Open Jupyter Notebook and open the file FinalCVProject.ipynb
Download the dataset and extract it.
Change the path in the code where your dataset is downloaded or either extract it in the same folder.
Run the python file "create_train_test".
It will make two separate folders for training and testing.
The splitting is done according to split file provided in the official website of UCF101.
This code was available online to split the dataset.
Now, run the cells in the .ipynb file one by one and we are done!
Go to the link: Google Drive
Download the folder named "data" and save it in your google drive.
Open google colab and run the FinalCVProject.ipynb file.
The folder already contains extracted features and images so it won't take much time to run!
Video analysis tasks have seen great variations and it has been moving from inferring
the present state to predicting the future state. This has been possible with the
developments in the field of Computer Vision and Machine Learning. In vision-based
action recognition tasks, various human actions are inferred based upon the complete
movements of that action. It also helps in prediction of future state of the human by
inferring the current action being performed by that human. It has become a hot topic
in recent years since it applies to real world problems directly, be it visual surveillance,
autonomous driving vehicle, entertainment etc. Many research works have been done in
this field to develop a good human action recognizer. Also, it is expected that more and
more work is going to be done in this regards since Human Action Recognition finds its
use in numerous applications.
In this report, we will be seeing the details of the work done by us and the methodology
adopted for the same. We will go through the techniques used to implement a system
that is suitable for human activity recognition. We will also compare the different models
used for action recognition and note which one is better than other. Finally, we will
conclude by noting down the results we get from the final model we have made.
Given a video, is it possible to recognize the action being performed in that video by an automatic system? An action recognition system is built on basic steps: first, the input video or sequence of frames; second, the extraction of low-level features from the frames; and finally, mid-level pose/gesture or action descriptions from low-level features.
The dataset used in building our model is UCF101. UCF101 is an action recognition data set
of realistic action videos, collected from YouTube, having 101 action categories. This data
set is an extension of UCF50 data set which has 50 action categories.
The action categories can be divided into five types: 1)Human-Object Interaction 2) Body-
Motion Only 3) Human-Human Interaction 4) Playing Musical Instruments 5) Sports.
We used “Google Colab” to run the programs. It provides us approx. 12 GB of RAM and variable GPU depending on the traffic.
- Working with the dataset.
- Extracting features from the frames using CNN.
- Passing those features into a recurrent neural network to train the model and classifying.
- Saving the best model and then using it to classify the videos.
We downloaded the dataset “UCF101” and extracted in google drive. It contains 13320
videos belonging to 101 different classes.
Then we separated the video in two folders namely “test” and “train”. This splitting was
based on the test train spilt file provided in their official site.
Then, we extracted the frames from each video in their corresponding folders as .jpg files.
To extract features from the images, we used a pre-trained model provided by Keras named
Inception-V3.
Inception-V3 is a model provided by Keras whose weights pre-trained on ImageNet dataset,
which is a huge dataset consisting of large number of images of different classes. It saves us
from building our own architecture from scratch which could take far more time and efforts
and not necessarily provide better results than when using Inception-V3.
Thus, in our project we used this Inception-V3 model to extract features. In our initial work,
we just settled with this work by fine tuning some outermost layers and predicting the class
solely based on this. But, we improved our design by using RNN which is shown in next
step.
Instead of classifying the images just with CNN, we now use CNN+RNN model. Here the
feature output from Inception-V3 are first taken by removing the top classifying layer. It
gives a vector of features.
We used LSTM, which is a special kind of RNN. It is also provided by keras in python. The
features we obtained from Inception-V3, are passed to this LSTM architecture. After that,
we defined some of our own layers. We tried with dense layers with ‘relu’ activation with
some dropouts between multiple layers. After trying with different layers, we settled down
to a 2048-wide LSTM layer followed by a 512 dense layer and used 0.5 dropout. Note that
we used the features from a video as input to the LSTM. Instead of passing features from every
frame, we reduced the number of frames to be passed. This reduced overfitting and also
made the program faster due to less features being processed now. Features from approx.
30-50 frames per video are sent as sequence to the LSTM.
