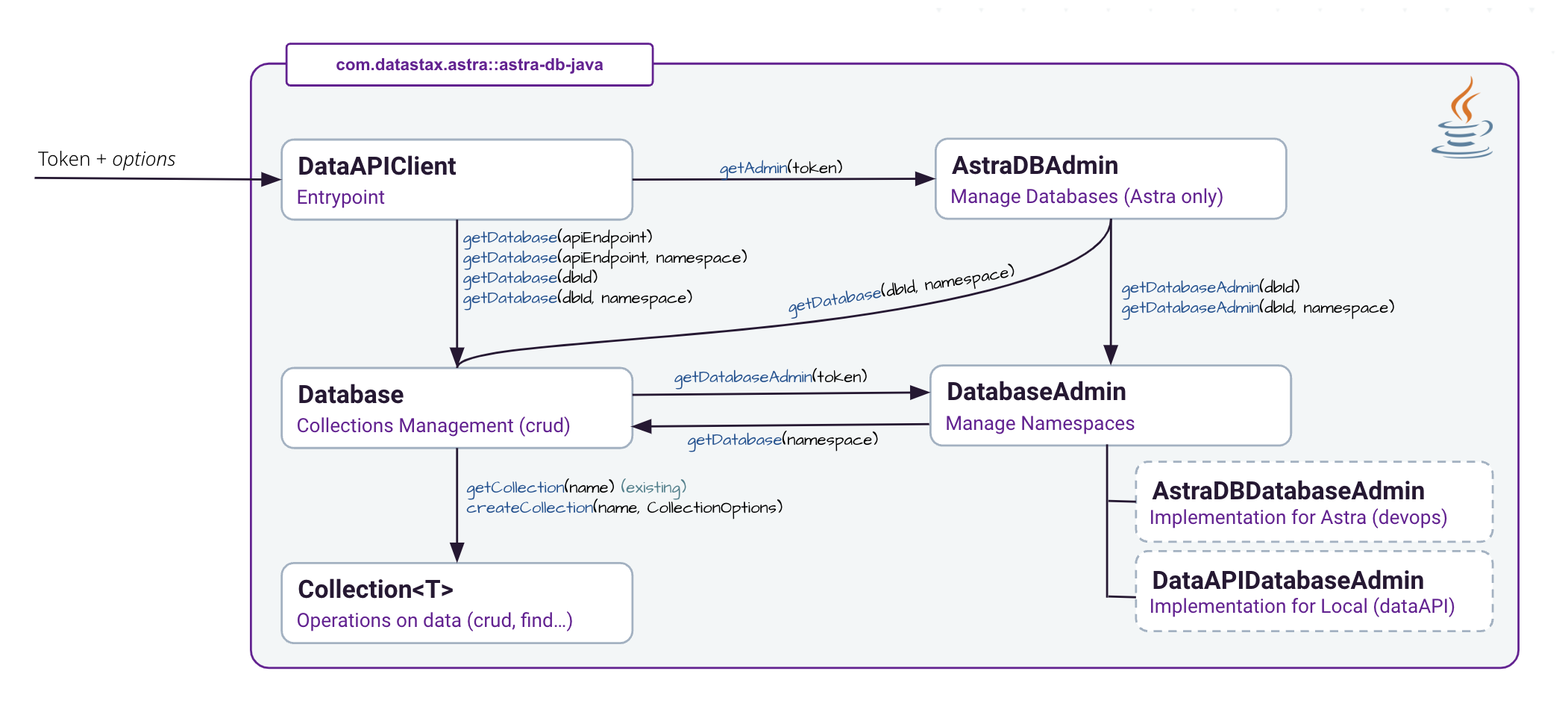
Serves as the primary entry point to the Data API client, offering streamlined access to the functionalities
+ provided by the Data API, whether deployed within Astra environments or on-premise DataStax Enterprise installations.
Represents a specific kind of DataApiException that is thrown when the response
+ received from the Data API does not match the expected format or content.
Encapsulates detailed information about the execution of a command, including the original request,
+ the raw response, HTTP response details, and timing information.
A Data API collection, the main object to interact with the Data API, especially for DDL operations.
+
+ A Collection is spawned from a Database object, from which it inherits the details on how to reach the API server
+ (endpoint, authentication). A Collection has a name, which is its unique identifier for a namespace and
+ options to specialize the usage as vector collections or advanced indexing parameters.
+
+
+ A Collection is typed object designed to work both with default @Document (wrapper for a Map) and application
+ plain old java objects (pojo). The serialization is performed with Jackson and application beans can be annotated.
+
+
+ All features are provided in synchronous and asynchronous flavors.
+
+
Example usage:
+
+
+ // Given a Database
+ Database db = new DataAPIClient("token").getDatabase("api_endpoint");
+
+ // Initialization with no POJO
+ Collection<Document> collection = db.getCollection("collection1");
+
+ // Initialization with POJO
+ Collection<MyBean> collection = db.getCollection("collection1", MyBean.class);
+
+
Finds documents in the collection that match the specified filter and sorts them based on their similarity
+ to a provided vector, limiting the number of results returned.
find(Filter filter,
+ float[] vector,
+ int limit)
+
+
Finds documents in the collection that match the specified filter and sorts them based on their similarity
+ to a provided vector, limiting the number of results returned.
Finds documents in the collection that match the specified filter and sorts them based on their similarity
+ to a provided vector, limiting the number of results returned.
Asynchronously attempts to find a single document within the collection that matches the given filter criteria,
+ utilizing the specified FindOneOptions for the query.
Inserts a single document into the collection in an atomic operation, similar to the insertOne(Object)
+ method, but with the additional capability to include vector embeddings.
Inserts a single document into the collection in an atomic operation, similar to the insertOne(Object)
+ method, but with the additional capability to include vector embeddings.
Inserts a single document into the collection in an atomic operation, extending the base functionality of
+ the insertOne(Object) method by adding the capability to compute and include a vector of embeddings
+ directly within the document.
Inserts a single document into the collection in an atomic operation, extending the base functionality of
+ the insertOne(Object) method by adding the capability to compute and include a vector of embeddings
+ directly within the document.
Constructs an instance of a collection within the specified database. This constructor
+ initializes the collection with a given name and associates it with a specific class type
+ that represents the schema of documents within the collection. This setup is designed for
+ CRUD (Create, Read, Update, Delete) operations.
+
+
Parameters:
+
db - The Database instance representing the client's namespace for HTTP
+ communication with the database. It encapsulates the configuration and management
+ of the database connection, ensuring that operations on this collection are
+ executed within the context of this database.
+
collectionName - A String that uniquely identifies the collection within the
+ database. This name is used to route operations to the correct
+ collection and should adhere to the database's naming conventions.
+
commandOptions - the options to apply to the command operation. If left blank the default collection
+
+
Example usage:
+
+
+ // Given a client
+ DataAPIClient client = new DataAPIClient("token");
+ // Given a database
+ Database myDb = client.getDatabase("myDb");
+ // Initialize a collection with a working class
+ Collection<MyDocumentClass> myCollection = new Collection<>(myDb, "myCollectionName", MyDocumentClass.class);
+
+
+
clazz - The Class<DOC> object that represents the model for documents within
+ this collection. This class is used for serialization and deserialization of
+ documents to and from the database. It ensures type safety and facilitates
+ the mapping of database documents to Java objects.
Retrieves the name of the parent namespace associated with this collection. A namespace in
+ this context typically refers to a higher-level categorization or grouping mechanism within
+ the database that encompasses one or more collections. This method allows for identifying
+ the broader context in which this collection exists, which can be useful for operations
+ requiring knowledge of the database structure or for dynamic database interaction patterns.
+
+
Returns:
+
A String representing the name of the parent namespace of the current
+ collection. This name serves as an identifier for the namespace and can be used
+ to navigate or query the database structure.
+
+
Example usage:
+
+
+ Collection myCollection = ... // assume myCollection is already initialized
+ String namespaceName = myCollection.getNamespaceName();
+ System.out.println("The collection belongs to the namespace: " + namespaceName);
+
+
Retrieves the full definition of the collection, encompassing both its name and its configuration options.
+ This comprehensive information is encapsulated in a CollectionInfo object, providing access to the
+ collection's metadata and settings.
+
+
The returned CollectionInfo includes details such as the collection's name, which serves as its
+ unique identifier within the database, and a set of options that describe its configuration. These options
+ may cover aspects like indexing preferences, read/write permissions, and other customizable settings that
+ were specified at the time of collection creation.
+
+
Example usage:
+
+
+ // Given a collection
+ DataApiCollection<Document> collection;
+ // Access its Definition
+ CollectionDefinition definition = collection.getDefinition();
+ System.out.println("Name=" + definition.getName());
+ CollectionOptions options = definition.getOptions();
+ if (options != null) {
+ // Operations based on collection options
+ }
+
+
+
+
Returns:
+
A CollectionInfo object containing the full definition of the collection, including its name
+ and configuration options. This object provides a comprehensive view of the collection's settings
+ and identity within the database.
Retrieves the configuration options for the collection, including vector and indexing settings.
+ These options specify how the collection should be created and managed, potentially affecting
+ performance, search capabilities, and data organization.
+
Example usage:
+
+
+ // Given a collection
+ DataApiCollection<Document> collection;
+ // Access its Options
+ CollectionOptions options = collection.getOptions();
+ if (null != c.getVector()) {
+ System.out.println(c.getVector().getDimension());
+ System.out.println(c.getVector().getMetric());
+ }
+ if (null != c.getIndexing()) {
+ System.out.println(c.getIndexing().getAllow());
+ System.out.println(c.getIndexing().getDeny());
+ }
+
+
+
+
Returns:
+
An instance of CollectionOptions containing the collection's configuration settings,
+ such as vector and indexing options. Returns null if no options are set or applicable.
Retrieves the name of the collection. This name serves as a unique identifier within the database and is
+ used to reference the collection in database operations such as queries, updates, and deletions. The collection
+ name is defined at the time of collection creation and is immutable.
+
+
Returns:
+
A String representing the name of the collection. This is the same name that was specified
+ when the collection was created or initialized.
Inserts a single document into the collection as an atomic operation, ensuring that the
+ document is added in a single, indivisible step.
+
+
Note: The document can optionally include an _id property, which serves as
+ its unique identifier within the collection. If the _id property is provided and it
+ matches the _id of an existing document in the collection, the insertion will fail
+ and an error will be raised. This behavior ensures that each document in the collection has
+ a unique identifier. If the _id property is not provided, the server will
+ automatically generate a unique _id for the document, ensuring its uniqueness within
+ the collection.
+
+
The `_id` can be of multiple types, by default it can be any json scalar String, Number, $date. But
+ at the collection definition level you can enforce property `defaultId` to work with specialize ids.
+
+
If defaultId is set to uuid, ids will be uuid v4 UUID
+
If defaultId is set to objectId, ids will be an ObjectId
+
If defaultId is set to uuidv6, ids will be an UUIDv6
+
If defaultId is set to uuidv7, ids will be an UUIDv7
+
+
+
The method returns an InsertOneResult object, which provides details about the
+ outcome of the insertion operation. This object can be used to verify the success of the
+ operation and to access the _id of the inserted document, whether it was provided
+ explicitly or generated automatically.
