ZooKeeper Operator is to manage ZooKeeper service instances deployed on the Kubernetes cluster. It is built using the Kubebuilder SDK, which is part of the Kubebuilder.
目前operator主要实现如下功能:
- 快速部署
- 安全伸缩容
- 自动化监控
- 故障自愈
- 可视化操作
Operator设计第一步是定义声明式接口的Item,spec主要包含节点资源、监控组件、副本数、持久化存储。
apiVersion: zk.cache.ghostbaby.io/v1alpha1
kind: Workload
metadata:
name: workload-sample
namespace: pg
spec:
version: v3.5.6
cluster:
name: test
resources:
requests:
cpu: 1000m
memory: 1Gi
limits:
cpu: 2000m
memory: 2Gi
exporter:
exporter: true
exporterImage: ghostbaby/zookeeper_exporter
exporterVersion: v3.5.6
disableExporterProbes: false
nodeCount: 3
storage:
persistentVolumeClaim:
metadata:
name: zookeeper-data
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
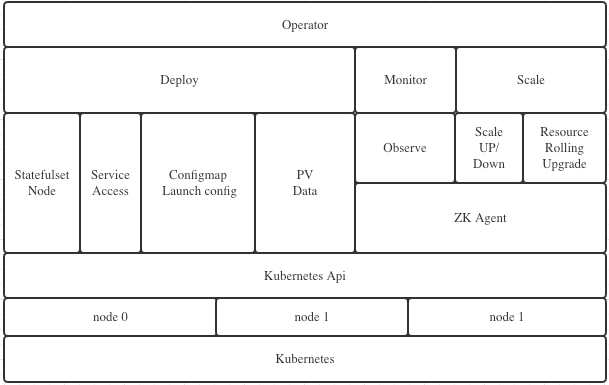
storageClassName: nfs-storageOperator主要包含:Depoloy、Monitor、Scale 三个大模块。
- Deploy,主要用于生成和创建 Statefulset、Service、ConfigMap、PV 等原生资源,用于快速部署 zookeeper 集群。
- Monitor,主要用于生成和创建ServiceMonitor、PrometheusRule资源,用于自动化注册target、添加告警策略,实现对集群的监控和告警。
- Scale,主要用于把控扩缩容以及滚动升级的进度,确保以最少的主从切换完成重启。
-
Kubernetes Lables
- Labels是一对key/value,被关联到特定对象上,标签一般用来表示同一类资源,用来划分特定的对象,一个对象可以有多个标签,但是,key值必须是唯一的。这里我们将在list-watch的时候用这个labels进行过滤,从所有的k8s event中过滤出符合特定label的event,用来触发operator的主流程。
-
Kubernetes Informer
-
watch可以是k8s内建的资源或者是自定义的资源。当reflector通过watch API接收到有关新资源实例存在的通知时,它使用相应的列表API获取新创建的对象,并将其放入watchHandler函数内的Delta Fifo队列中。
-
Informer:informer从Delta Fifo队列中弹出对象。执行此操作的功能是processLoop。base controller的作用是保存对象以供以后检索,并调用我们的控制器将对象传递给它。
-
Indexer:索引器提供对象的索引功能。典型的索引用例是基于对象标签创建索引。 Indexer可以根据多个索引函数维护索引。Indexer使用线程安全的数据存储来存储对象及其键。 在Store中定义了一个名为MetaNamespaceKeyFunc的默认函数,该函数生成对象的键作为该对象的 / 组合。
-
labels:
app: zookeeper
app.kubernetes.io/instance: zookeeper-sample
app.kubernetes.io/managed-by: zookeeper-operator
app.kubernetes.io/name: zookeeper
app.kubernetes.io/part-of: zookeeper
component: zookeeper
zookeeper: zookeeper-sample- InitContainer
- 配置文件初始化容器,主要用于zk config文件复制到工作区域。
- Container
- 主进程容器
- 监控容器
- Agent
zoo.cfg.dynamic,这个文件同样以configmap方式挂入主容器,主要用于zk节点发现和注册,下面将详细介绍下这个zk 3.5之后的特性。
- 具体可以参考ZooKeeper 动态重新配置
server.1=zookeeper-sample-0.zookeeper-sample.default.svc.cluster.local:2888:3888:participant;0.0.0.0:2181
