导读:伴随着lakehouse(datahouse+datalake)概念的兴起,数据湖框架近些年一直备受关注,Hudi作为少有的几个开源数据湖框架之一,不管是在社区还是业界也是备受追捧,特别的近期Hudi On Flink 0.10.0版本横空出世,基于Flink On Hudi的湖仓一体方案也在慢慢变得成熟而稳定,本文将会带来Hudi配合Flink与Alluxio搭建的近实时数据湖能力建设。
- 传统数据湖方案通过Hive来完成T+1级别的数据仓库,海量数据存储在HDFS上,通过Hive的元数据管理及SQL化查询来完成数据分析。
- 不支持事务,如果俩个有依赖的任务同时运行可能会导致下游的任务数据不准确,因此往往需要人为控制任务的调度周期,这也导致整体任务的
SLA很难保证。 - 数据更新效率低,往往增量更新很难做到,一般数据是通过
覆盖写的方式或者历史数据拉链表等形式,这都导致过多的数据存储或者资源占用。 - 无法及时应对业务表的变化,一般上游业务系统对数据的schema发生变更后会导致数据会发正常的写入Hive中。
- 小批量数据处理成本偏高,增量ETL需要借助细粒度分区从而也会导致小文件问题。
- 快速upsert能力
- 配合
可插拔的索引机制可以实现upsert能力 - 扩展的Merge操作符,实现新增、更新、删除混合数据同时入湖
- 支持写入同步小文件compaction能力,写入数据自动按照预设文件进行合并
- 配合
- 支持ACID
- 支持
Snapshot数据隔离,保证数据读取完整性,实现读写并发能力 - 数据commit,数据入湖秒级可见
- 支持
- 多种视图读取接口
- 支持实时快照数据读取方式
- 支持历史快照数据读取方式
- 支持当前增量和历史增量数据读取方式
- 支持快速数据探索分析
- 多版本
- 数据按照提交版本存储,保留历史操作记录,方便数据回溯
- 数据回退操作简单,速度快
- 支持Merge On Read&Copy On Write表类型
- Merge On Read:读取时进行base file和delta file的合并,适用于数据实时入湖场景,配合合理的compact配置可以达到秒级(写入+读取)能力
- Copy On Write:写入时进行合并更新,会根据上一个base file和当前写入数据进行merge,最终的数据格式就等同于
parquet文件格式的性能,用于替代传统数据湖分析场景的表类型。
Snapshot Queries:查询查看给定提交或压缩操作时表的最新快照。对于MergeOnRead,它通过动态合并最新文件片的base文件和delte文件来公开接近实时的数据(几分钟)。对于CopyOnWrite,它提供了现有parquet表的临时替代品,同时提供了插入/删除和其他写功能。Incremental Queries:由于给定的commit/compaction,查询只能看到写入表的新数据。这有效地提供了更改流来支持增量数据管道。Read Optimized Queries:查询查看给定commit/compaction操作时的表的最新快照。仅公开最新文件片中的base/columnar文件,并保证与非hudi columnar表相比具有相同的columnar查询性能,只读取最近compaction的base file。
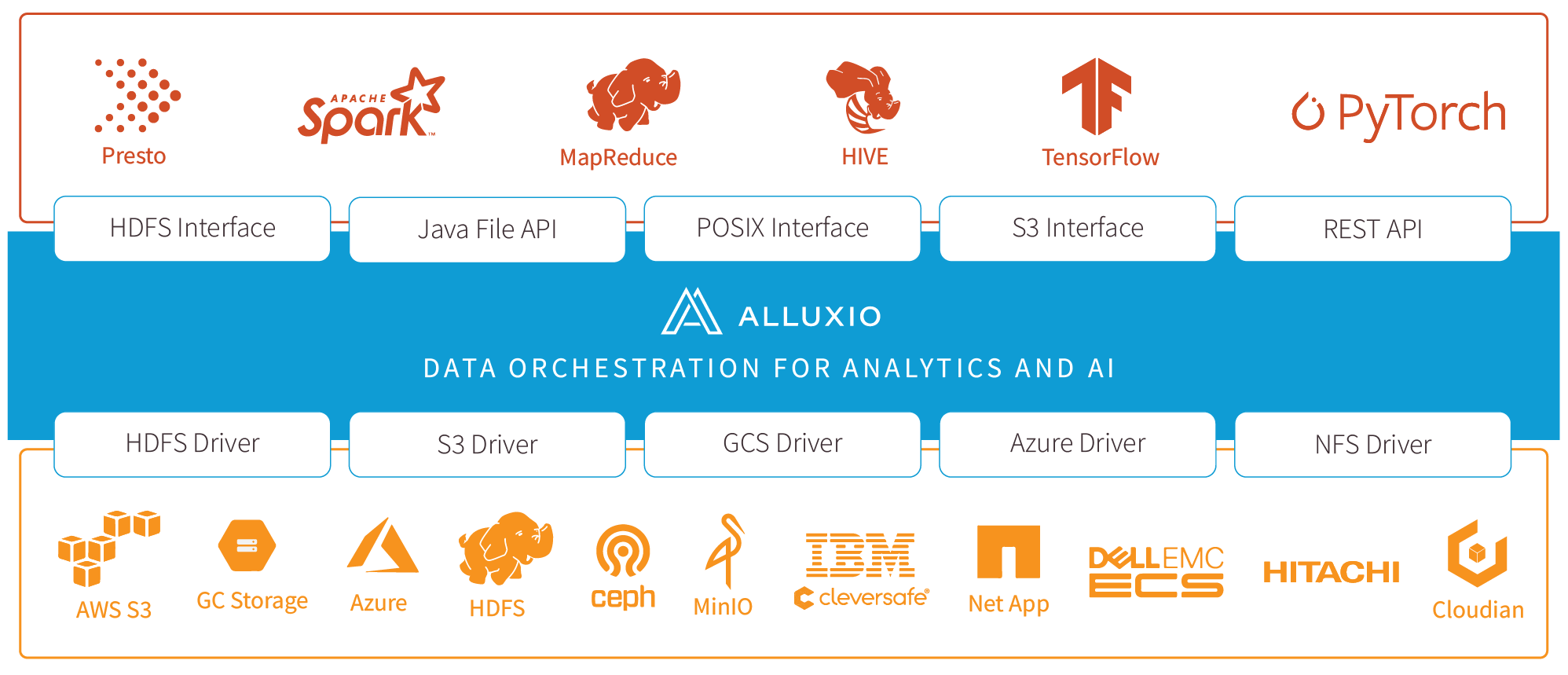
- Alluxio将存储分为俩个类别的方式来帮助统一跨各种平台用户数据的同时还有助于为用户提升总体I / O吞吐量。
- UFS(底层文件系统,底层存储):表示不受Alluxio管理的空间,UFS存储可能来自外部文件系统,如HDFS或S3, 通常,UFS存储旨在相当长一段时间持久存储大量数据。
- Alluxio存储
- alluxio作为一个分布式缓存来管理Alluxio workers本地存储,包括内存。这个在用户应用程序与各种底层存储之间的快速数据层带来的是显著提高的I / O性能。
- Alluxio存储主要用于存储热数据,暂态数据,而不是长期持久数据存储。
- 每个Alluxio节点要管理的存储量和类型由用户配置决定。
- 即使数据当前不在Alluxio存储中,通过Alluxio连接的UFS中的文件仍然 对Alluxio客户可见。当客户端尝试读取仅可从UFS获得的文件时数据将被复制到Alluxio存储中(这里体现在alluxio文件目录下的进度条)
- Alluxio存储通过将数据
存储在计算节点内存中来提高性能。Alluxio存储中的数据可以被复制来形成"热"数据,更易于I/O并行操作和使用。 - Alluxio中的
数据副本独立于UFS中可能已存在的副本。 Alluxio存储中的数据副本数是由集群活动动态决定的。 由于Alluxio依赖底层文件存储来存储大部分数据, Alluxio不需要保存未使用的数据副本。 - Alluxio还支持让系统存储软件可感知的分层存储,使类似L1/L2 CPU缓存一样的数据存储优化成为可能。
- Apache Flink 是一个分布式大数据处理引擎,可对有限数据流和无限数据流进行有状态或无状态的计算,能够部署在各种集群环境,对各种规模大小的数据进行快速计算。
- 有状态的计算,状态容错性依赖于checkpoint机制做状态持久化存储。