At the final layer, we used ‘softmax’ activation, which is basically used to provide a class as
output in terms of probability, i.e. it turns the input numbers to probabilities that sum to 1.
Thus, it outputs a probability distribution.
We used “categorical cross entropy” as a loss measure and adam optimizer was used with
learning rate of .Also, the metrics for training and testing was ‘accuracy’ and ‘top 5 categorical
accuracy’. Then we compiled our model using these parameters and are ready for
training.
Thus training is based on above mentioned architecture. The training and testing samples
are divided according to the file provided in official website. This ensures uniform division
of videos.
The model is trained to learn in such a way to minimize the validation loss. When we stop
learning, i.e. the validation loss keeps on increasing, then we stop the training. The accuracy
metrics is used.
When doing the training, we save the model weights whenever validation loss is decreased.
When training finishes, we get the recently saved weights.
As written above, we have saved the model weights for that iteration where we get the least
validation loss. This is generally a good practice because if we save model with best accuracy
only, no matter what the loss is, then we can’t say that it is the best model. So, least loss is
what we used when specifying the best model. Although it may vary depending on the tasks
given, but generally for HAR, it is good enough.
Now, to classify videos, we just define the same architecture we defined for training. Then
we load the model weights and now we are ready to classify the videos. Just take a video,
extract frames and then use Inception-V3 to extract features from that video. Pass those
features into the architecture and we get the class to which the video belongs.
We trained our model on UCF101 dataset using the architecture described in the previous
section and the results were obtained.
We experimented with different hidden layers added to our architecture so as to get the best
model.
Earlier the method we used included CNN only and the validation accuracy was very low in
that case when compared to the new model we defined.
The following graphs shows various accuracies and loss we found out during the experiment :
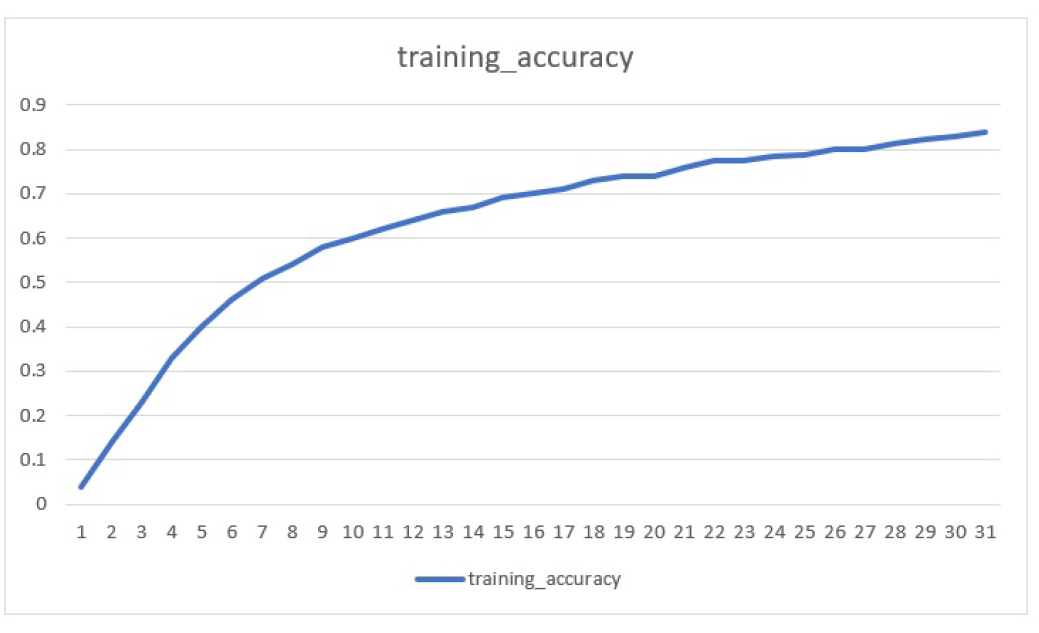
We reached training accuracy of approx. 84 percent and that accuracy was achieved at
around 30 epochs.