+
+
Parameters:
+
document - the document to be inserted into the collection. This parameter should represent
+ the document in its entirety. The _id field is optional and, if omitted,
+ will be automatically generated.
+
Returns:
+
An InsertOneResult object that contains information about the result of the
+ insertion operation, including the _id of the newly inserted document.
+
+
Example usage:
+
+
+ // Create a document without id.
+ Document newDocument = new Document("name", "John Doe").append("age", 30);
+ InsertOneResult result = collection.insertOne(newDocument);
+ System.out.println("(generated) document id: " + result.getInsertedId());
+
+ // Provide a document id
+ Document doc2 = Document.create("doc2").append("name", "John Doe").append("age", 30);
+ InsertOneResult result = collection.insertOne(doc2);
+ result.getInsertedId(); // will be "doc2"
+
+ // More way to provide to populate ids.
+ Document doc3 = new Document("doc3");
+ Document doc4 = new Document().id("doc4");
+ Document doc5 = new Document().append("_id", "doc5");
+
+
Inserts a single document into the collection as an atomic operation, ensuring that the
+ document is added in a single, indivisible step.
+
+
Note: The document can optionally include an _id property, which serves as
+ its unique identifier within the collection. If the _id property is provided and it
+ matches the _id of an existing document in the collection, the insertion will fail
+ and an error will be raised. This behavior ensures that each document in the collection has
+ a unique identifier. If the _id property is not provided, the server will
+ automatically generate a unique _id for the document, ensuring its uniqueness within
+ the collection.
+
+
The `_id` can be of multiple types, by default it can be any json scalar String, Number, $date. But
+ at the collection definition level you can enforce property `defaultId` to work with specialize ids.
+
+
If defaultId is set to uuid, ids will be uuid v4 UUID
+
If defaultId is set to objectId, ids will be an ObjectId
+
If defaultId is set to uuidv6, ids will be an UUIDv6
+
If defaultId is set to uuidv7, ids will be an UUIDv7
+
+
+
The method returns an InsertOneResult object, which provides details about the
+ outcome of the insertion operation. This object can be used to verify the success of the
+ operation and to access the _id of the inserted document, whether it was provided
+ explicitly or generated automatically.
+
+
Parameters:
+
document - the document to be inserted into the collection. This parameter should represent
+ the document in its entirety. The _id field is optional and, if omitted,
+ will be automatically generated.
+
insertOneOptions - the options to apply to the insert operation. If left blank the default collection
+ options will be used. If collection option is blank DataAPIOptions will be used.
+
Returns:
+
An InsertOneResult object that contains information about the result of the
+ insertion operation, including the _id of the newly inserted document.
+
+
Example usage:
+
+
+ // Create a document without id.
+ Document newDocument = new Document("name", "John Doe").append("age", 30);
+ InsertOneResult result = collection.insertOne(newDocument);
+ System.out.println("(generated) document id: " + result.getInsertedId());
+
+ // Provide a document id
+ Document doc2 = Document.create("doc2").append("name", "John Doe").append("age", 30);
+ InsertOneResult result = collection.insertOne(doc2);
+ result.getInsertedId(); // will be "doc2"
+
+ // More way to provide to populate ids.
+ Document doc3 = new Document("doc3");
+ Document doc4 = new Document().id("doc4");
+ Document doc5 = new Document().append("_id", "doc5");
+
+
Asynchronously inserts a single document into the collection. This method provides the same functionality as
+ insertOne(Object), but it operates asynchronously, returning a CompletableFuture that
+ will be completed with the insertion result. Utilizing this method is beneficial for non-blocking operations,
+ allowing other tasks to proceed while the document insertion is being processed.
+
+
The asynchronous operation ensures that your application can remain responsive, making this method ideal for
+ applications requiring high throughput or for operations that do not need immediate completion confirmation.
+
+
For details on the behavior, parameters, and return type, refer to the documentation of the synchronous
+ insertOne(Object) method. This method inherits all the properties and behaviors of its synchronous
+ counterpart, including error handling and the generation or requirement of the _id field.
+
+
Parameters:
+
document - The document to be inserted into the collection. The specifications regarding the document
+ structure and the _id field are the same as described in insertOne(Object).
+
Returns:
+
A CompletableFuture that, upon completion, contains the result of the insert operation as an
+ InsertOneResult. The completion may occur with a result in case of success or with an exception
+ in case of failure.
+
+
options - the options to apply to the insert operation. If left blank the default collection
+ options will be used. If collection option is blank DataAPIOptions will be used.
+
Returns:
+
result for insertion
+
+
+
+
+
+
insertOne
+
public finalInsertOneResultinsertOne(T document,
+ float[] embeddings)
+
Inserts a single document into the collection in an atomic operation, similar to the insertOne(Object)
+ method, but with the additional capability to include vector embeddings. These embeddings are typically used for
+ advanced querying capabilities, such as similarity search or machine learning models. This method ensures atomicity
+ of the insertion, maintaining the integrity and consistency of the collection.
+
+
Note: Like the base insertOne method, if the _id field is explicitly provided and matches
+ an existing document's _id in the collection, the insertion will fail with an error. If the _id field
+ is not provided, it will be automatically generated by the server, ensuring the document's uniqueness within the
+ collection. This variant of the method allows for the explicit addition of a "$vector" property to the document,
+ storing the provided embeddings.
+
+
The embeddings should be a float array representing the vector to be associated with the document. This vector
+ can be utilized by the database for operations that require vector space computations. An array containing only
+ zero is not valid as it would lead to computation error with division by zero.
+
+
Parameters:
+
document - The document to be inserted. This can include or omit the _id field. If omitted,
+ an _id will be automatically generated.
+
embeddings - The vector embeddings to be associated with the document, expressed as an array of floats.
+ This array populates the "$vector" property of the document, enabling vector-based operations.
+
Returns:
+
An InsertOneResult object that contains information about the result of the insertion, including
+ the _id of the newly inserted document, whether it was explicitly provided or generated.
+
+
Example usage:
+
+
+ // Document without an explicit _id and embeddings for vector-based operations
+ Document newDocument = new Document().append("name", "Jane Doe").append("age", 25);
+ float[] embeddings = new float[]{0.12f, 0.34f, 0.56f, 0.78f};
+ InsertOneResult result = collection.insertOne(newDocument, embeddings);
+ System.out.println("Inserted document id: " + result.getInsertedId());
+
+
Inserts a single document into the collection in an atomic operation, similar to the insertOne(Object)
+ method, but with the additional capability to include vector embeddings. These embeddings are typically used for
+ advanced querying capabilities, such as similarity search or machine learning models. This method ensures atomicity
+ of the insertion, maintaining the integrity and consistency of the collection.
+
+
Note: Like the base insertOne method, if the _id field is explicitly provided and matches
+ an existing document's _id in the collection, the insertion will fail with an error. If the _id field
+ is not provided, it will be automatically generated by the server, ensuring the document's uniqueness within the
+ collection. This variant of the method allows for the explicit addition of a "$vector" property to the document,
+ storing the provided embeddings.
+
+
The embeddings should be a float array representing the vector to be associated with the document. This vector
+ can be utilized by the database for operations that require vector space computations. An array containing only
+ zero is not valid as it would lead to computation error with division by zero.
+
+
Parameters:
+
document - The document to be inserted. This can include or omit the _id field. If omitted,
+ an _id will be automatically generated.
+
embeddings - The vector embeddings to be associated with the document, expressed as an array of floats.
+ This array populates the "$vector" property of the document, enabling vector-based operations.
+
options - the options to apply to the insert operation. If left blank the default collection
+ options will be used. If collection option is blank DataAPIOptions will be used.
+
Returns:
+
An InsertOneResult object that contains information about the result of the insertion, including
+ the _id of the newly inserted document, whether it was explicitly provided or generated.
+
+
Example usage:
+
+
+ // Document without an explicit _id and embeddings for vector-based operations
+ Document newDocument = new Document().append("name", "Jane Doe").append("age", 25);
+ float[] embeddings = new float[]{0.12f, 0.34f, 0.56f, 0.78f};
+ InsertOneResult result = collection.insertOne(newDocument, embeddings);
+ System.out.println("Inserted document id: " + result.getInsertedId());
+
+
Asynchronously inserts a single document into the collection with vector embeddings. This method mirrors the
+ functionality of insertOne(Object,float[]), operating asynchronously to return a
+ CompletableFuture that completes with the insertion result. It is designed for use cases where
+ non-blocking operations are essential, enabling other processes to continue while the document insertion
+ is executed in the background.
+
+
This method provides a convenient way to insert documents along with their associated vector embeddings
+ without halting the execution of your application, making it particularly suitable for applications that
+ require high levels of responsiveness or for operations where immediate confirmation of completion is not
+ critical.
+
+
For a comprehensive understanding of the behavior, parameters, including the purpose and use of vector
+ embeddings, refer to the synchronous insertOne(Object,float[] embeddings) method. This
+ asynchronous variant adopts all the behaviors and properties of its synchronous counterpart.
+
+
Parameters:
+
document - The document to be inserted, potentially without an _id field which, if omitted,
+ will be automatically generated.
+
embeddings - The vector embeddings associated with the document, intended to be used for advanced
+ database operations such as similarity search.
+
Returns:
+
A CompletableFuture that, upon completion, contains the result of the insert operation as an
+ InsertOneResult. This future may be completed with a successful result or an exception in
+ case of insertion failure.
+
+
Inserts a single document into the collection in an atomic operation, extending the base functionality of
+ the insertOne(Object) method by adding the capability to compute and include a vector of embeddings
+ directly within the document. This is achieved through a specified expression, which the service translates
+ into vector embeddings. These embeddings can then be utilized for advanced database operations that leverage
+ vector similarity.
+
Note : This feature is under current development.
+
+
Note: As with the base insertOne method, providing an _id field that matches an existing
+ document's _id in the collection will cause the insertion to fail with an error. If the _id field
+ is not present, it will be automatically generated, ensuring the document's uniqueness. This method variant
+ introduces the ability to automatically compute embeddings based on the provided vectorize string,
+ populating the "$vectorize" property of the document for later use in vector-based operations.
+
+
The vectorize parameter should be a string that conveys meaningful information about the document,
+ which will be converted into a vector representation by the database's embedding service. This functionality
+ is especially useful for enabling semantic searches or clustering documents based on their content similarity.
+
+
Parameters:
+
document - The document to be inserted. It can optionally include the _id field. If omitted,
+ an _id will be automatically generated.
+
vectorize - The expression to be translated into a vector of embeddings. This string is processed by
+ the service to generate vector embeddings that are stored in the document under the "$vectorize"
+ property.
+
options - the options to apply to the insert operation. If left blank the default collection
+ options will be used. If collection option is blank DataAPIOptions will be used.
+
Returns:
+
An InsertOneResult object that contains information about the result of the insertion, including
+ the _id of the newly inserted document, whether it was explicitly provided or generated.