- 多层API(Table/SQL API、DataStream/DataSet API、ProcessFunction API)
- exactly-once语义,状态一致性保证
- 低延迟,每秒处理数百万个事件,毫秒级别延迟。
- 随着流批一体的概念逐渐成熟,Flink的流批一体建设也在1.13至1.14版本相对成熟,虽然Spark On Hudi会相对稳定,但是Flink On Hudi在流批一体的大环境下将会是未来湖仓一体的重要技术选型,因此本文讲解Flink在Hudi中的实践与应用。
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<groupId>dev.learn.flink</groupId>
<version>1.0-SNAPSHOT</version>
<modelVersion>4.0.0</modelVersion>
<artifactId>flink-hudi</artifactId>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<flink.version>1.13.1</flink.version>
<java.version>1.8</java.version>
<scala.binary.version>2.11</scala.binary.version>
<scala.version>2.11.12</scala.version>
<maven.compiler.source>${java.version}</maven.compiler.source>
<maven.compiler.target>${java.version}</maven.compiler.target>
<log4j.version>2.12.1</log4j.version>
<hudi.version>0.10.1</hudi.version>
<hadoop.version>3.0.0</hadoop.version>
<hive.version>2.3.4</hive.version>
<commons.collections.version>3.2.2</commons.collections.version>
<junit.version>4.13.1</junit.version>
<lombok.version>1.18.12</lombok.version>
<alluxio.version>2.7.2</alluxio.version>
</properties>
<repositories>
<repository>
<id>apache.snapshots</id>
<name>Apache Development Snapshot Repository</name>
<url>https://repository.apache.org/content/repositories/snapshots/</url>
<releases>
<enabled>false</enabled>
</releases>
<snapshots>
<enabled>true</enabled>
</snapshots>
</repository>
</repositories>
<dependencies>
<!-- https://mvnrepository.com/artifact/org.roaringbitmap/RoaringBitmap -->
<dependency>
<groupId>org.roaringbitmap</groupId>
<artifactId>RoaringBitmap</artifactId>
<version>0.9.23</version>
</dependency>
<!-- <dependency>-->
<!-- <groupId>org.alluxio</groupId>-->
<!-- <artifactId>alluxio-core-client</artifactId>-->
<!-- <version>${alluxio.version}</version>-->
<!-- <scope>provided</scope>-->
<!-- </dependency>-->
<dependency>
<groupId>org.alluxio</groupId>
<artifactId>alluxio-core-client-fs</artifactId>
<version>${alluxio.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.alluxio</groupId>
<artifactId>alluxio-core-common</artifactId>
<version>${alluxio.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>${lombok.version}</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>${junit.version}</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>commons-collections</groupId>
