|
| 1 | + |
| 2 | +[](https://docs.vaex.io) |
| 3 | + |
| 4 | +# What is Vaex? |
| 5 | + |
| 6 | +Vaex is a high performance Python library for lazy **Out-of-Core DataFrames** |
| 7 | +(similar to Pandas), to visualize and explore big tabular datasets. It |
| 8 | +calculates *statistics* such as mean, sum, count, standard deviation etc, on an |
| 9 | +*N-dimensional grid* for more than **a billion** (`10^9`) samples/rows **per |
| 10 | +second**. Visualization is done using **histograms**, **density plots** and **3d |
| 11 | +volume rendering**, allowing interactive exploration of big data. Vaex uses |
| 12 | +memory mapping, zero memory copy policy and lazy computations for best |
| 13 | +performance (no memory wasted). |
| 14 | + |
| 15 | +# Key features |
| 16 | +## Instant opening of Huge data files (memory mapping) |
| 17 | +[HDF5](https://en.wikipedia.org/wiki/Hierarchical_Data_Format) and [Apache Arrow](https://arrow.apache.org/) supported. |
| 18 | + |
| 19 | + |
| 20 | + |
| 21 | + |
| 22 | +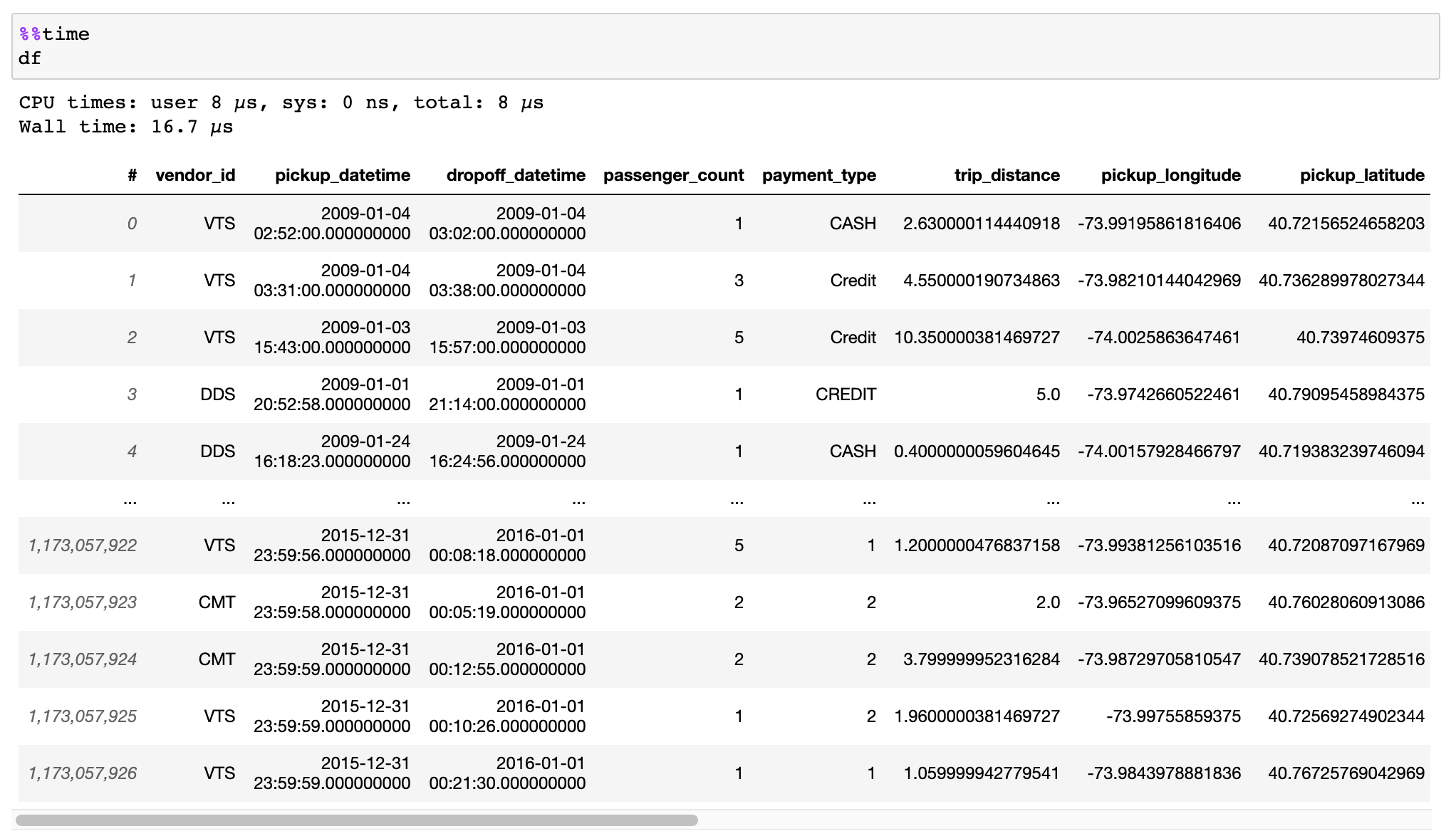 |
| 23 | + |
| 24 | +[Read the documentation on how to efficiently convert your data](https://docs.vaex.io/en/latest/example_io.html) from CSV files, Pandas DataFrames, or other sources. |
| 25 | + |
| 26 | + |
| 27 | +Lazy streaming from S3 supported in combination with memory mapping. |
| 28 | + |
| 29 | + |
| 30 | + |
| 31 | + |
| 32 | +## Expression system |
| 33 | +Don't waste memory or time with feature engineering, we (lazily) transform your data when needed. |
| 34 | + |
| 35 | + |
| 36 | +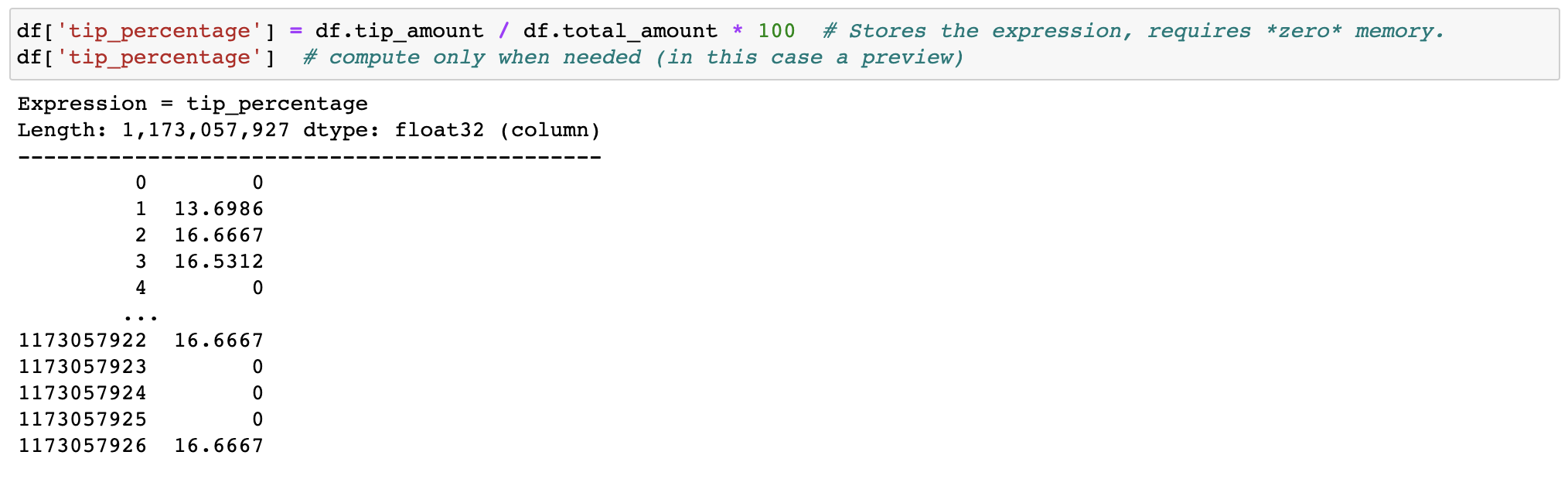 |
| 37 | + |
| 38 | + |
| 39 | + |
