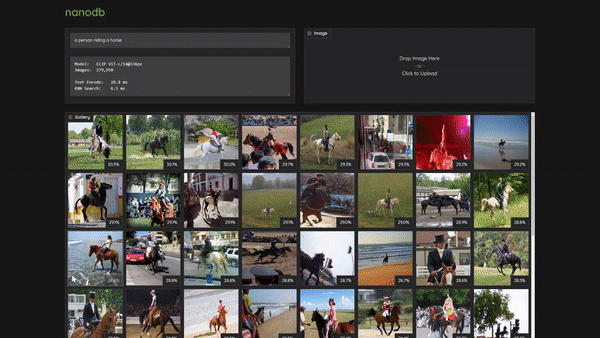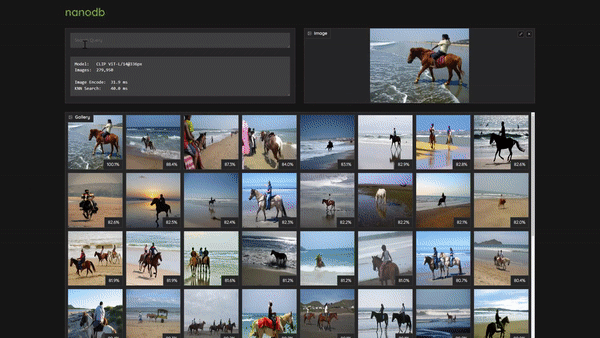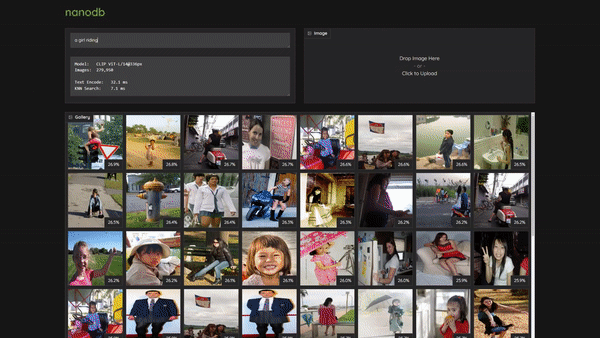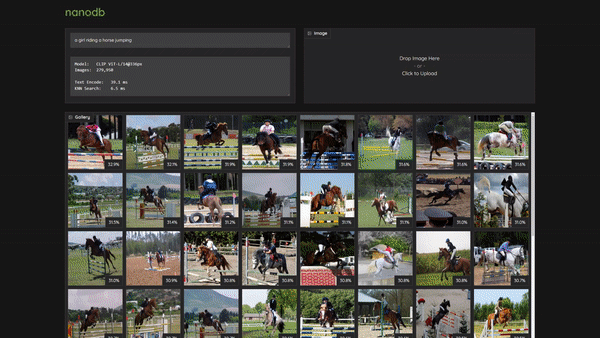
> a girl riding a horse
* index=80110 /data/datasets/coco/2017/train2017/000000393735.jpg similarity=0.29991915822029114
* index=158747 /data/datasets/coco/2017/unlabeled2017/000000189708.jpg similarity=0.29254037141799927
* index=123846 /data/datasets/coco/2017/unlabeled2017/000000026239.jpg similarity=0.292171448469162
* index=127338 /data/datasets/coco/2017/unlabeled2017/000000042508.jpg similarity=0.29118549823760986
* index=77416 /data/datasets/coco/2017/train2017/000000380634.jpg similarity=0.28964102268218994
* index=51992 /data/datasets/coco/2017/train2017/000000256290.jpg similarity=0.28929752111434937
* index=228640 /data/datasets/coco/2017/unlabeled2017/000000520381.jpg similarity=0.28642547130584717
* index=104819 /data/datasets/coco/2017/train2017/000000515895.jpg similarity=0.285491943359375By default, searches return the top 8 results, but you can change this with the
--kcommand-line argument when starting nanodb.
