Notice: This is only For the convinience of Chineses reader who cannot read English version directly
文章首发自我的CSDN博客:NLP自然语言处理-谷歌BERT模型深度解析,引用请注明出处
Author-作者
Junseong Kim, Scatter Lab ([email protected] / [email protected])
License-协议
This project following Apache 2.0 License as written in LICENSE file 本项目基于Apache2.0协议
Copyright 2018 Junseong Kim, Scatter Lab, respective BERT contributors
Copyright (c) 2018 Alexander Rush : The Annotated Trasnformer
Environment require:
---tqdm
---numpy
---torch>=0.4.0
---python3.6+
This version has based on the version in https://github.com/codertimo/BERT-pytorch
此中文版本仅基于原作者Junseong Kim与原Google项目的pytorch版本代码作为分享,如有其他用途请与原作者联系






Pytorch implementation of Google AI's 2018 BERT, with simple annotation
BERT 2018 BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding Paper URL : https://arxiv.org/abs/1810.04805
最近谷歌搞了个大新闻,公司AI团队新发布的BERT模型,在机器阅读理解顶级水平测试SQuAD1.1中表现出惊人的成绩:全部两个衡量指标上全面超越人类,并且还在11种不同NLP测试中创出最佳成绩,包括将GLUE基准推至80.4%(绝对改进7.6%),MultiNLI准确度达到86.7% (绝对改进率5.6%)等。可以预见的是,BERT将为NLP带来里程碑式的改变,也是NLP领域近期最重要的进展。
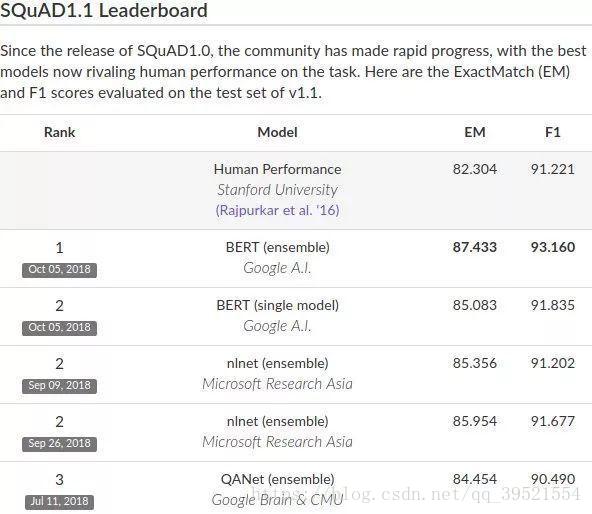
谷歌团队的Thang Luong直接定义:BERT模型开启了NLP的新时代
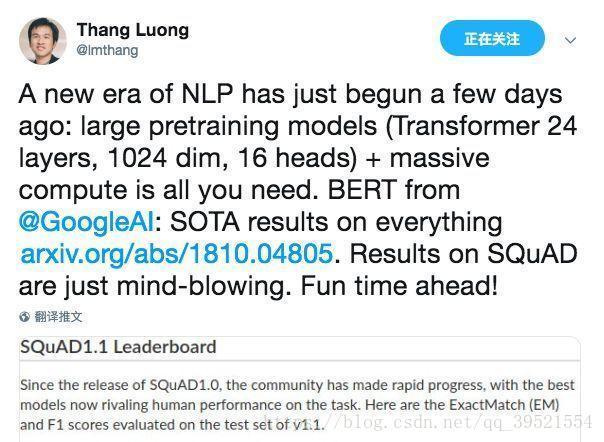
从现在的大趋势来看,使用某种模型预训练一个语言模型看起来是一种比较靠谱的方法。从之前AI2的 ELMo,到 OpenAI的fine-tune transformer,再到Google的这个BERT,全都是对预训练的语言模型的应用。
BERT这个模型与其它两个不同的是,它在训练双向语言模型时以减小的概率把少量的词替成了Mask或者另一个随机的词。我个人感觉这个目的在于使模型被迫增加对上下文的记忆。至于这个概率,我猜是Jacob拍脑袋随便设的。增加了一个预测下一句的loss。这个看起来就比较新奇了。
