1.在DataStream API和Table API中一致使用pipeline名称
- 批处理模式下 DataStream API 程序的默认作业名称已从“Flink Streaming Job”更改为“Flink Batch Job”。 可以使用配置选项
pipeline.name设置自定义名称。
2.为fromChangelogStream传播唯一的键
- 与1.13.2相比,
StreamTableEnvironment.fromChangelogStream可能会产生一个不同的流,因为之前没有正确地考虑主键。
3.支持新的Table#flatMap的类型推断
- Table.flatMap()支持新的类型系统
4.移除的API
- 移除
BatchTableEnvironment、BatchTableSource、BatchTableSink可以使用DynamicTableSource和DynamicTableSink替代。 - 移除
TableEnvironment.connect()可以使用TableEnvironment.createTemporaryTable(String, TableDescriptor) - 移除
connector.type旧的connector改为connector,format.type旧的foramt。 - 迁移
ModuleFactory
1. 允许在POJO字段声明上使用@TypeInfo注释
@TypeInfo注释现在也可以用于POJO字段,例如,它可以帮助定义第三方类的自定义序列化器,否则这些类本身无法被注释。
2. 明确SourceFunction#cancel()中关于中断的内容
3. 公开一致的GlobalDataExchangeMode
- 批执行的默认DataStream API shuffle模式已经更改为阻塞流图的所有边的交换。一个新的选项执行。批处理打乱模式允许您在必要时将其更改为管道行为。
1. 公开标准化operator指标
- connector使用定义的Source和Sink接口将会自动公开某些标准化的度量。
2. KafkaSink作为新的标准Sink API
- KafkaSink取代了FlinkKafkaProducer,并提供了高效的精确一次和至少一次的写入与新的统一接收器接口,支持批处理和流模式的DataStream API。
要升级,请停止保存点。为了在精确一次处理模式下运行,KafkaSink需要一个用户配置的唯一的事务前缀,这样不同应用程序的事务就不会相互干扰。
3. FlinkKafkaConsumer过期
- FlinkKafkaConsumer将被KafkaSource替代。
4. connector-base将暴露依赖给flink-core
- 连接器不再传递地持有对flink-core的引用。这意味着带有连接器的胖JAR在此修复中不包括flink-core。
1.如果心跳目标不再可达,则心跳超时
- Flink现在支持通过连续失败的心跳rpc的数量检测死的任务管理器。在TaskManager被标记为不可达之前,阈值可以通过
heartbeat.rpc-failure-threshold配置。这可以显著加快对失效任务管理器的检测。
2. 为可插拔shuffle服务框架改进shuffle master生命周期管理
- 我们改进了ShuffleMaster界面,添加了一些生命周期方法,包括open、close、registerJob和unregisterJob。此外,ShuffleMaster现在成为一个集群级服务,可以被多个作业共享。对于可插拔shuffle服务框架来说,这是一个突破性的变化,定制的shuffle插件需要相应地适应新的接口。