+
+
Example usage:
+
+
+ // Document without an explicit _id and a string to be vectorized
+ Document newDocument = new Document().append("title", "How to Use Vectorization");
+ String vectorizeExpression = "This is a guide on vectorization.";
+ InsertOneResult result = collection.insertOne(newDocument, vectorizeExpression);
+ System.out.println("Inserted document id: " + result.getInsertedId());
+
+
Inserts a single document into the collection in an atomic operation, extending the base functionality of
+ the insertOne(Object) method by adding the capability to compute and include a vector of embeddings
+ directly within the document. This is achieved through a specified expression, which the service translates
+ into vector embeddings. These embeddings can then be utilized for advanced database operations that leverage
+ vector similarity.
+
Note : This feature is under current development.
+
+
Note: As with the base insertOne method, providing an _id field that matches an existing
+ document's _id in the collection will cause the insertion to fail with an error. If the _id field
+ is not present, it will be automatically generated, ensuring the document's uniqueness. This method variant
+ introduces the ability to automatically compute embeddings based on the provided vectorize string,
+ populating the "$vectorize" property of the document for later use in vector-based operations.
+
+
The vectorize parameter should be a string that conveys meaningful information about the document,
+ which will be converted into a vector representation by the database's embedding service. This functionality
+ is especially useful for enabling semantic searches or clustering documents based on their content similarity.
+
+
Parameters:
+
document - The document to be inserted. It can optionally include the _id field. If omitted,
+ an _id will be automatically generated.
+
vectorize - The expression to be translated into a vector of embeddings. This string is processed by
+ the service to generate vector embeddings that are stored in the document under the "$vectorize"
+ property.
+
Returns:
+
An InsertOneResult object that contains information about the result of the insertion, including
+ the _id of the newly inserted document, whether it was explicitly provided or generated.
+
+
Example usage:
+
+
+ // Document without an explicit _id and a string to be vectorized
+ Document newDocument = new Document().append("title", "How to Use Vectorization");
+ String vectorizeExpression = "This is a guide on vectorization.";
+ InsertOneResult result = collection.insertOne(newDocument, vectorizeExpression);
+ System.out.println("Inserted document id: " + result.getInsertedId());
+
+
Asynchronously inserts a single document into the collection with a vectorization expression. This method
+ provides an asynchronous counterpart to insertOne(Object,String), allowing for
+ non-blocking operations while a document, along with its vectorization based on the provided string, is
+ inserted into the collection.
+
Note : This feature is under current development.
+
+
Utilizing this method facilitates the insertion of documents in scenarios where application responsiveness
+ is crucial. It allows the application to continue with other tasks while the document insertion, including
+ its vectorization, is processed in the background. This is particularly useful for operations that can
+ benefit from parallel execution or when the insertion time is not critical to the application's flow.
+
+
For detailed information on the behavior and parameters, especially the purpose and processing of the
+ vectorize string, refer to the documentation of the synchronous
+ insertOne(Object,String) method. This asynchronous method inherits all functionalities
+ and behaviors from its synchronous counterpart, ensuring consistency across the API.
+
+
Parameters:
+
document - The document to be inserted into the collection. The requirements and options regarding the
+ _id field and the document structure are identical to those described in the synchronous
+ version.
+
vectorize - The string expression that will be used to compute the vector embeddings. This parameter enables
+ the automatic generation of embeddings to be associated with the document, enhancing its
+ usefulness for vector-based operations within the database.
+
Returns:
+
A CompletableFuture that, when completed, provides the InsertOneResult indicating the
+ outcome of the insert operation. The future may complete normally with the insertion result or exceptionally
+ in case of an error.
+
+
Example usage:
+
+
+ // Asynchronously inserting a document with a vectorization expression
+ Document newDocument = new Document().append("title", "Async Insert with Vectorization").append("description", "Description for vectorization");
+ String vectorizationExpression = "Description for vectorization";
+ CompletableFuture<InsertOneResult> futureResult = collection.insertOneAsync(newDocument, vectorizationExpression);
+ futureResult.thenAccept(result -> System.out.println("Inserted document id: " + result.getInsertedId()))
+ .exceptionally(error -> { System.err.println("Insertion failed: " + error.getMessage()); return null; });
+
+
Inserts a batch of documents into the collection concurrently, optimizing the insertion process for
+ large datasets. This method provides a powerful mechanism to insert multiple documents with customizable
+ concurrency levels and batch sizes, while also ensuring error handling and performance optimization.
+
+
Validation: The method validates the input documents list for nullity and emptiness. It also
+ checks each document within the list to ensure none are null, throwing an IllegalArgumentException
+ if these conditions are not met.
+
+
Concurrency and Ordering: If concurrent insertion is requested with ordered inserts (via
+ options), the method throws an IllegalArgumentException, as ordered operations cannot
+ be performed concurrently.
+
+
Chunk Size and Maximum Insertions: The method checks if the specified chunk size exceeds the
+ maximum number of documents allowed for insertion in a single operation, throwing an
+ IllegalArgumentException if this limit is breached.
+
+
Documents are then split into chunks, each processed in parallel, according to the concurrency level
+ specified in options. The results of these insertions are aggregated into a single
+ InsertManyResult.
+
+
Timeout Handling: The method attempts to complete all insertion tasks within the specified
+ timeout. If tasks do not complete in time, a TimeoutException is thrown.
+
+
Error Handling: Exceptions encountered during insertion or result aggregation are captured,
+ and a RuntimeException is thrown, indicating an issue with merging results into a single
+ InsertManyResult.
+
+
Example usage: Inserting a list of 100 documents
+
+
+ InsertManyOptions options = InsertManyOptions.builder()
+ .ordered(false) // required for concurrent processing
+ .withConcurrency(5) // recommended
+ .withChunkSize(20) // maximum chunk size is 20
+ .withTimeout(100) // global timeout
+ .build();
+ List<Document> documents = new ArrayList<>();
+ for (int i = 0; i < 100; i++) {
+ documents.add(new Document().append("key" + i, "value" + i));
+ }
+ InsertManyResult result = collection.insertMany(documents, options);
+ System.out.println("Inserted document count: " + result.getInsertedIds().size());
+
+
+
+
Performance Monitoring: Logs the total response time for the insert many operation, aiding
+ in performance analysis and optimization efforts.
+
+
Parameters:
+
documents - A list of documents to be inserted. Must not be null or empty, and no document should
+ be null.
+
options - Detailed options for the insert many operation, including concurrency level, chunk size,
+ and whether the inserts should be ordered.
+
Returns:
+
An InsertManyResult object containing the IDs of all successfully inserted documents.
+
Throws:
+
IllegalArgumentException - if the documents list is null or empty, any document is null, or if
+ the options specified are invalid.
+
RuntimeException - if there is an error in merging the results of concurrent insertions.
Asynchronously inserts a batch of documents into the collection with customizable insertion options.
+ This method is the asynchronous counterpart to insertMany(List, InsertManyOptions), allowing
+ for non-blocking operations. It employs default or specified InsertManyOptions to optimize the
+ insertion process for large datasets, utilizing concurrency and batch processing to enhance performance.
+
+
Utilizing CompletableFuture, this method facilitates the insertion of multiple documents
+ without halting the execution of your application, making it well-suited for applications requiring
+ high throughput or responsiveness. For scenarios necessitating specific insertion behaviors, such as
+ concurrency levels and chunk sizes, the provided options parameter enables fine-tuned control
+ over the asynchronous operation.
+
+
This method inherits all the validation, chunking, and result aggregation logic from its synchronous
+ counterpart, ensuring consistent behavior and error handling, while extending functionality to support
+ asynchronous execution patterns.
+
+
Usage: Recommended for inserting large numbers of documents or when the application's
+ workflow benefits from non-blocking operations. For simpler use cases or default settings, the overload
+ without options provides a more straightforward approach.
+
+
Example usage: Asynchronously inserting a list of documents with custom options.
documents - A list of documents to be inserted. The list must not be null or empty, and no document
+ should be null.
+
options - Detailed options for the insert many operation, allowing customization of concurrency
+ level, chunk size, and insertion order.
+
Returns:
+
A CompletableFuture that, upon completion, contains the InsertManyResult indicating
+ the outcome of the insert operation. The future may complete normally with the insertion result
+ or exceptionally in case of an error.
Inserts a batch of documents into the collection using default insertion options. This method is a
+ simplified version of insertMany(List, InsertManyOptions), intended for use cases where
+ default settings for concurrency, chunk size, and insertion order are sufficient. It provides an
+ efficient way to insert multiple documents concurrently, optimizing the insertion process with
+ predefined settings.
+
+
The default InsertManyOptions used by this method assumes non-concurrent (sequential)
+ insertion, with no specific chunk size or timeout constraints. This is suitable for general use
+ cases where the simplicity of invocation is prioritized over the customization of insertion
+ parameters. For more advanced control over the insertion process, including the ability to specify
+ concurrency levels, chunk sizes, and operation timeouts, use the overloaded
+ insertMany(List, InsertManyOptions) method.
+
+
This method leverages the same underlying insertion logic as its overloaded counterpart,
+ ensuring consistent behavior and error handling. It automatically handles validation of the
+ input documents list, chunking of documents based on default settings, and aggregation of
+ insertion results into a single InsertManyResult.
+
+
Usage: Ideal for inserting a collection of documents without the need for custom
+ insertion options. Simplifies the insertion process for basic use cases.
+
+
Parameters:
+
documents - A list of documents to be inserted. Must not be null or empty, and no document should
+ be null.
+
Returns:
+
An InsertManyResult object containing the IDs of all successfully inserted documents.
Inserts a batch of documents into the collection using default insertion options. This method is a
+ simplified version of insertMany(List, InsertManyOptions), intended for use cases where
+ default settings for concurrency, chunk size, and insertion order are sufficient. It provides an
+ efficient way to insert multiple documents concurrently, optimizing the insertion process with
+ predefined settings.
+
+
The default InsertManyOptions used by this method assumes non-concurrent (sequential)
+ insertion, with no specific chunk size or timeout constraints. This is suitable for general use
+ cases where the simplicity of invocation is prioritized over the customization of insertion
+ parameters. For more advanced control over the insertion process, including the ability to specify
+ concurrency levels, chunk sizes, and operation timeouts, use the overloaded
+ insertMany(List, InsertManyOptions) method.
+
+
This method leverages the same underlying insertion logic as its overloaded counterpart,
+ ensuring consistent behavior and error handling. It automatically handles validation of the
+ input documents list, chunking of documents based on default settings, and aggregation of
+ insertion results into a single InsertManyResult.
+
+
Usage: Ideal for inserting a collection of documents without the need for custom
+ insertion options. Simplifies the insertion process for basic use cases.
+
+
Parameters:
+
documents - A list of documents to be inserted. Must not be null or empty, and no document should
+ be null.
+
Returns:
+
An InsertManyResult object containing the IDs of all successfully inserted documents.
Asynchronously inserts a batch of documents into the collection using default insertion options. This method
+ provides an asynchronous alternative to insertMany(List), facilitating non-blocking operations while
+ employing a simplified insertion process suited for general use cases.
+
+
Utilizing CompletableFuture, this method allows the insertion of multiple documents without interrupting
+ the application's execution flow. It is particularly useful in scenarios requiring high throughput or when maintaining
+ application responsiveness is critical. The default insertion settings are applied, simplifying the operation and
+ making it accessible for basic insertion needs without the necessity for custom configuration.
