from sklearn import datasets # 导入库
boston = datasets.load_boston() # 导入波士顿房价数据 print(boston.keys()) # 查看键(属性) ['data','target','feature_names','DESCR', 'filename'] print(boston.data.shape,boston.target.shape) # 查看数据的形状 (506, 13) (506,) print(boston.feature_names) # 查看有哪些特征 这里共13种 print(boston.DESCR) # described 描述这个数据集的信息 print(boston.filename) # 文件路径
dict_keys(['data', 'target', 'feature_names', 'DESCR', 'filename'])通过boston.data.shape查询得到data形状为(506, 13)
[[6.3200e-03 1.8000e+01 2.3100e+00 ... 1.5300e+01 3.9690e+02 4.9800e+00]
[2.7310e-02 0.0000e+00 7.0700e+00 ... 1.7800e+01 3.9690e+02 9.1400e+00]
[2.7290e-02 0.0000e+00 7.0700e+00 ... 1.7800e+01 3.9283e+02 4.0300e+00]
...
[6.0760e-02 0.0000e+00 1.1930e+01 ... 2.1000e+01 3.9690e+02 5.6400e+00]
[1.0959e-01 0.0000e+00 1.1930e+01 ... 2.1000e+01 3.9345e+02 6.4800e+00]
[4.7410e-02 0.0000e+00 1.1930e+01 ... 2.1000e+01 3.9690e+02 7.8800e+00]]通过boston.target.shape查询得到target形状为(506,)
[24. 21.6 34.7 33.4 36.2 28.7 22.9 27.1 16.5 18.9 15. 18.9 21.7 20.4
18.2 19.9 23.1 17.5 20.2 18.2 13.6 19.6 15.2 14.5 15.6 13.9 16.6 14.8
18.4 21. 12.7 14.5 13.2 13.1 13.5 18.9 20. 21. 24.7 30.8 34.9 26.6
25.3 24.7 21.2 19.3 20. 16.6 14.4 19.4 19.7 20.5 25. 23.4 18.9 35.4
24.7 31.6 23.3 19.6 18.7 16. 22.2 25. 33. 23.5 19.4 22. 17.4 20.9
24.2 21.7 22.8 23.4 24.1 21.4 20. 20.8 21.2 20.3 28. 23.9 24.8 22.9
23.9 26.6 22.5 22.2 23.6 28.7 22.6 22. 22.9 25. 20.6 28.4 21.4 38.7
43.8 33.2 27.5 26.5 18.6 19.3 20.1 19.5 19.5 20.4 19.8 19.4 21.7 22.8
18.8 18.7 18.5 18.3 21.2 19.2 20.4 19.3 22. 20.3 20.5 17.3 18.8 21.4
15.7 16.2 18. 14.3 19.2 19.6 23. 18.4 15.6 18.1 17.4 17.1 13.3 17.8
14. 14.4 13.4 15.6 11.8 13.8 15.6 14.6 17.8 15.4 21.5 19.6 15.3 19.4
17. 15.6 13.1 41.3 24.3 23.3 27. 50. 50. 50. 22.7 25. 50. 23.8
23.8 22.3 17.4 19.1 23.1 23.6 22.6 29.4 23.2 24.6 29.9 37.2 39.8 36.2
37.9 32.5 26.4 29.6 50. 32. 29.8 34.9 37. 30.5 36.4 31.1 29.1 50.
33.3 30.3 34.6 34.9 32.9 24.1 42.3 48.5 50. 22.6 24.4 22.5 24.4 20.