server.2=zookeeper-sample-1.zookeeper-sample.default.svc.cluster.local:2888:3888:participant;0.0.0.0:2181
server.3=zookeeper-sample-2.zookeeper-sample.default.svc.cluster.local:2888:3888:participant;0.0.0.0:2181
server.4=zookeeper-sample-3.zookeeper-sample.default.svc.cluster.local:2888:3888:participant;0.0.0.0:2181
server.5=zookeeper-sample-4.zookeeper-sample.default.svc.cluster.local:2888:3888:participant;0.0.0.0:2181- 更新目录权限
设置data和logs目录的权限,确保zk能够正常启动。
echo "chowning /data to zookeeper:zookeeper"
chown -v zookeeper:zookeeper /data
echo "chowning /logs to zookeeper:zookeeper"
chown -v zookeeper:zookeeper /logs- 环境变量
POD_IP、POD_NAME,主要将node的pod ip和名称传到pod内部,方便容器内部调用。
ZK_SERVER_HEAP,这变量为限制zk启动heapsize大小,由operator根据request内部大小设置,zk启动会读取这个变量。
- name: POD_IP
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: status.podIP
- name: POD_NAME
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.name
- name: ZK_SERVER_HEAP
value: "2048"
- name: ZK_CLIENT_HEAP
value: "512"- Readiness探针
主要通过zk 客户端端口传入ruok命令,检查返回码,返回imok认为zk node已经准备完毕,zk node将会被更新到上面说到的zoo.cfg.dynamic文件,zk cluster将会自动发现该节点。
ZK_CLIENT_PORT=${ZK_CLIENT_PORT:-2181}
OK=$(echo ruok | nc 127.0.0.1 $ZK_CLIENT_PORT)
if [ "$OK" == "imok" ]; then
exit 0
else
exit 1
figithub项目(https://github.com/dabealu/zookeeper-exporter) exporter跟随主进程一同启动,后续会介绍如何注册到prometheus target以及告警策略。
- 暴露端口
9114,该端口为exporter服务端口,通过servicemonitor注册prometheus target时将通过labels匹配该端口。
1988,该端口为zk-agent服务端口,通过该接口operator可以查询到当前节点运行状态,后面会详解介绍。
2181,该端口为zk 客户端端口,该端口创建k8s headless 模式 svc,方便客户端一次获取所有节点ip。
3888,选举leader使用
2888,集群内机器通讯使用(Leader监听此端口)
ports:
- name: client
port: 2181
protocol: TCP
targetPort: 2181
- name: server
port: 2888
protocol: TCP
targetPort: 2888
- name: leader-election
port: 3888
protocol: TCP
targetPort: 3888
- name: http-metrics
port: 9114
protocol: TCP
targetPort: 9114
- name: http-agent
port: 1988
protocol: TCP
targetPort: 1988- 暴露方式
这里主要k8s service的两种模式:Headless和Cluster
Headless Services,简单而言就是,每次访问headless service,kube-dns将返回后端一组ip,在我们这种场景下,即会返回es 所有节点ip给客户端,再由客户端自己判断通过哪个ip访问es集群。
Cluster,这种模式是默认配置,创建此类service之后,将分配一个cluster ip,这个ip类似vip,每次访问这个service name,kube-dns将会随机返回一个节点ip。