<artifactId>commons-collections</artifactId>
<version>${commons.collections.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-json</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
<version>${log4j.version}</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>${log4j.version}</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>${log4j.version}</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-sql-connector-kafka_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!--flink table api-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.hudi</groupId>
<artifactId>hudi-flink-bundle_${scala.binary.version}</artifactId>
<version>${hudi.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
<exclusions>
<exclusion>
<artifactId>commons-compress</artifactId>
<groupId>org.apache.commons</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
<exclusions>
<exclusion>
<artifactId>commons-compress</artifactId>
<groupId>org.apache.commons</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>${hive.version}</version>
<exclusions>
<exclusion>
<artifactId>pentaho-aggdesigner-algorithm</artifactId>
<groupId>org.pentaho</groupId>
</exclusion>
<exclusion>
<artifactId>antlr-runtime</artifactId>
<groupId>org.antlr</groupId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
<build>
<plugins>
<!-- Java Compiler -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>${java.version}</source>
<target>${java.version}</target>
</configuration>
</plugin>
<!-- We use the maven-shade plugin to create a fat jar that contains all necessary dependencies. -->
<!-- Change the value of <mainClass>...</mainClass> if your program entry point changes. -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.1.1</version>
<executions>
<!-- Run shade goal on package phase -->
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<artifactSet>
<excludes>
<exclude>org.apache.flink:force-shading</exclude>
<exclude>com.google.code.findbugs:jsr305</exclude>
<exclude>org.slf4j:*</exclude>
<exclude>org.apache.logging.log4j:*</exclude>
</excludes>
</artifactSet>
<filters>
<filter>
<!-- Do not copy the signatures in the META-INF folder.
