This is a Federated Learning implementation using the algorithm Federated Average. Video explanation can be found in this video (video is in portuguese).
Implemeted by: Beatriz Maia, Iago Cerqueira & Sophie Dilhon
The application was made using Python 3.10 and there are a few libraries that you may need to install. It is recommended to use a virtual environment, for that you may run the following commands:
python -m venv {environment}where {environment} can be any name of your choice. After creating it, it has to be activated. On Linux and Mac, use the following command:
source /{environment}/bin/activateand on Windows:
.\{environment}\Scripts\activateFinally, install the dependencies with
pip install -r requirements.txtTo execute the system, first run one of the following scripts. They are responsible to create the files used by the clients and server for the communication via grpc.
# Mac or Linux
./config.sh
# Windows
.\config.batTo run the server and clients, execute the following commands in different terminals.
python server.py --min_clients_per_round {n} --max_clients_total {m} --max_rounds {r} --accuracy_threshold {a} --timeout {t} --save_model --save_test
python client.py --ipv4 {i} --batch_size {b} --save_train --save_testServer flags meaning: --min_clients_per_round: Minimum number of clients per round. --max_clients_total: Maximum number of clients per round. --max_rounds: Maximum number of rounds. --accuracy_threshold: Minimum accuracy threshold. --timeout: Timeout in seconds for the server between training sessions. --save_model: Save the model after training. This means that the server will use this model for next training sessions. --save_test: Saves the test results in a csv file.
Client flags meaning: --ipv4: IPv4 address of the client. --save_train: Save the training results to csv file. --save_test: Save the testing results to csv file. --batch_size: Batch size for training.
Several clients can be created. The flags are not obligatory, the server will use default values if no argument is passed.
To stablish the communication between server and clients and vice versa, the grpc lib was used, and two proto files were created. The first, server.proto, is responsible for implementing the server's avaiable methods, and the other one, client.proto, is responsible for implementing the clients's avaiable methods. For this implementation, the side that is resposible for calculating the centralized federated average is the one called the server, and the side responsible for training models "locally" are the clients.
The server only has one method, which is responsible for receiving and saving the client's data, and checking if the training can start.
add_trainer(trainer_request) returns (success);As for the client, three methods were created.
- The first is responsible for training the model with the local data, and it returns to the server the model's weights.
train_model(models_weights_input) returns (models_weights_output); - The second one, receives the aggregated weights and tests the model with the local data.
test_model(models_weights) returns (metrics_results); - The last one ends the client's server
finish_training(finish_message) returns (finish_message);
The server runs on localhost:8080 and it is responsible for starting and finishing training. The code that represents it can be found at server.py. The genneral logic behind it can be described by the following steps:
- Server is initialized and connected to localhost:8080. It waits for clients to connect.
- When
max_clients_totalconnected to the server, it will start the training, sending to each of them the model weights, current round and number of clients training, as well as the training session id. To do that, the server must connect to the client's servers using their ipv4 and port (adress). - After training, each client sends back to the server their models weights.
- The server aggregates the weights calculating the federated average, where models that trained with more samples are given more importance. This can be summarized by:
sum(weights * local_sample_size) / sum(local_sample_size)
- The new weights are sent to every client (even non trainers), who then test the model and return the accuracy trained on their local data.
- Finally, the accuracies's mean is compared to the threshold, if it's smaller and current round <
max_roundsthen a new round starts. Else, training ends, clients close their server and the server goes back to step 2.
In order for the server to be able to both receive request ad well as idely wait for training and start training, the usage of thread was necessary. When the TrainerAgregator class is initialized in the server, the following code is executed:
threading.Thread(target=self.__train).start()This makes it so that a second thread is running, executing the __train method. This method is the one responible for listening in and triggering a training session. In order to have a time difference between each training session, we added a timeout after a session is completed. This means that if a session was to be finilized and new clients were available, training would only begin after the timeout was finished.
An important decision made during the implementation was permiting new clients to join when a session has started. This means that while that client will not be participating in the current training round, it can be chosen for the next rounds.
The clients runs on a random generate port on localhost, however that can be changed if the ipv4 argument is configured elsewise. The code that represents each client can be found at client.py. They end up having a type of behavior that is both of a client and a server. As a client, they add trainers to the server. As a server, they train the models and return the weights.
To simulate data on the client side, we use tensorflow MNIST and reduce the train and test datasets. During the train portion of the code, this can be observed by
percentage = int(1 / (request.number_of_trainers + 10) * 100)
min_lim = min(5, percentage)
random_number = randint(min_lim, percentage) / 100
sample_size_train = int(random_number * len(self.x_train))This section of code attempts to get a portion of the train data depending on how many trainers are currently in that round. In order for the clients to have an even smaller dataset, making it easier to see the models improvements between rounds in the analysis, the denominator is increased by 10. In order to also have a variety of weight, where each client mught contribute differently to the federated average calculation, we added an extra randomizing step. This step can be translated into: choose a sample size that is between 5% and the percentage calculate beforehand. We added a min_lim just in case the percentage calculated before is smaller than 5%.
For test, we consider the same size of data between all trainers.
sample_size_test = int((1/request.number_of_trainers)*len(self.x_test))This analysis is done considering that 10 max trainers were used. For each round, the minimum amoun of trainers were 5, but more could be used. A total of 10 rounds were made.
In the image below, we can follow the training of the 10 different clients. The models start with a few data examples, which results in an accuracy of around 80%. Not all clients trained in the first round (or all rounds), only clients with an 'o' marker in round 0.

After the federated average is calculated and sent to the new clients in round 1, the accuracy shots up. This shows that the usage of the algorithm helped tremendously, with an increase of 10%. This indicates that even though the clients between themselves had limited data, when calculting the average between them, it was possible to create a more accurate model.
As the rounds increases, the accuracy as well, but in a slower ramp.
Analyzing the average test accuracy by the server size, we can also see this increase to the accuracy. While the training models start in rather lower percentage, the test considers the federate average calculated model, and it shows what observed in round 1 of training. Round 0 test results are already over 90%. As the rounds increases, so does the accuracy.

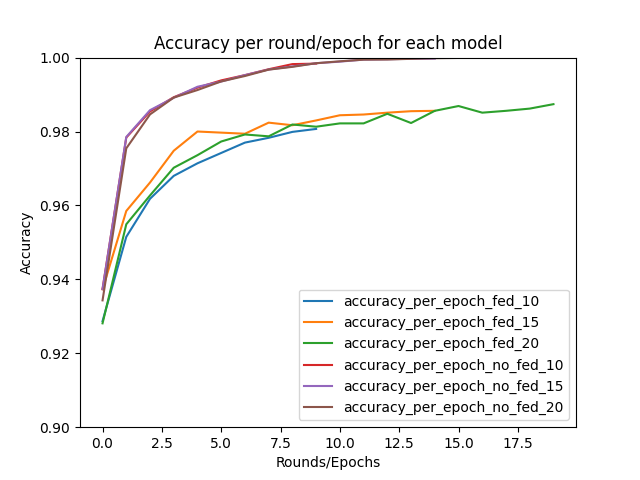
Running for different of rounds, it's to observe how the accuracy increases, however it's not as big of an increase. The MNIST data is very simple, therefore this is expected.

These results can be compared to Lab 2 results. While the traditional way of training, with all of the MNIST data, resulted into a near 100% accuracy, the federated average result was also extremely high. Our implementation had a similar result to the flwr implementation.