基于 badger
v4.0.1进行源码分析
本文主要分析 badger 的启动阶段的初始化流程, 以及关闭时如何减少数据的丢失.
golang badger kv 存储引擎实现原理系列的文章地址 (更新中)
https://github.com/rfyiamcool/notes#golang-badger
badgerDB 的启动流程略有些长, 其启动流程如下:
- 使用 flock 对 dir 和 valueDir 目录进行文件锁, 避免多进程同时打开 db 文件.
- 解析读取 manifest 配置.
- 配置 sstable 和 bloomfilter 缓存.
- 从 dir 目录中读取 memtable 数据.
- 按照 manifest 来读取各个 level 的 sstable 构建 levelController 控制器.
- 初始化 wisckey vlog 对象.
- 初始化当前的 nextTxnTs 及事务对象.
- 开启 compact 合并, flush 刷新, 写协程, valuelog gc 协程, pub 通知协程等.
func Open(opt Options) (*DB, error) {
// 检测 options 并配置默认值.
if err := checkAndSetOptions(&opt); err != nil {
return nil, err
}
var dirLockGuard, valueDirLockGuard *directoryLockGuard
if !opt.InMemory {
// 尝试创建 db 目录
if err := createDirs(opt); err != nil {
return nil, err
}
var err error
// 默认为 false, 也就是 flock 文件锁逻辑.
if !opt.BypassLockGuard {
// 尝试获取文件锁
dirLockGuard, err = acquireDirectoryLock(opt.Dir, lockFile, opt.ReadOnly)
if err != nil {
// 如果文件锁被占用, 则有异常直接退出.
return nil, err
}
defer func() {
// 退出后,会立即释放锁?
// Open 的尾部会把 lock 对象重置为 nil, 所以无异常下不会触发.
if dirLockGuard != nil {
// 如果拿到锁, defer 里延迟放锁.
_ = dirLockGuard.release()
}
}()
// ...
// 如果 valueDir 和 dir 不一致, 则对 valueDir 也进行 flock 加锁.
if absValueDir != absDir {
valueDirLockGuard, err = acquireDirectoryLock(opt.ValueDir, lockFile, opt.ReadOnly)
if err != nil {
return nil, err
}
defer func() {
// 退出后,会立即释放锁?
// Open 的尾部会把 lock 对象重置为 nil, 所以无异常下不会触发.
if valueDirLockGuard != nil {
_ = valueDirLockGuard.release()
}
}()
}
}
}
// 解析读取 manifest 配置
manifestFile, manifest, err := openOrCreateManifestFile(opt)
if err != nil {
return nil, err
}
defer func() {
if manifestFile != nil {
// 关闭 manifest 文件描述符.
_ = manifestFile.close()
}
}()
db := &DB{
imm: make([]*memTable, 0, opt.NumMemtables),
flushChan: make(chan flushTask, opt.NumMemtables),
writeCh: make(chan *request, kvWriteChCapacity),
opt: opt,
manifest: manifestFile,
dirLockGuard: dirLockGuard,
valueDirGuard: valueDirLockGuard,
orc: newOracle(opt),
pub: newPublisher(),
allocPool: z.NewAllocatorPool(8),
bannedNamespaces: &lockedKeys{keys: make(map[uint64]struct{})},
threshold: initVlogThreshold(&opt),
}
defer func() {
// 如果初始化 badger 失败.
if err != nil {
// 进行收尾, 关闭 flush, compact 协程, 关闭 cache, 关闭 write, vlog gc 和 pub 等协程.
db.cleanup()
db = nil
}
}()
// 配置 sstable 缓存
if opt.BlockCacheSize > 0 {
numInCache := opt.BlockCacheSize / int64(opt.BlockSize)
// 定义配额
config := ristretto.Config{
NumCounters: numInCache * 8,
MaxCost: opt.BlockCacheSize,
BufferItems: 64,
Metrics: true,
OnExit: table.BlockEvictHandler,
}
db.blockCache, err = ristretto.NewCache(&config)
if err != nil {
return nil, y.Wrap(err, "failed to create data cache")
}
}
// 配置 bloomfilter 布隆过滤器缓存
if opt.IndexCacheSize > 0 {
indexSz := int64(float64(opt.MemTableSize) * 0.05)
numInCache := opt.IndexCacheSize / indexSz
// 定义配额
config := ristretto.Config{
NumCounters: numInCache * 8,
MaxCost: opt.IndexCacheSize,
BufferItems: 64,
Metrics: true,
}
db.indexCache, err = ristretto.NewCache(&config)
if err != nil {
return nil, y.Wrap(err, "failed to create bf cache")
}
}
db.closers.cacheHealth = z.NewCloser(1)
// 开一个监控协程, 周期检测 metrics 指标, 超过阈值则打日志输出.
go db.monitorCache(db.closers.cacheHealth)
if db.opt.InMemory {
db.opt.SyncWrites = false
db.opt.ValueThreshold = math.MaxInt32
}
krOpt := KeyRegistryOptions{
ReadOnly: opt.ReadOnly,
Dir: opt.Dir,
EncryptionKey: opt.EncryptionKey,
EncryptionKeyRotationDuration: opt.EncryptionKeyRotationDuration,
InMemory: opt.InMemory,
}
if db.registry, err = OpenKeyRegistry(krOpt); err != nil {
return db, err
}
// 计算当前 lsm tree 的各组件的磁盘开销.
db.calculateSize()
db.closers.updateSize = z.NewCloser(1)
// 开一个协程异步去统计磁盘开销.
go db.updateSize(db.closers.updateSize)
// 扫描 db 目录以 .mem 结尾的 memtable 文件, 这里的 memtable 文件本质就是 wal 文件.