Otherwise, this might cause SecurityExceptions when using the JAR. -->
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>dev.flink.hudi.driver.AlluxioOnHudiDriver</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>- Flink配置类
public class FlinkEnvConfig {
/**
* 获取流式执行环境
*
* @return
*/
public static StreamExecutionEnvironment getStreamEnv() {
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
return executionEnvironment;
}
/**
* 获取流式table执行环境
*
* @return
*/
public static StreamTableEnvironment getStreamTableEnv() {
StreamExecutionEnvironment streamEnv = getStreamEnv();
return StreamTableEnvironment.create(streamEnv,
EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build());
}
public static TableEnvironment getBatchTableEnv() {
return TableEnvironment.create(EnvironmentSettings.newInstance().useBlinkPlanner().inBatchMode().build());
}
}- Hudi核心服务
public class SQLHudiOperatorService<ENV extends TableEnvironment> implements HudiOperatorService<ENV, SQLOperator,
Consumer<TableResult>> {
private static final Logger LOGGER = LoggerFactory.getLogger(SQLHudiOperatorService.class);
@Override
public void operation(ENV streamTableEnvironment, SQLOperator sqlOperator,
Consumer<TableResult> collector) {
sqlOperator.checkParams();
List<String> ddlSQLList = sqlOperator.getDdlSQLList();
for (String ddlSQL : ddlSQLList) {
LOGGER.info("execute DDL SQL:{}", ddlSQL);
streamTableEnvironment.executeSql(ddlSQL);
}
List<String> querySQLList = sqlOperator.getQuerySQLList();
if (null != querySQLList) {
for (String querySql : querySQLList) {
LOGGER.info("execute query SQL:{}", querySql);
collector.accept(streamTableEnvironment.executeSql(querySql));
}
}
List<String> insertSQLList = sqlOperator.getInsertSQLList();
StatementSet statementSet = streamTableEnvironment.createStatementSet();
if (null != insertSQLList) {
for (String coreSQL : insertSQLList) {
LOGGER.info("execute insert SQL:{}", coreSQL);
statementSet.addInsertSql(coreSQL);
collector.accept(statementSet.execute());
}
}
}
}- Hudi Driver类
public class CommonQueryDriver {
public static void main(String[] args) {
HudiOperatorService<StreamTableEnvironment, SQLOperator,
Consumer<TableResult>> streamHudiOperatorService = new SQLHudiOperatorService<>();
StreamTableEnvironment streamTableEnv = FlinkEnvConfig.getStreamTableEnv();
String sourceTableName = "update_user";
Map<String, Object> props = Maps.newHashMap();
props.put(FactoryUtil.CONNECTOR.key(), HoodieTableFactory.FACTORY_ID);
props.put(FlinkOptions.PATH.key(), "hdfs://hadoop:8020/user/flink/" + sourceTableName);
props.put(FlinkOptions.TABLE_TYPE.key(), HoodieTableType.COPY_ON_WRITE.name());
props.put(FlinkOptions.PRECOMBINE_FIELD.key(), "dt");
props.put(FlinkOptions.RECORD_KEY_FIELD.key(), "id");
props.put(FlinkOptions.PARTITION_PATH_FIELD.key(), "dt");