+
+
This method inherits the core logic and validations from its synchronous counterpart, ensuring consistent behavior
+ and error handling. It automatically manages the input documents list, applying default options for chunking and
+ concurrency, and aggregates the results into a single InsertManyResult asynchronously.
+
+
Usage: Ideal for applications that benefit from asynchronous document insertion, especially when inserting
+ a large number of documents under default settings. This method simplifies asynchronous batch insertions, making it
+ straightforward to integrate into existing workflows.
+
+
Example usage: Asynchronously inserting a list of 100 documents using default options.
documents - A list of documents to be inserted. Must not be null or empty, and no document within the list should
+ be null.
+
Returns:
+
A CompletableFuture that, upon completion, contains the InsertManyResult indicating the
+ outcome of the insert operation. The future may complete with the insertion results or exceptionally in
+ case of an error.
Attempts to find a single document within the collection that matches the given filter criteria. This method
+ efficiently locates the first document that fulfills the specified conditions, making it an optimal choice for
+ queries where a unique identifier or specific characteristics are used to identify a document. Its efficiency
+ stems from the ability to halt the search as soon as a matching document is found, potentially avoiding a full
+ collection scan.
+
+
Utilizing a Filter instance to articulate the search criteria, this method sifts through the collection
+ to find a document that aligns with the provided conditions. The filter defines the parameters that a document
+ must satisfy to be deemed a match, encompassing a wide range of possible attributes and values specific to the
+ document structure and contents within the collection.
+
+
In cases where the search does not yield a matching document, this method returns an empty Optional,
+ signifying the absence of a compatible document. This design choice facilitates more graceful error handling,
+ allowing callers to easily distinguish between the presence and absence of a match without resorting to exception
+ handling for non-existent documents. Consequently, client code can implement more robust and cleaner retrieval
+ logic by leveraging the Optional pattern.
+
+
Example usage:
+
+
+ // Given a collection
+ DataApiCollection<Document> collection;
+ // Assuming a Document in the collection with an id field
+ Document doc = new Document().id(1).append("name", "John Doe");
+ // To find the document with the id 1
+ Optional<Document> foundDoc = collection.findOne(Filters.eq("_id", 1));
+ foundDoc.ifPresent(System.out::println);
+
+
+
+
Parameters:
+
filter - The Filter instance encapsulating the search criteria used to pinpoint the desired document.
+ This object specifies the exact conditions that must be met for a document to be selected as a match.
+
Returns:
+
An Optional encapsulating the found document, if any, that meets the filter criteria.
+ If no document matches the specified conditions, an empty Optional is returned, ensuring
+ that retrieval operations can be performed safely without the concern of NoSuchElementException.
Attempts to find a single document within the collection that matches the given filter criteria.
+ This method is designed to return the first document that satisfies the filter conditions,
+ making it particularly useful for retrieving specific documents when unique identifiers or
+ specific criteria are known. If no document matches the filter, the method will return an empty
+ Optional, indicating the absence of a matching document. This approach
+ avoids throwing exceptions for non-existent documents, thereby facilitating cleaner and more
+ robust error handling in client code.
+
+
Example usage:
+
+
+ // Given a collection
+ DataApiCollection<Document> collection;
+ // Assuming a Document in the collection with an id field
+ Document doc = new Document().id(1).append("name", "John Doe");
+ // To find the document with the id 1
+ FindOneOptions options2 = FindOneOptions.builder()
+ .withIncludeSimilarity() // return similarity in vector search
+ .projections("_id", "name") // return a subset of fields
+ .build();
+ Optional<Document> foundDoc = collection.findOne(Filters.eq("_id", 1), );
+ foundDoc.ifPresent(System.out::println);
+
+
+
+
Parameters:
+
filter - The Filter instance containing the criteria used to identify the desired document.
+ It specifies the conditions that a document must meet to be considered a match.
+
findOneOptions - The FindOneOptions instance containing additional options for the find operation,
+
Returns:
+
An Optional that contains the found document if one exists that matches
+ the filter criteria. Returns an empty Optional if no matching document is found,
+ enabling safe retrieval operations without the risk of NoSuchElementException.
An Optional that contains the found document if one exists that matches
+ the filter criteria. Returns an empty Optional if no matching document is found,
+ enabling safe retrieval operations without the risk of NoSuchElementException.
Initiates an asynchronous search to find a single document that matches the given filter criteria.
+ This method leverages the functionality of to perform the
+ search, but it does so asynchronously, returning a CompletableFuture. This approach allows
+ the calling thread to remain responsive and perform other tasks while the search operation completes.
+ The result of the operation is wrapped in a CompletableFuture that, upon completion, will
+ contain an Optional instance. This instance either holds the document that matches the filter
+ criteria or is empty if no such document exists.
+
+
Parameters:
+
filter - The Filter specifying the conditions that the document must meet to be considered
+ a match. This parameter determines how the search is conducted and what criteria the
+ document must satisfy to be retrieved.
+
Returns:
+
CompletableFuture that, when completed, will contain the result of
+ the search operation. If a matching document is found, the Optional is non-empty;
+ otherwise, it is empty to indicate the absence of a matching document. This future allows for
+ non-blocking operations and facilitates the integration of asynchronous programming patterns.
Asynchronously attempts to find a single document within the collection that matches the given filter criteria,
+ utilizing the specified FindOneOptions for the query. This method offers a non-blocking approach to
+ querying the database, making it well-suited for applications requiring efficient I/O operations without
+ compromising the responsiveness of the application.
+
+
By executing the search operation in an asynchronous manner, this method allows other tasks to proceed
+ concurrently, effectively utilizing system resources and improving application throughput. The query leverages
+ a Filter instance to define the search criteria, and FindOneOptions to specify query
+ customizations, such as projection or sort parameters.
+
+
In cases where no document matches the filter, the method returns a CompletableFuture completed with
+ an empty Optional, thus avoiding exceptions for non-existent documents. This behavior ensures
+ a more graceful handling of such scenarios, allowing for cleaner and more robust client code by leveraging
+ the Optional pattern within asynchronous workflows.
+
+
Parameters:
+
filter - The Filter instance encapsulating the criteria used to identify the desired document.
+ It defines the conditions that a document must meet to be considered a match.
+
findOneOptions - The FindOneOptions providing additional query configurations such as projection
+ and sort criteria to tailor the search operation.
+
Returns:
+
A CompletableFuture that, upon completion, contains an Optional
+ with the found document if one exists matching the filter criteria. If no matching document is found,
+ a completed future with an empty Optional is returned, facilitating safe asynchronous retrieval.
+
+
Retrieves a document by its identifier from the collection.
+
+ This method searches for a document with the specified id. If a matching document is found,
+ it is returned wrapped in an Optional, otherwise, an empty Optional is returned.
+ This approach provides a null-safe way to handle the presence or absence of a document.
+
+
+
Parameters:
+
id - The identifier of the document to find.
+
Returns:
+
An Optional containing the found document, or an empty Optional if no document
+ matches the provided id.
+ This method returns an iterable interface that allows iterating over all documents in the collection,
+ without applying any filters. It leverages the default FindOptions for query execution.
+
+
+
Returns:
+
A FindIterable for iterating over all documents in the collection.
Retrieves documents in the collection that match the specified filter.
+
+ This method returns an iterable interface for documents that meet the criteria defined by the filter.
+ It uses default FindOptions for query execution, allowing for customization of the query if needed.
+
+
+
Parameters:
+
filter - The query filter to apply when retrieving documents.
+
Returns:
+
A FindIterable for iterating over the documents that match the filter.
Finds documents in the collection that match the specified filter and sorts them based on their similarity
+ to a provided vector, limiting the number of results returned.
+
+ This method is particularly useful for vector-based search operations where documents are ranked according
+ to their distance from a reference vector. The limit parameter controls the maximum number of documents
+ to return, allowing for efficient retrieval of the most relevant documents.
+
+
+
Parameters:
+
filter - The query filter to apply when retrieving documents.
+
vector - A float array representing the vector used to sort the documents.
+
limit - The maximum number of documents to return.
+
Returns:
+
A FindIterable for iterating over the sorted and limited documents.
+
+
+
+
+
+
find
+
publicFindIterable<T>find(float[] vector,
+ int limit)
+
Finds documents in the collection that match the specified filter and sorts them based on their similarity
+ to a provided vector, limiting the number of results returned.
+
+ This method is particularly useful for vector-based search operations where documents are ranked according
+ to their distance from a reference vector. The limit parameter controls the maximum number of documents
+ to return, allowing for efficient retrieval of the most relevant documents.
+
+
+
Parameters:
+
vector - A float array representing the vector used to sort the documents.
+
limit - The maximum number of documents to return.
+
Returns:
+
A FindIterable for iterating over the sorted and limited documents.
Finds documents in the collection that match the specified filter and sorts them based on their similarity
+ to a provided vector, limiting the number of results returned.
+
Note : This feature is under current development.
+
+ This method leverage the 'vectorization' to compute the embeddings on the fly in order to execute the search.
+
+
+
Parameters:
+
filter - The query filter to apply when retrieving documents.
+
vectorize - A float array representing the vector used to sort the documents.
+
limit - The maximum number of documents to return.
+
Returns:
+
A FindIterable for iterating over the sorted and limited documents.
Finds all documents in the collection, applying the specified find options.
+
+ This method allows for detailed control over the query execution through FindOptions, which can
+ specify sorting, projection, limits, and other query parameters. If no filter is applied, all documents
+ in the collection are considered.
+
+
+
Parameters:
+
options - The FindOptions to apply when executing the find operation.
+
Returns:
+
A FindIterable for iterating over the documents according to the specified options.
Executes a paginated 'find' query on the collection using the specified filter and find options.
+
+ This method constructs and executes a command to fetch a specific page of documents from the collection that match
+ the provided filter criteria. It allows for detailed control over the query through FindOptions, such as sorting,
+ projection, pagination, and more. The result is wrapped in a Page object, which includes the documents found,
+ the page size, and the state for fetching subsequent pages.
+
+
+ Pagination is facilitated by the skip, limit, and pageState parameters within FindOptions,
+ enabling efficient data retrieval in scenarios where the total dataset is too large to be fetched in a single request.
+ Optionally, similarity scoring can be included if includeSimilarity is set, which is useful for vector-based search queries.
+
+
+ The method processes the command's response, mapping each document to the specified document class and collecting them into a list.
+ This list, along with the maximum page size and the next page state, is used to construct the Page object returned by the method.
+
+
+
Parameters:
+
filter - The filter criteria used to select documents from the collection.
+
options - The FindOptions providing additional query parameters, such as sorting and pagination.
+
Returns:
+
A Page object containing the documents that match the query, along with pagination information.
Executes a paginated 'find' query on the collection using the specified filter and find options asynchronously.
+
+ This method constructs and executes a command to fetch a specific page of documents from the collection that match
+ the provided filter criteria. It allows for detailed control over the query through FindOptions, such as sorting,
+ projection, pagination, and more. The result is wrapped in a Page object, which includes the documents found,
+ the page size, and the state for fetching subsequent pages.
+
+
+ Pagination is facilitated by the skip, limit, and pageState parameters within FindOptions,
+ enabling efficient data retrieval in scenarios where the total dataset is too large to be fetched in a single request.