// openMemTables 会把 wal 文件读取出来, 构建 skiplist 跳表, 然后赋值到内存的 memtable 对象里, 这些 memtable 集合会归到 immutable memtable 里.
// 后面有细讲.
if err := db.openMemTables(db.opt); err != nil {
return nil, y.Wrapf(err, "while opening memtables")
}
if !db.opt.ReadOnly {
// 实例化当前的 memtable 对象.
if db.mt, err = db.newMemTable(); err != nil {
return nil, y.Wrapf(err, "cannot create memtable")
}
}
// 按照 manifest 来读取各个 level 的 sstable 构建 levelController 控制器
if db.lc, err = newLevelsController(db, &manifest); err != nil {
return db, err
}
// 初始化 vlog
db.vlog.init(db)
if !opt.ReadOnly {
// 开启合并协程, 默认 4 个.
db.closers.compactors = z.NewCloser(1)
db.lc.startCompact(db.closers.compactors)
db.closers.memtable = z.NewCloser(1)
go func() {
// 开启 flush 协程
_ = db.flushMemtable(db.closers.memtable)
}()
// 马上先把 immutable memtables 给持久化.
for _, mt := range db.imm {
db.flushChan <- flushTask{mt: mt}
}
}
// 获取当前最大的事务版本号 MaxVersion, 赋值到 nextTxnTs.
// 后面获取事务版本号都是从该字段 nextTxnTs 递增.
db.orc.nextTxnTs = db.MaxVersion()
db.opt.Infof("Set nextTxnTs to %d", db.orc.nextTxnTs)
// 打开 vlog 实例对象
if err = db.vlog.open(db); err != nil {
return db, y.Wrapf(err, "During db.vlog.open")
}
// 更新 txn 事务和读事务的水位线.
db.orc.txnMark.Done(db.orc.nextTxnTs)
db.orc.readMark.Done(db.orc.nextTxnTs)
// 递增一个版本号.
db.orc.incrementNextTs()
// 尝试初始化被禁用的 ns
if err := db.initBannedNamespaces(); err != nil {
return db, errors.Wrapf(err, "While setting banned keys")
}
// 开启写协程
// badger Set 操作都是写到 writeCh, 然后通过写协程来进行 db 写操作.
db.closers.writes = z.NewCloser(1)
go db.doWrites(db.closers.writes)
if !db.opt.InMemory {
// 开启 wisckey value log gc 协程
db.closers.valueGC = z.NewCloser(1)
go db.vlog.waitOnGC(db.closers.valueGC)
}
// 开启读写事件的监听协程
db.closers.pub = z.NewCloser(1)
go db.pub.listenForUpdates(db.closers.pub)
valueDirLockGuard = nil
dirLockGuard = nil
manifestFile = nil
return db, nil
}Close 为 badgerDB 的关闭入口, 当需要关闭 badger db 对象时, 需要使用 Close 来进行安全关闭. 如果直接粗暴的退出进行,而非优雅安全的调用 Close() 退出, 则会出现丢数据的可能.
比如, badger 的写操作是先写到 write channel 里的, 进程直接 crash 退出会丢失这一部分数据. wal 的写只有开启 sync 选项才是实时同步落盘的, 否则是写到 buffer 里, 如果机器发生重启,那么 page cache 的数据自然丢失. sstable 合并时可能会写到一半的情况,需要后面修复.
总之, 需要安全关闭.
func (db *DB) Close() error {
var err error
db.closeOnce.Do(func() {
err = db.close()
})
return err
}
func (db *DB) close() (err error) {
defer db.allocPool.Release()
db.blockWrites.Store(1)
if !db.opt.InMemory {
// 通知 value gc 协程退出
db.closers.valueGC.SignalAndWait()
}
// 通知 write 协程退出.
db.closers.writes.SignalAndWait()
close(db.writeCh)
// 通知 pub 协程退出.
db.closers.pub.SignalAndWait()
if db.mt != nil {
if db.mt.sl.Empty() {
// 如果空则解除引用.
db.mt.DecrRef()
} else {
for {
// 进行刷盘操作.
pushedFlushTask := func() bool {
db.lock.Lock()
defer db.lock.Unlock()
y.AssertTrue(db.mt != nil)
select {
case db.flushChan <- flushTask{mt: db.mt}:
db.imm = append(db.imm, db.mt) // Flusher will attempt to remove this from s.imm.