operator在创建service的时候,上面两种都会创建,headless类型主要给 k8s内部应用访问,cluster类型主要通过NodePort暴露给外部应用访问。
- 配置文件
autopurge.purgeInterval=24
autopurge.snapRetainCount=20
initLimit=10
syncLimit=5
skipACL=yes
maxClientCnxns=300
4lw.commands.whitelist=cons, envi, conf, crst, srvr, stat, mntr, ruok
tickTime=2000
dataDir=/data
dataLogDir=/logs
reconfigEnabled=true
standaloneEnabled=false
dynamicConfigFile=/conf/zoo.cfg.dynamic.c00000002
- PersistentVolume
StorageClass PROVISIONER: diskplugin.csi.alibabacloud.com,阿里云CSI插件实现了Kubernetes平台使用阿里云云存储卷的生命周期管理,支持动态创建、挂载、使用云数据卷。 当前的CSI实现基于K8S 1.14以上的版本。
云盘CSI插件支持动态创建云盘数据卷、挂载数据卷。云盘是一种块存储类型,只能同时被一个负载使用(ReadWriteOnce)。
operator会将crd中配置的pvc信息,透传到sts中去,并挂载到zk data目录下 。
selector.matchLabels,这里通过zookeeper: zookeeper-sample来匹配service
port: http-metrics,这里通过匹配service中到port name来注册到prometheus target
operator调用prometheus-operator client完成servicemonior资源的创建,实现新建zk集群自动注册到prometheus的功能。
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
app: zookeeper
app.kubernetes.io/instance: zookeeper-sample
app.kubernetes.io/managed-by: zookeeper-operator
app.kubernetes.io/name: zookeeper
app.kubernetes.io/part-of: zookeeper
component: zookeeper
zookeeper: zookeeper-sample
name: zookeeper-sample
namespace: default
spec:
endpoints:
- interval: 30s
port: http-metrics
namespaceSelector: {}
selector:
matchLabels:
zookeeper: zookeeper-sampleoperator调用prometheus-operator client完成prometheusrule资源的创建,实现将告警策略自动注册到prometheus。
告警策略中的 dingtalkRobot标签,主要用来重定向告警信息到指定钉钉群中,这里可以添加多个钉钉群机器人。
-
更新Zookeeper CR中spec.cluster.nodeCount 配置。
-
触发operator主流程,判断期望副本数大于实际副本数继续流程,否则退出主流程。
-
更新zk集群records,提交两种record:
-
Zookeeper upscale from 3 to 4.
-
Zookeeper Statefulset %s already update.
-
-
更新zk集群StatefulSet资源,StatefulSet控制器将会新建节点,zk将新建节点加入集群中,数据将会自动做同步。
-
Reconfig模块将从集群中添加或者剔除节点
-
更新Zookeeper CR中spec.node.resources 配置。
-
如果zk节点数与期望节点数不一致,退出主流程,直到节点数一致,所有pod全部ready。
-
通过节点数量检查之后,更新StatefulSet资源,由于我们这边StatefulSet设置的rollingupdate 策略为OnDelete,即更新StatefulSet配置之后,StatefulSet将不会主动重启节点以完成升级,需要我们自己手动去重启节点。
-
获取当前集群中节点角色,将leader节点放到最后重启,尽量减少集群不可用时间。
-
operator比对StatefulSet和pod的resourceVersion值,如果不一致将节点加入到需要重启节点列表中。
-
operator执行对节点如下检查项:
-
当前重启中对节点是否超过MaxUnavailable值,目前MaxUnavailable值默认为1.