21.7 19.3 22.4 28.1 23.7 25. 23.3 28.7 21.5 23. 26.7 21.7 27.5 30.1
44.8 50. 37.6 31.6 46.7 31.5 24.3 31.7 41.7 48.3 29. 24. 25.1 31.5
23.7 23.3 22. 20.1 22.2 23.7 17.6 18.5 24.3 20.5 24.5 26.2 24.4 24.8
29.6 42.8 21.9 20.9 44. 50. 36. 30.1 33.8 43.1 48.8 31. 36.5 22.8
30.7 50. 43.5 20.7 21.1 25.2 24.4 35.2 32.4 32. 33.2 33.1 29.1 35.1
45.4 35.4 46. 50. 32.2 22. 20.1 23.2 22.3 24.8 28.5 37.3 27.9 23.9
21.7 28.6 27.1 20.3 22.5 29. 24.8 22. 26.4 33.1 36.1 28.4 33.4 28.2
22.8 20.3 16.1 22.1 19.4 21.6 23.8 16.2 17.8 19.8 23.1 21. 23.8 23.1
20.4 18.5 25. 24.6 23. 22.2 19.3 22.6 19.8 17.1 19.4 22.2 20.7 21.1
19.5 18.5 20.6 19. 18.7 32.7 16.5 23.9 31.2 17.5 17.2 23.1 24.5 26.6
22.9 24.1 18.6 30.1 18.2 20.6 17.8 21.7 22.7 22.6 25. 19.9 20.8 16.8
21.9 27.5 21.9 23.1 50. 50. 50. 50. 50. 13.8 13.8 15. 13.9 13.3
13.1 10.2 10.4 10.9 11.3 12.3 8.8 7.2 10.5 7.4 10.2 11.5 15.1 23.2
9.7 13.8 12.7 13.1 12.5 8.5 5. 6.3 5.6 7.2 12.1 8.3 8.5 5.
11.9 27.9 17.2 27.5 15. 17.2 17.9 16.3 7. 7.2 7.5 10.4 8.8 8.4
16.7 14.2 20.8 13.4 11.7 8.3 10.2 10.9 11. 9.5 14.5 14.1 16.1 14.3
11.7 13.4 9.6 8.7 8.4 12.8 10.5 17.1 18.4 15.4 10.8 11.8 14.9 12.6
14.1 13. 13.4 15.2 16.1 17.8 14.9 14.1 12.7 13.5 14.9 20. 16.4 17.7
19.5 20.2 21.4 19.9 19. 19.1 19.1 20.1 19.9 19.6 23.2 29.8 13.8 13.3
16.7 12. 14.6 21.4 23. 23.7 25. 21.8 20.6 21.2 19.1 20.6 15.2 7.
8.1 13.6 20.1 21.8 24.5 23.1 19.7 18.3 21.2 17.5 16.8 22.4 20.6 23.9
22. 11.9]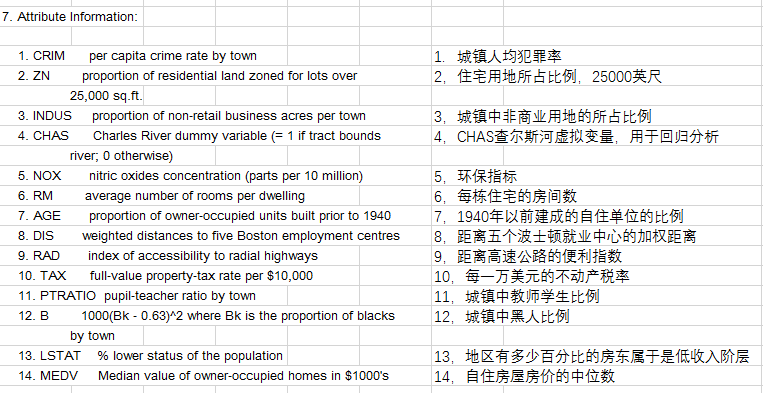
CRIM:城镇人均犯罪率。
ZN:住宅用地超过 25000 sq.ft. 的比例。
INDUS:城镇非零售商用土地的比例。
CHAS:查理斯河空变量(如果边界是河流,则为1;否则为0)。
NOX:一氧化氮浓度。
RM:住宅平均房间数。
AGE:1940 年之前建成的自用房屋比例。
DIS:到波士顿五个中心区域的加权距离。
RAD:辐射性公路的接近指数。
TAX:每 10000 美元的全值财产税率。
PTRATIO:城镇师生比例。
B:1000(Bk-0.63)^ 2,其中 Bk 指代城镇中黑人的比例。
LSTAT:人口中地位低下者的比例。
MEDV:自住房的平均房价,以千美元计。
预测平均值的基准性能的均方根误差(RMSE)是约 9.21 千美元
- CRIM per capita crime rate by town
- ZN proportion of residential land zoned for lots over 25,000 sq.ft.