db.mt = nil // Will segfault if we try writing!
db.opt.Debugf("pushed to flush chan\n")
return true
default:
}
return false
}()
if pushedFlushTask {
break
}
time.Sleep(10 * time.Millisecond)
}
}
}
// 关闭 flush 和 compact 合并协程
db.stopMemoryFlush()
db.stopCompactions()
// 如果开启 CompactL0OnClose, 则退出时需要对 level 0 进行合并.
if db.opt.CompactL0OnClose {
err := db.lc.doCompact(173, compactionPriority{level: 0, score: 1.73})
switch err {
case errFillTables:
case nil:
default:
db.opt.Warningf("While forcing compaction on level 0: %v", err)
}
}
// 关闭 wisckey value log 文件.
if vlogErr := db.vlog.Close(); vlogErr != nil {
err = y.Wrap(vlogErr, "DB.Close")
}
db.opt.Infof(db.LevelsToString())
if lcErr := db.lc.close(); err == nil {
err = y.Wrap(lcErr, "DB.Close")
}
db.opt.Debugf("Waiting for closer")
db.closers.updateSize.SignalAndWait()
db.orc.Stop()
db.blockCache.Close()
db.indexCache.Close()
db.isClosed.Store(1)
db.threshold.close()
if db.opt.InMemory {
return
}
// 释放 dir 文件锁
if db.dirLockGuard != nil {
if guardErr := db.dirLockGuard.release(); err == nil {
err = y.Wrap(guardErr, "DB.Close")
}
}
// 释放 valueDir 文件锁
if db.valueDirGuard != nil {
if guardErr := db.valueDirGuard.release(); err == nil {
err = y.Wrap(guardErr, "DB.Close")
}
}
// 关闭 manifest 文件描述符
if manifestErr := db.manifest.close(); err == nil {
err = y.Wrap(manifestErr, "DB.Close")
}
// 强制同步 dir 数据到磁盘
if syncErr := db.syncDir(db.opt.Dir); err == nil {
err = y.Wrap(syncErr, "DB.Close")
}
// 强制同步 valueDir 数据到磁盘
if syncErr := db.syncDir(db.opt.ValueDir); err == nil {
err = y.Wrap(syncErr, "DB.Close")
}
return err
}openMemTables 用来构建 immutable memtables, 其内部的逻辑是这样, 先扫描 db 目录里 .mem 结尾的 memtable 文件, 这里的 memtable 文件本质就是 wal 文件. 然后把 wal 文件读取出来,构建 skiplist 跳表, 然后构建 memtable 内存里的对象, 把这些构建出来的 memtable 归到 immutable memtables 集合里.
这里需要说明一下, 像其他数据库也都有 wal, 需要实现 checkpoints 检查点和 recovery 恢复机制. 比如为了避免 wal 太大, 数据归档到 db 文件后需要对 wal 文件进行删减, 删减的点就是 checkpoints 检查点, 当 db 正常或异常恢复启动时, 需要重做日志, 把 wal 的数据写到内存缓存里.
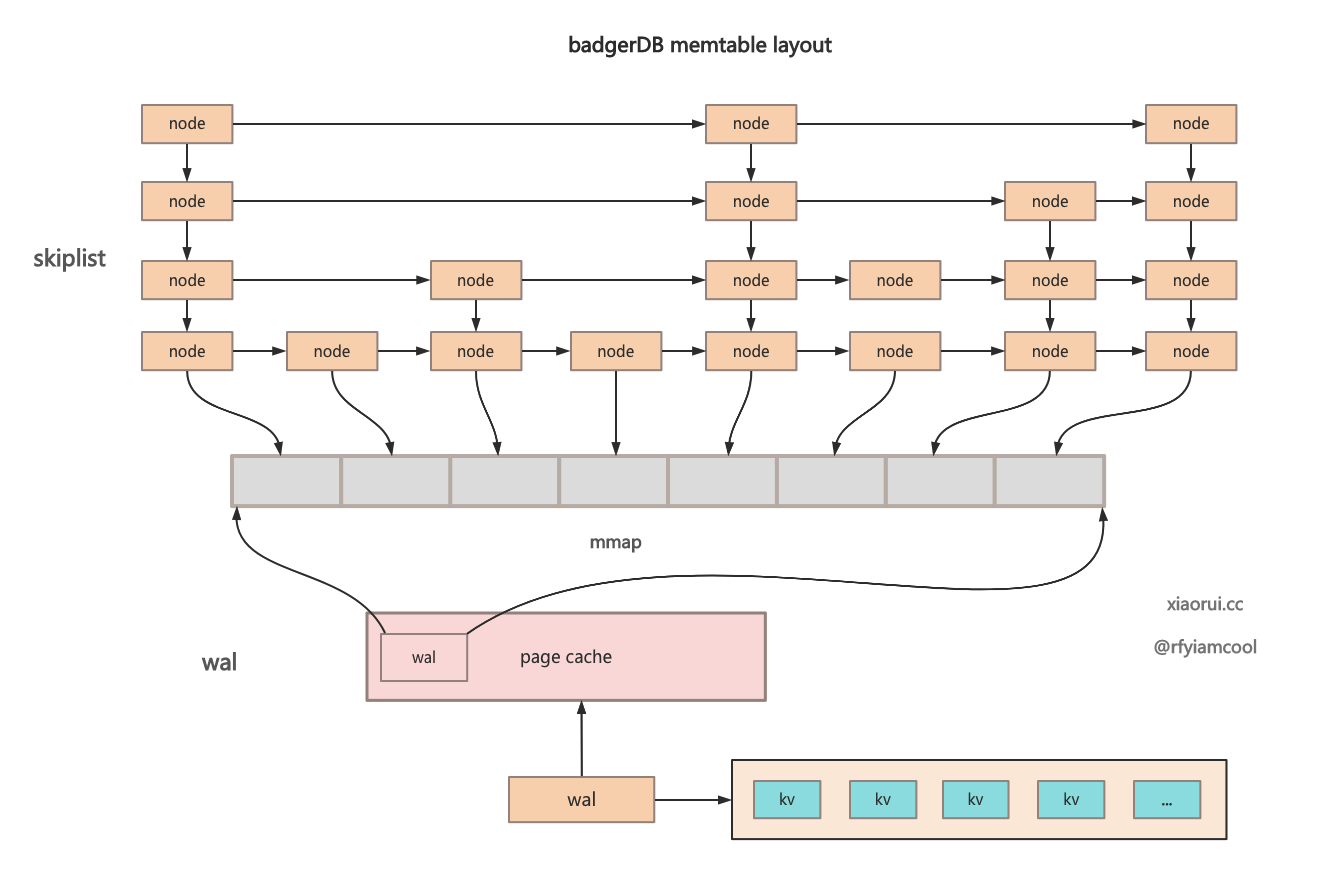