props.put(FlinkOptions.TABLE_NAME.key(), sourceTableName);
props.put(FlinkOptions.READ_AS_STREAMING.key(), "true");
props.put(FlinkOptions.READ_START_COMMIT.key(), "20211215000000");
String sourceDDL = SqlBuilderFactory.getSqlBuilder(SQLEngine.FLINK, props, sourceTableName,
Lists.newArrayList(
ColumnInfo.builder()
.columnName("id")
.columnType("int").build(),
ColumnInfo.builder()
.columnName("age")
.columnType("int").build(),
ColumnInfo.builder()
.columnType("string")
.columnName("name").build(),
ColumnInfo.builder()
.columnName("dt")
.columnType("string").build())).generatorDDL();
streamHudiOperatorService.operation(streamTableEnv, SQLOperator.builder()
.querySQLList(Lists.newArrayList("select * from " + sourceTableName))
.ddlSQLList(Lists.newArrayList(sourceDDL)).build(),
new Consumer<TableResult>() {
@Override
public void accept(TableResult tableResult) {
tableResult.print();
}
});
}
}# 挂载RAMFS文件系统
alluxio-mount.sh SudoMount
# 格式化文件系统,类似与hdfs在第一次使用的时候需要格式化
alluxio format
# 启动本地文件系统,为挂载ramdisk或重新挂载
alluxio-start.sh local SudoMount
# 如果已经挂载了直接启动即可
alluxio-start.sh local
# 验证alluxio是否运行
alluxio runTests
# 关闭alluxio
alluxio-stop.sh local- master web ui

- worker web ui

- 修改hadoop的
core-site.xml配置,增加alluxio文件系统实现
<property>
<name>fs.alluxio.impl</name>
<value>alluxio.hadoop.FileSystem</value>
</property>- 修改
flink-conf.yaml配置
fs.hdfs.hadoopconf: core-site.xml配置路径
# 配置alluxio其他配置,通过env.java.opts方式添加
env.java.opts: -Dalluxio.user.file.writetype.default=CACHE_THROUGH-
添加alluxio客户端jar包的三种方式
- 将
/<PATH_TO_ALLUXIO>/client/alluxio-2.7.3-client.jar文件放在Flink的lib目录下(对于本地模式以及独立集群模式)。 - 将
/<PATH_TO_ALLUXIO>/client/alluxio-2.7.3-client.jar文件放在布置在Yarn中的Flink下的ship目录下。 - 在
HADOOP_CLASSPATH环境变量中指定该jar文件的路径(要保证该路径对集群中的所有节点都有效)。例如:
$ export HADOOP_CLASSPATH=/<PATH_TO_ALLUXIO>/client/alluxio-2.7.3-client.jar
- 将
-
FLINK_HOME的lib目录详情

- 通过Flink配合Alluxio中间层加速将数据写入Hudi中,并通过alluxio master webUi观察数据是否写入成功,这里需要了解一下flink on hudi的写入策略,一批buffer数据上超过
FlinkOptions#WRITE_BATCH_SIZE大小或者全部的buffer数据超过FlinkOptions#WRITE_TASK_MAX_SIZE,或者是Flink开始做ck,则flush。如果一批数据写入成功,则StreamWriteOperatorCoordinator会标识写入成功。代码中的ck设置为30s,因此在数据流不满足FlinkOptions#WRITE_TASK_MAX_SIZE和FlinkOptions#WRITE_BATCH_SIZE的时候,每30s进行一次flush。
/**
* @fileName: AlluxioOnHudiDriver.java
* @description: alluxio整合flink&hudi
* @author: huangshimin
* @date: 2022/2/18 10:26 下午
*/
public class AlluxioOnHudiDriver {
public static void main(String[] args) {
ParameterTool parameterTool = ParameterTool.fromArgs(args);
String hudiSinkPath = parameterTool.get("hudiSinkPath", "alluxio://hadoop:19998/user/flink" +
"/alluxio_hudi_user_t");
String sinkTableName = parameterTool.get("hudiTableName", "hudi_user");
HudiOperatorService<StreamTableEnvironment, SQLOperator,
Consumer<TableResult>> streamHudiOperatorService = new SQLHudiOperatorService<>();