| 40 | +## Out-of-core DataFrame |
| 41 | +Filtering and evaluating expressions will not waste memory by making copies; the data is kept untouched on disk, and will be streamed only when needed. Delay the time before you need a cluster. |
| 42 | + |
| 43 | + |
| 44 | + |
| 45 | + |
| 46 | +## Fast groupby / aggregations |
| 47 | +Vaex implements parallelized, highly performant `groupby` operations, especially when using categories (>1 billion/second). |
| 48 | + |
| 49 | + |
| 50 | +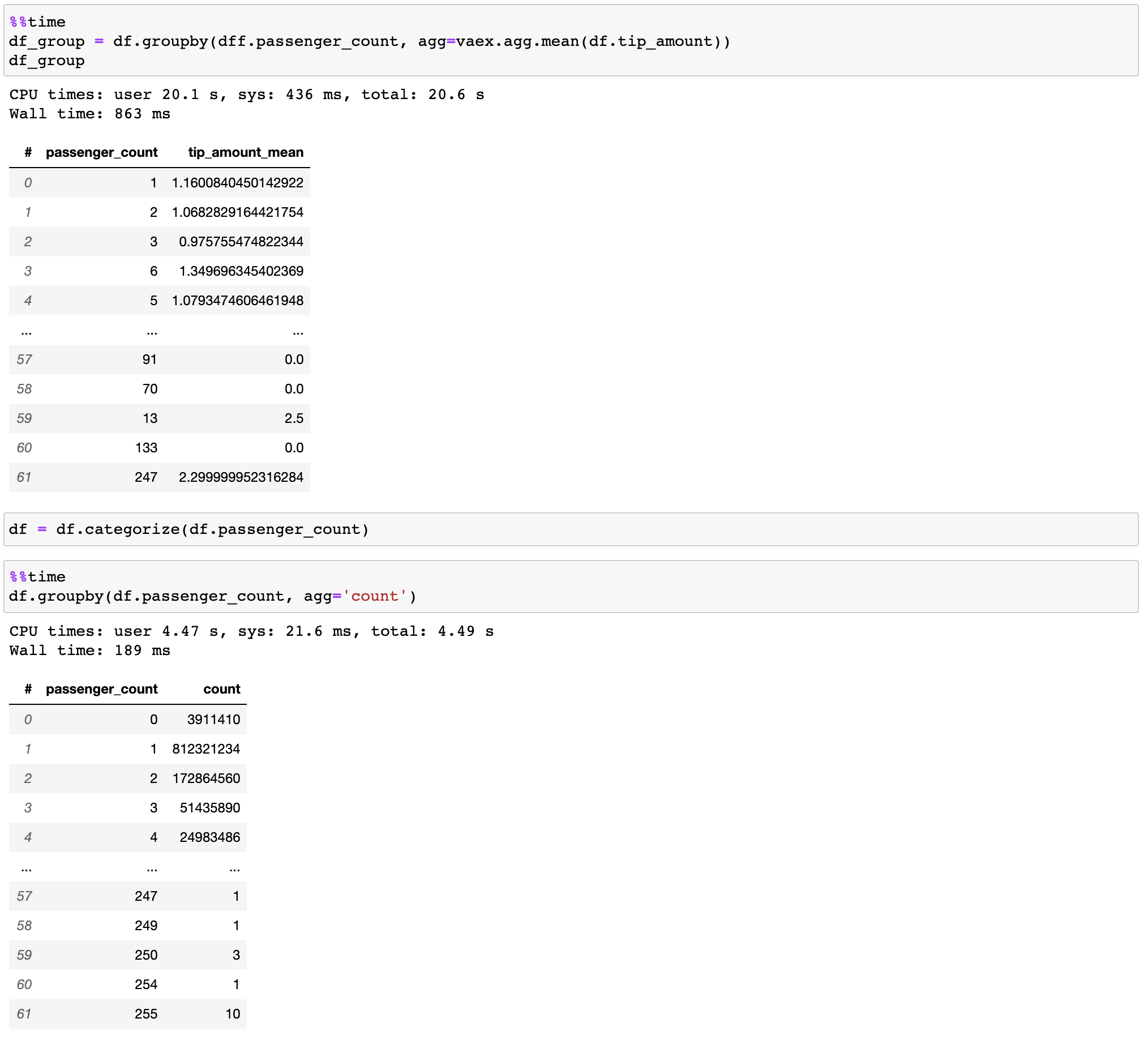 |
| 51 | + |
| 52 | + |
| 53 | +## Fast and efficient join |
| 54 | +Vaex doesn't copy/materialize the 'right' table when joining, saving gigabytes of memory. With subsecond joining on a billion rows, it's pretty fast! |
| 55 | + |
| 56 | +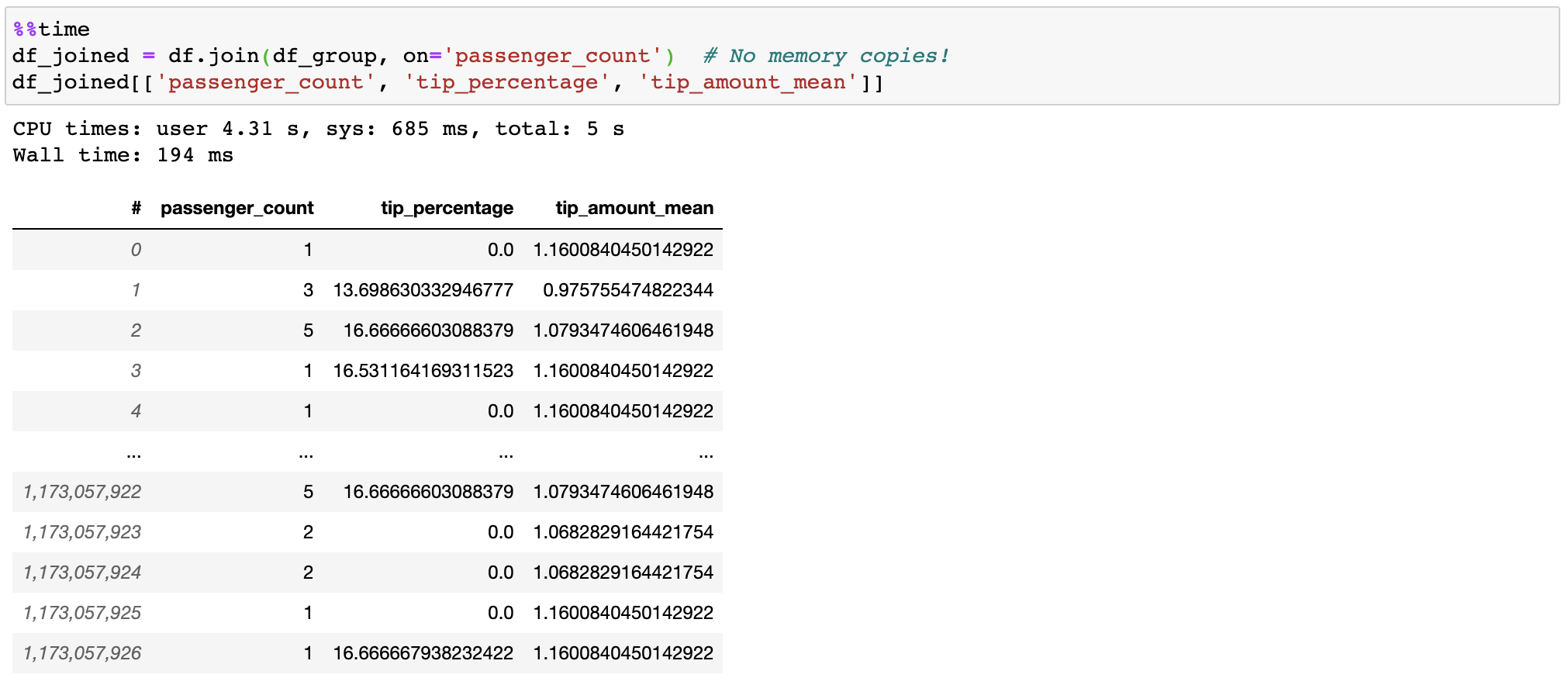 |
| 57 | + |
| 58 | +## More features |
| 59 | + |
| 60 | + * Remote DataFrames (documentation coming soon) |
| 61 | + * Integration into [Jupyter and Voila for interactive notebooks and dashboards](https://vaex.readthedocs.io/en/latest/tutorial_jupyter.html) |
| 62 | + * [Machine Learning without (explicit) pipelines](https://vaex.readthedocs.io/en/latest/tutorial_ml.html) |
| 63 | + |
| 64 | + |
| 65 | +# Learn how to use Vaex efficiently |
| 66 | + * [Follow our tutorials](https://docs.vaex.io/en/latest/tutorials.html) |
| 67 | + * Watch our more recent talks: |
| 68 | + * [PyData London 2019](https://www.youtube.com/watch?v=2Tt0i823-ec) |
| 69 | + * [SciPy 2019](https://www.youtube.com/watch?v=ELtjRdPT8is) |
| 70 | + * Contact us for training or enterprise support at https://vaex.io/ |
0 commit comments