而 badgerDB 的 wal 预写日志设计很巧妙, 它的 wal 是跟 memtable 对象绑定的. memtable 是由 skiplist 和 wal 组成的. skiplist 用来实现 kv 的快速检索, 其中 value 不存储数据,而只是存储 wal 文件的偏移量信息.而 wal 存储预写日志,该日志使用 mmap 映射到进程空间里,对于应用层来说就是个 []byte 字节数组.
当使用 badgerDB 写数据时, 会先写到活跃 memtable 的 wal 文件里, 使用 mmap msync 进行刷盘, 接着把对象加到 skiplist 跳表里, skiplist 的 node 没有数据实体, 而是指向 memtable.wal 文件的偏移量, 由于 memtable 和 immutable memtable 没有使用 cahce 组件,所以基本是内存读操作.
当某个最旧的 memtable 被刷到 Level 0 层后, 该 memtable 则需要被删除, memtale 对应的 wal 日志文件自然也要被删除.
通过下图更好的理解 badger memtable 的设计.
const memFileExt string = ".mem"
func (db *DB) openMemTables(opt Options) error {
if db.opt.InMemory {
return nil
}
// 获取 db dir 的所有文件名.
files, err := os.ReadDir(db.opt.Dir)
if err != nil {
return errFile(err, db.opt.Dir, "Unable to open mem dir.")
}
var fids []int
// 遍历 db dir 的所有文件.
for _, file := range files {
// 如果不是 .mem 结尾, 说明不是 memtable.wal 文件.
if !strings.HasSuffix(file.Name(), memFileExt) {
continue
}
fsz := len(file.Name())
// 获取文件的 file id.
fid, err := strconv.ParseInt(file.Name()[:fsz-len(memFileExt)], 10, 64)
if err != nil {
return errFile(err, file.Name(), "Unable to parse log id.")
}
// 添加 fid 到 fids 集合里.
fids = append(fids, int(fid))
}
// 对文件进行升序排序.
sort.Slice(fids, func(i, j int) bool {
return fids[i] < fids[j]
})
// 遍历文件列表
for _, fid := range fids {
flags := os.O_RDWR
if db.opt.ReadOnly {
flags = os.O_RDONLY
}
// 打开文件并创建 memtable 对象
mt, err := db.openMemTable(fid, flags)
if err != nil {
return y.Wrapf(err, "while opening fid: %d", fid)
}
// 如果 skiplist 为空, 则解除引用, 尝试删除文件.
if mt.sl.Empty() {
mt.DecrRef()
continue
}
// 把 memtable 对象加到 immutable memtabels 集合里.
db.imm = append(db.imm, mt)
}
if len(fids) != 0 {
db.nextMemFid = fids[len(fids)-1]
}
db.nextMemFid++
return nil
}
func (db *DB) openMemTable(fid, flags int) (*memTable, error) {
// 获取文件路径
filepath := db.mtFilePath(fid)
// 实例化 skiplist 对象
s := skl.NewSkiplist(arenaSize(db.opt))
mt := &memTable{
sl: s,
opt: db.opt,
buf: &bytes.Buffer{},
}
if db.opt.InMemory {
return mt, z.NewFile
}
// 实例化 wal 对象, 这里的 wal 是通过 logFile 实现的, badger 的 wal 和 wisckey vlog 都是 logFile 实现的.