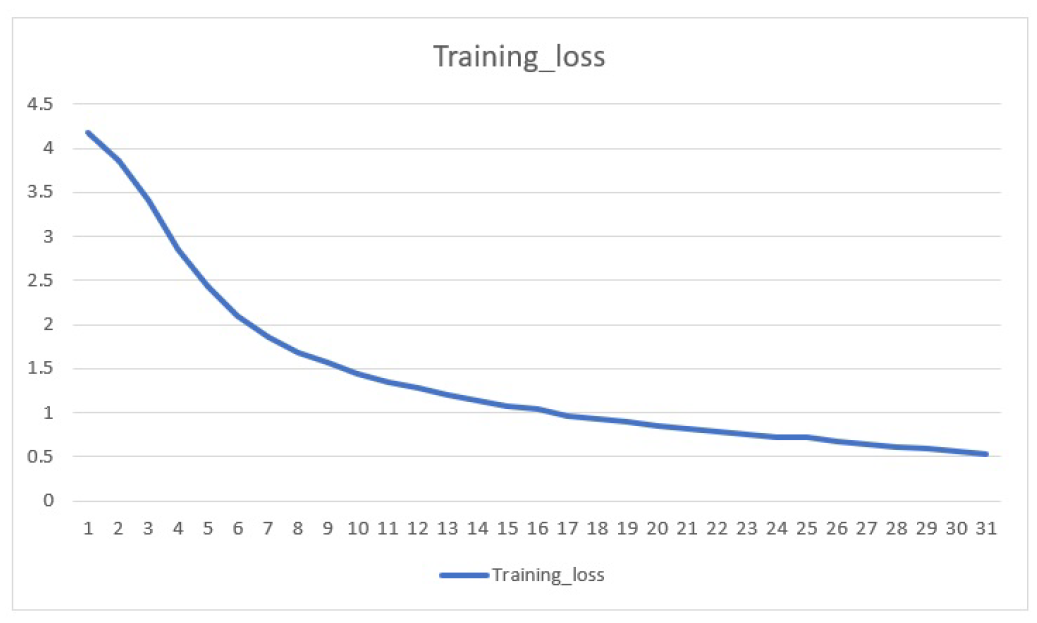
The training loss decreased with number of epochs. It dropped down from 4.2 to 0.6 with
30 epochs.
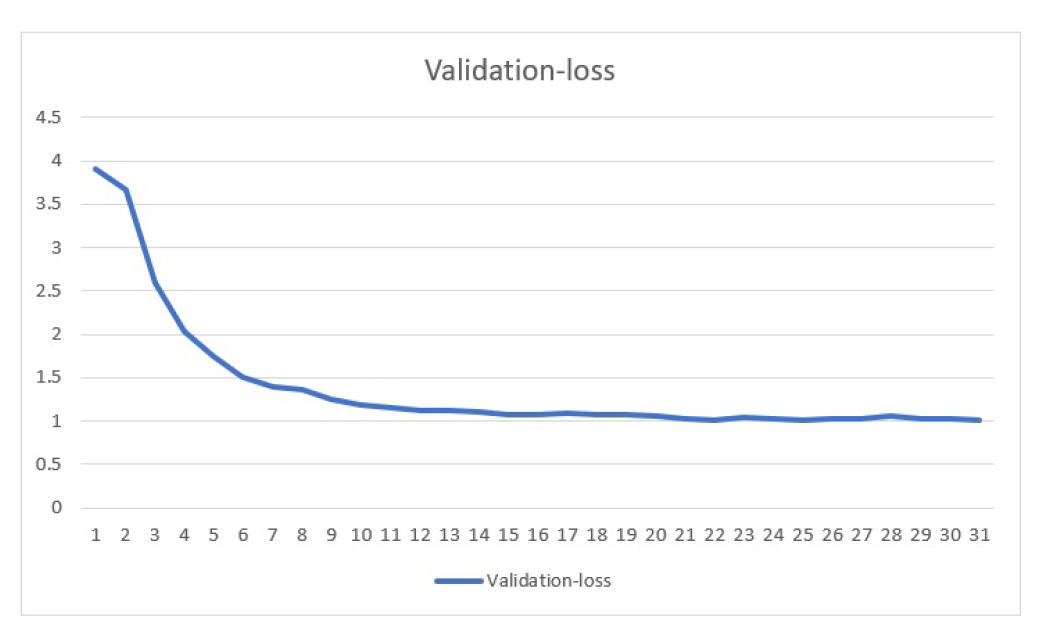
The validation loss was initially 3.8 and gradually it decreases to around 1 after 30 epochs.