第一,是这个模型非常的深,12层,并不宽(wide),中间层只有1024,而之前的Transformer模型中间层有2048。这似乎又印证了计算机图像处理的一个观点——深而窄 比 浅而宽 的模型更好。
第二,MLM(Masked Language Model),同时利用左侧和右侧的词语,这个在ELMo上已经出现了,绝对不是原创。其次,对于Mask(遮挡)在语言模型上的应用,已经被Ziang Xie提出了(我很有幸的也参与到了这篇论文中):[1703.02573] Data Noising as Smoothing in Neural Network Language Models。这也是篇巨星云集的论文:Sida Wang,Jiwei Li(香侬科技的创始人兼CEO兼史上发文最多的NLP学者),Andrew Ng,Dan Jurafsky都是Coauthor。但很可惜的是他们没有关注到这篇论文。用这篇论文的方法去做Masking,相信BRET的能力说不定还会有提升。
部分代码基于 The Annotated Transformer 目前此项目仍在开发中,后续会有不断更新,欢迎FORK
通常情况 transformer 模型有很多参数需要训练。譬如 BERT BASE 模型: L=12, H=768, A=12, 需要训练的模型参数总数是 12 * 768 * 12 = 110M。这么多参数需要训练,自然需要海量的训练语料。如果全部用人力标注的办法,来制作训练数据,人力成本太大。
受《A Neural Probabilistic Language Model》论文的启发,BERT 也用 unsupervised 的办法,来训练 transformer 模型。神经概率语言模型这篇论文,主要讲了两件事儿,1. 能否用数值向量(word vector)来表达自然语言词汇的语义?2. 如何给每个词汇,找到恰当的数值向量?
这篇论文写得非常精彩,深入浅出,要言不烦,而且面面俱到。经典论文,值得反复咀嚼。很多同行朋友都熟悉这篇论文,内容不重复说了。常用的中文汉字有 3500 个,这些字组合成词汇,中文词汇数量高达 50 万个。假如词向量的维度是 512,那么语言模型的参数数量,至少是 512 * 50万 = 256M
模型参数数量这么大,必然需要海量的训练语料。从哪里收集这些海量的训练语料?《A Neural Probabilistic Language Model》这篇论文说,每一篇文章,天生是训练语料。难道不需要人工标注吗?回答,不需要。
深度学习四大要素,1. 训练数据、2. 模型、3. 算力、4. 应用。训练数据有了,接下去的问题是模型。关于模型,BERT提出了五个关键词 Pre-training、Deep、Bidirectional、Transformer、Language Understanding 。
《A Neural Probabilistic Language Model》这篇论文讲的 Language Model,严格讲是语言生成模型(Language Generative Model),预测语句中下一个将会出现的词汇。语言生成模型能不能直接移用到其它 NLP 问题上去?譬如,淘宝上有很多用户评论,能否把每一条用户转换成评分?-2、-1、0、1、2,其中 -2 是极差,+2 是极好。假如有这样一条用户评语,“买了一件鹿晗同款衬衫,没想到,穿在自己身上,不像小鲜肉,倒像是厨师”,请问这条评语,等同于 -2,还是其它?