mt.wal = &logFile{
fid: uint32(fid),
path: filepath,
registry: db.registry,
writeAt: vlogHeaderSize,
opt: db.opt,
}
// 使用 mmap 来映射 wal 文件到进程空间.
lerr := mt.wal.open(filepath, flags, 2*db.opt.MemTableSize)
if lerr != z.NewFile && lerr != nil {
return nil, y.Wrapf(lerr, "While opening memtable: %s", filepath)
}
s.OnClose = func() {
if err := mt.wal.Delete(); err != nil {
db.opt.Errorf("while deleting file: %s, err: %v", filepath, err)
}
}
if lerr == z.NewFile {
return mt, lerr
}
// 把 wal 的数据读取出来, 添加到 skiplist 跳表结构里.
err := mt.UpdateSkipList()
return mt, y.Wrapf(err, "while updating skiplist")
}badger 的 wal 和 sstable 的读写都使用了 mmap 文件映射. 还有 badger 在初始阶段构建 levelController 控制器时, 把所有的 sstable 和 wal 文件用 mmap 方式映射到进程地址空间里.
- 什么是 mmap ?
- mmap 对比 read/write 的优缺点是什么?
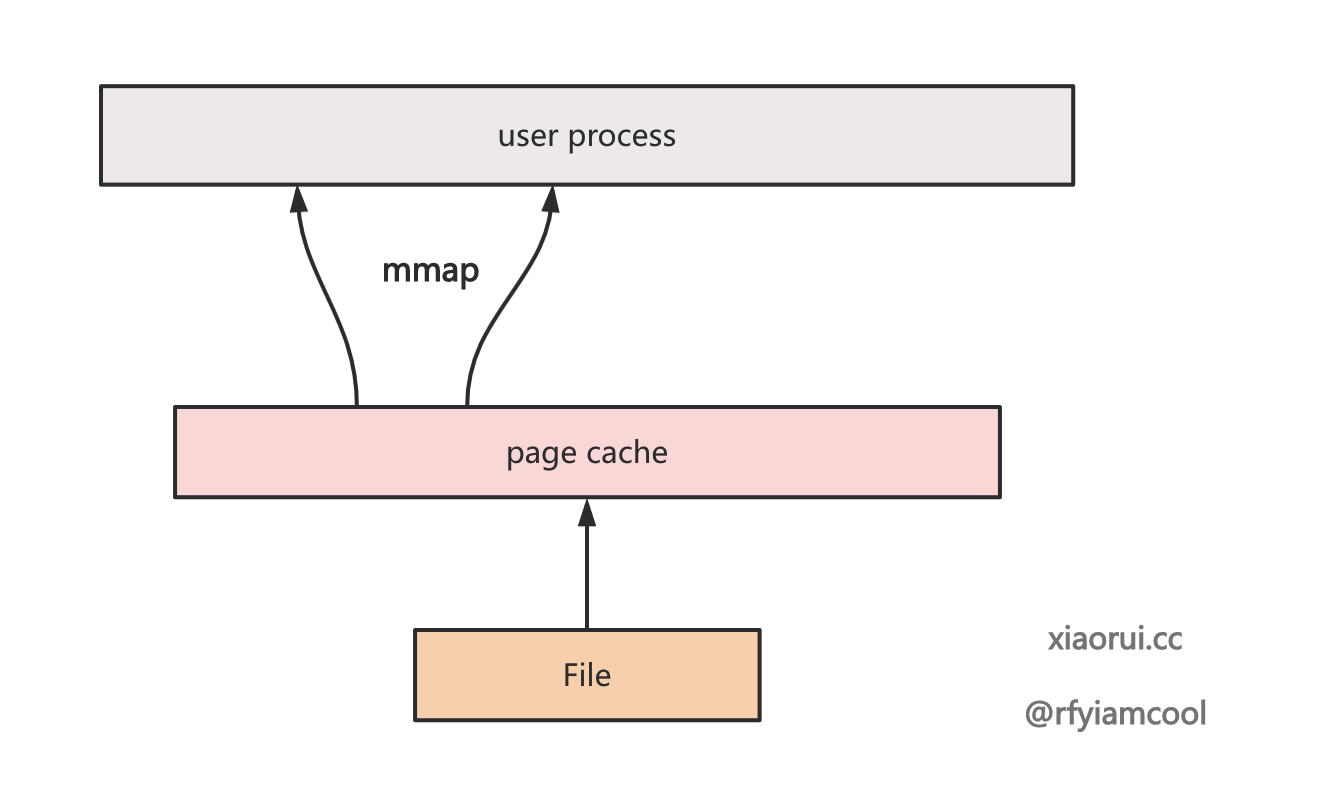
mmap() 是一种内存映射文件的方法,将一个文件映射到进程的地址空间,实现文件磁盘地址和一段进程虚拟地址的映射。实现这样的映射关系后,进程就可以采用指针的方式读写操作这一段内存,无需使用 read/write 系统调用函数. 另外, 在内核空间对这段区域的修改, 也直接反映用户空间.
es, kafka, pulsarMQ 和 rocketMQ 等等都使用 mmap 来管理文件.