+ Optionally, similarity scoring can be included if includeSimilarity is set, which is useful for vector-based search queries.
+
+
+ The method processes the command's response, mapping each document to the specified document class and collecting them into a list.
+ This list, along with the maximum page size and the next page state, is used to construct the Page object returned by the method.
+
+
+
Parameters:
+
filter - The filter criteria used to select documents from the collection.
+
options - The FindOptions providing additional query parameters, such as sorting and pagination.
+
Returns:
+
A Page object containing the documents that match the query, along with pagination information.
Counts the number of documents in the collection.
+
+
+ Takes in a `upperBound` option which dictates the maximum number of documents that may be present before a
+ TooManyDocumentsToCountException is thrown. If the limit is higher than the highest limit accepted by the
+ Data API, a TooManyDocumentsToCountException will be thrown anyway (i.e. `1000`).
+
+
+ Count operations are expensive: for this reason, the best practice is to provide a reasonable `upperBound`
+ according to the caller expectations. Moreover, indiscriminate usage of count operations for sizeable amounts
+ of documents (i.e. in the thousands and more) is discouraged in favor of alternative application-specific
+ solutions. Keep in mind that the Data API has a hard upper limit on the amount of documents it will count,
+ and that an exception will be thrown by this method if this limit is encountered.
+
+
+
Parameters:
+
upperBound - The maximum number of documents to count.
Executes the "estimatedDocumentCount" command to estimate the number of documents
+ in a collection.
+
+ This method sends a command to estimate the document count and parses the count
+ from the command's response. It handles the execution of the command and the extraction
+ of the document count from the response.
+
+
+
Parameters:
+
options - the options to apply to the operation
+
Returns:
+
the estimated number of documents in the collection.
Counts the number of documents in the collection with a filter.
+
+
+ Takes in a `upperBound` option which dictates the maximum number of documents that may be present before a
+ TooManyDocumentsToCountException is thrown. If the limit is higher than the highest limit accepted by the
+ Data API, a TooManyDocumentsToCountException will be thrown anyway (i.e. `1000`).
+
+
+ Count operations are expensive: for this reason, the best practice is to provide a reasonable `upperBound`
+ according to the caller expectations. Moreover, indiscriminate usage of count operations for sizeable amounts
+ of documents (i.e. in the thousands and more) is discouraged in favor of alternative application-specific
+ solutions. Keep in mind that the Data API has a hard upper limit on the amount of documents it will count,
+ and that an exception will be thrown by this method if this limit is encountered.
+
+
+
Parameters:
+
filter - A filter to select the documents to count. If not provided, all documents will be counted.
+
upperBound - The maximum number of documents to count.
+
options - overriding options for the count operation.
Removes all documents from the collection that match the given query filter. If no documents match, the collection is not modified.
+
+
Returns:
+
the result of the remove many operation
+
+
+
+
+
+
exists
+
publicbooleanexists()
+
Checks if the specified collection exists within the current namespace.
+
+
+ This method delegates the existence check to the existCollection method of the associated
+ namespace, evaluates the existence based on the collection's name, as retrieved by getName().
+
+
+
Returns:
+
true if the collection exists within the namespace, false otherwise.
+
+
+
+
+
+
drop
+
publicvoiddrop()
+
Delete the current collection and all documents that its contains.
+
+
+
+
+
findOneAndReplace
+
publicOptional<T>findOneAndReplace(Filter filter,
+ T replacement)
+
Atomically find a document and replace it.
+
+
Parameters:
+
filter - the query filter to apply the replace operation
+
replacement - the replacement document
+
Returns:
+
the document that was replaced. Depending on the value of the returnOriginal property, this will either be the document as it was before the update or as it is after the update. If no documents matched the query filter, then null will be returned
Note: Supports retryable writes on MongoDB server versions 3.6 or higher when the retryWrites setting is enabled.
+
+
Parameters:
+
filter - the query filter to apply the replace operation
+
replacement - the replacement document
+
options - the options to apply to the operation
+
Returns:
+
the document that was replaced. Depending on the value of the returnOriginal property, this will either be the
+ document as it was before the update or as it is after the update. If no documents matched the query filter, then null will be
+ returned
filter - a document describing the query filter, which may not be null.
+
update - a document describing the update, which may not be null. The update to apply must include at least one update
+ operator.
+
options - the options to apply to the operation
+
Returns:
+
the document that was updated. Depending on the value of the returnOriginal property, this will either be the
+ document as it was before the update or as it is after the update. If no documents matched the query filter, then null will be
+ returned
Serves as the primary entry point to the Data API client, offering streamlined access to the functionalities
+ provided by the Data API, whether deployed within Astra environments or on-premise DataStax Enterprise installations.
+
+ This client aims to simplify interactions with the Data API through a user-friendly, high-level API design. It
+ supports fluent API patterns, builder mechanisms for complex configurations, and employs idiomatic method naming
+ conventions to enhance readability and ease of use. The design philosophy of this client closely mirrors that of
+ the established MongoDB API, providing a familiar experience to developers accustomed to MongoDB's client interface.
+
+
+ Through this client, users can perform a wide range of operations, from basic data manipulation in databases and
+ collections to more advanced administrative tasks. Administrative capabilities, such as database creation and
+ namespace management, are available to users with the appropriate administrative privileges.
+
+
+
Example usage:
+
+
+ // Initialize the client with default settings
+ DataAPIClient client = new DataAPIClient("yourAuthTokenHere");
+
+ // Initialize the client with custom HTTP configuration
+ DataAPIClient clientWithCustomConfig = new DataAPIClient("yourAuthTokenHere", DataAPIOptions.builder()
+ .withHttpRequestTimeout(1000) // Request timeout in milliseconds
+ .withHttpConnectTimeout(10) // Connection timeout in milliseconds
+ .withHttpVersion(HttpClient.Version.HTTP_2) // HTTP protocol version
+ .withDestination("ASTRA") // Target destination, e.g., Astra
+ .build());
+
+
+
+ This documentation highlights the ease of starting with the DataAPIClient, whether opting for a quick setup with
+ default configurations or a more tailored approach via detailed HTTP client settings. The examples demonstrate
+ both the straightforward initialization process and the method to apply fine-grained configurations for developers'
+ specific needs.
Constructs a DataAPIClient instance using the specified authentication token. This constructor
+ initializes the client with default DataAPIOptions for its configuration.
+
+ The provided token is used for authenticating HTTP requests made by this client. It is essential for accessing
+ secured resources. If specific HTTP configurations are required (e.g., custom timeouts, HTTP version), use the
+ other constructor that accepts both a token and a DataAPIOptions instance.
+
+
+ This constructor is suitable for scenarios where default client settings are sufficient and no advanced
+ configuration is needed. It simplifies the initialization process for quick setup and use.
+
+
+
Example usage:
+
+
+ String myAuthToken = "AstraCS:...";
+ DataAPIClient client = new DataAPIClient(myAuthToken);
+ // Now the client is ready to make authenticated requests with default settings
+
+
+
+
Parameters:
+
token - The authentication token to be used for HTTP requests. This token should follow the format expected
+ by the server, typically starting with "AstraCS:.." for Astra environments.
Constructs a DataAPIClient with specified authentication token and HTTP client configuration options.
+
+ This constructor allows for the explicit specification of both the authentication token and the advanced
+ HTTP configuration settings. The authentication token is essential for securing access to the API, while the
+ DataAPIOptions object provides granular control over the HTTP client's behavior, including timeouts,
+ HTTP version, and other properties impacting connectivity and request handling.
+
+
+ It is recommended to use this constructor when you need to customize the HTTP client beyond the default
+ configuration, such as setting custom timeouts or specifying a particular HTTP protocol version. The provided
+ Assert methods ensure that neither the token nor the options are null or empty, enforcing the presence of
+ essential configuration details at the time of client initialization.
+
+
+
Example usage:
+
+
+ String myAuthToken = "AstraCS:...";
+ DataAPIOptions myOptions = DataAPIOptions.builder()
+ .withHttpRequestTimeout(1000)
+ .withHttpConnectTimeout(500)
+ .withHttpVersion(HttpClient.Version.HTTP_2)
+ .build();
+
+ DataAPIClient myClient = new DataAPIClient(myAuthToken, myOptions);
+ // The client is now ready to perform actions with custom configurations.
+
+
+
+
Parameters:
+
token - The authentication token to be used for securing API access. This token should adhere to the
+ format required by the API, typically starting with "AstraCS:.." for Astra environments.
+
options - The DataAPIOptions specifying the detailed HTTP client configurations, offering
+ customization over aspects such as timeouts and protocol versions.
Retrieves an administration client specific to Astra deployments. This client is intended for performing
+ administrative tasks such as creating databases. It requires the use of a token with sufficient privileges.
+
+ To use this method effectively, the provided authentication token must be associated with a user having
+ elevated privileges, such as a Database Administrator or Organization Administrator. This ensures that
+ the client has the necessary permissions to execute administrative operations within the Astra environment.
+
+
+ The administration client provides a programmatic interface for managing various aspects of the Astra
+ deployment, enabling tasks such as database creation, user management, and configuration adjustments
+ without the need for direct interaction with the Astra UI.
+
+
+
Example usage:
+
+
+ DataAPIClient apiClient = new DataAPIClient("AstraCS:your_admin_token_here");
+ AstraDBAdmin adminClient = apiClient.getAdmin();
+ // Use adminClient to perform administrative operations, e.g., create a database
+
+
+
+
Returns:
+
An instance of AstraDBAdmin configured with the current authentication token, ready for
+ administrative operations.
+
Throws:
+
SecurityException - if the current token does not have the necessary administrative privileges.
Retrieves an administration client capable of performing CRUD operations on databases, requiring a token with
+ advanced privileges. This method is designed for scenarios where administrative access is necessary beyond the
+ default token capabilities associated with the DataAPIClient.
+
+ The provided superUserToken should be granted sufficient privileges to perform administrative operations,
+ such as creating, updating, and deleting databases. This typically involves tokens associated with roles like
+ Database Administrator or Organization Administrator within the Astra environment.
+
+
+ Utilizing this method allows for direct access to the Astra database's administrative functionalities, enabling
+ comprehensive management capabilities through the returned AstraDBAdmin client. This includes but is not
+ limited to database creation, modification, and deletion.
+
+
+
Example usage:
+
+
+ String superUserToken = "AstraCS:super_user_token_here";
+ DataAPIClient apiClient = new DataAPIClient(superUserToken);
+ AstraDBAdmin adminClient = apiClient.getAdmin(superUserToken);
+ // Now you can use adminClient for administrative operations like creating a database
+
+
+
+
Parameters:
+
superUserToken - A token with elevated privileges, enabling administrative actions within the Astra
+ environment. This token must be authorized to perform operations such as creating and managing databases.
+
Returns:
+
An instance of AstraDBAdmin, configured for administrative tasks with the provided user token.
+
Throws:
+
SecurityException - if the provided superUserToken lacks the necessary privileges for administrative operations.
Retrieves a client for a specific database, enabling interactions with the Data API. This method allows for
+ operations such as querying, updating, and managing data within the specified database and namespace.
+
+ The databaseId parameter is a unique identifier for the target database. This ID ensures that operations
+ performed through the returned client are executed against the correct database instance within the Astra
+ environment or an on-premise DataStax Enterprise setup.