语言生成模型,能不能很好地解决上述问题?进一步问,有没有 “通用的” 语言模型,能够理解语言的语义,适用于各种 NLP 问题?BERT 这篇论文的题目很直白,《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》,一眼看去,就能猜得到这篇文章会讲哪些内容。
这个题目有五个关键词,分别是 Pre-training、Deep、Bidirectional、Transformers、和 Language Understanding。其中 pre-training 的意思是,作者认为,确实存在通用的语言模型,先用文章预训练通用模型,然后再根据具体应用,用 supervised 训练数据,精加工(fine tuning)模型,使之适用于具体应用。为了区别于针对语言生成的 Language Model,作者给通用的语言模型,取了一个名字,叫语言表征模型 Language Representation Model。
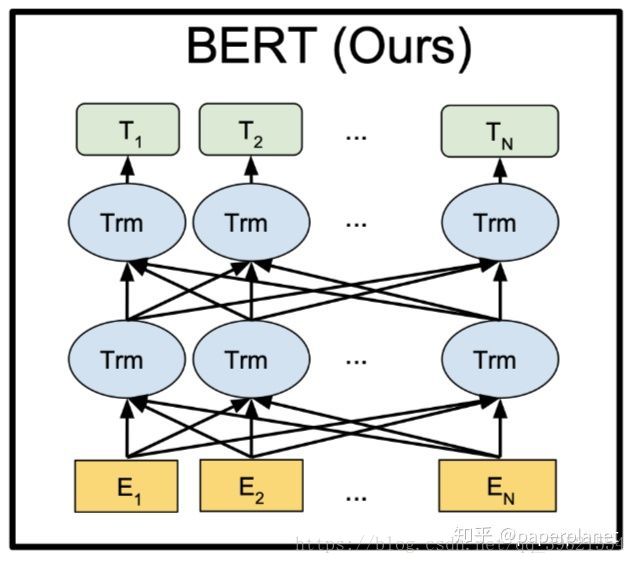
能实现语言表征目标的模型,可能会有很多种,具体用哪一种呢?作者提议,用 Deep Bidirectional Transformers 模型。假如给一个句子 “能实现语言表征[mask]的模型”,遮盖住其中“目标”一词。从前往后预测[mask],也就是用“能/实现/语言/表征”,来预测[mask];或者,从后往前预测[mask],也就是用“模型/的”,来预测[mask],称之为单向预测 unidirectional。单向预测,不能完整地理解整个语句的语义。于是研究者们尝试双向预测。把从前往后,与从后往前的两个预测,拼接在一起 [mask1/mask2],这就是双向预测 bi-directional。细节参阅《Neural Machine Translation by Jointly Learning to Align and Translate》。
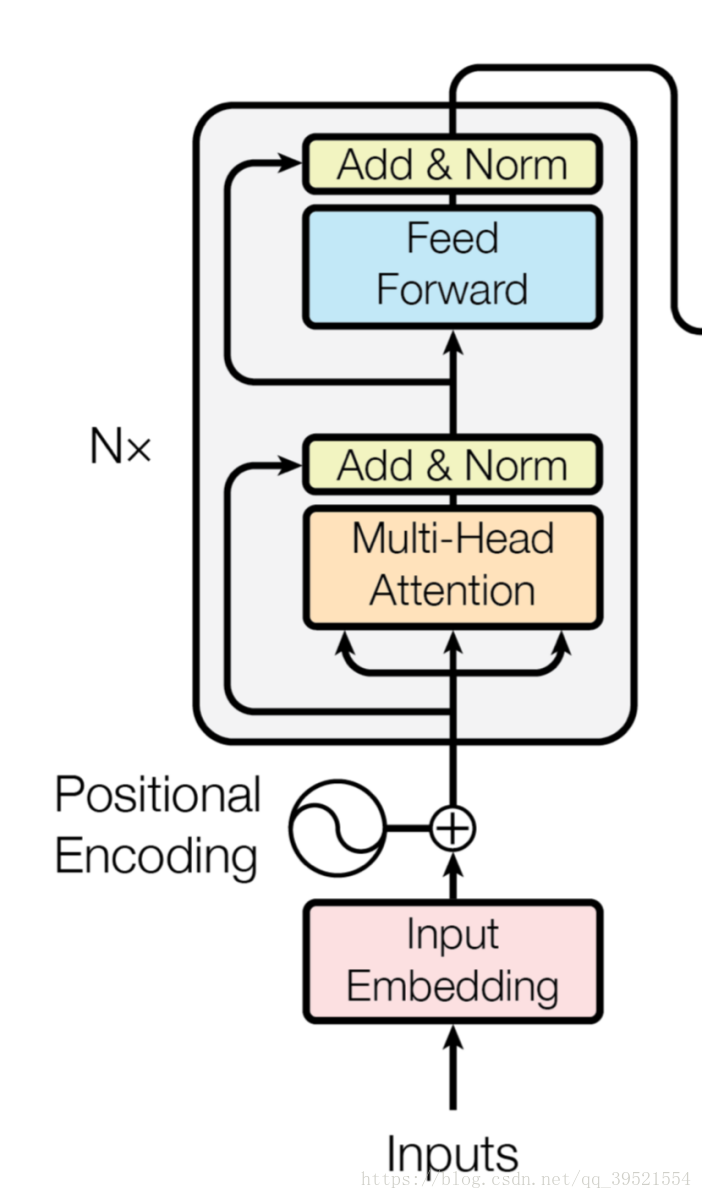
BERT 的作者认为,bi-directional 仍然不能完整地理解整个语句的语义,更好的办法是用上下文全向来预测[mask],也就是用 “能/实现/语言/表征/../的/模型”,来预测[mask]。BERT 作者把上下文全向的预测方法,称之为 deep bi-directional。如何来实现上下文全向预测呢?BERT 的作者建议使用 Transformer 模型。这个模型由《Attention Is All You Need》一文发明。
这个模型的核心是聚焦机制,对于一个语句,可以同时启用多个聚焦点,而不必局限于从前往后的,或者从后往前的,序列串行处理。不仅要正确地选择模型的结构,而且还要正确地训练模型的参数,这样才能保障模型能够准确地理解语句的语义。BERT 用了两个步骤,试图去正确地训练模型的参数。第一个步骤是把一篇文章中,15% 的词汇遮盖,让模型根据上下文全向地预测被遮盖的词。假如有 1 万篇文章,每篇文章平均有 100 个词汇,随机遮盖 15% 的词汇,模型的任务是正确地预测这 15 万个被遮盖的词汇。通过全向预测被遮盖住的词汇,来初步训练 Transformer 模型的参数。然后,用第二个步骤继续训练模型的参数。譬如从上述 1 万篇文章中,挑选 20 万对语句,总共 40 万条语句。挑选语句对的时候,其中 2乘10万对语句,是连续的两条上下文语句,另外 2x10 万对语句,不是连续的语句。然后让 Transformer 模型来识别这 20 万对语句,哪些是连续的,哪些不连续。
这两步训练合在一起,称为预训练 pre-training。训练结束后的 Transformer 模型,包括它的参数,是作者期待的通用的语言表征模型。
首先来看下谷歌AI团队做的这篇论文。

论文作者认为现有的技术严重制约了预训练表示的能力。其主要局限在于标准语言模型是单向的,这使得在模型的预训练中可以使用的架构类型很有限。在论文中,作者通过提出BERT:即Transformer的双向编码表示来改进基于架构微调的方法。