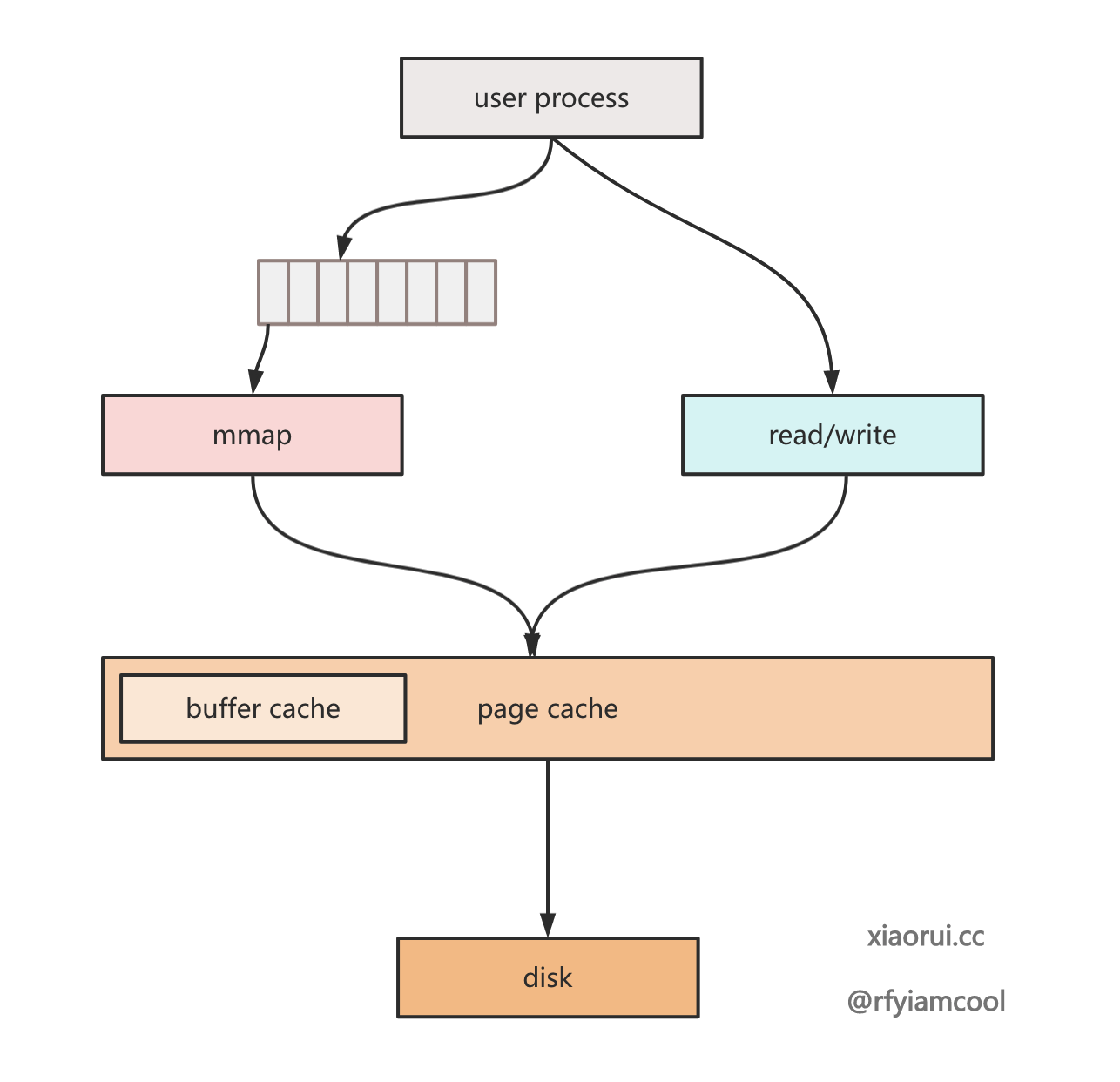
read/write 系统调用的流程:
- 访问文件, 这涉及到用户态到内核态的转换.
- 从磁盘中读取文件中并写到 page cache 缓存中.
- 将 read 中需要的数据, 从 page cache 中拷贝到用户缓冲区中. 如果是写操作, 则需要把数据写到 page cache 里.
整个过程还是比较繁琐, 涉及到用户和内核态之间的切换, 还有数据的拷贝.