StreamTableEnvironment streamTableEnv = FlinkEnvConfig.getStreamTableEnv();
String sourceTableName = "source";
// 通过flink datagen connector生成指定mock数据,写入hudi
String sourceSQLDDL = "create table " + sourceTableName + " (id int," +
"age int," +
"name string," +
"dt string)with('connector'='kafka','topic' = " +
"'hudi_user_topic'," +
" 'properties.bootstrap.servers' = 'localhost:9092',\n" +
" 'properties.group.id' = 'hudiUserGroup',\n" +
" 'scan.startup.mode' = 'earliest-offset',\n" +
" 'format' = 'json')";
Map<String, Object> props = Maps.newHashMap();
// hudi连接器配置
props.put(FactoryUtil.CONNECTOR.key(), HoodieTableFactory.FACTORY_ID);
// 设置hudi表写入path
props.put(FlinkOptions.PATH.key(), hudiSinkPath);
// 设置表类型
props.put(FlinkOptions.TABLE_TYPE.key(), HoodieTableType.COPY_ON_WRITE.name());
// precombine字段设置,如果出现相同partition path&record key根据precombine字段的大小去最大的值
props.put(FlinkOptions.PRECOMBINE_FIELD.key(), "dt");
// record key,每个partition path下的唯一标识字段
props.put(FlinkOptions.RECORD_KEY_FIELD.key(), "id");
// 分区字段
props.put(FlinkOptions.PARTITION_PATH_FIELD.key(), "dt");
// hudi表名
props.put(FlinkOptions.TABLE_NAME.key(), sinkTableName);
// 最大和最小commit归档限制
props.put(FlinkOptions.ARCHIVE_MAX_COMMITS.key(), 30);
props.put(FlinkOptions.ARCHIVE_MIN_COMMITS.key(), 20);
// bucket assign的任务书
props.put(FlinkOptions.BUCKET_ASSIGN_TASKS.key(), 4);
// 保留的commit数
props.put(FlinkOptions.CLEAN_RETAIN_COMMITS.key(), 10);
// 写入hudi的并行度
props.put(FlinkOptions.WRITE_TASKS.key(), 4);
// 写入一批的大小,128MB,
props.put(FlinkOptions.WRITE_BATCH_SIZE.key(), "128D");
// hudi操作类型
props.put(FlinkOptions.OPERATION.key(), WriteOperationType.UPSERT.value());
String sinkDDL = SqlBuilderFactory.getSqlBuilder(SQLEngine.FLINK, props, sinkTableName,
Lists.newArrayList(ColumnInfo.builder()
.columnName("id")
.columnType("int").build(),
ColumnInfo.builder()
.columnName("age")
.columnType("int").build(),
ColumnInfo.builder()
.columnType("string")
.columnName("name").build(),
ColumnInfo.builder()
.columnName("dt")
.columnType("string").build())).generatorDDL();
String insertSQLDML = HudiSqlConfig.getDML(OperatorEnums.INSERT, "*", sinkTableName, sourceTableName, "");
SQLOperator sqlOperator = SQLOperator.builder()
.ddlSQLList(Lists.newArrayList(sinkDDL, sourceSQLDDL))
.insertSQLList(Lists.newArrayList(insertSQLDML))
.build();
streamHudiOperatorService.operation(streamTableEnv, sqlOperator, new Consumer<TableResult>() {
@Override
public void accept(TableResult tableResult) {
tableResult.print();
}
});
}
}- 运行命令
# 启动yarn-session
yarn-session.sh --detached
# 提交hudi on flink任务
flink run -Dtaskmanager.numberOfTaskSlots=16 -c dev.flink.hudi.driver.AlluxioOnHudiDriver ~/Desktop/flink-hudi-1.0-SNAPSHOT.jar -hudiSinkPath alluxio://hadoop:19998/user/flink/alluxio_user -hudiTableName alluxio_user- Flink Checkpoint配置

- Flink Ui数据

- 通过kafka发送数据


- 观察alluxio Master Ui&HDFS底层数据