- INDUS proportion of non-retail business acres per town
- CHAS Charles River dummy variable (= 1 if tract bounds river; 0 otherwise)
- NOX nitric oxides concentration (parts per 10 million)
- RM average number of rooms per dwelling
- AGE proportion of owner-occupied units built prior to 1940
- DIS weighted distances to five Boston employment centres
- RAD index of accessibility to radial highways
1. 使用scikit-learn跑一个两年前的案例, 报错:cannot import name ‘joblib’ from ‘sklearn.externals’
原因: scikit-learn版本太新了,
在调用sklearn时出现 Unknown label type: ‘continuous’ model.fit(X_train, y_train) 更改为 model.fit(X_train, y_train.astype('int'))
MSE (Mean Squared Error)叫做均方误差,是反映估计量与被估计量之间差异程度的一种度量。设t是根据子样确定的总体参数θ的一个估计量,(θ-t)2的数学期望,称为估计量t的均方误差。它等于σ2+b2,其中σ2与b分别是t的方差与偏倚。MSE=
测试集中的数据量m不同,因为有累加操作,所以随着数据的增加 ,误差会逐渐积累;因此衡量标准和m相关。为了抵消掉数据量的形象,可以除去数据量,抵消误差。通过这种处理方式得到的结果叫做均方误差MSE(Mean Squared Error):

用 真实值-预测值 然后平方之后求和平均。在线性回归的时候我们的目的就是让这个损失函数最小。
SVM方法建立在统计学VC维和结构风险最小化原则上,既可以用于分类(二/多分类)、也可用于回归和异常值检测。SVM具有良好的鲁棒性,对未知数据拥有很强的泛化能力,特别是在数据量较少的情况下,相较其他传统机器学习算法具有更优的性能。
使用SVM作为模型时,通常采用如下流程:
- 对样本数据进行归一化
- 应用核函数对样本进行映射(最常采用和核函数是RBF和Linear,在样本线性可分时,Linear效果要比RBF好)
- 用cross-validation和grid-search对超参数进行优选
- 用最优参数训练得到模型
- 测试
sklearn中支持向量分类主要有三种方法:SVC、NuSVC、LinearSVC,扩展为三个支持向量回归方法:SVR、NuSVR、LinearSVR。
SVC和NuSVC方法基本一致,唯一区别就是损失函数的度量方式不同(NuSVC中的nu参数和SVC中的C参数);LinearSVC是实现线性核函数的支持向量分类,没有kernel参数,也缺少一些方法的属性,如support_等。
2. 参数
- SVC class
sklearn.svm.``SVC(C=1.0, kernel='rbf', degree=3, gamma='auto', coef0=0.0, shrinking=True, probability=False, tol=0.001, cache_size=200, class_weight=None, verbose=False, max_iter=-1, decision_function_shape='ovr', random_state=None)
**C:** 惩罚系数,用来控制损失函数的惩罚系数,类似于LR中的正则化系数。C越大,相当于惩罚松弛变量,希望松弛变量接近0,即对误分类的惩罚增大,趋向于对训练集全分对的情况,这样会出现训练集测试时准确率很高,但泛化能力弱,容易导致过拟合。 C值小,对误分类的惩罚减小,容错能力增强,泛化能力较强,但也可能欠拟合。
**kernel:** 算法中采用的和函数类型,核函数是用来将非线性问题转化为线性问题的一种方法。参数选择有RBF, Linear, Poly, Sigmoid,precomputed或者自定义一个核函数, 默认的是"RBF",即径向基核,也就是高斯核函数;而Linear指的是线性核函数,Poly指的是多项式核,Sigmoid指的是双曲正切函数tanh核;。
**degree:**当指定kernel为'poly'时,表示选择的多项式的最高次数,默认为三次多项式;若指定kernel不是'poly',则忽略,即该参数只对'poly'有用。(多项式核函数是将低维的输入空间映射到高维的特征空间)
**gamma:** 核函数系数,该参数是rbf,poly和sigmoid的内核系数;默认是'auto',那么将会使用特征位数的倒数,即1 / n_features。