-
跳过节点状态为Terminating的节点。
-
-
从重启节点中取一个节点,调用k8s接口,执行重启操作。
-
第一个节点重启完成之后,将requeue主流程,继续其他节点重启。
-
所有节点全部重启完成,滚动升级成功。
-
operator会为每一个创建的zk集群启动一个observer,每个observer将会启动两个goroutine:
-
GetClusterStatus,获取zk-agent /status接口数据。
-
GetClusterUp,获取/runok接口数据。
-
-
operator将每10秒获取集群最新状态,包括集群状态、node节点数、leader节点等。
-
operator获取到最新集群状态之后,将更新cr的status中,达到实时更新cr 中zk集群状态的功能,效果如下图。
status:
availableNodes: 3
leaderNode: zookeeper-sample-1.zookeeper-sample.default.svc.cluster.local- 如果zk集群被销毁,operator将调用finalizers方法停止observer协程。
-
operator 控制器在初始化的时候,将watch 一个自定义的event channel,等待event通过channel传递过来,触发主控流程执行。
-
observer初始化的时候,创建一个listeners函数数组,用于observer状态刷新时候调用,每新建一个zk集群将加入一个listener。
-
observer执行一次,listeners数组中的函数将会执行一次,获取最新各个zk集群的health状态。
-
listeners数组的函数将判断,集群新状态与老状态是否一致,一致则返回nil,否则进一步处理。
-
如果状态不一致将传值到event channel,由watch消费以触发operator主控流程执行。
可视化操作,主要实现一下功能:
- zk集群的查询、创建、伸缩、资源调整
- 支持多k8s环境
- 支持集群监控展示
对于多k8s环境的支持,主要通过在每个环境部署agent组件,组件通过rbac进行授权,确保agent组件只能操作指定资源。将agent注册到管理平台,管理平台按照环境请求不同环境接口即可。
| 模式 | 接口 | 说明 | 备注 |
|---|---|---|---|
| GET | /zookeeper/list | 查询所有zookeeper集群信息 | |
| POST | /zookeeper/info | 查询单个zookeeper集群信息 | |
| POST | /zookeeper/create | 创建单个zookeeper集群 | |
| POST | /zookeeper/update | 更新单个zookeeper集群 | |
| POST | /zookeeper/delete | 销毁单个zookeeper集群 |
- ValidatingWebhook,主要实现验证检测,即检查通过 k8s API client 提交到CR参数是否合法,如果不符合要求直接拒绝资源创建。检查项如下:
- 检查节点资源,request CPU/mem 是否小于 limit CPU/mem
- MutatingWebhook,主要实现注入默认参数,即检查到提交参数缺少一些关键性参数,将由webhook补齐并注入到创建资源中。补全项如下:
- 节点资源限制,比如request cpu/mem和limit cpu/mem。
- exporter配置,默认开启exporter,
Exporter: true,
ExporterImage: "ghostbaby/zookeeper_exporter",
ExporterVersion: "1.1.0",
DisableExporterProbes: false,StatefulSets 提供了多种升级策略:OnDelete,RollingUpdate,RollingUpdate with partition。
使用OnDelete,除非Pod的数量高于预期的副本数,否则StatefulSet控制器不会从StatefulSet中删除Pod。
Operator决定何时要删除pod。一旦删除,便会由StatefulSet控制器自动重新创建一个pod,该pod具有相同的名称,但是最新的规范。
我们的操作员永远不会创建Pod,但是当我们决定准备删除Pod时,它将负责Pod的删除。
当对StatefulSet进行修改时(例如,更改pod资源限制),我们最终得到一个新的revision(基于模板规范的哈希值)。
查看StatefulSet状态,我们可以获得当前的修订版(currentRevision: zookeeper-sample-7b889dd5b4),使用该修订版的容器的数量以及仍在使用旧修订版的容器的数量(updateRevision: zookeeper-sample-74597f9b9d)。
通过列出该StatefulSet中的Pod,我们可以检查每个Pod(metadata.labels["controller-revision-hash"]: "zookeeper-sample-74597f9b9d")的当前版本。
使用此策略,我们定义了一个partition索引:这允许使用StatefulSet控制器替换序数高于此索引的Pod。
例如,如果我们有一个带有5个副本的StatefulSet:
- zookeeper-sample-0