可以观察到通过kafka发送的数据已经成功写入到hudi的底层存储已经flink的中间数据加速层HDFS和Alluxio中- 通过Hudi On Flink提供的流式能力,根据
FlinkOptions.READ_STREAMING_CHECK_INTERVAL配置,每3s进行一次数据增量拉取。
/**
* @fileName: AlluxioHudiQueryDriver.java
* @description: 通过flink on hudi查询指定alluxio路径数据
* @author: huangshimin
* @date: 2021/12/16 8:57 下午
*/
public class AlluxioHudiQueryDriver {
public static void main(String[] args) {
ParameterTool parameterTool = ParameterTool.fromArgs(args);
String hudiPath = parameterTool.get("hudiPath", "alluxio://hadoop:19998/user/flink" +
"/alluxio_user");
String sourceTableName = parameterTool.get("hudiTableName", "alluxio_user");
HudiOperatorService<StreamTableEnvironment, SQLOperator,
Consumer<TableResult>> streamHudiOperatorService = new SQLHudiOperatorService<>();
StreamTableEnvironment streamTableEnv = FlinkEnvConfig.getStreamTableEnv();
Map<String, Object> props = Maps.newHashMap();
props.put(FactoryUtil.CONNECTOR.key(), HoodieTableFactory.FACTORY_ID);
props.put(FlinkOptions.PATH.key(), hudiPath);
props.put(FlinkOptions.TABLE_TYPE.key(), HoodieTableType.COPY_ON_WRITE.name());
props.put(FlinkOptions.PRECOMBINE_FIELD.key(), "dt");
props.put(FlinkOptions.RECORD_KEY_FIELD.key(), "id");
props.put(FlinkOptions.PARTITION_PATH_FIELD.key(), "dt");
props.put(FlinkOptions.TABLE_NAME.key(), sourceTableName);
props.put(FlinkOptions.READ_AS_STREAMING.key(), "true");
props.put(FlinkOptions.READ_STREAMING_CHECK_INTERVAL.key(), 3);
// 指定commit开始消费
props.put(FlinkOptions.READ_START_COMMIT.key(), FlinkOptions.START_COMMIT_EARLIEST);
String sourceDDL = SqlBuilderFactory.getSqlBuilder(SQLEngine.FLINK, props, sourceTableName,
Lists.newArrayList(
ColumnInfo.builder()
.columnName("id")
.columnType("int").build(),
ColumnInfo.builder()
.columnName("age")
.columnType("int").build(),
ColumnInfo.builder()
.columnType("string")
.columnName("name").build(),
ColumnInfo.builder()
.columnName("dt")
.columnType("string").build())).generatorDDL();
streamHudiOperatorService.operation(streamTableEnv, SQLOperator.builder()
.querySQLList(Lists.newArrayList("select * from " + sourceTableName))
.ddlSQLList(Lists.newArrayList(sourceDDL)).build(),
new Consumer<TableResult>() {
@Override
public void accept(TableResult tableResult) {
tableResult.print();
}
});
}
}- 运行命令
# 启动yarn-session
yarn-session.sh --detached
# 提交hudi on flink任务
flink run -c dev.flink.hudi.driver.AlluxioHudiQueryDriver ~/Desktop/flink-hudi-1.0-SNAPSHOT.jar -hudiPath alluxio://hadoop:19998/user/flink/alluxio_user -hudiTableName alluxio_user- Flink Web UI

- 读取数据


- 实时写入数据动态演示
写入数据需要30秒进行一次flush,流式读取需要3秒一次拉取,也就是最坏情况下一条数据写入后33秒后可以查看到。

- 通过案例的写入操作和读取操作可以看出来整体Flink整合Alluxio以及Hudi是相当便捷的,并且通过用户自定义的ck间隔配置或者buffer大小设置可以决定数据入湖的时间,通过流式读取的间隔配置可以决定数据拉取的频率,整体来说基于Flink建设企业级的lakehouse是一个相对成熟的方案。也是因为数据量的条件限制这里就没有对比alluxio带来的性能提升,感兴趣的朋友可以看下附录的文档参考,里面有介绍T3出行对于Alluxio的深入实践。