而 mmap 系统调用是将硬盘文件对应的 page cache 地址映射到进程地址空间里. 进程可以直接访问自身地址空间的虚拟地址来访问 page cache 中的页. 简单理解就是 mmap 后返回一个数组指针, 可直接对该数组进行读写操作.
mmap 读写的流程:
- 使用 mmap 映射文件到进程的地址空间
- 直接从字节数组中读写数据即可.
- 手动执行 msync 或者等待内核进行同步刷盘操作.
就读写性能来说, mmap 会比 read/write 系统调用更加高效一些, 当然read/write 易用性更好. 另外使用 mmap 可以更好的构建缓存, 比如原始数据在磁盘中, 一般构建缓存需要把数据放在内存中, 而使用 mmap 则实现的更加优雅.
拿 badger 来说, memtable 中使用 skiplist 在内存中构建索引, 而 skiplist node 指向的 value则在 wal 中,而 wal 又使用 mmap 映射到进程地址空间. 对于上层应用来说 mmap 的空间当成一个 []byte 数组. sstable 也被 mmap 映射了, 由于 sstable 的文件结构布局是索引结构化的, 可以直接用 mmap 的空间做 sstable 缓存.
badgerDB 是通过 flock 文件锁实现进程级别的锁, 用以确保只有一个进程可以打开 badger db, 在已被打开的情况下,其他进程会因拿不到而异常退出. leveldb 和 rocksdb 也是使用 flock 实现 db 读写安全.
其实除了 flock 外, 使用 syscall fcntl 也是可以实现 flock 相同的文件锁功能.
func Open(opt Options) (*DB, error) {
// ...
if !opt.BypassLockGuard {
dirLockGuard, err = acquireDirectoryLock(opt.Dir, lockFile, opt.ReadOnly)
if err != nil {
return nil, err
}
defer func() {
if dirLockGuard != nil {
_ = dirLockGuard.release()
}
}()
}
// ...
}下面使用 linux 提供的 flock 测试文件锁的效果.
终端1
$ flock -xn log sleep 10
echo $?
0
终端2
$ flock -xn log sleep 10
echo $?
1
const (
lockFile = "LOCK"
)
// acquireDirectoryLock gets a lock on the directory (using flock). If
// this is not read-only, it will also write our pid to
// dirPath/pidFileName for convenience.
func acquireDirectoryLock(dirPath string, pidFileName string, readOnly bool) (
*directoryLockGuard, error) {
absPidFilePath, err := filepath.Abs(filepath.Join(dirPath, pidFileName))
if err != nil {
return nil, y.Wrapf(err, "cannot get absolute path for pid lock file")
}
// 打开 LOCK 文件
f, err := os.Open(dirPath)
if err != nil {
return nil, y.Wrapf(err, "cannot open directory %q", dirPath)
}
// 配置互斥和非阻塞的标记
opts := unix.LOCK_EX | unix.LOCK_NB
if readOnly {
opts = unix.LOCK_SH | unix.LOCK_NB
}
// 调用 unix.Flock 拿锁, 当已被占用时, 直接报错退出.
err = unix.Flock(int(f.Fd()), opts)
if err != nil {
f.Close()
return nil, y.Wrapf(err,
"Cannot acquire directory lock on %q. Another process is using this Badger database.",
dirPath)
}
if !readOnly {
// 把当前的 go 进程的 pid 写进去.
err = os.WriteFile(absPidFilePath, []byte(fmt.Sprintf("%d\n", os.Getpid())), 0666)
if err != nil {
f.Close()
return nil, y.Wrapf(err,
"Cannot write pid file %q", absPidFilePath)
}
}
// 返回释放锁的回调函数.
return &directoryLockGuard{f, absPidFilePath, readOnly}, nil
}释放锁的逻辑是先关闭文件, 再收尾删除文件. 其实当 golang 程序直接 crash 崩溃, 没有删除 lock 文件, 其他进程也可以直接拿到锁的.
// Release deletes the pid file and releases our lock on the directory.
func (guard *directoryLockGuard) release() error {
var err error
if !guard.readOnly {
// It's important that we remove the pid file first.