- zookeeper-sample-1
- zookeeper-sample-2
- zookeeper-sample-3
- zookeeper-sample-4
如果分区索引为3,则允许StatefulSet控制器自动删除然后重新创建pod zookeeper-sample-3和zookeeper-sample-4。
在此模式下,操作员永远不会删除pod。它所做的就是:
- 当应添加新容器或应除去容器时,更新StatefulSets副本
- 当应更换某些Pod时更新分区索引
要对上面的StatefulSet进行滚动升级,我们将从索引开始5,确保4可以安全地替换pod ,然后将索引更新为4。这将触发更换POD。
OnDelete除了不显式删除pod而是管理索引外,其他逻辑与适用相同。
zk agent作为sidecar伴随主容器一并启动,提供如下接口:
- status,返回宿主zk节点当前运行状态,参考zk srvr命令。
- runok,返回宿主zk节点是否正常运行且无错误,参考zk ruok命令。
- health,返回agent运行状态,用于agent的心跳检测。
- get,返回zk集群节点列表,查询/zookeeper/config文件。
- add,增加节点到zk集群中,主要依赖zk reconfigure特性,集群扩容时使用。
- del,从现有zk集群中删除某个节点,如果删除节点是主节点,会先做主节点切换,之后才会移除节点,集群缩容时使用。
| 模式 | 接口 | 说明 | 备注 |
|---|---|---|---|
| GET | /status | getZkStatus | |
| GET | /runok | getZkRunok | |
| GET | /health | Health | |
| GET | /get | getMember | |
| POST | /add | addMember | |
| POST | /del | delMember |
/status, 获取当前zk节点运行状态,字段含义对照mntr查看信息,包括如下字段:
{
"Sent": 1617,
"Received": 1618,
"NodeCount": 5,
"MinLatency": 0,
"AvgLatency": 2,
"MaxLatency": 5,
"Connections": 1,
"Outstanding": 0,
"Epoch": 14,
"Counter": 82,
"BuildTime": "2019-10-08T20:18:00Z",
"Mode": 2, //0表示Unknown,1代表Leader,2代表follower
"Version": "3.5.6-c11b7e26bc554b8523dc929761dd28808913f091",
"Error": null
}/runok,获取当前节点是否正常启动。
/health,获取zk-agent是否正常启动。
/get,获取当前Reconfig动态配置节点信息。
{
"record": "server.1=zookeeper-sample-0.zookeeper-sample.default.svc.cluster.local:2888:3888:participant;0.0.0.0:2181\nserver.2=zookeeper-sample-1.zookeeper-sample.default.svc.cluster.local:2888:3888:participant;0.0.0.0:2181\nserver.3=zookeeper-sample-2.zookeeper-sample.default.svc.cluster.local:2888:3888:participant;0.0.0.0:2181\nversion=c00000002"
}/add,获取客户端传入需要新增的节点信息,并更新到动态节点配置中。
/del,获取客户端传入需要删除到节点信息,并更新到动态节点配置中。传入值参考add接口格式。
OAM 是一个专注于描述应用的标准规范。有了这个规范,应用描述就可以彻底与基础设施部署和管理应用的细节分开。这种关注点分离(Seperation of Conerns)的设计好处是非常明显的。
组件(Components),概念让平台架构师等能够将应用分解成成一个个可被复用的模块,这种模块化封装应用组成部分的思想,代表了一种构建安全、高可扩展性应用的最佳实践:通过一个完全分布式的架构模型,实现了应用组件描述和实现的解耦。
按照应用组件的定义,对应到目前zk operator的快速部署模块上,部署模块主要生成和创建原生资源,完成容器化zk集群搭建,并持续维持声明式定义的集群终态。部署模块可以单独定义CRD, 比如workload.zookeeper.example.com。
运维特征(Traits),它们描述了应用在具体部署环境中的运维特征,比如应用的水平扩展的策略和 Ingress 规则,这些特征对于应用的运维来说非常重要,但它们在不同的部署环境里却往往有着截然不同的实现方式。
Traits则对应zk operator模块中的 伸缩、滚动升级两个模块,这两个模块可以抽出来定义为单独CRD,比如scale.zookeeper.example.com和rolling.zookeeper.example.com。
目前zk operator的实现能力也仅仅实现 部署、伸缩、滚动升级、监控等能力,还有很多模块可以做,比如:备份、重置、迁移、调度策略、暂停等等。