+
+
+ The namespace parameter specifies the namespace (often synonymous with "keyspace" in Cassandra terminology)
+ within the database to which the client will have access. Namespaces are used to organize and isolate data within
+ the database, providing a layer of abstraction and security.
+
+
+
Example usage:
+
+
+ UUID databaseId = UUID.fromString("your-database-uuid-here");
+ String namespace = "your_namespace_here";
+ DataAPIClient apiClient = new DataAPIClient("yourAuthTokenHere");
+ Database databaseClient = apiClient.getDatabase(databaseId, namespace);
+ // Use databaseClient to perform data operations within the specified namespace
+
+
+
+
Parameters:
+
databaseId - The unique identifier of the database to interact with.
+
namespace - The namespace within the specified database to which operations will be scoped.
+
Returns:
+
A Database client configured to interact with the specified database and namespace, allowing for
+ data manipulation and query operations.
Retrieves a client for a specific database, enabling interactions with the Data API. This method allows for
+ operations such as querying, updating, and managing data within the specified database and namespace.
+
+
Parameters:
+
databaseId - The unique identifier of the database to interact with.
+
namespace - The namespace associated to this database
+
region - The cloud provider region where the database is deployed.
+
Returns:
+
A Database client configured to interact with the specified database and namespace, allowing for
+ data manipulation and query operations.
Retrieves a client for interacting with a specified database using its unique identifier. This client facilitates
+ direct communication with the Data API, enabling a range of operations such as querying, inserting, updating, and
+ deleting data within the database. This streamlined method provides access to the default namespace or keyspace.
+
+ The databaseId serves as a unique identifier for the database within the Astra environment or an on-premise
+ DataStax Enterprise setup, ensuring that all operations through the client are correctly routed to the intended
+ database instance.
+
+
+
Example usage:
+
+
+ UUID databaseId = UUID.fromString("123e4567-e89b-12d3-a456-426614174000");
+ DataAPIClient apiClient = new DataAPIClient("yourAuthTokenHere");
+ Database databaseClient = apiClient.getDatabase(databaseId);
+ // Perform data operations using the databaseClient
+
+
+
+
Parameters:
+
databaseId - The unique identifier of the database for which to retrieve the client.
+
Returns:
+
A Database client that provides the ability to perform operations on the specified database.
Creates and returns a database client configured to interact with the Data API at the specified API endpoint
+ and within the given namespace. This method facilitates operations such as querying, inserting, updating, and
+ deleting data by directly communicating with the Data API, allowing for a wide range of data manipulation
+ tasks in a specified namespace.
+
+ The apiEndpoint parameter should be the URL of the API endpoint where the Data API is hosted. This
+ is typically a fully qualified URL that points to the Astra service or an on-premise DataStax Enterprise
+ deployment hosting the Data API.
+
+
+ The namespace parameter specifies the namespace (or keyspace in Cassandra terms) within the database
+ that the client will interact with. Namespaces help organize data within the database and provide a way to
+ isolate and manage access to data.
+
+
+
Example usage:
+
+
+ String apiEndpoint = "https://example-astra-data-api.com";
+ String namespace = "my_keyspace";
+ DataAPIClient apiClient = new DataAPIClient("yourAuthTokenHere");
+ Database databaseClient = apiClient.getDatabase(apiEndpoint, namespace);
+ // Now you can use the databaseClient to perform operations within "my_keyspace"
+
+
+
+
Parameters:
+
apiEndpoint - The URL of the Data API endpoint. This specifies the location of the API the client will connect to.
+
namespace - The namespace (or keyspace) within the database that the client will access and perform operations in.
+
Returns:
+
A Database client configured for the specified API endpoint and namespace, enabling data manipulation
+ and query operations within the targeted namespace.
Retrieves a database client configured to interact with the Data API at the specified API endpoint. This method
+ enables direct communication with the Data API, facilitating a range of data manipulation operations such as querying,
+ inserting, updating, and deleting data. The client accesses the default namespace or keyspace for operations, unless
+ otherwise specified through additional configuration.
+
+ The apiEndpoint parameter should be the URL of the Data API endpoint you wish to connect to. This URL
+ points to the location where the Data API is hosted, which could be an Astra cloud service or an on-premise DataStax
+ Enterprise instance.
+
+
+ Utilizing this method simplifies the process of connecting to the Data API by focusing on essential configuration,
+ making it particularly useful for scenarios where detailed namespace management is handled separately or not required.
+
+
+
Example usage:
+
+
+ String apiEndpoint = "https://<database_id>-<database_region>.apps.astra.datastax.com";
+ DataAPIClient apiClient = new DataAPIClient("yourAuthTokenHere");
+ Database databaseClient = apiClient.getDatabase(apiEndpoint);
+ // The databaseClient is now ready to perform data operations at the specified API endpoint
+
+
+
+
Parameters:
+
apiEndpoint - The URL of the Data API endpoint to connect to, specifying the API's location.
+
Returns:
+
A Database client tailored for interaction with the Data API at the provided API endpoint,
+ ready for executing data manipulation tasks.
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
diff --git a/astra-db-java/1.2.0/com/datastax/astra/client/DataAPIClients.html b/astra-db-java/1.2.0/com/datastax/astra/client/DataAPIClients.html
new file mode 100644
index 0000000..4ac7950
--- /dev/null
+++ b/astra-db-java/1.2.0/com/datastax/astra/client/DataAPIClients.html
@@ -0,0 +1,353 @@
+
+
+
+
+DataAPIClients (Java Client Library for Data API 1.2.0 API)
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Provides utility methods for initializing and configuring clients to interact with the Data API. This class
+ simplifies the creation of Data API clients by abstracting the complexities associated with configuring
+ clients for different environments and settings.
+
+
Depending on the application's requirements and the operational environment, DataAPIClients can
+ tailor the Data API client with appropriate configuration options such as authentication credentials, connection
+ timeouts, proxy settings, and more. This enables developers to quickly and easily set up their Data API clients
+ without delving into the intricate details of each configuration option.
+
+
Example Usage:
+
+
+ // Get you the client for a local deployment of Data API
+ DataAPIClient devClient = DataAPIClients.localClient();
+
+ // Get you the database for a local deployment of Data API
+ DataAPIClient devClient = DataAPIClients.localDatabase();
+
+ // Default target environment Astra Production
+ DataAPIClient devClient = DataAPIClients.astra("token");
+
+
+
+
Note: This class should be used as a starting point for initializing Data API clients. It is advisable to
+ review the specific configuration options relevant to your use case and adjust them accordingly.
Creates and configures a DataAPIClient for interaction with a local instance of Stargate, a
+ data gateway for working with Apache Cassandra®. This method is specifically designed for scenarios
+ where the application is intended to communicate with a Stargate instance running locally, facilitating
+ development and testing workflows by providing easy access to local database resources.
+
+
Returns:
+
A fully configured DataAPIClient ready for interacting with the local Stargate instance, equipped
+ with the necessary authentication token and targeting options for Cassandra. This client abstracts away
+ the complexities of direct database communication, providing a simplified interface for data operations.
Creates and configures a Database client specifically designed for interaction with a local instance
+ of Stargate. This method streamlines the process of setting up a client for local database interactions,
+ encapsulating both the creation of a DataAPIClient and its integration within a Database
+ abstraction. This setup is ideal for local development and testing, providing a straightforward path to
+ interact with Cassandra through Stargate with minimal setup.
+
+
Returns:
+
A Database client ready for use with a local Stargate instance, fully configured for immediate
+ interaction with the database. This client enables developers to focus on their application logic rather
+ than the intricacies of database connectivity and command execution.
Creates a DataAPIClient configured for interaction with Astra, DataStax's cloud-native database
+ as a service. This method streamlines the client setup by requiring only an authentication token, handling
+ the other configuration details internally to ensure compatibility with Astra's API and endpoints.
+
+
By specifying the destination as Astra in the DataAPIOptions, this method ensures that the
+ client is properly configured to communicate with Astra's infrastructure, leveraging the provided token
+ for authentication. This approach enables developers to quickly establish a connection to Astra for
+ database operations without manually setting up connection parameters and authentication details.
+
+
Parameters:
+
token - The authentication token required for accessing Astra. This token should be treated
+ securely and not exposed in public code repositories or unsecured locations.
+
Returns:
+
A DataAPIClient instance ready for use with Astra, fully configured with the provided
+ authentication token and set to target Astra as its destination.
+
+
Example usage:
+
+
+ DataAPIClient astraClient = DataAPIClients.astra("my_astra_auth_token");
+ // Use astraClient for database operations
+
+
Creates a DataAPIClient configured for interacting with Astra in a development environment. This
+ method simplifies the setup of a client specifically tailored for development purposes, where you might
+ need different configurations or less stringent security measures compared to a production environment.
+ The client is configured to target Astra's development environment, ensuring that operations do not
+ affect production data.
+
+
Parameters:
+
token - The authentication token required for accessing Astra's development environment. This token
+ should have the necessary permissions for development activities and be protected accordingly.
+
Returns:
+
A DataAPIClient instance ready for development activities with Astra, configured with the
+ provided authentication token and targeting Astra's development environment.
+
+
Example usage:
+
+
+ DataAPIClient devClient = DataAPIClients.astraDev("your_astra_dev_token");
+ // Utilize devClient for development database operations
+
+
Creates a DataAPIClient specifically configured for interacting with Astra in a test environment.
+ This setup is ideal for testing scenarios, where isolation from development and production environments
+ is critical to ensure the integrity and stability of test results. By directing the client to Astra's
+ test environment, it facilitates safe, isolated testing of database interactions without risking the
+ alteration of development or production data.
+
+
Parameters:
+
token - The authentication token required for accessing Astra's test environment. Ensure that this
+ token is designated for testing purposes to prevent unintended access to or effects on
+ non-test data and resources.
+
Returns:
+
A DataAPIClient instance specifically for use in testing scenarios with Astra, equipped
+ with the necessary authentication token and configured to target the test environment.
+
+
Example usage:
+
+
+ DataAPIClient testClient = DataAPIClients.astraTest("your_astra_test_token");
+ // Execute test database operations with testClient
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
diff --git a/astra-db-java/1.2.0/com/datastax/astra/client/DataAPIOptions.DataAPIClientOptionsBuilder.html b/astra-db-java/1.2.0/com/datastax/astra/client/DataAPIOptions.DataAPIClientOptionsBuilder.html
new file mode 100644
index 0000000..4276652
--- /dev/null
+++ b/astra-db-java/1.2.0/com/datastax/astra/client/DataAPIOptions.DataAPIClientOptionsBuilder.html
@@ -0,0 +1,563 @@
+
+
+
+
+DataAPIOptions.DataAPIClientOptionsBuilder (Java Client Library for Data API 1.2.0 API)
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Sets the delay between retry attempts when the number of retries is greater than 1.
+ This allows configuring the interval to wait before initiating a subsequent retry
+ after a failed attempt. The delay is specified in milliseconds.
+
+ If not explicitly set, the default delay is defined by DEFAULT_RETRY_DELAY_MILLIS,
+ which is 100 milliseconds.