To scan additional items after the database has started, enter the path to your dataset directory or file:
> /data/pascal_voc
-- loaded /data/pascal_voc/VOCdevkit/VOC2012/JPEGImages/2007_000027.jpg in 4 ms
-- loaded /data/pascal_voc/VOCdevkit/VOC2012/JPEGImages/2007_000032.jpg in 2 ms
-- loaded /data/pascal_voc/VOCdevkit/VOC2012/JPEGImages/2007_000033.jpg in 3 ms
-- loaded /data/pascal_voc/VOCdevkit/VOC2012/JPEGImages/2007_000039.jpg in 3 ms
...To save the updated database with any changes/additions made, use the save command:
> save
-- saving database to /my_dataset/nanodb
To spin up the Gradio server, start nanodb with the --server command-line argument:
./run.sh -v /path/to/your/dataset:/my_dataset $(./autotag nanodb) \
python3 -m nanodb \
--path /my_dataset/nanodb \
--server --port=7860The default port is 7860, bound to all network interfaces
(--host=0.0.0.0)
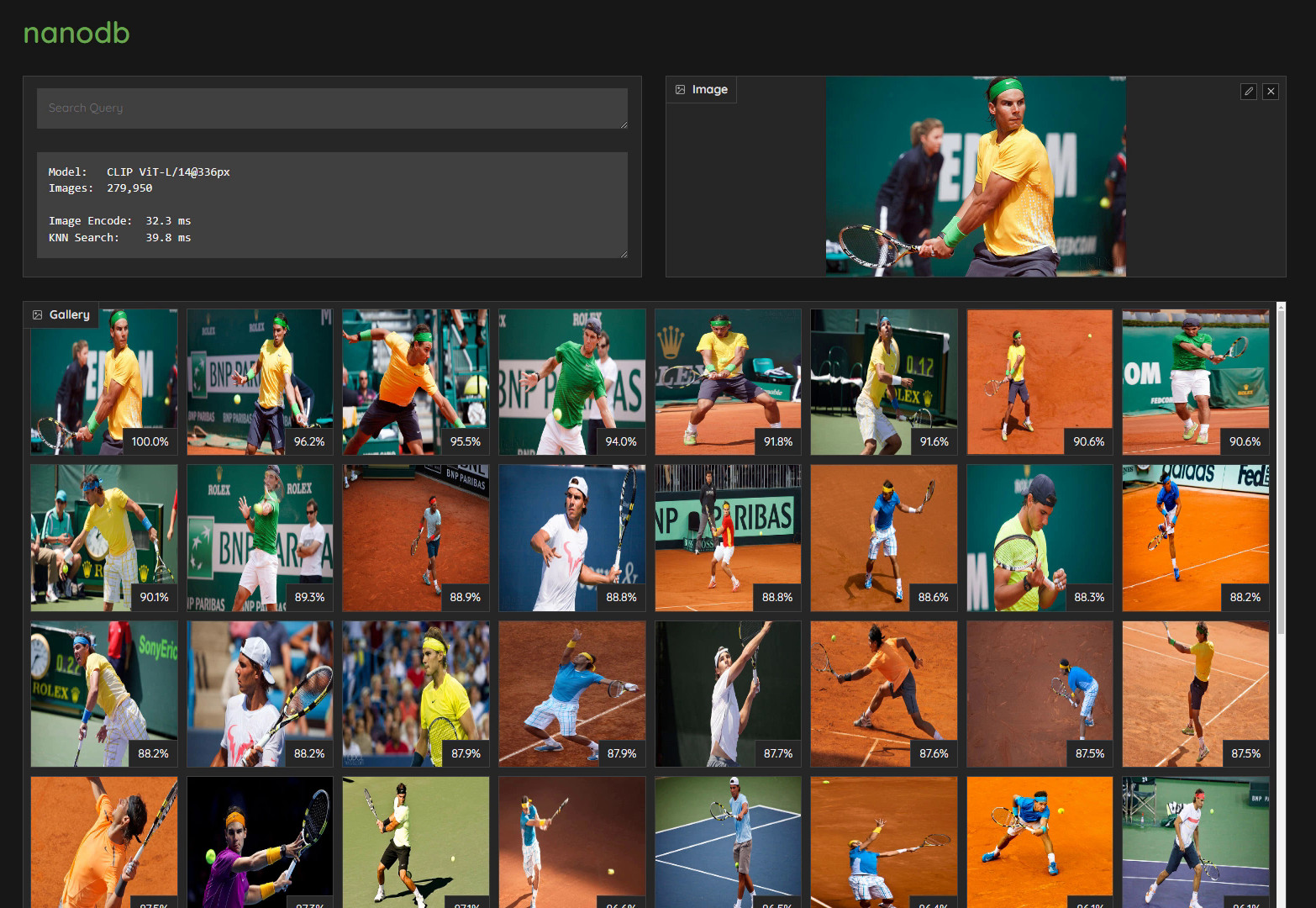
Then navigate your browser to http://HOSTNAME:7860?__theme=dark, and you can enter text search queries as well as drag/upload images:
CONTAINERS
nanodb |
|
|---|---|
| Builds |   |
| Requires | L4T ['>=32.6'] |
| Dependencies | build-essential cuda:11.4 cudnn python numpy cmake onnx pytorch:2.2 cuda-python faiss faiss_lite torchvision huggingface_hub rust transformers tensorrt torch2trt |
| Dockerfile | Dockerfile |
| Images | dustynv/nanodb:r35.2.1 (2023-12-14, 6.9GB)dustynv/nanodb:r35.3.1 (2023-12-15, 7.0GB)dustynv/nanodb:r35.4.1 (2023-12-12, 6.9GB)dustynv/nanodb:r36.2.0 (2024-03-08, 7.8GB) |
CONTAINER IMAGES
| Repository/Tag | Date | Arch | Size |
|---|---|---|---|
dustynv/nanodb:r35.2.1 |
2023-12-14 |
arm64 |
6.9GB |
dustynv/nanodb:r35.3.1 |
2023-12-15 |
arm64 |
7.0GB |
dustynv/nanodb:r35.4.1 |
2023-12-12 |
arm64 |
6.9GB |
dustynv/nanodb:r36.2.0 |