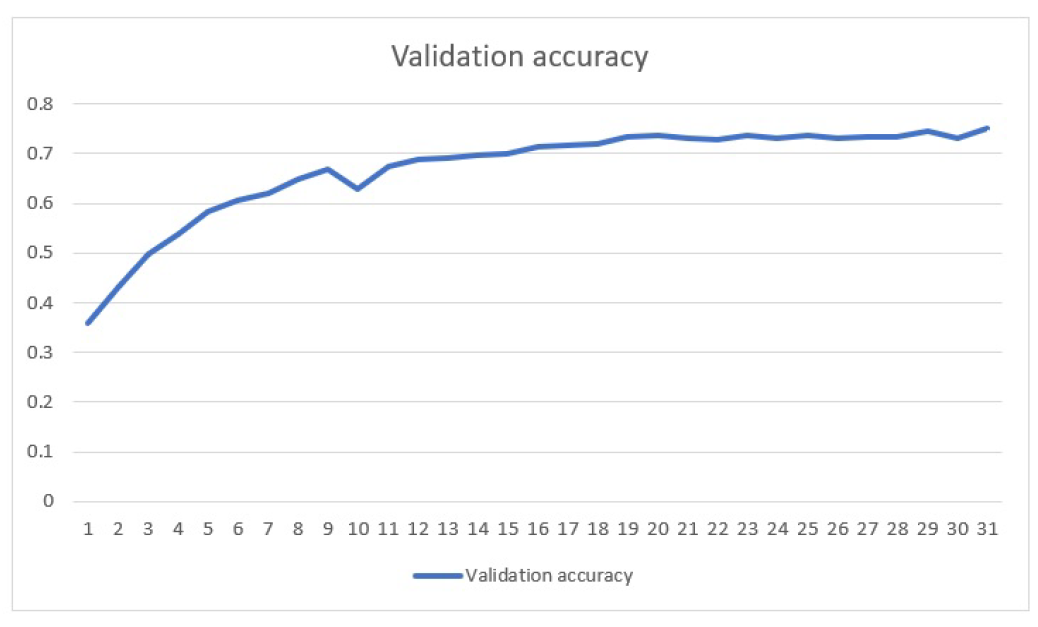
The validation accuracy we got on UCF101 data was around 74 percent and was achieved
with 30 epochs.
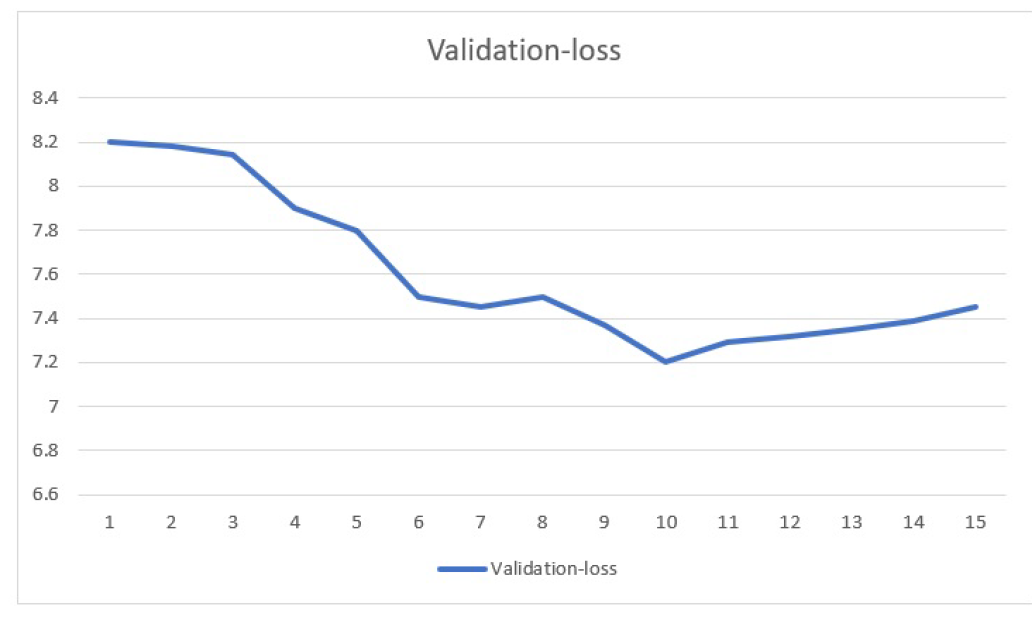
In CNN only model, we obtained best loss of 7.2 which is much higher than what we
obtained in our new model which was nearly 1.