(即核函数的带宽,超圆的半径)。gamma越大,σ越小,使得高斯分布又高又瘦,造成模型只能作用于支持向量附近,可能导致过拟合;反之,gamma越小,σ越大,高斯分布会过于平滑,在训练集上分类效果不佳,可能导致欠拟合。
**coef0:** 核函数常数值(y=kx+b中的b值),只有‘poly’和‘sigmoid’核函数有,默认值是0。
shrinking : 是否进行启发式。如果能预知哪些变量对应着支持向量,则只要在这些样本上训练就够了,其他样本可不予考虑,这不影响训练结果,但降低了问题的规模并有助于迅速求解。进一步,如果能预知哪些变量在边界上(即a=C),则这些变量可保持不动,只对其他变量进行优化,从而使问题的规模更小,训练时间大大降低。这就是Shrinking技术。 Shrinking技术基于这样一个事实:支持向量只占训练样本的少部分,并且大多数支持向量的拉格朗日乘子等于C。
**probability: **是否使用概率估计,默认是False。必须在 fit( ) 方法前使用,该方法的使用会降低运算速度。
**tol:** 残差收敛条件,默认是0.0001,即容忍1000分类里出现一个错误,与LR中的一致;误差项达到指定值时则停止训练。
**cache_size:** 缓冲大小,用来限制计算量大小,默认是200M。
class_weight : {dict, ‘balanced’},字典类型或者'balance'字符串。权重设置,正类和反类的样本数量是不一样的,这里就会出现类别不平衡问题,该参数就是指每个类所占据的权重,默认为1,即默认正类样本数量和反类一样多,也可以用一个字典dict指定每个类的权值,或者选择默认的参数balanced,指按照每个类中样本数量的比例自动分配权值。如果不设置,则默认所有类权重值相同,以字典形式传入。 将类i 的参数C设置为SVC的class_weight[i]*C。如果没有给出,所有类的weight 为1。'balanced'模式使用y 值自动调整权重,调整方式是与输入数据中类频率成反比。如n_samples / (n_classes * np.bincount(y))。(给每个类别分别设置不同的惩罚参数C,如果没有给,则会给所有类别都给C=1,即前面参数指出的参数C。如果给定参数'balance',则使用y的值自动调整与输入数据中的类频率成反比的权重。)
verbose : 是否启用详细输出。在训练数据完成之后,会把训练的详细信息全部输出打印出来,可以看到训练了多少步,训练的目标值是多少;但是在多线程环境下,由于多个线程会导致线程变量通信有困难,因此verbose选项的值就是出错,所以多线程下不要使用该参数。
**max_iter:** 最大迭代次数,默认是-1,即没有限制。这个是硬限制,它的优先级要高于tol参数,不论训练的标准和精度达到要求没有,都要停止训练。
decision_function_shape : 原始的SVM只适用于二分类问题,如果要将其扩展到多类分类,就要采取一定的融合策略,这里提供了三种选择。‘ovo’ 一对一,为one v one,即将类别两两之间进行划分,用二分类的方法模拟多分类的结果,决策所使用的返回的是(样本数,类别数*(类别数-1)/2); ‘ovr’ 一对多,为one v rest,即一个类别与其他类别进行划分,返回的是(样本数,类别数),或者None,就是不采用任何融合策略。默认是ovr,因为此种效果要比oro略好一点。
**\**random_state:\** **在使用SVM训练数据时,要先将训练数据打乱顺序,用来提高分类精度,这里就用到了伪随机序列。如果该参数给定的是一个整数,则该整数就是伪随机序列的种子值;如果给定的就是一个随机实例,则采用给定的随机实例来进行打乱处理;如果啥都没给,则采用默认的 np.random实例来处理。
- NuSVC class
sklearn.svm.``NuSVC(nu=0.5, kernel='rbf', degree=3, gamma='auto', coef0=0.0, shrinking=True, probability=False, tol=0.001, cache_size=200, class_weight=None, verbose=False, max_iter=-1, decision_function_shape='ovr', random_state=None)
nu: 训练误差部分的上限和支持向量部分的下限,取值在(0,1)之间,默认是0.5
- LinearSVC class
sklearn.svm.``LinearSVC(penalty='l2', loss='squared_hinge', dual=True, tol=0.0001, C=1.0, multi_class='ovr', fit_intercept=True, intercept_scaling=1, class_weight=None, verbose=0, random_state=None, max_iter=1000)