2024-03-08 |
arm64 |
7.8GB |
Container images are compatible with other minor versions of JetPack/L4T:
• L4T R32.7 containers can run on other versions of L4T R32.7 (JetPack 4.6+)
• L4T R35.x containers can run on other versions of L4T R35.x (JetPack 5.1+)
RUN CONTAINER
To start the container, you can use jetson-containers run and autotag, or manually put together a docker run command:
# automatically pull or build a compatible container image
jetson-containers run $(autotag nanodb)
# or explicitly specify one of the container images above
jetson-containers run dustynv/nanodb:r36.2.0
# or if using 'docker run' (specify image and mounts/ect)
sudo docker run --runtime nvidia -it --rm --network=host dustynv/nanodb:r36.2.0
jetson-containers runforwards arguments todocker runwith some defaults added (like--runtime nvidia, mounts a/datacache, and detects devices)
autotagfinds a container image that's compatible with your version of JetPack/L4T - either locally, pulled from a registry, or by building it.
To mount your own directories into the container, use the -v or --volume flags:
jetson-containers run -v /path/on/host:/path/in/container $(autotag nanodb)To launch the container running a command, as opposed to an interactive shell:
jetson-containers run $(autotag nanodb) my_app --abc xyzYou can pass any options to it that you would to docker run, and it'll print out the full command that it constructs before executing it.
BUILD CONTAINER
If you use autotag as shown above, it'll ask to build the container for you if needed. To manually build it, first do the system setup, then run:
jetson-containers build nanodbThe dependencies from above will be built into the container, and it'll be tested during. Run it with --help for build options.