3. taskmanager.slot.timeout的回退值
- 如果没有配置任何值,配置选项
taskmanager.slot.timeout现在会返回到akka.ask.timeout。之前,taskmanager.slot.timeout的默认值是10秒。
4. 优化大规模作业的调度程序性能
- 调度器的性能得到了改进,从而减少了执行图创建、任务部署和任务故障转移的时间。这一改进对于目前可能在上述流程上花费几分钟时间的大规模作业非常重要。这个改进还有助于避免作业管理器主线程阻塞太长时间并导致心跳超时的情况。
1. alignmentTimeout配置改变含义
alignmentTimeout配置的语义已经改变了含义,现在它被测量为从检查点(在检查点协调器上)开始到任务接收到检查点屏障的时间`。
2. 关闭非对齐checkpoint BROADCAST的exchanges
- 广播分区不能与未对齐的检查点一起工作。不能保证记录在
所有通道中以相同的速度被使用。这可能导致一些任务应用与某个广播事件对应的状态更改,而另一些任务则不应用。在恢复时,可能会导致不一致的状态。
3. 移除CompletedCheckpointRecover#recover()
- 在故障转移后恢复任务状态之前,Flink不再从外部存储重新加载检查点元数据(JobManager故障转移/更改领导除外)。这将导致更少的外部I/O和更快的故障转移。
- 任务具有明显不同的并行性。
- 整个管道所需的资源太多,单个槽/任务管理器无法容纳。
- 不同阶段任务所需的资源有显著差异的批处理任务
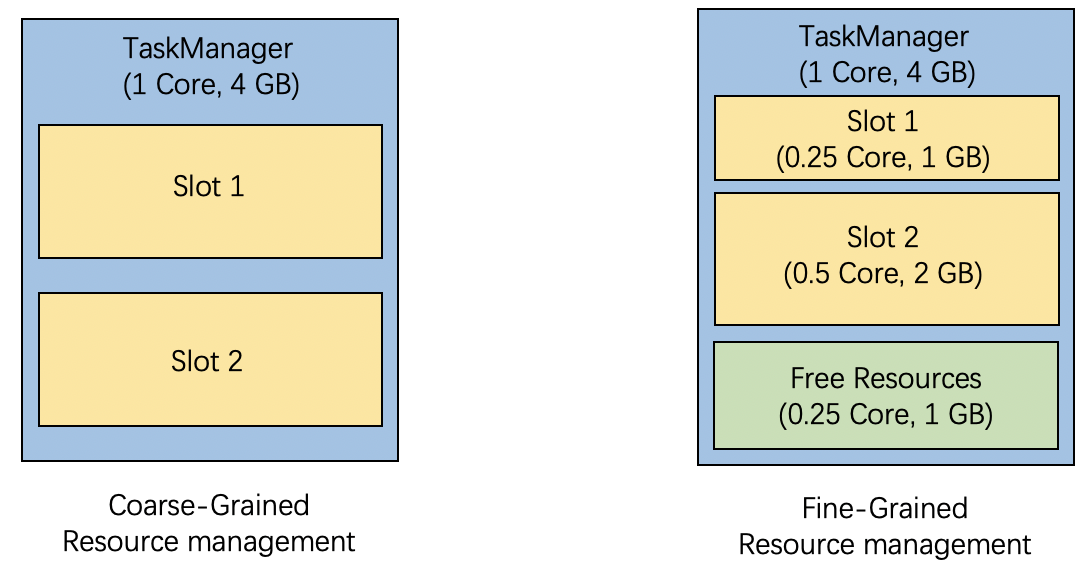
- 左边为粗粒度资源管理,是没有明确的让用户指定slot的资源配额。对于没有指定资源配置文件的资源需求,Flink 会自动决定一个资源配置文件。 目前,它的资源配置文件是根据TaskManager的总资源和taskmanager.numberOfTaskSlots计算出来的,就像粗粒度的资源管理一样。 如上图,TaskManager 的总资源为 1 Core 和 4 GB 内存,任务槽数设置为 2,Slot 2 是根据需求创建的,具有 0.5 Core 和 2 GB 内存,没有指定资源配置文件。
- 细粒度的资源管理,槽请求包含用户可以指定的特定资源配置文件。 Flink 将尊重那些用户指定的资源需求,并动态地从 TaskManager 的可用资源中切出一个完全匹配的槽。 如上图,有0.25 Core 1GB内存的插槽需求,Flink为其分配了Slot 1。
- 配置开启细粒度资源管理,指定资源配置。
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
# 设置slot共享组的资源配置
SlotSharingGroup ssgA = SlotSharingGroup.newBuilder("a")
.setCpuCores(1.0)
.setTaskHeapMemoryMB(100)
.build();
SlotSharingGroup ssgB = SlotSharingGroup.newBuilder("b")
.setCpuCores(0.5)
.setTaskHeapMemoryMB(100)
.build();
someStream.filter(...).slotSharingGroup("a") // Set the slot sharing group with name “a”
.map(...).slotSharingGroup(ssgB); // Directly set the slot sharing group with name and resource.