BERT 提出一种新的预训练目标:遮蔽语言模型(masked language model,MLM),来克服上文提到的单向性局限。MLM 的灵感来自 Cloze 任务(Taylor, 1953)。MLM 随机遮蔽模型输入中的一些 token,目标在于仅基于遮蔽词的语境来预测其原始词汇 id。
与从左到右的语言模型预训练不同,MLM 目标允许表征融合左右两侧的语境,从而预训练一个深度双向 Transformer。除了遮蔽语言模型之外,本文作者还引入了一个“下一句预测”(next sentence prediction)任务,可以和MLM共同预训练文本对的表示。
证明了双向预训练对语言表示的重要性。与之前使用的单向语言模型进行预训练不同,BERT使用遮蔽语言模型来实现预训练的深度双向表示。 论文表明,预先训练的表示免去了许多工程任务需要针对特定任务修改体系架构的需求。 BERT是第一个基于微调的表示模型,它在大量的句子级和token级任务上实现了最先进的性能,强于许多面向特定任务体系架构的系统。 BERT刷新了11项NLP任务的性能记录。本文还报告了 BERT 的模型简化研究(ablation study),表明模型的双向性是一项重要的新成果。相关代码和预先训练的模型将会公布在goo.gl/language/bert上。 BERT目前已经刷新的11项自然语言处理任务的最新记录包括:将GLUE基准推至80.4%(绝对改进7.6%),MultiNLI准确度达到86.7% (绝对改进率5.6%),将SQuAD v1.1问答测试F1得分纪录刷新为93.2分(绝对提升1.5分),超过人类表现2.0分。
本节介绍BERT模型架构和具体实现,并介绍预训练任务,这是这篇论文的核心创新。
BERT的模型架构是基于Vaswani et al. (2017) 中描述的原始实现multi-layer bidirectional Transformer编码器,并在tensor2tensor库中发布。由于Transformer的使用最近变得无处不在,论文中的实现与原始实现完全相同,因此这里将省略对模型结构的详细描述。
在这项工作中,论文将层数(即Transformer blocks)表示为L,将隐藏大小表示为H,将self-attention heads的数量表示为A。在所有情况下,将feed-forward/filter 的大小设置为 4H,即H = 768时为3072,H = 1024时为4096。论文主要报告了两种模型大小的结果:
BERT_{BASE}: L=12, H=768, A=12, Total Parameters=110MBERT_{LARGE}: L=24, H=1024, A=16, Total Parameters=340M
为了进行比较,论文选择了BASE,它与OpenAI GPT具有相同的模型大小。然而,重要的是,BERT Transformer 使用双向self-attention,而GPT Transformer 使用受限制的self-attention,其中每个token只能处理其左侧的上下文。研究团队注意到,在文献中,双向 Transformer 通常被称为“Transformer encoder”,而左侧上下文被称为“Transformer decoder”,因为它可以用于文本生成。BERT,OpenAI GPT和ELMo之间的比较如图1所示。
BERT使用双向Transformer。OpenAI GPT使用从左到右的Transformer。ELMo使用经过独立训练的从左到右和从右到左LSTM的串联来生成下游任务的特征。三个模型中,只有BERT表示在所有层中共同依赖于左右上下文。
论文的输入表示(input representation)能够在一个token序列中明确地表示单个文本句子或一对文本句子(例如, [Question, Answer])。对于给定token,其输入表示通过对相应的token、segment和position embeddings进行求和来构造。图2是输入表示的直观表示:

具体如下:
- 使用WordPiece嵌入(Wu et al., 2016)和30,000个token的词汇表。用##表示分词。
- 使用学习的positional embeddings,支持的序列长度最多为512个token。
- 每个序列的第一个token始终是特殊分类嵌入([CLS])。对应于该token的最终隐藏状态(即,Transformer的输出)被用作分类任务的聚合序列表示。对于非分类任务,将忽略此向量。
- 句子对被打包成一个序列。以两种方式区分句子。首先,用特殊标记([SEP])将它们分开。其次,添加一个learned sentence A嵌入到第一个句子的每个token中,一个sentence B嵌入到第二个句子的每个token中。
- 对于单个句子输入,只使用 sentence A嵌入。
与Peters et al. (2018) 和 Radford et al. (2018)不同,论文不使用传统的从左到右或从右到左的语言模型来预训练BERT。相反,使用两个新的无监督预测任务对BERT进行预训练。
从直觉上看,研究团队有理由相信,深度双向模型比left-to-right 模型或left-to-right and right-to-left模型的浅层连接更强大。遗憾的是,标准条件语言模型只能从左到右或从右到左进行训练,因为双向条件作用将允许每个单词在多层上下文中间接地“see itself”。
为了训练一个深度双向表示(deep bidirectional representation),研究团队采用了一种简单的方法,即随机屏蔽(masking)部分输入token,然后只预测那些被屏蔽的token。论文将这个过程称为“masked LM”(MLM),尽管在文献中它经常被称为Cloze任务(Taylor, 1953)。
在这个例子中,与masked token对应的最终隐藏向量被输入到词汇表上的输出softmax中,就像在标准LM中一样。在团队所有实验中,随机地屏蔽了每个序列中15%的WordPiece token。与去噪的自动编码器(Vincent et al., 2008)相反,只预测masked words而不是重建整个输入。
虽然这确实能让团队获得双向预训练模型,但这种方法有两个缺点。首先,预训练和finetuning之间不匹配,因为在finetuning期间从未看到[MASK]token。为了解决这个问题,团队并不总是用实际的[MASK]token替换被“masked”的词汇。相反,训练数据生成器随机选择15%的token。例如在这个句子“my dog is hairy”中,它选择的token是“hairy”。然后,执行以下过程:
数据生成器将执行以下操作,而不是始终用[MASK]替换所选单词:
- 80%的时间:用[MASK]标记替换单词,例如,my dog is hairy → my dog is [MASK]
- 10%的时间:用一个随机的单词替换该单词,例如,my dog is hairy → my dog is apple
- 10%的时间:保持单词不变,例如,my dog is hairy → my dog is hairy. 这样做的目的是将表示偏向于实际观察到的单词。
Transformer encoder不知道它将被要求预测哪些单词或哪些单词已被随机单词替换,因此它被迫保持每个输入token的分布式上下文表示。此外,因为随机替换只发生在所有token的1.5%(即15%的10%),这似乎不会损害模型的语言理解能力。
使用MLM的第二个缺点是每个batch只预测了15%的token,这表明模型可能需要更多的预训练步骤才能收敛。团队证明MLM的收敛速度略慢于 left-to-right的模型(预测每个token),但MLM模型在实验上获得的提升远远超过增加的训练成本。
许多重要的下游任务,如问答(QA)和自然语言推理(NLI)都是基于理解两个句子之间的关系,这并没有通过语言建模直接获得。
在为了训练一个理解句子的模型关系,预先训练一个二进制化的下一句测任务,这一任务可以从任何单语语料库中生成。具体地说,当选择句子A和B作为预训练样本时,B有50%的可能是A的下一个句子,也有50%的可能是来自语料库的随机句子。例如:
Input = [CLS] the man went to [MASK] store [SEP]
he bought a gallon [MASK] milk [SEP]
Label = IsNext
Input = [CLS] the man [MASK] to the store [SEP]
penguin [MASK] are flight ##less birds [SEP]
Label = NotNext
团队完全随机地选择了NotNext语句,最终的预训练模型在此任务上实现了97%-98%的准确率。
如前文所述,BERT在11项NLP任务中刷新了性能表现记录!在这一节中,团队直观呈现BERT在这些任务的实验结果,具体的实验设置和比较请阅读原论文.
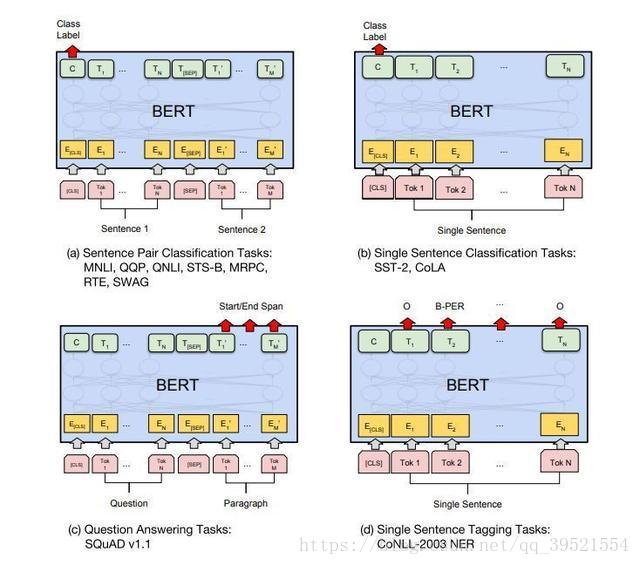
图3:我们的面向特定任务的模型是将BERT与一个额外的输出层结合而形成的,因此需要从头开始学习最小数量的参数。在这些任务中,(a)和(b)是序列级任务,而(c)和(d)是token级任务。在图中,E表示输入嵌入,Ti表示tokeni的上下文表示,[CLS]是用于分类输出的特殊符号,[SEP]是用于分隔非连续token序列的特殊符号。
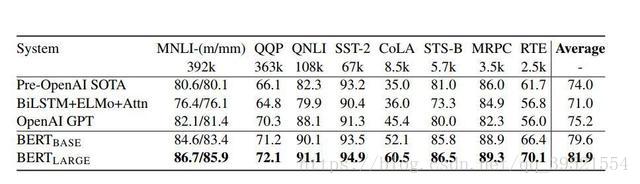


图6:CoNLL-2003 命名实体识别结果。超参数由开发集选择,得出的开发和测试分数是使用这些超参数进行五次随机重启的平均值。
BERT是一个语言表征模型(language representation model),通过超大数据、巨大模型、和极大的计算开销训练而成,在11个自然语言处理的任务中取得了最优(state-of-the-art, SOTA)结果。或许你已经猜到了此模型出自何方,没错,它产自谷歌。估计不少人会调侃这种规模的实验已经基本让一般的实验室和研究员望尘莫及了,但它确实给我们提供了很多宝贵的经验:
- 深度学习就是表征学习 (Deep learning is representation learning):"We show that pre-trained representations eliminate the needs of many heavily engineered task-specific architectures". 在11项BERT刷出新境界的任务中,大多只在预训练表征(pre-trained representation)微调(fine-tuning)的基础上加一个线性层作为输出(linear output layer)。在序列标注的任务里(e.g. NER),甚至连序列输出的依赖关系都先不管(i.e. non-autoregressive and no CRF),照样秒杀之前的SOTA,可见其表征学习能力之强大。
- 规模很重要(Scale matters):"One of our core claims is that the deep bidirectionality of BERT, which is enabled by masked LM pre-training, is the single most important improvement of BERT compared to previous work". 这种遮挡(mask)在语言模型上的应用对很多人来说已经不新鲜了,但确是BERT的作者在如此超大规模的数据+模型+算力的基础上验证了其强大的表征学习能力。这样的模型,甚至可以延伸到很多其他的模型,可能之前都被不同的实验室提出和试验过,只是由于规模的局限没能充分挖掘这些模型的潜力,而遗憾地让它们被淹没在了滚滚的paper洪流之中。