+
+
+ Usage of this method is crucial in scenarios where repeated requests are made and a
+ gentle back-off strategy is desired to reduce the load on the server or to handle temporary
+ network issues gracefully.
+
+
+
Parameters:
+
retryDelay - the delay between two retry attempts, expressed in milliseconds.
+ Must be a non-negative number.
+
Returns:
+
a reference to this builder, allowing for method chaining.
+
+ Example usage:
+
+
+ DataAPIClientOptions
+ .builder()
+ .withHttpRetryDelayMillis(200); // Sets a 200ms delay between retries.
+
Returns the enum constant of this type with the specified name.
+The string must match exactly an identifier used to declare an
+enum constant in this type. (Extraneous whitespace characters are
+not permitted.)
+
+
Parameters:
+
name - the name of the enum constant to be returned.
A Data API database. This is the entry-point object for doing database-level
+ DML, such as creating/deleting collections, and for obtaining Collection
+ objects themselves. This class has a synchronous interface.
+
+ A Database comes with an "API Endpoint", which implies a Database object
+ instance reaches a specific region (relevant point in case of multi-region
+ databases).
+
+
+
+
+
+
+
+
Field Summary
+
+
Fields inherited from class com.datastax.astra.internal.command.AbstractCommandRunner
Create new database with a name on the specified cloud provider and region.
+ If the database with same name already exists it will be resumed if not active.
+ The method will wait for the database to be active.
+
+
Parameters:
+
name - database name
+
cloud - cloud provider
+
cloudRegion - cloud region
+
waitForDb - if set to true, the method is blocking
Create new database with a name on the specified cloud provider and region.
+ If the database with same name already exists it will be resumed if not active.
+ The method will wait for the database to be active.
Implementation of the DatabaseAdmin interface for Astra. To create the namespace the devops APi is leverage. To use this class a higher token permission is required.
namespaceName - The name of the namespace (or keyspace) to retrieve. This parameter should match the
+ exact name of the namespace as it exists in the database.
namespaceName - The name of the namespace (or keyspace) to retrieve. This parameter should match the
+ exact name of the namespace as it exists in the database.
+
tokenUser - token with reduce privileges compared to admin token in order to do dml options (CRUD).
Retrieves a stream of namespace names available in the current database. This method is essential for
+ applications that need to enumerate all namespaces to perform operations such as displaying available
+ namespaces to users, managing namespaces programmatically, or executing specific tasks within each
+ namespace. The returned Stream facilitates efficient processing of namespace names, enabling
+ operations like filtering, sorting, and mapping without the need for preloading all names into memory.
+
+
Example usage:
+
+
+ // Assuming 'client' is an instance of DataApiClient
+ Stream<String> namespaceNames = client.listNamespaceNames());
+ // Display names in the console
+ namespaceNames.forEach(System.out::println);
+
+
A Set containing the names of all namespaces within the current database. The stream
+ provides a flexible and efficient means to process the namespace names according to the application's needs.
Retrieve the list of embedding providers available in the current database. Embedding providers are services
+ that provide embeddings for text, images, or other data types. This method returns a map of provider names to
+ EmbeddingProvider instances, allowing applications to access and utilize the embedding services.
+
+
Example usage:
+
+
+ // Assuming 'client' is an instance of DataApiClient
+ Map<String, EmbeddingProvider> providers = client.listEmbeddingProviders());
+
+
Drops (deletes) the specified namespace from the database. This operation is idempotent; it will not
+ produce an error if the namespace does not exist. This method is useful for cleaning up data or removing
+ entire keyspaces as part of database maintenance or restructuring. Caution should be exercised when using
+ this method, as dropping a namespace will remove all the data, collections, or tables contained within it,
+ and this action cannot be undone.
+
+
Example usage:
+
+
+ // Assume 'client' is an instance of your data API client
+ String namespace = "targetNamespace";
+
+ // Drop the namespace
+ client.dropNamespace(namespace);
+
+ // The namespace 'targetNamespace' is now deleted, along with all its contained data
+
+
+
+ This example demonstrates how to safely drop a namespace by name. The operation ensures that even if the
+ namespace does not exist, the method call will not interrupt the flow of the application, thereby allowing
+ for flexible and error-tolerant code design.
namespace - The name of the namespace to be dropped. This parameter specifies the target namespace
+ that should be deleted. The operation will proceed silently and without error even if the
+ namespace does not exist, ensuring consistent behavior.
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
diff --git a/astra-db-java/1.2.0/com/datastax/astra/client/admin/DataAPIDatabaseAdmin.html b/astra-db-java/1.2.0/com/datastax/astra/client/admin/DataAPIDatabaseAdmin.html
new file mode 100644
index 0000000..89c1c88
--- /dev/null
+++ b/astra-db-java/1.2.0/com/datastax/astra/client/admin/DataAPIDatabaseAdmin.html
@@ -0,0 +1,517 @@
+
+
+
+
+DataAPIDatabaseAdmin (Java Client Library for Data API 1.2.0 API)
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Retrieves a stream of namespace names available in the current database. This method is essential for
+ applications that need to enumerate all namespaces to perform operations such as displaying available
+ namespaces to users, managing namespaces programmatically, or executing specific tasks within each
+ namespace. The returned Stream facilitates efficient processing of namespace names, enabling
+ operations like filtering, sorting, and mapping without the need for preloading all names into memory.
+
+
Example usage:
+
+
+ // Assuming 'client' is an instance of DataApiClient
+ Stream<String> namespaceNames = client.listNamespaceNames());
+ // Display names in the console
+ namespaceNames.forEach(System.out::println);
+
+
A Set containing the names of all namespaces within the current database. The stream
+ provides a flexible and efficient means to process the namespace names according to the application's needs.
Retrieve the list of embedding providers available in the current database. Embedding providers are services
+ that provide embeddings for text, images, or other data types. This method returns a map of provider names to
+ EmbeddingProvider instances, allowing applications to access and utilize the embedding services.
+
+
Example usage:
+
+
+ // Assuming 'client' is an instance of DataApiClient
+ Map<String, EmbeddingProvider> providers = client.listEmbeddingProviders());
+
+
Retrieves a Database instance that represents a specific database (or namespace) based on the
+ provided namespace name.
+
+
Example usage:
+
+
+ // Assume 'client' is an instance of your data API client
+ String namespaceName = "exampleNamespace";
+
+ // Retrieve the namespace instance
+ DataApiNamespace namespace = client.getNamespace(namespaceName);
+
+ // Now, 'namespace' can be used to perform operations within 'exampleNamespace'
+
+
+
+ This example illustrates how to obtain a DataApiNamespace instance for a specified namespace name,
+ which then enables the execution of various database operations within that namespace. It highlights the
+ method's role in facilitating direct interaction with different parts of the database.
namespaceName - The name of the namespace (or keyspace) to retrieve. This parameter should match the
+ exact name of the namespace as it exists in the database.
+
Returns:
+
A DataApiNamespace instance that encapsulates the operations and information specific to the
+ given namespace.
Drops (deletes) the specified namespace from the database. This operation is idempotent; it will not
+ produce an error if the namespace does not exist. This method is useful for cleaning up data or removing
+ entire keyspaces as part of database maintenance or restructuring. Caution should be exercised when using
+ this method, as dropping a namespace will remove all the data, collections, or tables contained within it,
+ and this action cannot be undone.
+
+
Example usage:
+
+
+ // Assume 'client' is an instance of your data API client
+ String namespace = "targetNamespace";
+
+ // Drop the namespace
+ client.dropNamespace(namespace);
+
+ // The namespace 'targetNamespace' is now deleted, along with all its contained data
+
+
+
+ This example demonstrates how to safely drop a namespace by name. The operation ensures that even if the
+ namespace does not exist, the method call will not interrupt the flow of the application, thereby allowing
+ for flexible and error-tolerant code design.
namespace - The name of the namespace to be dropped. This parameter specifies the target namespace
+ that should be deleted. The operation will proceed silently and without error even if the
+ namespace does not exist, ensuring consistent behavior.
Defines the core client interface for interacting with the Data API, focusing on CRUD (Create, Read, Update, Delete)
+ operations for namespaces. This interface extends the CommandRunner, incorporating methods that
+ allow for the execution of various data manipulation and query commands within the scope of a namespace.
+
+ Implementations of this interface should provide concrete methods for namespace management, including the
+ creation, retrieval, updating, and deletion of namespaces. By leveraging the extended command runner capabilities,
+ it facilitates a streamlined and efficient approach to data management within the specified context.
+
+
+
Example usage:
+
+
+
+ // Initialization of the client
+ DataApiClient client1 = DataApiClients.create("http://<>endpoint>", "<token>", new HttpClientOptions());
+
+ // Example operation: Create a new namespace
+ DataApiNamespace newNamespace = client.createNamespace("exampleNamespace");
+
+ // Example operation: Fetch a namespace
+ DataApiNamespace fetchedNamespace = client.getNamespace("exampleNamespace");
+
+ // Example operation: Delete a namespace
+ client.deleteNamespace("exampleNamespace");
+
+
Retrieves a stream of namespace names available in the current database. This method is essential for
+ applications that need to enumerate all namespaces to perform operations such as displaying available
+ namespaces to users, managing namespaces programmatically, or executing specific tasks within each
+ namespace. The returned Stream facilitates efficient processing of namespace names, enabling
+ operations like filtering, sorting, and mapping without the need for preloading all names into memory.
+
+
Example usage:
+
+
+ // Assuming 'client' is an instance of DataApiClient
+ Stream<String> namespaceNames = client.listNamespaceNames());
+ // Display names in the console
+ namespaceNames.forEach(System.out::println);
+
+
+
+
Returns:
+
A Set containing the names of all namespaces within the current database. The stream
+ provides a flexible and efficient means to process the namespace names according to the application's needs.
Retrieve the list of embedding providers available in the current database. Embedding providers are services
+ that provide embeddings for text, images, or other data types. This method returns a map of provider names to
+ EmbeddingProvider instances, allowing applications to access and utilize the embedding services.
+
+
Example usage:
+
+
+ // Assuming 'client' is an instance of DataApiClient
+ Map<String, EmbeddingProvider> providers = client.listEmbeddingProviders());
+
+
Asynchronously retrieves a stream of namespace names available in the current database. This method facilitates
+ non-blocking operations by allowing the application to continue executing other tasks while the list of namespace
+ names is being fetched. The method returns a CompletableFuture that, upon completion, provides a
+ Stream of namespace names, enabling efficient and flexible processing through stream operations.
+
Example usage:
+
+
+ // Assuming 'client' is an instance of DataApiClient
+ CompletableFuture<Stream<String>> futureNamespaces = client.listNamespaceNamesAsync();
+ // Process the stream of names asynchronously once it's available
+ futureNamespaces.thenAccept(streamOfNames -> {
+ Stream<String> namespaceNames = streamOfNames);
+ namespaceNames.forEach(System.out::println);
+ }).exceptionally(ex -> {
+ System.out.println("An error occurred: " + ex.getMessage());
+ return null;
+ });
+
+
+
+
Returns:
+
A CompletableFuture that, when completed, provides a stream containing the names
+ of all namespaces within the current database. This allows for the asynchronous processing of namespace
+ names with the flexibility and efficiency benefits of using a stream.