env.registerSlotSharingGroup(ssgA); // Then register the resource of group “a”- 不支持弹性扩缩容,弹性伸缩目前只支持slot请求,不支持指定资源。
- 不支持任务管理器冗余。slotmanager.redundant-taskmanager-num用于启动冗余taskmanager,加快任务恢复速度。此配置选项目前在细粒度资源管理中不会生效。
- 不支持均匀分布的插槽策略。这个策略试图在所有可用的taskmanager上均匀地分布插槽。在细粒度资源管理和集群的第一版中不支持该策略。 cluster.evenly-spread-out-slots 将不会生效
- 与Flink的Web UI集成有限。细粒度资源管理中的槽可以具有不同的资源规格。web UI目前只显示槽位号,没有详细信息。
- 与批处理作业的集成有限。目前,细粒度资源管理要求在所有边缘类型为BLOCKING的情况下执行批处理工作负载。为此,您需要配置
fine-grained.shuffle-mode.all-blocking为true。注意,这可能会影响性能。 - 不推荐混合资源需求。不建议只指定任务的某些部分的资源要求,而不指定其他部分的要求。目前,这个未指定的需求可以用任何资源的槽来满足。在不同的作业执行或故障转移过程中,它获取的实际资源可能不一致。
- 插槽分配结果可能不是最优的。由于插槽需求包含多个维度的资源,插槽分配实际上是一个多维的打包问题,是NP-hard。默认的资源分配策略可能无法实现最优的槽位分配,在某些场景下可能导致资源分片或资源分配失败。
- 设置槽位共享组可能会影响性能。
- 插槽共享组不限制operators的调度。
- 在 Reactive 模式下,Job 会使用集群中所有的资源。当增加 TaskManager 时,Job 会自动扩容。当删除时,就会自动缩容。Flink 会管理 Job 的并行度,始终会尽可能地使用最大值。
- 当发生扩缩容时,Job 会被重启,并且会从最新的 Checkpoint 中恢复。这就意味着不需要花费额外的开销去创建 Savepoint。当然,所需要重新处理的数据量取决于 Checkpoint 的间隔时长,而恢复的时间取决于状态的大小。
- 借助 Reactive 模式,Flink 用户可以通过一些外部的监控服务产生的指标,例如:消费延迟、CPU 利用率汇总、吞吐量、延迟等,实现一个强大的自动扩缩容机制。当上述的这些指标超出或者低于一定的阈值时,增加或者减少 TaskManager 的数量。在 Kubernetes 中,可以通过改变 Deployment 的副本数(Replica Factor) 实现。而在 AWS 中,可以通过改变 Auto Scaling 组 来实现。这类外部服务只需要负责资源的分配以及回收,而 Flink 则负责在这些资源上运行 Job。
# 以下步骤假设你当前目录处于 Flink 发行版的根目录。
# 将 Job 拷贝到 lib/ 目录下
cp ./examples/streaming/TopSpeedWindowing.jar lib/
# 使用 Reactive 模式提交 Job
./bin/standalone-job.sh start -Dscheduler-mode=reactive -Dexecution.checkpointing.interval="10s" -j org.apache.flink.streaming.examples.windowing.TopSpeedWindowing
# 启动第一个 TaskManager
./bin/taskmanager.sh start
# 扩容一个TM
./bin/taskmanager.sh start
# 缩容一个TM
./bin/taskmanager.sh stop- 仅支持 Standalone 部署模式。其他主动的部署模式实现(例如:原生的 Kubernetes 以及 YARN)都明确不支持。Session 模式也同样不支持。仅支持单 Job 的部署。
- Adaptive 调度器可以基于现有的 Slot 调整 Job 的并行度。它会在 Slot 数目不足时,自动减少并行度。这种情况包括在提交时资源不够,或者在 Job 运行时 TaskManager 不可用。当有新的 Slot 加入时,Job 将会自动扩容至配置的并行度。 在 Reactive 模式下(详见上文),并行度配置会被忽略,即无限大,使得 Job 尽可能地使用资源。 你也可以不使用 Reactive 模式而仅使用 Adaptive 调度器,但这种情况会有如下的局限性:
- 如果你在 Session 集群上使用 Adaptive 调度器,在这个集群中运行的多个 Job,他们间 Slot 的分布是无法保证的。
- 相比默认的调度器,Adaptive 调度器其中一个优势在于,它能够优雅地处理 TaskManager 丢失所造成的问题,因为对它来说就仅仅是缩容。
jobmanager.scheduler: adaptive:将默认的调度器换成 Adaptive。cluster.declarative-resource-management.enabled:声明式资源管理必须开启(默认开启)。
- 只支持流式 Job:Adaptive 调度器的第一个版本仅支持流式 Job。当提交的是一个批处理 Job 时,我们会自动换回默认调度器。
- 不支持本地恢复:本地恢复是将 Task 调度到状态尽可能的被重用的机器上的功能。不支持这个功能意味着 Adaptive 调度器需要每次从 Checkpoint 的存储中下载整个 State。
- 不支持部分故障恢复: 部分故障恢复意味着调度器可以只重启失败 Job 其中某一部分(在 Flink 的内部结构中被称之为 Region)而不是重启整个 Job。这个限制只会影响那些独立并行(Embarrassingly Parallel)Job的恢复时长,默认的调度器可以重启失败的部分,然而 Adaptive 将需要重启整个 Job。
- 与 Flink Web UI 的集成受限: Adaptive 调度器会在 Job 的生命周期中改变它的并行度。Web UI 上只显示 Job 当前的并行度。
- Job 的指标受限: 除了
numRestarts外,Job作用域下所有的 可用性 和 Checkpoint 指标都不准确。 - 空闲 Slot: 如果 Slot 共享组的最大并行度不相等,提供给 Adaptive 调度器所使用的 Slot 可能不会被使用。
- 扩缩容事件会触发 Job 和 Task 重启,Task 重试的次数也会增加。