err = os.Remove(guard.path)
}
if closeErr := guard.f.Close(); err == nil {
err = closeErr
}
guard.path = ""
guard.f = nil
return err
}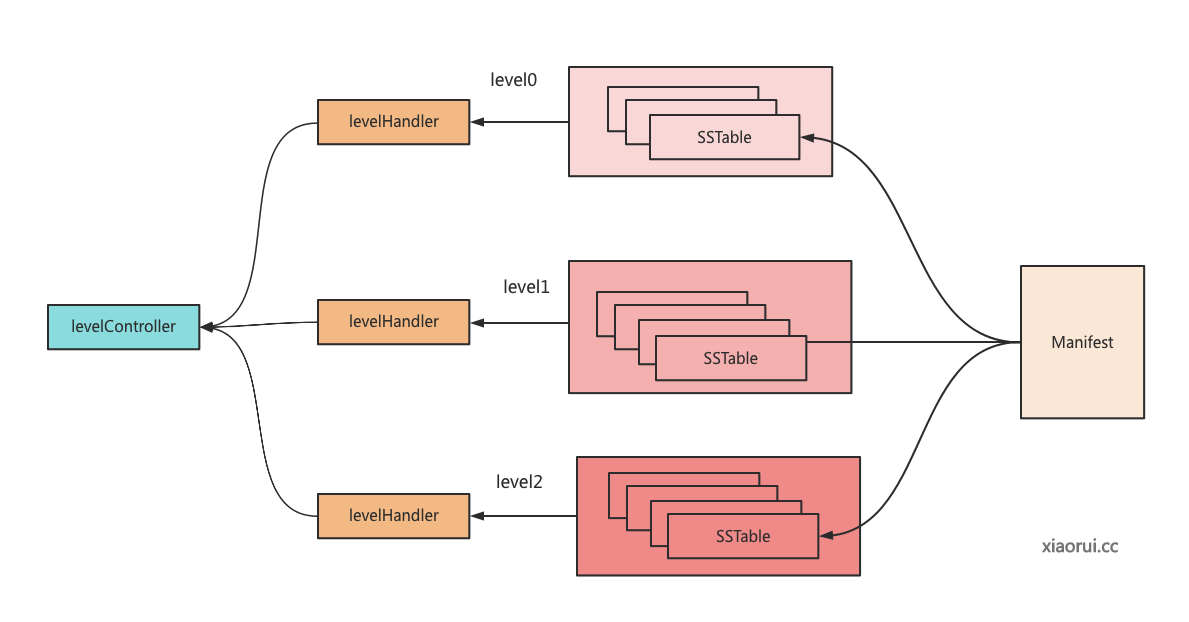
LevelsController 控制器对象用来组织管理各级的 level 及其下面的 tables 集合. newLevelsController 用来生成 levelController 控制器对象, 其内部就是把注册在 manifest 里的 tables 关联到 levelsController 控制器里.
func newLevelsController(db *DB, mf *Manifest) (*levelsController, error) {
s := &levelsController{
kv: db,
// 预设 levels 数组
levels: make([]*levelHandler, db.opt.MaxLevels),
}
// ...
// 实例化各个 levelHandler 对象
for i := 0; i < db.opt.MaxLevels; i++ {
s.levels[i] = newLevelHandler(db, i)
s.cstatus.levels[i] = new(levelCompactStatus)
}
if db.opt.InMemory {
return s, nil
}
// 用来判断是否有 manifest 没关联的 table 文件, 如果有则进行删除. manifest 里记录了所有的有效的 sstable 文件. 当合并写入新 sstable 发生异常 crash, 则会出现不一致的问题. 另外合并完成没来得及删除旧文件,也会出现不一致.
if err := revertToManifest(db, mf, getIDMap(db.opt.Dir)); err != nil {
return nil, err
}
var mu sync.Mutex
tables := make([][]*table.Table, db.opt.MaxLevels)
var maxFileID uint64
// badger 抽象了一个并发控制对象.
throttle := y.NewThrottle(3)
start := time.Now()
var numOpened atomic.Int32
tick := time.NewTicker(3 * time.Second)
defer tick.Stop()
// 遍历 manifest 注册的 tables 集合.
for fileID, tf := range mf.Tables {
// 获取全路径名字
fname := table.NewFilename(fileID, db.opt.Dir)
select {
case <-tick.C:
default:
}
// 尝试获取并发位
if err := throttle.Do(); err != nil {
closeAllTables(tables)
return nil, err
}
if fileID > maxFileID {
maxFileID = fileID
}
// 进行异步读取.
go func(fname string, tf TableManifest) {
var rerr error
defer func() {
// 释放并发位
throttle.Done(rerr)
numOpened.Add(1)
}()
// ...
topt := buildTableOptions(db)
topt.Compression = tf.Compression
topt.DataKey = dk
// 通过 mmap 读取映射 table 文件.
mf, err := z.OpenMmapFile(fname, db.opt.getFileFlags(), 0)
if err != nil {
rerr = y.Wrapf(err, "Opening file: %q", fname)
return
}
// 构建 table 对象.
t, err := table.OpenTable(mf, topt)
if err != nil {
// ...
}
// 加锁,把读取到的 table 添加到集合里.
mu.Lock()
tables[tf.Level] = append(tables[tf.Level], t)
mu.Unlock()
}(fname, tf)
}
if err := throttle.Finish(); err != nil {
closeAllTables(tables)
return nil, err
}
// 对各 level 进行表初始化.
for i, tbls := range tables {
s.levels[i].initTables(tbls)
}
// 验证表的 key range 是否有重叠.
if err := s.validate(); err != nil {
_ = s.cleanupLevels()
return nil, y.Wrap(err, "Level validation")
}
// 由于前面有一些删文件操作, 所以这里进行同步刷盘.
if err := syncDir(db.opt.Dir); err != nil {
_ = s.close()
return nil, err
}
return s, nil
}badger 的启动和关闭流程的代码还是好理解的.