Retrieves a Database instance that represents a specific database (or namespace) based on the
+ provided namespace name.
+
+
Example usage:
+
+
+ // Assume 'client' is an instance of your data API client
+ String namespaceName = "exampleNamespace";
+
+ // Retrieve the namespace instance
+ DataApiNamespace namespace = client.getNamespace(namespaceName);
+
+ // Now, 'namespace' can be used to perform operations within 'exampleNamespace'
+
+
+
+ This example illustrates how to obtain a DataApiNamespace instance for a specified namespace name,
+ which then enables the execution of various database operations within that namespace. It highlights the
+ method's role in facilitating direct interaction with different parts of the database.
+
+
Parameters:
+
namespaceName - The name of the namespace (or keyspace) to retrieve. This parameter should match the
+ exact name of the namespace as it exists in the database.
+
Returns:
+
A DataApiNamespace instance that encapsulates the operations and information specific to the
+ given namespace.
Drops (deletes) the specified namespace from the database. This operation is idempotent; it will not
+ produce an error if the namespace does not exist. This method is useful for cleaning up data or removing
+ entire keyspaces as part of database maintenance or restructuring. Caution should be exercised when using
+ this method, as dropping a namespace will remove all the data, collections, or tables contained within it,
+ and this action cannot be undone.
+
+
Example usage:
+
+
+ // Assume 'client' is an instance of your data API client
+ String namespace = "targetNamespace";
+
+ // Drop the namespace
+ client.dropNamespace(namespace);
+
+ // The namespace 'targetNamespace' is now deleted, along with all its contained data
+
+
+
+ This example demonstrates how to safely drop a namespace by name. The operation ensures that even if the
+ namespace does not exist, the method call will not interrupt the flow of the application, thereby allowing
+ for flexible and error-tolerant code design.
+
+
Parameters:
+
namespace - The name of the namespace to be dropped. This parameter specifies the target namespace
+ that should be deleted. The operation will proceed silently and without error even if the
+ namespace does not exist, ensuring consistent behavior.
Asynchronously drops (deletes) the specified namespace from the database. This operation is idempotent, meaning
+ it will not produce an error if the namespace does not exist. Performing this operation asynchronously ensures
+ that the calling thread remains responsive, and can be particularly useful for applications that require high
+ availability and cannot afford to block on potentially long-running operations. Just like its synchronous counterpart,
+ this method should be used with caution as dropping a namespace will remove all associated data, collections,
+ or tables, and this action is irreversible.
+
+
Example usage:
+
+
+ // Assume 'client' is an instance of your data API client
+ String namespace = "asyncTargetNamespace";
+
+ // Asynchronously drop the namespace
+ client.dropNamespaceAsync(namespace);
+
+ // The namespace 'asyncTargetNamespace' is now being deleted in the background, along with all its contained data
+
+
+
+ This example illustrates the non-blocking nature of dropping a namespace. It demonstrates the method's utility in
+ maintaining application responsiveness, even when performing potentially long-running database operations.
+
+
Parameters:
+
namespace - The name of the namespace to be dropped. This is the target namespace that will be deleted.
+ The asynchronous nature of this method means that it will execute without blocking the calling
+ thread, regardless of whether the namespace exists or not, ensuring a consistent and responsive
+ application behavior.
public class DataAPIFaultyResponseException
+extends DataApiException
+
Represents a specific kind of DataApiException that is thrown when the response
+ received from the Data API does not match the expected format or content. This exception
+ is typically thrown in situations where the API response is either malformed, incomplete,
+ or contains an error code indicating a failure that needs to be addressed by the client application.
+
+ This exception encapsulates details about the command that triggered the erroneous response
+ and the actual response received from the Data API, allowing for more informed error handling
+ and debugging. It is advisable to catch this exception specifically when performing operations
+ that are critical and have known potential for response inconsistencies.
+
+
Example usage:
+
+
+ try {
+ ApiResponse response = dataApiClient.executeCommand(someCommand);
+ if (!response.isSuccessful()) {
+ throw new DataApiFaultyResponseException(someCommand, response, "The response indicates a failure.");
+ }
+ // Process the successful response
+ } catch (DataApiFaultyResponseException e) {
+ // Handle scenarios where the API response was not as expected
+ log.error("Faulty response received for command: " + e.getCommand() + " with message: " + e.getMessage(), e);
+ }
+
+
Represents a runtime exception that occurs within the Data API client. This exception
+ is thrown to indicate a problem encountered while performing operations such as querying,
+ updating, or deleting data through the Data API. It acts as a wrapper for lower-level exceptions
+ to provide a more general fault indication to the client code.
+
+ This exception should be caught and handled by the client application to gracefully
+ manage API-related errors, such as connectivity issues, data format mismatches, or unauthorized
+ access attempts. It is recommended to log the details of this exception and present a user-friendly
+ message to the end-user, if applicable.
+
+
Example usage:
+
+
+ try {
+ collection.insertOne(document);
+ } catch (DataApiException e) {
+ // Handle the exception, e.g., log it or display an error message
+ log.error("Error performing Data API operation: " + e.getMessage(), e);
+ }
+
+
Extends DataApiException to specifically address errors encountered during the
+ processing of responses from the Data API. This exception is particularly useful when
+ a command issued to the API is internally divided into multiple sub-operations, each of
+ which might succeed or fail independently. It aggregates detailed information about each
+ sub-operation, including execution times and any errors encountered, facilitating comprehensive
+ error tracking and debugging.
+
+ The commandsList attribute of this exception holds a collection of ExecutionInfos
+ objects, each representing the outcome of a sub-operation. This detailed breakdown helps in
+ identifying specific points of failure within a complex command execution sequence, making it
+ easier for developers to diagnose issues and implement more robust error handling and recovery
+ strategies.
+
+
Example usage:
+
+
+ try {
+ List<Document> longListOfDocuments;
+ collection.insertMany(longListOfDocuments);
+ } catch (DataApiResponseException e) {
+ e.getCommandsList().forEach(executionInfo -> {
+ if (executionInfo.hasErrors()) {
+ log.error("Error in sub-operation: " + executionInfo.getErrorDetails());
+ }
+ });
+ // Handle the exception or notify the user
+ }
+
+
Represents a specific kind of DataApiException that is thrown when the response
+ received from the Data API does not match the expected format or content.
Represents a specific kind of DataApiException that is thrown when the response
+ received from the Data API does not match the expected format or content.
Returns the enum constant of this type with the specified name.
+The string must match exactly an identifier used to declare an
+enum constant in this type. (Extraneous whitespace characters are
+not permitted.)
+
+
Parameters:
+
name - the name of the enum constant to be returned.
Returns the enum constant of this type with the specified name.
+The string must match exactly an identifier used to declare an
+enum constant in this type. (Extraneous whitespace characters are
+not permitted.)
+
+
Parameters:
+
name - the name of the enum constant to be returned.
Constructs an iterable that provides distinct elements from a specified collection, optionally filtered by
+ a given criterion. This iterable allows for iterating over unique values of a specific field within the collection's documents,
+ which can be particularly useful for data analysis, reporting, or implementing specific business logic that requires
+ uniqueness in the dataset.
+
+ The distinct elements are determined based on the fieldName parameter, ensuring that each value provided during
+ iteration is unique with respect to this field across all documents in the collection. The filter parameter allows
+ for narrowing down the documents considered by this iterable, offering the capability to perform more targeted queries.
+
+
+
Parameters:
+
collection - The source collection client, used to fetch documents and, if necessary, subsequent pages of results.
+ This collection should be capable of executing queries and returning filtered results.
+
fieldName - The name of the field for which unique values are to be iterated over. This field's values are used
+ to determine the distinctness of elements provided by this iterable.
+
filter - The original filter used to limit the documents considered for finding distinct values. This filter
+ allows for the specification of criteria that documents must meet to be included in the iteration.
+
fieldClass - The class of the field values being iterated over. This parameter is used to ensure type safety
+ and proper casting of the field values extracted from the documents in the collection.
Implementing a logic of iterator combining current page and paging. A local iterator is started on elements
+ of the processing page. If the local iterator is exhausted, the flag 'nextPageState' can tell us is there are
+ more elements to retrieve. if 'nextPageState' is not null the next page is fetch at Iterable level and the
+ local iterator is reinitialized on the new page.
Gets the value of the given key, casting it to the given Class<T>. This is useful to avoid having casts in client code,
+ though the effect is the same. So to get the value of a key that is of type String, you would write String name =
+ doc.get("name", String.class) instead of String name = (String) doc.get("x") .
+
+
Type Parameters:
+
T - the type of the class
+
Parameters:
+
key - the key
+
clazz - the non-null class to cast the value to
+
Returns:
+
the value of the given key, or null if the instance does not contain this key.
Gets the list value of the given key, casting the list elements to the given Class<T>. This is useful to avoid having
+ casts in client code, though the effect is the same.
+
+
Type Parameters:
+
T - the type of the class
+
Parameters:
+
key - the key
+
clazz - the non-null class to cast the list value to
+
Returns:
+
the list value of the given key, or null if the instance does not contain this key.
+
Throws:
+
ClassCastException - if the elements in the list value of the given key is not of type T or the value is not a list
Gets the list value of the given key, casting the list elements to Class<T> or returning the default list value if null.
+ This is useful to avoid having casts in client code, though the effect is the same.
+
+
Type Parameters:
+
T - the type of the class
+
Parameters:
+
key - the key
+
clazz - the non-null class to cast the list value to
+
defaultValue - what to return if the value is null
+
Returns:
+
the list value of the given key, or the default list value if the instance does not contain this key.
Returns the enum constant of this type with the specified name.
+The string must match exactly an identifier used to declare an
+enum constant in this type. (Extraneous whitespace characters are
+not permitted.)
+
+
Parameters:
+
name - the name of the enum constant to be returned.
Creates a filter that matches all documents where the value of _id field equals the specified value. Note that this doesn't
+ actually generate a $eq operator, as the query language doesn't require it.
T - The type of documents contained in the collection. This generic type allows FindIterable
+ to be used with any type of document, making it a flexible solution for a wide variety of data models.
Represents the result of a 'find' command executed on a collection, providing an iterable interface to navigate
+ through the result set. This class extends PageableIterable to offer efficient, page-by-page iteration
+ over the results, which is particularly useful for handling large datasets.
+
+ Utilizing a lazy-loading approach, FindIterable allows for seamless navigation through the result set
+ without the necessity of loading all documents into memory at once. This makes it an ideal choice for applications
+ that need to process or display large amounts of data with minimal memory footprint. As users iterate over the
+ collection, subsequent pages of results are fetched as needed, ensuring efficient use of resources.
+
+
+ This approach is advantageous in scenarios where the full result set might be too large to store in memory
+ comfortably or when only a portion of the results is needed by the application at any given time. By iterating
+ over the results with FindIterable, applications can maintain lower memory usage while still having
+ the flexibility to access the entire result set.
+
Implementing a logic of iterator combining current page and paging. An local iterator is started on elements
+ of the processing page. If the local iterator is exhausted, the flag 'nextPageState' can tell us is there are
+ more elements to retrieve. if 'nextPageState' is not null the next page is fetch at Iterable level and the
+ local iterator is reinitialized on the new page.