**penalty:** 正则化参数,L1和L2两种参数可选,仅LinearSVC有。
**loss:** 损失函数,有‘hinge’和‘squared_hinge’两种可选,前者又称L1损失,后者称为L2损失,默认是是’squared_hinge’,其中hinge是SVM的标准损失,squared_hinge是hinge的平方
**dual:** 是否转化为对偶问题求解,默认是True。
**tol:** 残差收敛条件,默认是0.0001,与LR中的一致。
**C:** 惩罚系数,用来控制损失函数的惩罚系数,类似于LR中的正则化系数。
**multi_class:** 负责多分类问题中分类策略制定,有‘ovr’和‘crammer_singer’ 两种参数值可选,默认值是’ovr’,'ovr'的分类原则是将待分类中的某一类当作正类,其他全部归为负类,通过这样求取得到每个类别作为正类时的正确率,取正确率最高的那个类别为正类;‘crammer_singer’ 是直接针对目标函数设置多个参数值,最后进行优化,得到不同类别的参数值大小
**fit_intercept:** 是否计算截距,与LR模型中的意思一致。
**class_weight:** 与其他模型中参数含义一样,也是用来处理不平衡样本数据的,可以直接以字典的形式指定不同类别的权重,也可以使用balanced参数值。
**verbose:** 是否冗余,默认是False。
**random_state:** 随机种子。
**max_iter:** 最大迭代次数,默认是1000。
3. 属性(Attributes)
**support_:** 以数组的形式返回支持向量的索引,即在所有的训练样本中,哪些样本成为了支持向量。
**support_vectors_:** 返回支持向量,汇总了当前模型所有的支持向量。
**n_support_:** 比如SVC将数据集分成了4类,该属性表示了每一类的支持向量的个数。
**dual_coef_:** 对偶系数,即支持向量在决策函数中的系数,在多分类问题中,这个会有所不同。
**coef_:** 每个特征系数(重要性),只有核函数是Linear的时候可用。
**intercept_:** 决策函数中的常数项(借据值),和coef_共同构成决策函数的参数值。
4. 方法(Method)
**decision_function(X): **获取数据集中样本X到分离超平面的距离。
**fit(X, y): **在数据集(X,y)上拟合SVM模型。
**get_params([deep]): **获取模型的参数。
**predict(X): **预测数据值X的标签。
**score(X,y): 返回给定测试集和对应标签的平均准确率。
**
5. 核函数的使用
- **RBF核:**高斯核函数就是在属性空间中找到一些点,这些点可以是也可以不是样本点,把这些点当做base,以这些base为圆心向外扩展,扩展半径即为带宽,即可划分数据。换句话说,在属性空间中找到一些超圆,用这些超圆来判定正反类。
- **线性核和多项式核:**这两种核的作用也是首先在属性空间中找到一些点,把这些点当做base,核函数的作用就是找与该点距离和角度满足某种关系的样本点。当样本点与该点的夹角近乎垂直时,两个样本的欧式长度必须非常长才能保证满足线性核函数大于0;而当样本点与base点的方向相同时,长度就不必很长;而当方向相反时,核函数值就是负的,被判为反类。即,它在空间上划分出一个梭形,按照梭形来进行正反类划分。
- **Sigmoid核:**同样地是定义一些base,核函数就是将线性核函数经过一个tanh函数进行处理,把值域限制在了-1到1上。
总之,都是在定义距离,大于该距离,判为正,小于该距离,判为负。至于选择哪一种核函数,要根据具体的样本分布情况来确定。
一般有如下指导规则:
- 如果Feature的数量很大,甚至和样本数量差不多时,往往线性可分,这时选用LR或者线性核Linear;
- 如果Feature的数量很小,样本数量正常,不算多也不算少,这时选用RBF核;
- 如果Feature的数量很小,而样本的数量很大,这时手动添加一些Feature,使得线性可分,然后选用LR或者线性核Linear;
- 多项式核一般很少使用,效率不高,结果也不优于RBF;
- Linear核参数少,速度快;RBF核参数多,分类结果非常依赖于参数,需要交叉验证或网格搜索最佳参数,比较耗时;
- 应用最广的应该就是RBF核,无论是小样本还是大样本,高维还是低维等情况,RBF核函数均适用。
6. 总结
支持向量机的优点:
- 在高维空间中非常高效;
- 即使在数据维度比样本数量大的情况下仍然有效;
- 在决策函数(称为支持向量)中使用训练集的子集,因此它也是高效利用内存的;
- 通用性:不同的核函数与特定的决策函数一一对应;
支持向量机的缺点:
-
如果特征数量比样本数量大得多,在选择核函数时要避免过拟合;
-
支持向量机不直接提供概率估计,这些都是使用昂贵的五次交叉验算计算的。