- 预训练价值很大(Pre-training is important):"We believe that this is the first work to demonstrate that scaling to extreme model sizes also leads to large improvements on very small-scale tasks, provided that the model has been sufficiently pre-trained". 预训练已经被广泛应用在各个领域了(e.g. ImageNet for CV, Word2Vec in NLP),多是通过大模型大数据,这样的大模型给小规模任务能带来的提升有几何,作者也给出了自己的答案。BERT模型的预训练是用Transformer做的,但我想换做LSTM或者GRU的话应该不会有太大性能上的差别,当然训练计算时的并行能力就另当别论了。
model Tutorial
pip install bert-pytorch
注意 : 你的语料如果位于同一行,则应该由制表符\t所分割
Welcome to the \t the jungle\n
I can stay \t here all night\n
or tokenized corpus (tokenization is not in package)
Wel_ _come _to _the \t _the _jungle\n
_I _can _stay \t _here _all _night\n
bert-vocab -c data/corpus.small -o data/vocab.smallbert -c data/corpus.small -v data/vocab.small -o output/bert.model在原论文中,作者展示了新的语言训练模型,称为编码语言模型与次一句预测 In the paper, authors shows the new language model training methods, which are "masked language model" and "predict next sentence".
Original Paper : 3.3.1 Task #1: Masked LM
Input Sequence : The man went to [MASK] store with [MASK] dog
Target Sequence : the his
会有15%的随机输入被改变,这些改变基于以下规则: Randomly 15% of input token will be changed into something, based on under sub-rules:
- 80%的tokens会成为‘掩码’token
- 10%的tokens会称为‘随机’token
- 10%的tokens会保持不变但需要被预测
Original Paper : 3.3.2 Task #2: Next Sentence Prediction
Input : [CLS] the man went to the store [SEP] he bought a gallon of milk [SEP]
Label : Is Next
Input = [CLS] the man heading to the store [SEP] penguin [MASK] are flight ##less birds [SEP]
Label = NotNext
"Is this sentence can be continuously connected?"
- 50%的下一句会(随机)成为连续句子
- 50%的下一句会(随机)成为不关联句子
Junseong Kim, Scatter Lab ([email protected] / [email protected])
This project following Apache 2.0 License as written in LICENSE file
Copyright 2018 Junseong Kim, Scatter Lab, respective BERT contributors
Copyright (c) 2018 Alexander Rush : The Annotated Trasnformer