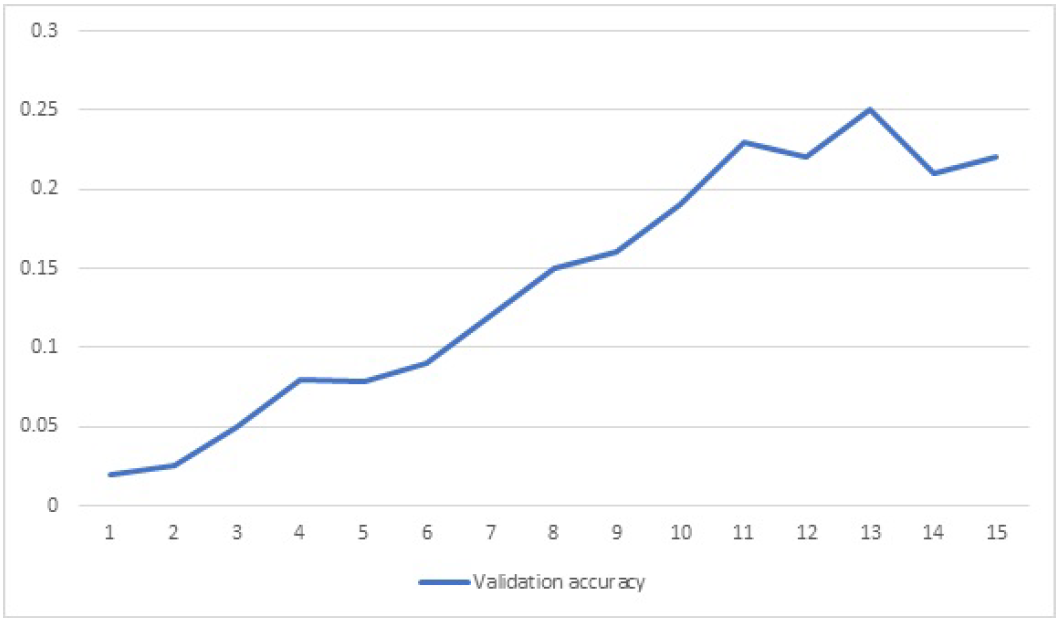
We reached around 25 percent accuracy only on validation data when using the CNN model
only. This is very much less compared to 74 percent accuracy we obtained on CNN+RNN
model.
We can use deep learning models to solve the human action recognition problem. When
we do not take into account the temporal nature of the video into account, then we lack in
classifying videos with good accuracy.
Spatio-temporal understanding provides a better way to human action recognition.
The new model we used for implementation gave about 74-75% validation accuracy on such
a big dataset UCF101. And the loss was approximately 1. Whereas, the previous model just
gave 25% accuracy with a higher loss.
Although this 74% accuracy achieved is not that good when compared to 94% state-of-theart
accuracy, yet it is not that bad even because we were limited by the resources and lack of
knowledge of some other better techniques.
We hope to learn new techniques to solve HAR problem which will enhance our understanding.